sqlite3源码解析之sql解析(一)
一:sql准备过程
在前面的分析中我们知道,sqlite3_open()为我们打开了数据库并准备了所要的内存空间,锁,vfs等。
接下来就分析sql是如何被解析器一步一步解析的。

上图是准备sql语句的过程分析图。
1.1:sqlite3_prepare_v2函数:
该函数是准备的入口函数。
传入了5个参数:
sqlite3 *db : sqlite3_open()返回的数据库句柄
const char *zSql: 要准备的sql语句
int nBytes : sql语句的 长度(strlen(sql))
sqlite3_stmt **ppStmt: 准备的语句存储该结构体对象中,可以认为是预编译语句的句柄,执行时需要传入这个句柄
const char **pzTail: 指向被解析的字符串的末尾
SQLite 现在提供两个版本的编译 API 函数:遗留的和现在使用的。
在遗留版本中,原始 SQL 文本没有保存在编译后的语句(sqlite3_stmt 结构)中,因此,如
果 schema 发生改变,sqlite3_step()会返回 SQLITE_SCHEMA。在新版本中,编译后的语句
中保存原始 SQL 文本,当遇到schema 改变时自动重新编译。sqlite3_prepare()函数中其实只包含一条对 sqlite3LockAndPrepare()的调用语句:
SQLITE_APIint sqlite3_prepare_v2( sqlite3 *db, /* Database handle. 成功打开的数据库句柄*/ constchar *zSql, /* UTF-8 encoded SQL statement. UTF8编码的 SQL 语句 */ intnBytes, /* Length of zSql in bytes. 参数 sql 的字节数, 包含 '\0' */ sqlite3_stmt **ppStmt, /* OUT: A pointer to the prepared statement 输出:预编译语句句柄 */ constchar **pzTail /* OUT: End of parsed string 输出:指向 sql 语句中未使用的部分*/ ){ int rc;
rc = sqlite3LockAndPrepare(db,zSql,nBytes,SQLITE_PREPARE_SAVESQL,0, ppStmt,pzTail); assert( rc==SQLITE_OK || ppStmt==0 || *ppStmt==0 ); return rc; } |
1.2:sqlite3LockAndPrepare函数
该函数并没有做太多事情主要是多了两个参数,判断一下db是否合法。
调用sqlite3Prepare函数。
staticint sqlite3LockAndPrepare( sqlite3 *db, /* Database handle. */ constchar *zSql, /* UTF-8 encoded SQL statement.(UTF-8 编码的 SQL 语句) */ intnBytes, /* Length of zSql in bytes. (zSql 的字节数)*/ u32prepFlags, /* Zero or more SQLITE_PREPARE_* flags(保存的sql文本) */ Vdbe *pOld, /* VM being reprepared */ sqlite3_stmt **ppStmt, /* OUT: A pointer to the prepared statement(指向已准备好的语句的指针 ) */ constchar **pzTail /* OUT: End of parsed string(未处理的 SQL 串) */ ){ int rc;
#ifdef SQLITE_ENABLE_API_ARMOR if( ppStmt==0 ) return SQLITE_MISUSE_BKPT; #endif *ppStmt = 0; if( !sqlite3SafetyCheckOk(db)||zSql==0 ){//确定 db 指针的合法性 returnSQLITE_MISUSE_BKPT; } sqlite3_mutex_enter(db->mutex); sqlite3BtreeEnterAll(db); rc = sqlite3Prepare(db, zSql, nBytes, prepFlags, pOld, ppStmt, pzTail);//将 UTF-8 编码的 SQL 语句 zSql 编译成 if( rc==SQLITE_SCHEMA ){ // 如果遇到 SCHEMA 改变,定案,再编译 sqlite3ResetOneSchema(db, -1); sqlite3_finalize(*ppStmt); rc = sqlite3Prepare(db, zSql, nBytes, prepFlags, pOld, ppStmt, pzTail); } sqlite3BtreeLeaveAll(db); sqlite3_mutex_leave(db->mutex); assert( rc==SQLITE_OK || *ppStmt==0 ); return rc; } |
1.3: sqlite3Prepare函数
这个函数做了以下几个事:
1:加入解析器Parse
2:所需内存的初始化以及是否禁用后备内存
3:判断链接的数据库是否加锁,如果加锁需要解锁
4:zSqlCopy= sqlite3DbStrNDup(db, zSql, nBytes)语句复制了zsql。
5:调用sqlite3RunParser(&sParse,zSql, &zErrMsg);
还有的后面补上
staticint sqlite3Prepare( sqlite3 *db, /* Database handle. */ constchar *zSql, /* UTF-8 encoded SQL statement. */ intnBytes, /* Length of zSql in bytes. */ u32prepFlags, /* Zero or more SQLITE_PREPARE_* flags */ Vdbe *pReprepare, /* VM being reprepared */ sqlite3_stmt **ppStmt, /* OUT: A pointer to the prepared statement (输出经过处理的准备语句)*/ constchar **pzTail /* OUT: End of parsed string */ ){ char *zErrMsg = 0; /* Error message */ int rc = SQLITE_OK; /* Result code */ int i; /* Loop counter */ Parse sParse; /* Parsing context(解析语境) */
memset(&sParse, 0, PARSE_HDR_SZ); memset(PARSE_TAIL(&sParse), 0, PARSE_TAIL_SZ);//初始化内存空间 sParse.pReprepare = pReprepare; assert( ppStmt && *ppStmt==0 ); /* assert( !db->mallocFailed ); // not true with SQLITE_USE_ALLOCA */ assert( sqlite3_mutex_held(db->mutex) );
/* For a long-term use prepared statement avoid the use of ** lookaside memory. (长期使用事先准备好的声明避免后备存储器的使用。) */ if( prepFlags & SQLITE_PREPARE_PERSISTENT ){ sParse.disableLookaside++;//禁用后备内存 来使需要重复使用的准备语句可以多次使用 db->lookaside.bDisable++;//同时禁止db中后备内存分配的参数 }
/* **(检查以验证是否可以在所有数据库模式上获得读锁 .无法获得读锁,表明某些其他数据库连接持有写锁。 这反过来意味着另一个连接对模式做出了未提交的更改。 ) **(我们是否要继续和准备对未提交的模式更改的声明,如果这些模式更改随后回滚,并在其位置进行不同的更改 然后,当准备好的语句运行时,模式cookie将无法检测模式更改。灾难会随之发生。 */ for(i=0; i<db->nDb; i++) {//依此遍历连接的数据库 Btree *pBt = db->aDb[i].pBt; if( pBt ){ assert( sqlite3BtreeHoldsMutex(pBt) ); rc = sqlite3BtreeSchemaLocked(pBt);//判断这个btree是否被锁 if( rc ){ //如果是就提示该数据库已被加锁 constchar *zDb = db->aDb[i].zDbSName; sqlite3ErrorWithMsg(db, rc, "database schema is locked: %s", zDb); testcase( db->flags & SQLITE_ReadUncommit ); goto end_prepare; } } }
sqlite3VtabUnlockList(db);//然后解锁
sParse.db = db; if( nBytes>=0 && (nBytes==0 || zSql[nBytes-1]!=0) ){ char *zSqlCopy; int mxLen = db->aLimit[SQLITE_LIMIT_SQL_LENGTH]; //准备语句最大长度 testcase( nBytes==mxLen ); testcase( nBytes==mxLen+1 ); if( nBytes>mxLen ){//如果超过了这个长度就提示 sqlite3ErrorWithMsg(db, SQLITE_TOOBIG, "statement too long"); rc = sqlite3ApiExit(db, SQLITE_TOOBIG); goto end_prepare;//结束准备阶段 } zSqlCopy = sqlite3DbStrNDup(db, zSql, nBytes);//复制zSql字符串 if( zSqlCopy ){ sqlite3RunParser(&sParse, zSqlCopy, &zErrMsg); sParse.zTail = &zSql[sParse.zTail-zSqlCopy]; sqlite3DbFree(db, zSqlCopy); }else{ sParse.zTail = &zSql[nBytes]; } }else{ sqlite3RunParser(&sParse, zSql, &zErrMsg); } assert( 0==sParse.nQueryLoop );
if( sParse.rc==SQLITE_DONE ) sParse.rc = SQLITE_OK; if( sParse.checkSchema ){ schemaIsValid(&sParse); } if( db->mallocFailed ){ sParse.rc = SQLITE_NOMEM_BKPT; } if( pzTail ){ *pzTail = sParse.zTail; } rc = sParse.rc;
#ifndef SQLITE_OMIT_EXPLAIN if( rc==SQLITE_OK && sParse.pVdbe && sParse.explain ){ staticconstchar * const azColName[] = { "addr", "opcode", "p1", "p2", "p3", "p4", "p5", "comment", "selectid", "order", "from", "detail" }; int iFirst, mx; if( sParse.explain==2 ){ sqlite3VdbeSetNumCols(sParse.pVdbe, 4); iFirst = 8; mx = 12; }else{ sqlite3VdbeSetNumCols(sParse.pVdbe, 8); iFirst = 0; mx = 8; } for(i=iFirst; i sqlite3VdbeSetColName(sParse.pVdbe, i-iFirst, COLNAME_NAME, azColName[i], SQLITE_STATIC); } } #endif
if( db->init.busy==0 ){ sqlite3VdbeSetSql(sParse.pVdbe, zSql, (int)(sParse.zTail-zSql), prepFlags); } if( sParse.pVdbe && (rc!=SQLITE_OK || db->mallocFailed) ){ sqlite3VdbeFinalize(sParse.pVdbe); assert(!(*ppStmt)); }else{ *ppStmt = (sqlite3_stmt*)sParse.pVdbe; }
if( zErrMsg ){ sqlite3ErrorWithMsg(db, rc, "%s", zErrMsg); sqlite3DbFree(db, zErrMsg); }else{ sqlite3Error(db, rc); }
/* Delete any TriggerPrg structures allocated while parsing this statement. */ while( sParse.pTriggerPrg ){ TriggerPrg *pT = sParse.pTriggerPrg; sParse.pTriggerPrg = pT->pNext; sqlite3DbFree(db, pT); }
end_prepare:
sqlite3ParserReset(&sParse); rc = sqlite3ApiExit(db, rc); assert( (rc&db->errMask)==rc ); return rc; } |
1.4:sqlite3RunParser函数
sqlite3RunParser位于token.c文件中,它是进行SQL语句分析的入口,它调用sqlite3GetToken对SQL语句zSql进行分词,然后调用sqlite3Parser进行语法分析。而sqlite3Parser在语法规则发生规约时调用相应的opcode生成子例程,生成opcode。
在给定的SQL字符串上运行解析器.解析器结构传入。
功能:在给定的 SQL 字符串上执行分析器。传入一个 parser 结构。返回一个 SQLITE_状态
码。如果有错误发生,将错误信息写入*pzErrMsg。
本函数内部是一个循环语句,每次循环处理一个词,根据词的类型做出不同的处理。如果是
正经的词(不是空格什么的),都会调用 sqlite3Parser()函数对其进行分析。
SQLITE_PRIVATEint sqlite3RunParser(Parse *pParse, constchar *zSql, char **pzErrMsg){
int nErr = 0; /* Number of errors encountered(遇到的错误数) */ void *pEngine; /* The LEMON-generated LALR(1) parser(lemon算法解析器) */ int n = 0; /* Length of the next token token(下一个token的长度) */ int tokenType; /* type of the next token (下一个token的类型)*/ int lastTokenParsed = -1; /* type of the previous token (上一个token的类型)*/ sqlite3 *db = pParse->db; /* The database connection */ int mxSqlLen; /* Max length of an SQL string(sql字符串的最大长度) */ #ifdefsqlite3Parser_ENGINEALWAYSONSTACK yyParser sEngine; /* Space to hold the Lemon-generated Parser object(保存lemon生成的解析器对象的空间 ) */ #endif
assert( zSql!=0 ); mxSqlLen = db->aLimit[SQLITE_LIMIT_SQL_LENGTH];// mxSqlLen 1000000000 int if( db->nVdbeActive==0 ){//虚拟机活动数量为0 db->u1.isInterrupted = 0;//sqlite3_interrupt不被执行(我猜是中断执行) } pParse->rc = SQLITE_OK; pParse->zTail = zSql; assert( pzErrMsg!=0 ); /* sqlite3ParserTrace(stdout, "parser: "); */ #ifdefsqlite3Parser_ENGINEALWAYSONSTACK pEngine = &sEngine; sqlite3ParserInit(pEngine);//初始化已分配的解析器(初始化解析器对象各个字段) #else pEngine = sqlite3ParserAlloc(sqlite3Malloc); if( pEngine==0 ){ sqlite3OomFault(db); return SQLITE_NOMEM_BKPT; } #endif assert( pParse->pNewTable==0 ); assert( pParse->pNewTrigger==0 ); assert( pParse->nVar==0 ); assert( pParse->pVList==0 ); while( 1 ){ if( zSql[0]!=0 ){// zSql[0]表示一个token 开头(比如select就为s) n = sqlite3GetToken((u8*)zSql, &tokenType); mxSqlLen -= n; if( mxSqlLen<0 ){ pParse->rc = SQLITE_TOOBIG; break; } }else{
if( lastTokenParsed==TK_SEMI ){ tokenType = 0; }elseif( lastTokenParsed==0 ){ break; }else{ tokenType = TK_SEMI; } zSql -= n; } if( tokenType>=TK_SPACE ){ assert( tokenType==TK_SPACE || tokenType==TK_ILLEGAL ); if( db->u1.isInterrupted ){ pParse->rc = SQLITE_INTERRUPT; break; } if( tokenType==TK_ILLEGAL ){ sqlite3ErrorMsg(pParse, "unrecognized token: \"%.*s\"", n, zSql); break; } zSql += n; }else{ pParse->sLastToken.z = zSql;//0x0070808f "id,name from stu" const char * pParse->sLastToken.n = n; sqlite3Parser(pEngine, tokenType, pParse->sLastToken, pParse); lastTokenParsed = tokenType; zSql += n; if( pParse->rc!=SQLITE_OK || db->mallocFailed ) break; } } assert( nErr==0 ); pParse->zTail = zSql; #ifdef YYTRACKMAXSTACKDEPTH sqlite3_mutex_enter(sqlite3MallocMutex()); sqlite3StatusHighwater(SQLITE_STATUS_PARSER_STACK, sqlite3ParserStackPeak(pEngine) ); sqlite3_mutex_leave(sqlite3MallocMutex()); #endif/* YYDEBUG */ #ifdefsqlite3Parser_ENGINEALWAYSONSTACK sqlite3ParserFinalize(pEngine); #else sqlite3ParserFree(pEngine, sqlite3_free); #endif if( db->mallocFailed ){ pParse->rc = SQLITE_NOMEM_BKPT; } if( pParse->rc!=SQLITE_OK && pParse->rc!=SQLITE_DONE && pParse->zErrMsg==0 ){ pParse->zErrMsg = sqlite3MPrintf(db, "%s", sqlite3ErrStr(pParse->rc)); } assert( pzErrMsg!=0 ); if( pParse->zErrMsg ){ *pzErrMsg = pParse->zErrMsg; sqlite3_log(pParse->rc, "%s", *pzErrMsg); pParse->zErrMsg = 0; nErr++; } if( pParse->pVdbe && pParse->nErr>0 && pParse->nested==0 ){ sqlite3VdbeDelete(pParse->pVdbe); pParse->pVdbe = 0; } #ifndef SQLITE_OMIT_SHARED_CACHE if( pParse->nested==0 ){ sqlite3DbFree(db, pParse->aTableLock); pParse->aTableLock = 0; pParse->nTableLock = 0; } #endif #ifndef SQLITE_OMIT_VIRTUALTABLE sqlite3_free(pParse->apVtabLock); #endif
if( !IN_DECLARE_VTAB ){
sqlite3DeleteTable(db, pParse->pNewTable); }
if( pParse->pWithToFree ) sqlite3WithDelete(db, pParse->pWithToFree); sqlite3DeleteTrigger(db, pParse->pNewTrigger); sqlite3DbFree(db, pParse->pVList); while( pParse->pAinc ){ AutoincInfo *p = pParse->pAinc; pParse->pAinc = p->pNext; sqlite3DbFreeNN(db, p); } while( pParse->pZombieTab ){ Table *p = pParse->pZombieTab; pParse->pZombieTab = p->pNextZombie; sqlite3DeleteTable(db, p); } assert( nErr==0 || pParse->rc!=SQLITE_OK ); return nErr; }
|
这个函数里面比较重要的三个函数我已经加粗了。
下面我说一下解析时是如何循环的。
n = sqlite3GetToken((u8*)zSql, &tokenType);
这句代码就是获取sql语句第一个词的长度,比如有一个sql语句select id name from stu;
通过while循环获取第一个词select的长度为6。然后依次循环直到结束。
第一次循环zSql[0]的数为s,及sql预语句的第一个关键字的第一个字符。

然后获取n为6及select的长度,mxSqlLen-= n;这条语句是让最大长度减当前n的值。
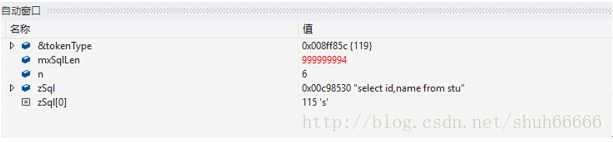
后面就将n的大小和sql语句传个解析对象和Token
然后执行sqlite3Parser(pEngine,tokenType, pParse->sLastToken, pParse);函数进行解析
