排序小结之插入排序及其升级版
1、直接插入排序
比较次数最好n-1,最坏n(n-1)/2,平均比较复杂度为O(n^2),平均移动复杂度也为O(n^2),稳定的排序方法,在大部分元素有序的情况下,表现优良。不适合数据量较大的排序,小于千的数量级,是不错选择(文末有测试数据)。STL的sort算法和stdlib的qsort算法中,都将插入排序作为快速排序的补充,用于少量元素的排序(通常为8个或以下)
void insert_sort(int a[], int len)
{
int i, j, temp;
for(i = 1; i < len; i++)
{
temp = a[i];
for( j = i -1; j >= 0 && a[j] >= temp; a[j + 1] = a[j], j--);
a[j + 1] = temp;
}
}
可在上述程序中去掉地7行中a[j] >= temp表达式中的等号,优化相等情况的性能
2.二分插入排序
也是稳定的排序方法,和直接插入比较,减少了比较次数,数据规模大时,比直接插入稍微好些,但改观不大,平均移动复杂度也为O(n^2)
int binary_search(int elm, int start_pos, int end_pos)
{
if (start_pos == end_pos)
return start_pos;
else
{
int tmp_pos = (start_pos + end_pos) / 2;
if (tmp_pos == start_pos)
return start_pos;
if (elm > a[tmp_pos])
binary_search(elm, tmp_pos, end_pos);
else if (elm < a[tmp_pos])
binary_search(elm, start_pos, tmp_pos);
else
return tmp_pos;
}
}
void isort_binary(int a[], int len)
{
int i, j, temp, pos;
for (i = 1; i < len ; i++)
{
temp = a[i];
pos = binary_search(temp, 0, i - 1);
for (j = i - 1; j > pos; a[j + 1] = a[j], j--);
a[pos+1] = temp;
}
}
3. 希尔排序 wiki
是插入排序的一种更高效的改进版本,非稳定排序算法,把直接插入每次移动的一次改为一定的步长,并按照一定规律递减,最终为1.
举个例子,以步长20开始,折半递减
void shell_sort(int a[], int len)//#define INITSTEP 20
{
int step, i, j, temp;
for (step = INITSTEP; step >= 1; step /= 2)
{
for (i = 1; i < len; i++)
{
temp = a[i];
for (j = i - step; j >= 0 && a[j] > temp; a[j + step] = a[j], j -= step);
a[j + step] = temp;
}
}
}
好的增量序列的共同特征:
① 最后一个增量必须为1;
② 应该尽量避免序列中的值(尤其是相邻的值)互为倍数的情况。
参考一下维基百科里的各种步长效率:
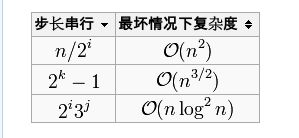
总的说来,它比O(N^2)复杂度的算法快得多,并且容易实现,此外,希尔算法在最坏的情况下和平均情况下执行效率相差不是很多
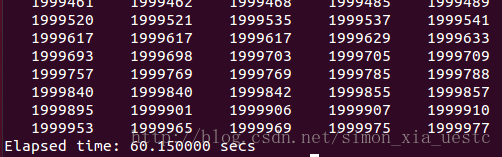
博主纯手工肉测了一组数据,小做参考
测试程序和数据打包到这里:http://download.csdn.net/detail/simon_uestc/6858561

可以看出希尔的效率着实喜人,再马克一个测试截图以做纪念