Unity优化大全(二)之CPU-DrawCall- Batching
前言:
首先我们要讲的是CPU方面的优化,其主要会包括以下方面,之后会不断完善。在这里你要知道一点,CPU是负责频率的!
- DrawCalls(DC回调)
- GC(内存回收)和Script
-
VSync Count (垂直同步)
- Physics
- 日后会不断补上
前面说过了,DC是CPU调用底层图形接口。比如有上千个物体,每一个的渲染都需要去调用一次底层接口,而每一次的调用CPU都需要做很多工作,那么CPU必然不堪重负。但是对于GPU来说,图形处理的工作量是一样的。所以对DC的优化,主要就是为了尽量解放CPU在调用图形接口上的开销。所以针对DC我们主要的思路就是每个物体尽量减少渲染次数,多个物体最好一起渲染。所以,按照这个思路就有了以下几个方案:
- 使用DC Batching,也就是描绘调用批处理。Unity在运行时可以将一些物体进行合并,从而用一个描绘调用来渲染他们。具体下面会介绍。
- 通过把纹理打包成图集来尽量减少材质的使用。
- 尽量少的使用反光,阴影啦之类的,因为那会使物体多次渲染。
-
使用Occlusion Culling算法,减少可见的物体数量同时也可以减少Draw Call。
-
删除不必要的Shader中的Pass通道,因为一个Pass对应一个DC。
- 日后会不断补上。
一、DC Batching(DC批处理)
首先我们要先理解为何2个没有使用相同材质的物体即使使用批处理,也无法实现DC数量的下降和性能上的提升。因为被“批处理”的2个物体的网格模型需要使用相同材质的目的,也就是材质使用同一个Shader,同时Shader属性也要一相同,属性分为好多种,在这里可能大家对纹和颜色用的最多,这里就主要说说纹理吧,对于两个不同纹理的材质可以将纹理打包成图集,这样我们就可以只用一个材质来代替之前的2个材质了。而Draw Call Batching本身,也还会细分为2种,一种是Dynamic Batching 动态批处理,另一种是Static Batching 静态批处理。
Dynamic Batching 动态批处理
在这里我们首先要知道,如果动态物体共用着相同的材质,那么Unity会自动对这些物体进行批处理,而且动态批处理操作是自动完成的,并不需要你进行额外的操作。
在这里我用例子来说明:
我们在场景里放两个物体,他们使用同一个材质,根本就是同一个Shader,里面的属性都相同,如下所示:


我只是运行下程序,什么也没做处理,你会发现其Saved By Batching为1,也就是减少了一个DC.
在这里再看看VBO(顶点缓冲对象Vertex Buffer Objects-是让APP存储和操作GPU内存中数据的一种机制,当GPU处理数据时,不需要从CPU内存中读取,可以节约内存带宽) Total的值是207.2KB,这与场景里没放物体207.2KB一样大小,这说明了动态批处理不仅优化了CPU的DC,还有优化了Memory(内存)大小!!!!!!
注意:
如像笔者所言, 动态批处理这么好,那动态批处理做起来不是很容易,那还为什么要有静态批处理(接下来会解答),现在来讲讲为什么不容易,因为要时时刻刻注意以下几点:
1.批处理动态物体需要在每个顶点上进行一定的开销,所以动态批处理仅支持小于900顶点的网格物体,如果你的着色器使用顶点位置,法线和UV值三种属性,那么你只能批处理300顶点以下的物体;请注意:属性数量的限制可能会在将来进行改变。
2.(1)所有统一缩放的物体但是尺度不一样的不会进行批处理,比如(1,1,1)尺度为1,(2,2,2)尺度为2,(n,n,n)尺度为n在一起不会进行批处理,如图所示:
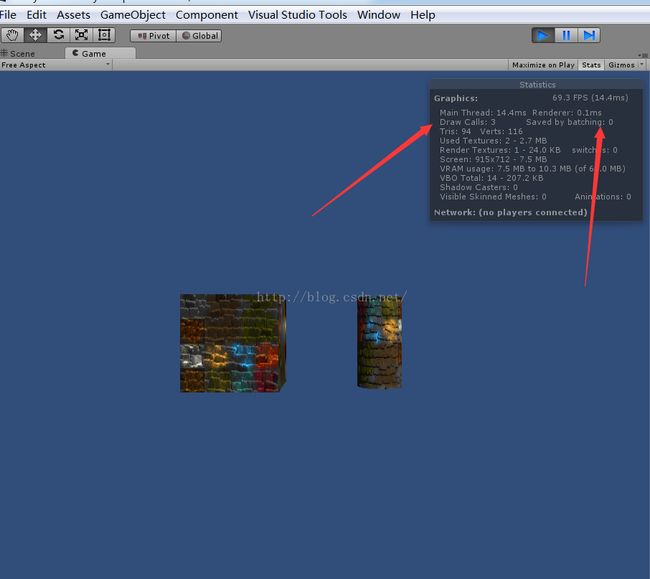
但是统一缩放的尺度一样的就会进行动态批处理,比如都是(1,1,1)尺度为1,或者都是(2,2,2)尺度为2,或都是(n,n,n)尺度为n的能进行动态批处理,如下图所示:
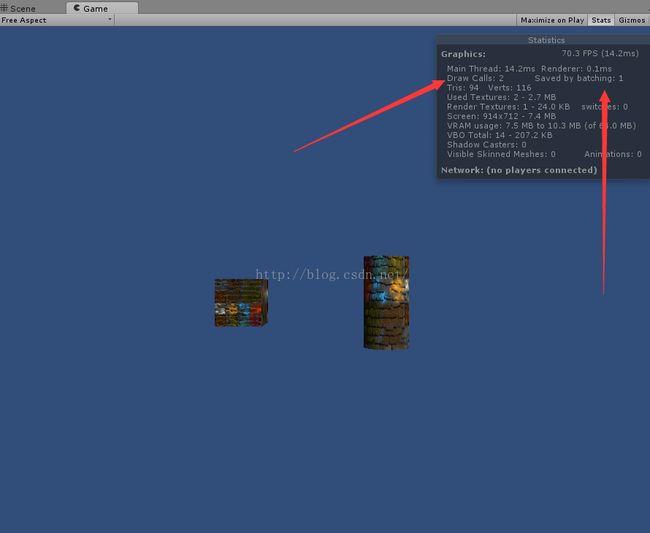
这块好多人都没讲明白,希望这里可以解惑大多数还处在迷惑的小鸟!还有一点就是统一缩放有些新手不懂,就比如基于(1,1,1),如果想x,y,z,缩放相同的倍数就是统一缩放,如(2,2,2,)就是统一缩放。有一点让我感到很奇怪的要说明下,Unity自带的球体和胶囊体在我测试下貌似不会动态批处理,结果我又测试了下从3dMax下导入球体和胶囊体也不会进行动态批处理。其实这点还有待考证!
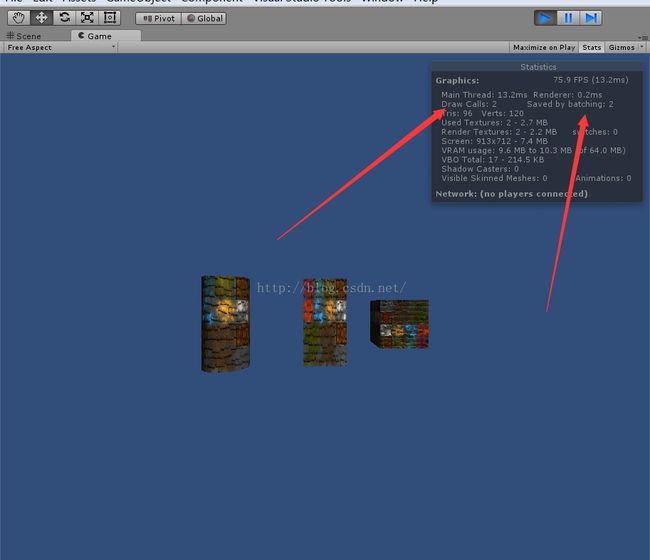
(2)统一缩放的物体不会与非统一缩放的物体进行批处理,比如(1,1,1)和(1,2,2)就不会动态批处理,如下图所示:

那比如三个物体,(1,1,1),(1,1,1),(1,2,2),虽然统一缩放的物体不会与非统一缩放的物体进行批处理,但是不会影响其中能批处理的物理,但但是这里的(1,1,1)和(1,1,1)却受到会影响,不会进行批处理,如图所示:

- 你会看到两条红线所指的物体就没被批处理!!!!!!!这是大部分网上绝大部分文章所没涉及的内容。
- 但你放四个物体(1,1,1),(1,1,1),(1,1,1),(1,2,2),你又会发现,居然节省了一个DC,尼玛,坑!
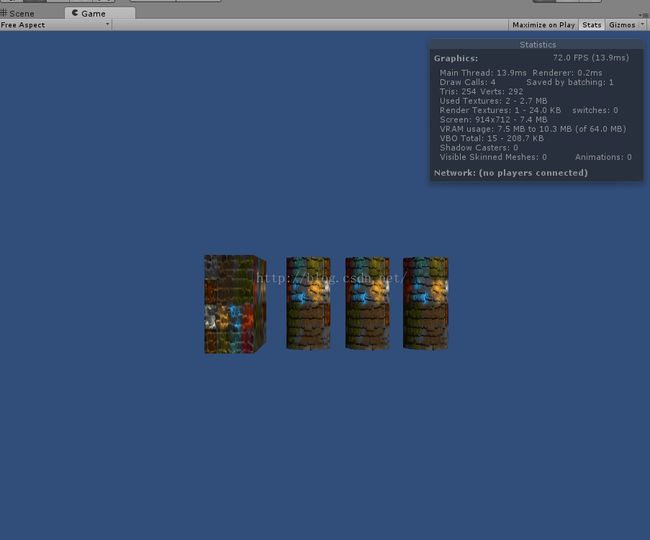

- 能用动态批处理就尽量用动态批处理,但是请小心上面提到的各种注意事项。
- 当使用静态批处理,得时刻小心对内存的消耗。
- 对于游戏中的小道具,例如可以捡拾的武器,药水等,可以使用动态批处理。
- 对于包含动画的这类物体,我们无法全部使用静态批处理,但其中如果有不动的部分,可以把这部分标识成“Static”,使用静态批处理!
(1)、在平行光和区域光的照射下(Render Mode为任何情况下)DC为2;
(2)、在点光源和聚光灯的照射下(Render Mode 为Important和Auto情况下)DC为6,也就是四个物体被再照射一次,且再次照射后的物体静态批处理失效。