周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =。这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark SQL相关的知识,如果对Spark不熟的同学可以先看看之前总结的两篇文章:
【原】Learning Spark (Python版) 学习笔记(一)----RDD 基本概念与命令
【原】Learning Spark (Python版) 学习笔记(二)----键值对、数据读取与保存、共享特性
########################################我是正文分割线######################################
第七章主要讲了Spark的运行架构以及在集群上的配置,这部分文字比较多,可能会比较枯燥,主要是讲整个过程是怎么运行的。首先我们来了解一下Spark在分布式环境中的架构,如图1 所示

图1 Spark分布式结构图
如上图所示,在Spark集群中有一个节点负责中央协调,调度各个分布式工作节点。这个中央协调点叫“驱动器节点(Driver)”,与之对应的工作节点叫“执行器节点(executor)”。驱动器节点和所有的执行器节点被称为一个Spark应用(Application)。Spark应用通过一个“集群管理器(Cluster Manager)”的外部服务在集群中的机器上启动,其中它自带的集群管理器叫“独立集群管理器”。
驱动器节点:
作用
- 执行程序中的main()方法的进程,一旦终止,Spark应用也终止了。
职责
- 把用户程序转化为任务
- 用户输入数据,创建了一系列RDD,再使用Transformation操作生成新的RDD,最后启动Action操作存储RDD中的数据,由此构成了一个有向无环图(DAG)。当Drive启动时,Spark会执行这些命令,并转为一系列stage(步骤)来操作。在这些步骤中,包含了多个task(任务),这些task被打包送到集群中,就可以进行分布式的运算了,是不是像流水线上的工人呢~
- 为执行器节点调度任务:
- Driver启动后,必须在各执行器进程间协调各个任务。执行器进程启动后会在Driver上注册自己的节点,这样Driver就有所有执行器节点的完整记录了。每个执行器节点代表一个能够处理任务和存储RDD数据的进程。Spark会根据当前任务的执行器节点集合,尝试把所有的任务基于数据所在的位置分配给合适的执行器进程。当我们的任务执行时,执行器进程会把缓存数据存储起来,而驱动器进程同样也会跟踪这些缓存数据的任务,并利用这些位置信息来调度以后的任务,以尽量减少数据的网络传输。
执行器节点:
作用:
- 负责在Spark作业中运行任务,各个任务间相互独立。Spark启动应用时,执行器节点就被同时启动,并一直持续到Spark应用结束。
职责:
- 负责运行组成Spark应用的任务,并将结果返回给驱动器程序。
- 通过自身的块管理器(Block Manager)为用户程序中要求缓存的RDD提供内存式存储。RDD是直接缓存在执行器进程里的,所以可以在运行时充分利用缓存数据提高运算速度。
集群管理器:
在图一中我们看到,Spark依赖于集群管理器来启动执行器节点,而在某些特殊情况下,也会依赖集群管理器来启动驱动器节点。Spark有自带的独立集群管理器,也可以运行在其他外部集群管理器上,如YARN和Mesos等。下面讲一下两种比较常见的外部集群管理器:
独立集群管理器:
1.启动独立集群管理器
2.提交应用:spark-submit --master spark://masternode:7077 yourapp
支持两种部署模式:客户端模式和集群模式
3.配置资源用量:在多个应用间共享Spark集群时,通过以下两个设置来对执行器进程分配资源:
3.1 执行器进程内存:可以通过spark-submit中的 --executor-memory 参数来配置。每个应用在每个工作节点上最多拥有一个执行器进程。因此这个这个能够控制 执行器节点占用工作节点多少内存。默认值是1G。
3.2 占用核心总数的最大值:可以通过spark-submit中的 --total -executorcores 参数来设置。
Hadoop YARN:
1.提交应用:设置指向你的Hadoop配置目录的环境变量,然后使用spark-submit 向一个特殊的主节点URL提交作业即可。
2.配置资源用量:
- --num -executors :设置执行器节点,默认值为2
- --executor -memory: 设置每个执行器的内存用量
- --executor -cores: 设置每个执行器进程从YARN中占用的核心数目
- --queue:设置队列名称,YARN可以将应用调度到多个队列中。
Apache Mesos:
1.提交应用:spark-submit --master mesos://masternode:5050 your app
2.Mesos调度模式:两种:
- 细粒度模式:默认模式。一台运行了多个执行器进程的机器可以动态共享CPU资源
- 粗粒度模式:Spark为每个执行器分配固定数量的CPU数目,并且在应用结束前不会释放该资源,即使执行器进程当前没有运行任务(多浪费啊 = =)。可以通过spark-submit 传递 --conf spark.mesos.coarse=true 来打开粗粒度模式
3.部署模式:仅支持以客户端的部署模式运行应用,即驱动器程序必须运行提交应用的那台机器上。
4.配置资源用量:
- --executor -memory:设置每个执行器进程的内存
- --total -executor -cores :设置应用占用的核心数(所有执行器节点占用的总数)的最大值。如果不设置该值,Mesos可能会使用急群众所有可用的核心。
选择合适的集群管理器:
1.一般情况下,可以直接选择独立集群模式,功能全,而且简单。
2.如果要在使用Spark的同时使用其他应用,可以选择YARN或Mesos。而且大多数版本的Hadoop中已经预装好YARN了,非常方便。
3.对于多用户同事运行交互式shell时,可以选择Mesos(选择细粒度模式),这种模式可以将Spark-shell这样的交互式应用中的不同命令分配到不同的CPU上。
4.任何时候,最好把Spark运行在运行HDFS的节点上,可以快速访问存储。
提交应用:
使用spark-submit脚本提交应用,可以根据不同的情况设置成在本地运行和在集群运行等:
- 本地模式:bin/spark-submit (--local) my_script.py
(lcoal可以省略)
- 集群模式:bin/spark-submit --master spark://host:7077 --executor-memory 10g my_script.py
(--master标记要连接的集群的URL)
总结一下Spark在集群上的运行过程:
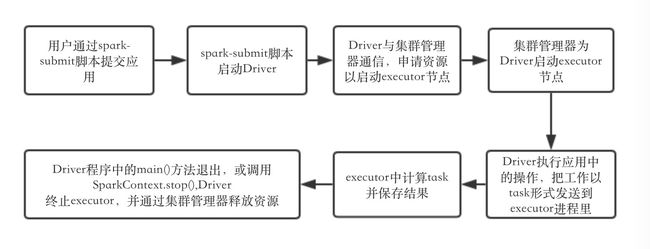
#########################################我是看累了休息会儿的分割线##############################
前面已经讲完了Spark的运行过程,包括本地和集群上的。现在我们来讲讲Spark的调优与调试。
我们知道,Spark执行一个应用时,由作业、任务和步骤组成。先回顾一下:
任务:Spark的最小工作单位
步骤:由多个任务组成
作业:由一个或多个作业组成
在第一篇中我们也讲过,当我们创建转化(Transformation)RDD时,是执行"Lazy"(惰性)计算的,只有当出现Action操作时才会触发真正的计算。而Action操作是如何调用Transformation计算的呢?实际上,Spark调度器会创建出用于计算Action操作的RDD物理执行计划,当它从最终被调用Action操作的RDD时,向上回溯所有必需计算的RDD。调度器会访问RDD的父节点、父节点的父节点,以此类推,递归向上生成计算所有必要的祖先RDD的物理计划。
然而,当调度器图与执行步骤的对应关系并不一定是一对一的。当RDD不需要混洗数据就可以从父节点计算出来,RDD不需要混洗数据就可以从父节点计算出来,或把多个RDD合并到一个步骤中时,调度器就会自动进行进行"流水线执行"(pipeline)。例如下图中,尽管有很多级父RDD,但从缩进来看,只有两个步骤,说明物理执行只需要两个步骤。因为这个执行序列中有几个连续的筛选和映射操作,所以才会出现流水线执行。
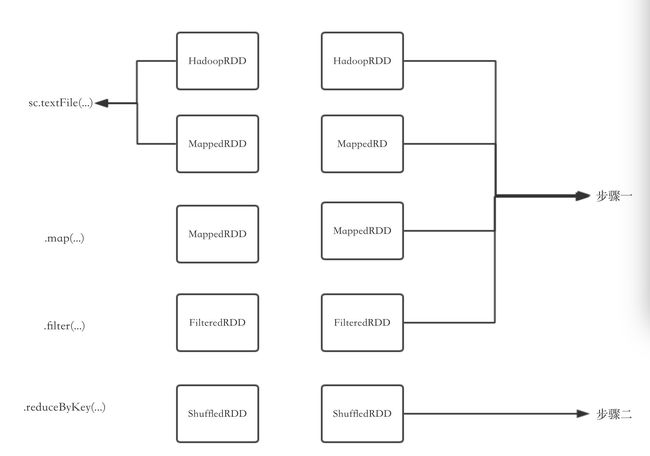
当步骤图确定下来后,任务就会被创建出来并发给内部的调度器,这些步骤会以特定的顺序执行。一个物理步骤会启动很多任务,每个任务都是在不同的数据分区上做同样的事情,任务内部的流程是一样的,如下所示:
1.从数据存储(输入RDD)或已有RDD(已缓存的RDD)或数据混洗的输出中获取输入数据
2.执行必要的操作来计算RDD。
3.把输出写到一个数据混洗文件中,写入外部存储,或是发挥驱动器程序。
总结一下,Spark执行的流程:
- 用户定义RDD的有向无环图(DAG):RDD上的操作会创建出新的RDD,并引用它们的父节点,这样就创建出了一个图。
- Action操作把有向无环图强制转译为执行计划:Spark调度器提交一个作业来计算所必要的RD,这个作业包含一个或多个步骤,每个步骤就是一些并行执行的计算任务。一个步骤对应有向无环图中的一个或多个RDD(其中对应多个RDD是在"流水线执行"中发生的)
- 在集群中调度并执行任务:步骤是按顺序处理的,任务则独立启动来计算RDD的一部分。当作业的最后一个步骤结束时,一个Action操作也执行完了。
Spark调优
到这里我们已经基本了解Spark的内部工作原理了,那么在哪些地方可以进行调优呢?有以下四个方面:
并行度
- 影响性能的两个方面
- a.并行度过低时,会出现资源限制的情况。此时可以提高并行度来充分利用更多的计算core。
- b.并行度过高时,每个分区产生的间接开销累计起来会更大。评价并行度是否过高可以看你的任务是不是在瞬间(毫秒级)完成的,或者任务是不是没有读写任何数据。
- 调优方法
- 在数据混洗操作时,对混洗后的RDD设定参数制定并行度
- 对于任何已有的RDD进行重新分区来获取更多/更少的分区数。重新分区:repartition();减少分区:coalesce(),比repartition()更高效。
序列化格式
当Spark需要通过网络传输数据,或者将数据溢出写到磁盘上时(默认存储方式是内存存储),Spark需要数据序列化为二进制格式。默认情况下,使用Java内建的序列化库。当然,也支持使用第三方序列化库Kryo,比Java序列化时间更短,并且有更高压缩比的二进制表示。但有一点需要注意:Kryo不能序列化全部类型的对象。
内存管理
- RDD存储(60%)
- 调用persisit()或cahe()方法时,RDD的分区会被存储到缓存区中。Spark会根据spark.storage.memoryFraction限制用来缓存的内存占整个JVM堆空间的比例大小。超出限制的话,旧的分区会被移出内存。
- 数据混洗与聚合的缓存区(20%)
- 当数据进行数据混洗时,Spark会创造一些中间缓存区来存储数据混洗的输出数据。根据spark.shuffle.memoryFraction限定这种缓存区占总内存的比例。
- 用户的代码(20%)
- spark可以执行任意代码,所以用户的代码可以申请大量内存,它可以访问JVM堆空间中除了分配给RDD存储和数据混洗存储以外的全部空间。20%是默认情况下的分配比例。不过用户可以自行调节这个比例来提高性能。
当然,除了调整内存比例,也可以改变内存的存储顺序。我们知道,Spark默认的cache()操作是以Memory_ONLY的存储等级持久化数据的,也就是说内存优先。如果RDD分区时的空间不够,旧的分区会直接删除。(妹的删数据也不带打声招呼的 = =!)当用到这些分区时,又会重新进行计算。所以,如果我们用Memory_AND_DISK的存储等级调用persist()方法效果会更好。因为当内存满的时候,放不下的旧分区会被写入磁盘,再用的时候就从磁盘里读取回来,这样比重新计算各分区的消耗要小得多,性能也更稳定(不会动不动报Memory Error了,哈哈)。特别是当RDD从数据库中读取数据的话,最好选择内存+磁盘的存储等级吧。
硬件供给
影响集群规模的主要这几个方面:分配给每个执行器节点的内存大小、每个执行器节点占用的核心数、执行器节点总数、以及用来存储临时数据的本地磁盘数量(在数据混洗使用Memory_AND_DISK的存储等级时,更大的磁盘可以提升Spark的性能哦~)。
##################################我是文章快结束的分割线######################################
最后我们来讲讲Spark SQL,上一篇中我们已经总结了如何使用Spark读取和保存文件,涉及到了这部分内容,所以这一篇中只会简要的说明一下:
导入Spark SQL与简单的查询示例
1 #初始化Spark SQL
2 #导入Spark SQL
3 from pyspark.sql import HiveContext,Row
4 #当不能引入Hive依赖时
5 from pyspark.sql import SQLContext,Row
6 #创建SQL上下文环境
7 hiveCtx = HiveContext(sc)
8 #基本查询示例
9 input = hiveCtx.jsonFile(inputFile)
10 #注册输入的SchemaRDD(SchemaRDD在Spark 1.3版本后已经改为DataFrame)
11 input.registerTempTable("tweets")
12 #依据retweetCount(转发计数)选出推文
13 topTweets = hiveCtx.sql("SELECT text,retweetCount FROM tweets ORDER BY retweetCount LIMIT 10")
缓存
以一种列式存储格式在内存中存储数据。这些缓存下来的表只会在Driver的生命周期内保留在内存中,退出的话就没有了。可以通过cache() 和 uncache()命令来缓存表或者删除已缓存的表。
读取和存储数据
Apache Hive
1 #使用Python从Hive中读取
2 from pyspark.sql import HiveContext
3
4 hiveCtx = HiveContext(sc)
5 rows = hiveCtx.sql("SELECT key,value FROM mytable")
6 keys = rows.map(lambda: row,row[0])
Parquet
1 #Python中的Parquet数据读取
2 #从一个有name和favoriteAnimal字段的Parquet文件中读取数据
3 rows = hiveCtx.parquetFile(parquetFile)
4 names = rows.map(lambda row: row.name)
5 print "Everyone"
6 print names.collect()
7
8 #Python中的Parquet数据查询
9 #这里把Parquet文件注册为Spark SQL的临时表来查询数据
10 #寻找熊猫爱好者
11 tbl = rows.registerTempTable("people")
12 pandaFriends = hiveCtx.sql("SELECT name FROM people WHERE favouriteAnimal = \"panda\"")
13 print "Panda friends"
14 print pandaFriends.map(lambda row:row.name).collect()
15
16 #使用saveAsParquetFile()保存文件
17 pandaFriends.saveAsParqueFile("hdfs://")
JSON
1 #在python中读取JSON数据 2 input= hiveCtx.jsonFile(inputFile)
使用BeeLine
创建、列举、查询Hive表
用户自定义函数(UDF)
1 #Python版本的字符串长度UDF
2 hiveCtx.registerFuction("strLenPython",lambda x :len(x),IntegerType())
3 LengthSchemaRDD = hiveCtx.sql("SELECT strLenPython('text') FROM tweets LIMIT 10")
Spark SQL性能
Spark SQL在缓存数据时,使用的是内存式的列式存储,即Parquet格式,不仅节约了缓存时间,而且尽可能的减少了后续查询中针对某几个字段时的数据读取。
性能调优选项
| 选项 | 默认值 | 用途 |
| spark.sql.codegen | false | 设为True时,Spark SQL会把每条查询语句在运行时编译为Java二进制代码。这可以提高大型查询的性能,但在小规模查询时会变慢 |
| spark.sql.inMemoryColumnarStorage.compressed | false | 自动对内存中的列式存储进行压缩 |
| spark.sql.inMemoryColumnarStorage.batchSize | 1000 | 列式缓存时的每个批处理的大小。把这个值调大可能会导致内存不够的异常 |
| spark.sql.parquet.compression.codec | snappy | 选择不同的压缩编码器。可选项包括uncompressed/snappy/gzip/lzo |
到这里,第七章-第九章的内容就全部总结完了,看完之后会对Spark的运行过程,性能调优以及存储格式等有一个更清晰的概念。下一篇是最后一篇,5.15更新,主要讲Spark Streaming和Spark MLlib机器学习的内容。顺便也可以和PySpark做机器学习做一下对比:D