机器学习之网络爬虫
在进行爬虫实验时,我们通常需要模拟浏览器访问目标网站,从而download下我们需要的一些资源。这时候我们需要了解一些网页前端的知识,结合我们常用的Chrome浏览器,这里进行一点简单的总结:
- Chrome开发者工具
直接在目标网页按下F12或鼠标右键查看网页源码即可进入以下界面

通常使用较多的四个功能页面是:
元素(ELements)
主要用于查看或修改HTML元素的属性、CSS属性、监听事件、断点等。点击左上角箭头(或用者用快捷键Ctrl+Shift+C)进入选择元素模式,然后从页面中选择需要查看的元素,然后可以在开发者工具元素(Elements)一栏中定位到该元素源代码的具体位置 。查看元素属性:可从被定位的源码中查看部分,如class、src,也可在右边的侧栏中查看全部的属性,如下图位置查看!可参考https://wangdoc.com/html/text.html。

可以直接定位网页对应的代码,若想要修改元素的代码和属性,只需直接双击该部分或右键选择修改即可。这种修改仅仅对当前的页面渲染生效,但是不会修改服务器上的源码,故该功能多用于页面调试使用。
控制台(Console)
控制台一般用于执行一次性代码,查看JavaScript对象,查看调试日志信息或异常信息。而当网页的JS代码中使用了console.log()函数时,该函数输出的日志信息会在控制台中显示。日志信息一般在开发调试时启用,而当正式上线后,一般会将该函数去掉。

源代码(Sources)
该页面用于查看页面的HTML文件源代码、JavaScript源代码、CSS源代码,此外最重要的是可以调试JavaScript源代码,可以给JS代码添加断点等。

网络(Network)
网络页面主要用于查看header等与网络连接相关的信息。
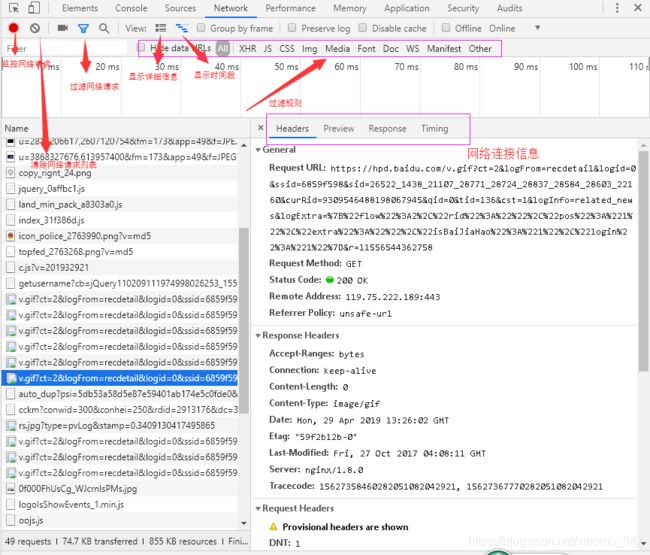
其中网络连接信息包括四个模块,
- Header:面板列出资源的请求url、HTTP方法、响应状态码、请求头和响应头及它们各自的值、请求参数等等。
- Preview:预览面板,用于资源的预览。
- Response:响应信息面板包含资源还未进行格式处理的内容。
- Timing:资源请求的详细信息花费时间。
2、网络爬虫小试
(1)爬虫定义:网络爬虫(Web Spider),是以一种自动化搜集数据的小工具,利用网页地址(URL)向网站发起请求,通过分析并提取目标资源数据,从而实现对制定的网页内容的爬取。
URL:统一资源定位符(也称网页地址),如https://www.baidu.com/,就是我们在浏览器中输入的网站链接。
(2)原理
原理就是通过给定的一个 URL请求,去访问获取目标网页的源代码,再对源码进行一些处理而得到目标数据,最后再将这些数据保存下来的一套数据处理过程。常见的对源码处理方法有json库,BeautifulSoup库,正则表达式等。学习爬虫最重要的是,学习它的原理,万变不离其宗。
(3)常见的类型
①通用网络爬虫(General Purpose Web Crawler),爬取的目标资源是全互联网,范围是非常大的,对爬取的性能要求是非常高的,主要应用于大型搜索引擎中,有非常高的应用价值。通用网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等构成。通用网络爬虫在爬行的时候会采取一定的爬行策略,主要有深度优先爬行策略和广度优先爬行策略。
②聚焦网络爬虫(Focused Crawler),即按照预先定义好的主题有选择地进行网页爬取,其范围在与主题相关的页面中,可以满足一些有针对性的资源提取。主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块可以评价内容的重要性,同理,链接评价模块也可以评价出链接的重要性,然后根据链接和内容的重要性,可以确定哪些页面优先访问。聚焦网络爬虫的爬行策略主要有4种,即基于内容评价的爬行策略、基于链接评价的爬行策略、基于增强学习的爬行策略和基于语境图的爬行策略。
③增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。增量式更新指的是在更新的时候只更新改变的地方,而未改变的地方则不更新,所以增量式网络爬虫,在爬取网页的时候,只爬取内容发生变化的网页或者新产生的网页,对于未发生内容变化的网页,则不会爬取。增量式网络爬虫在一定程度上能够保证所爬取的页面,尽可能是新页面。
④深层网络爬虫(Deep Web Crawler),在互联网中,网页按存在方式分类,可以分为表层页面和深层页面。
表层网页:不需要提交表单,使用静态的链接就能够到达的静态网页
深层网页:隐藏在表单后面,不能通过静态链接直接获得,是需要提交一定的关键词之后才能够获取得到的网页。
深层网络爬虫最重要的部分即为表单填写部分
深层网络爬虫的基本构成:URL列表,LVS列表(LVS指的是标签/数值集合,即填充表单的数据源)爬行控制器,解析器,LVS控制器,表单分析器,表单处理器,响应分析器等。
(4)爬虫的一般流程
分析爬取的网站结构(URL分析、页面组成分析、源码分析)https://blog.csdn.net/wenxuhonghe/article/details/84897936
发送请求---》获取响应内容---》解析内容---》保存数据
#1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
#2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
#3、解析内容
解析html数据:正则表达式,第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以b的方式写入文件
#4、保存数据
存储在数据库或文件中。
(5)常见的爬虫框架
常见的爬虫框架有Scrapy、PySpider、Crawley、Beautiful Soup等,具体的可以参考这篇博客https://blog.csdn.net/sinat_38682860/article/details/81044027
示例:
test1使用爬虫爬去汇图网上某类数据集示例:
import requests
from bs4 import BeautifulSoup
def getHtml(url):
header = { # 'content-type': 'application/json',
# 'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
try:
html=requests.get(url,headers=header)
print(html.status_code)
html.encoding=html.apparent_encoding
html.raise_for_status()
return html.text
except:
return " "
def parseHtml(html,num):
soup=BeautifulSoup(html,'html.parser')
cnt=1
try:
cont1=soup.select('div.seozone > a')
for cnt,i in enumerate(cont1):
print("正在爬取第%d页,第%d张图片"%(num,cnt))
with open('./new_data//'+str(num)+'_'+str(cnt)+'.jpg','wb') as f:
data=requests.get(i.img.attrs['originalsrc']).content
f.write(data)
except:
pass
if __name__=='__main__':
word = input("请输入关键字:")
for num in range(1,100):
url = "http://soso.huitu.com/search?kw={}&ds={}".format(word,num)
html=getHtml(url)
content=parseHtml(html,num)test2爬取百度上的图片
from urllib.parse import urlencode
import requests
import re
import os
save_dir = 'data/'
def baidtu_uncomplie(url):
res = ''
c = ['_z2C$q', '_z&e3B', 'AzdH3F']
d = {'w': 'a', 'k': 'b', 'v': 'c', '1': 'd', 'j': 'e', 'u': 'f', '2': 'g', 'i': 'h', 't': 'i', '3': 'j', 'h': 'k',
's': 'l', '4': 'm', 'g': 'n', '5': 'o', 'r': 'p', 'q': 'q', '6': 'r', 'f': 's', 'p': 't', '7': 'u', 'e': 'v',
'o': 'w', '8': '1', 'd': '2', 'n': '3', '9': '4', 'c': '5', 'm': '6', '0': '7', 'b': '8', 'l': '9', 'a': '0',
'_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/'}
if (url == None or 'http' in url):
return url
else:
j = url
for m in c:
j = j.replace(m, d[m])
for char in j:
if re.match('^[a-w\d]+$', char):
char = d[char]
res = res + char
return res
def get_page(offset,keyword):
params = {
'tn': 'resultjson_com',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': keyword,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '0',
'word': keyword,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'pn': offset *40,
'rn': '40',
'gsm': '1e',
'1537355234668': '',
}
url = 'https://image.baidu.com/search/acjson?' + urlencode(params)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
def get_images(json):
if json.get('data'):
for item in json.get('data'):
if item.get('fromPageTitle'):
title = item.get('fromPageTitle')
else:
title = 'noTitle'
image = baidtu_uncomplie(item.get('objURL'))
if (image):
yield {
'image': image,
'title': title
}
def save_image(item, count):
try:
response = requests.get(item.get('image'))
#import pdb;pdb.set_trace()
if response.status_code == 200:
file_path = save_dir + '{0}.{1}'.format(str(count), 'jpg')
if not os.path.exists(file_path):
with open(file_path, 'wb') as f:
f.write(response.content)
else:
print('Already Downloaded', file_path)
except requests.ConnectionError:
print('Failed to Save Image')
def main(pageIndex, count,keyword):
json = get_page(pageIndex,keyword)
for image in get_images(json):
#print("该页面第%d张图"%count)
save_image(image, count)
count += 1
return count
if __name__ == '__main__':
if not os.path.exists(save_dir):
os.mkdir(save_dir)
count = 1
keyword = input("请输入关键字:")
for i in range(1, 6):
count = main(i, count,keyword)
print('total:', count)test3爬取全景视觉网
import requests
import re
import os
import time
robot='./new_data/'
kv={'user-agent':'Mozilla/5.0'}
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ''
def parseHTML(html):
pattern=r'"imgurl":"(.*?)"'
reg=re.compile(pattern)
urls=reg.findall(html)
return urls
def getmoreURL(word,num):
more_urls=[]
url='http://search.quanjing.com/search?key={word}&pageSize=200&pageNum={num}&imageType=2&sortType=1&callback=searchresult'
for i in range(1,num+1):
more_url=url.format(word=word,num=i)
more_urls.append(more_url)
return more_urls
def download(urls):
for url in urls:
try:
r=requests.get(url,timeout=30,headers=kv)
r.raise_for_status()
path=robot+url.split('/')[-2]+url.split('/')[-1]
if not os.path.exists(robot):
os.makedirs(robot)
if not os.path.exists(path):
with open(path,'wb') as f:
f.write(r.content)
f.close()
print(path+'保存成功')
else:
print('文件已存在')
except:
continue
def main():
word=input('输入搜索标题:')
num=int(input('输入搜索页数:'))
urls=getmoreURL(word,num)
for url in urls:
html=getHTMLText(url)
imgurls=parseHTML(html)
download(imgurls)
time.sleep(3)
main()test4爬取电影天堂电影
import requests
import bs4
import re
import pandas as pd
#####负责访问指定的 url 网页,并将网页的内容返回
def get_data(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
#####网页解析函数
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取表头信息
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
name = link["title"]
url = 'https://www.dy2018.com' + link["href"]
try:
# 查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('tbody')
for i in tbody:
download = i.a.text
if 'magnet:?xt=urn:btih' in download: ####去除无效的链接
movie.append(name)
movie.append(url)
movie.append(download)
#print(movie)
info.append(movie)
break
except Exception as e:
print(e)
return info
####数据存储函数
def save_data(data):
'''
功能:将 data 中的信息输出到文件中/或数据库中。
参数:data 将要保存的数据
'''
filename = 'Data/电影天堂/动作片.csv'
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename, mode='a', index=False, sep=',', header=False)
#####爬虫调度器
def main():
# 循环爬取多页数据
for page in range(1, 114):
print('正在爬取:第' + str(page) + '页......')
# 根据之前分析的 URL 的组成结构,构造新的 url
if page == 1:
index = 'index'
else:
index = 'index_' + str(page)
url = 'https://www.dy2018.com/2/'+ index +'.html'
# 依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据
html = get_data(url)
movies = parse_data(html)
save_data(movies)
print('第' + str(page) + '页完成!')
####主函数
if __name__ == '__main__':
print('爬虫启动成功!')
main()
print('爬虫执行完毕!')
由于一些网站长期会维护,反扒技术也在迭代更新中,上面的例子可能过一段时间就需要做一定优化才能实现成功爬取了,此消彼长,还是要好好学会爬虫的精髓才行!
参考链接:
https://blog.csdn.net/m0_37724356/article/details/79884006
https://juejin.im/entry/58c235d9570c35005823142b
爬虫: https://www.cnblogs.com/jokerbj/p/8254761.html
https://blog.csdn.net/hz_zdeveloper/article/details/70172898
https://blog.csdn.net/wenxuhonghe/article/details/84897936
https://blog.csdn.net/u012662731/article/details/78537432
https://blog.51cto.com/11623741/2097160
https://blog.csdn.net/mingzhiqing/article/details/82778954