语言模型(二) 评估和类别
一、Evaluation
1、 熵 entropy
l 熵(entropy)又称自信息,self-information
描述一个随机变量的不确定性的数量,熵越大,不确定性越大,正确估计其值的可能性越小。越不确定的随机变量越需要大的信息量以确定其值。

p(x)表示x的分布概率
l 相对熵(relativeentropy)又称KL距离,Kullback-Leibler divergence
衡量相同事件空间里两个概率分布相对差距的测度,当p=q的时候,相对熵为0,当p和q差距变大时,交叉熵也变大。
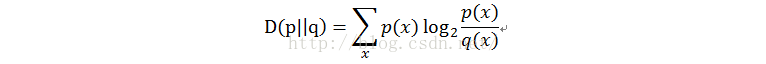
p(x)和q(x)代表x的两种概率分布
l 交叉熵(crossentropy)
衡量估计模型和真实概率分布之间的差异
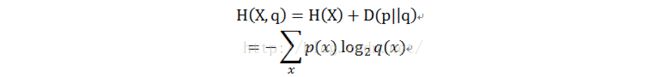
定义语言L=(Xi)~p(x)与其模型q的交叉熵为:

表示L的语句(应该表示一句话),q(x)表示估计模型,由于无法获取真实模型的概率,需要作出一个假设:假定L是稳态遍历的随机过程,即当n无穷大的时候,所有句子的概率和为1。

2、 困惑度perplexity
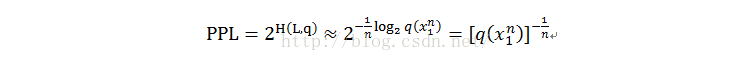
相比如交叉熵的优势在于:
交叉熵的值在6.6位和7.64位之间,对应的ppl在100到200之间,ppl值更容易记。
交叉熵下降2%,对应于Ppl值10%的提升,描述同样的提升,ppl的数值更漂亮。
最重要的一点是,ppl更容易计算,最小的ppl值意味着训练的模型最接近真实模型。
劣势在于:
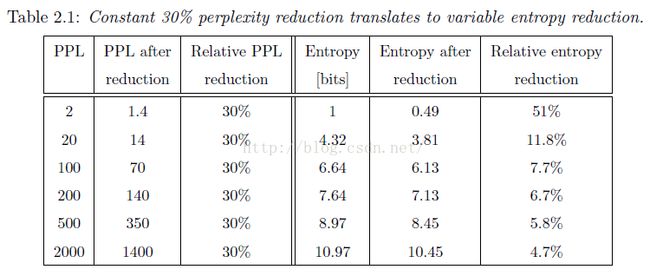
Ppl适合直接比较两个模型,交叉熵适合描述一个模型的提升。在描述模型的提升的时候,通常使用相比于基线降低的相对百分比,如下图:
3、 字错误率 worderror rate
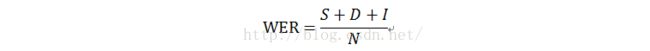
S表示替换个数,D表示删除个数,I表示插入个数,N表示reference中字的个数。
WER通常用在语音识别结果的评估上面,有标准答案,适合比较,缺点就是过于死板,没有同义词的容错机制。
适合用于同一个任务的不同技术比较,不适合在不同系统不同技术之间的对比。
二、N-gram model
影响n-gram模型性能最重要的两点是阶数和平滑。其中KN平滑算法性能最佳。
n-gram最大的优势在于速度和可靠性,计算简单。
局限性有以下几点:
跨领域的脆弱性——不同领域的语言使用规律不同
独立性假设的无效性——n-gram假设当前词只和前n-1个词有关
语言模型规模——随着阶数的增加,n-gram会呈指数型增长,所以无法使用高阶数的语言模型。基于神经网络的LM可以解决该问题。
语言模型面临两个问题如下:
1、 高阶问题
THE SKY ABOVE OUR HEADS IS BLUE
如果要刻画BLUE和SKY之间的联系,需要6gram的语言模型,将导致语言模型过大。
2、 相似词问题
PARTY WILL BE ON
由于训练语料的问题,可能导致Friday的概率明显高于Monday。
三、其他语言模型
1、 Cache LM
在文本中刚刚出现的一些词在后面的句子中再次出现的可能性较大。通过原始n-gram的概率和cache的n-gram概率的线性插值,获得最终的概率。
优势在于可以降低PPL值,劣势在于PPL值降低的同时WER会升高,原因在于识别结果错误的时候会形成错误的反馈。
2、 Class based LM
当训练数据量小时候,为了解决数据稀疏,可以引入classes,然后根据classes训练gram。
该类语言模型的难点在于高的计算复杂度和如何构造class。
3、 Structured LM
在一个句子中的相关词,可能没有出现在临近的位置。Structured LM将句子看做一种树结构,叶子代表词,节点代表连接符号。
4、 Decision Trees andRandomForestLM
使用决策树通过问问题的方式构建LM,但是很难找到好的决策树。计算复杂度较高,在某种程度上面类似于class based LM。
5、 Maximum Entropy LM
将来自不同信息源的语言模型进行结合(类似于插值),获得更好的语言模型。
6、 Neural Network LM
Frederick Jelinek: "Every time I _re alinguist out of my group, the accuracy goes up."
7、 NNLM
训练trick:
每次训练句子随机化,可以减少训练的epoch。
学习率,当提升明显的时候,学习率保持不变,当没有明显提升的时候,学习率减半。
权重矩阵初始化为均值为0、方差为0.1的随机数分布。
参考文献:
《statistic language models based on neural networks》
http://www.fit.vutbr.cz/~imikolov/rnnlm/thesis.pdf
《统计自然语言处理》宗成庆