flume-kafka- spark streaming(pyspark) - redis 实时日志收集实时计算
鉴于实在是比较少python相关是spark streaming的例子,对于自己实现的测试例子分享上来一起讨论。另外如果做spark streaming应用程序,强烈建议使用scala,python写日常的spark批处理程序还好
这个例子为一个简单的收集hive的元数据日志,监控各个hive客户端访问表的统计。例子简单,但是涉及到不同的组件的应用,结构图(不含红色方框)如下
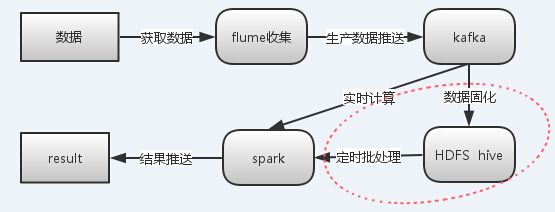
这也是Linkedln技术高管Jay Kreps:Lambda架构剖析中指的架构的一种实现,据了解很多公司也是按照这一套来走,具体在应用上也会灵活选用。
在实际应用中会有个疑惑:不管是写入hdfs还是利用streaming读取数据,flume或者kafka都能独立实现,包括负载均衡容错,那么为什么要两个一起上。下面是一些个人的总结,归根结底就是方便,方便用方便管
在应用上 flume 1、配置简单不用自己开发 2、可直接拦截屏蔽数据 3、通过channel对数据进行分发
kafka 1、支持副本事件 2、topic可以被重复使用,是一个非常通用的系统
架构上flume提供一个管道流和数据分发的功能,收集数据后能够将数据分发到不同的系统中,
如同一份数据同时写入hdfs和kafka,这样就没有必要自己实现自己的消费者。
kafka则作为一个兼容且高可靠平台存储一段时间内的数据flume
flume作为一个日志收集组件,可以简单的通过配置化文档将不同源的数据写入到类似hdfs、kafka等目标。有些时候flume未必能解决数据源整合的问题,就像日志重复这个问题。可以根据需要选择其他东西,比如统一将所有日志都按照一定格式写到redis上去,后台另起服务不断地拉取数据到kafka,甚至直接从业务代码上不断往kafka写数据,相对来说flume感觉可能更适合做一些离线的非实时数据的收集。
这里采用的是单机模式直接用exec监控日志文件,并将日志发送到kafka上,topic为mytopic。下面是其配置文件
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.channels = c1
a1.sources.r1.command = tail -F /var/log/hive/hadoop-cmf-hive1-HIVEMETASTORE-master.log.out
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#使用内置的过滤器regex_filter
a1.sources.r1.interceptors= i1
a1.sources.r1.interceptors.i1.type= regex_filter
a1.sources.r1.interceptors.i1.regex= .*HiveMetaStore\\.audit.*
a1.sources.r1.interceptors.i1.excludeEvents = false
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = mytopic
a1.sinks.k1.brokerList = 10.10.10.230:9092
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.batchSize = 20
a1.sinks.k1.serializer.class=kafka.serializer.StringEncoder
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1运行语句脚本为:nohup bin/flume-ng agent --conf conf/ -f conf/hive_log.conf -n a1 &
其中hive_log.conf为上面的配置文件,注意在这之前需要启用kafka
kafka
kafka消息收集与订阅,这里kafka只起到一个暂时存储数据及记录消费者对数据消费的偏移量。
简单启动
1、启用自带zookeeper,这里也可以指定到已有的zookeeper集群
2、启用broker服务,可使用jps查看获取启动情况
具体操作可以参考Kafka单机环境搭建
spark streaming 写入到redis
主要程序逻辑大概是这样:将从kafka获取到的数据进行解析获取ip并统计,最后将结果返回到driver端拼接成json格式,最后直接以rdd执行的时间作为key,结果为value写入redis;后续的应用需要这些数据就从redis取数了。
直接放代码了,注释都尽量写上去了…
#coding=utf8
'''
读取kafka数据 -> 解析 -> 统计 -> 返回driver写入redis
关于redis连接池在集群模式下的处理问题是将特定的连接写到了方法内去调用
已测试local、standalone模式可行
'''
from __future__ import print_function
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka import KafkaUtils
import re
import redis
# 解析日志
def parse(logstring):
regex = '(\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2},\d{3}).*ip=\/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}).*tbl=([a-zA-Z0-9_]+)'
pattern = re.compile(regex)
m1 = pattern.search(str(logstring))
if m1 is not None:
m = m1.groups()
else:
m = None
return m
class RedisClient:
pool = None
def __init__(self):
self.getRedisPool()
def getRedisPool(self):
redisIp='10.10.10.230'
redisPort=6379
redisDB=0
self.pool = redis.ConnectionPool(host=redisIp, port=redisPort, db=redisDB)
return self.pool
def insertRedis(self, key, value):
if self.pool is None:
self.pool = self.getRedisPool()
r = redis.Redis(connection_pool=self.pool)
r.hset('hsip', str(key), value)
if __name__ == '__main__':
zkQuorum = '10.10.10.230:2181'
topic = 'mytopic'
sc = SparkContext(appName="pyspark kafka-streaming-redis")
ssc = StreamingContext(sc, 15)
kvs = KafkaUtils.createStream(ssc, zkQuorum, "kafka-streaming-redis", {topic: 1})
# 利用正则解析日志获取到结果为 (访问时间,访问ip,访问表名)
# kafka读取返回的数据为tuple,长度为2,tuple[1]为实际的数据,tuple[1]的编码为Unicode
# kvs.map(lambda x:x[1]).map(parse).pprint()
# 预处理,如果需要多次计算则使用缓存
ips = kvs.map(lambda line: line[1]).map(lambda x:parse(x)).filter(lambda x:True if x is not None and len(x) == 3 else False).map(lambda ip:(ip[1],1))
ipcount = ips.reduceByKey(lambda a, b: a+b).map(lambda x:x[0]+':'+str(x[1]))
# 传入rdd进行循坏,即用于foreachRdd(insertRedis)
r = RedisClient()
def echo(time,rdd):
if rdd.isEmpty() is False:
rddstr = "{"+','.join(rdd.collect())+"}"
print (str(time)+":"+rddstr)
r.insertRedis(str(time), rddstr)
ipcount.foreachRDD(echo)
# 各节点的rdd的循坏
# wordCounts.foreachRDD(lambda rdd: rdd.foreach(sendRecord))
ssc.start()
ssc.awaitTermination()运行脚本如下
spark-submit --master spark://master:7077 \
--jars spark-streaming-kafka-assembly_2.10-1.5.0.jar \
../kafkatest/kafka-streaming.py对运行结果也打印出到控制台进行查看,结果如下
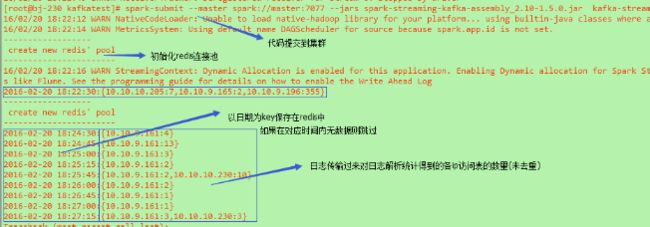
这是一份测试,其目的是打通整个流程,所以很多方面是没有做很细致的考虑,包括ssc程序重启、redis等组件的参数配置读取,以上供参考。