Apollo自动驾驶进阶课(4)——Apollo无人车定位技术
1.无人车自定位系统
1.1自定位系统
无人车的自动定位系统:相对一个坐标系,确定无人车的位置和姿态。
这个坐标系可以是一个局部的坐标系,也可以是一个全局的坐标系,比如全球坐标系,可以知道一个很精确的位置。
位置和姿态有6个自由度。
位置对应X,Y,Z,即相当于某个坐标系的汽车的平移。
姿态是三个方向的一个旋转,一般会用欧拉角来表示。包括横滚、俯仰和航向,分别相对于X,Y,Z三个坐标轴。
如果本地坐标系已经定义好,现在有一个车上的坐标系,它相对于本地坐标系的变化(即姿态的变化),就可用三个角度来表示,也就是本地坐标系的三个轴和相对坐标系的这三个轴之间的夹角。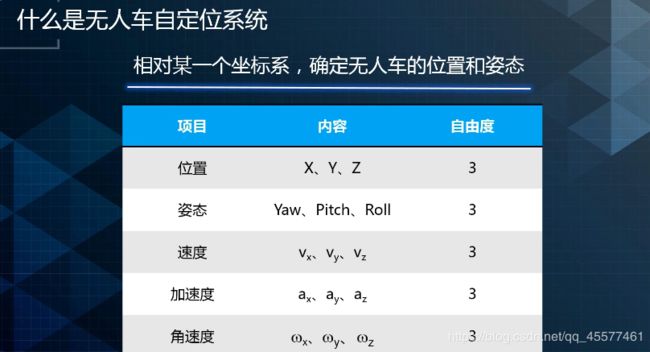
除速度、加速度和角速度外,自定位系统还需要对位置和姿态加上一个置信度,表示这次输出的定位结果好不好。
自动驾驶汽车,定位的指标要求大概分为三个部分:
- 定位精度,误差均值 ,<10cm,才能使行驶中的自动驾驶车辆避免出现碰撞/车道偏离的情况。
- 鲁棒性,最大误差,<30cm。有时纵向误差偏大,只要没有偏离车道就没有太大影响。超过30厘米的误差对前后距离的控制会有很大风险。
- 场景,覆盖场景,全天候, 举例。
场景对应模块是否能够完全地在这些场景当中工作,至关重要。因为L4和L5自动驾驶需要自定位系统在各种场景下面都能够工作。
1.2作用
无人车需要精准的定位系统。
- 定位系统与高精度地图配合提供静态环境感知。
- 定位系统捕捉车辆的速度、加速度、角速度等信息用于路线规划及控制模块。
1.3定位方法
定位的方法大体上可以分为三个部分:
- 基于电子信号的定位,特点是GNSS(全球导航卫星系统),通过一组卫星的伪距、星历、卫星发射时间等观测量,以及用户钟差,得知大概的位置。
- 航迹推算,特点是IMU。航迹推算就是根据上一时刻位置和姿态,叠加一些测量信息可以知道现在的位置和姿态。
惯性导航参考入门课内容 - 环境特征匹配,相对较多。比如LiDAR的匹配,在建好了点云定位的地图,将LIDAR的数据和已建好的地图做匹配,以此来计算位置。或者通过摄像头,知道了一些车道线,红绿灯的标志,然后确定位置。
现在有一些差分的技术,即卫星的实时动态差分技术可以弥补GPS精度低的缺憾。
差分技术分为物理差分和距离差分两种,距离差分又分为伪距差分和载波相位差分。
伪距差分的精度在米级,不能满足要求。因此发展出实时动态的载波相位差分。
载波相位差分最主要的是估计一个载波相位的一个整周,定位精确基本上是在厘米级(小于5厘米)。其优缺点:
- 优点:
高精度;全球、全天候、全天时;。 - 缺点:
基站布设成本高,硬件+人力;
强依赖可视卫星数;
易受电磁环境的干扰;
GNSS信号遮挡引起多径效应。
激光定位
激光定位是预先制作一个地图,把实时的激光点云和这个地图做匹配。
地图可能是3D的Voxel地图、点云地图、2D的概率地图。
2D概率地图是把所有的这个点云数据铺到一块,压成了一个2D地图。2D地图分成很多小格子,每个格子里面存储了颜色信息,位置。位置上面可能只存Z的这个维度,因为2D地图有XY。
另外,还包括一些概率,概率和点云的数量以及分布相关。
举例:选择一个XY化的矩形或者正方形,在每个小格子里面去匹配。这个范围大概是几米乘几米。每个里面会算一个匹配的概率,匹配可能会用实时点云里面的颜色值或者高度值的分部和2D地图去匹配,最后会得到一个概率图。根据该概率图,用加权平均会得到XY的位置。
视觉定位
视觉定位,照明环境变化越大,视觉所受到的影响就越大。
所以基于特征点的定位,比如SLAM里面用Relocalization并不是很合适用于车的视觉定位。因为下次可能检测不到那些特征,比如SIFT特征或者别的特征就会造成定位的失败。
但是有一些特征具有明显Semantic意义,比如车道线或者旁边立的这些柱子,红绿灯的柱子或者红绿灯本身或者一些Traffic Sign之类的,对于定位而言非常有用。
需要包含车道线的信息的高精度地图,把每个线段两个端点拿出来。
在线跑的时候,车上的摄像头会用深度学习的方式检查出这些车道线。车道线也是一段一段的,然后会做匹配。匹配的方法有很多种。
Metric的方式匹配两个线段,考虑一个线段到另一个线段的投影的重合度、两个端点到车距离大小、用这两个匹配的方式来度量匹配优劣。

多传感器融合定位
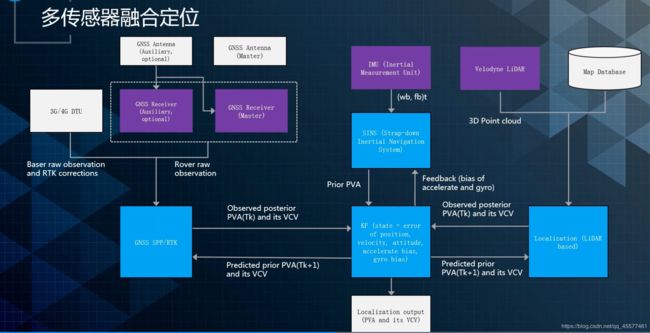
介绍了GNSS定位、激光定位、视觉定位还有惯性导航,这四种定位方式都有各自的特点。如果把它们放到一块就可以做到一个很好的系统——多传感器融合定位。
多传感器融合定位的核心是中间的卡尔曼滤波器,这是一个状态误差的卡尔曼滤波器。
该滤波器接收惯性导航输出的递推,作为它的时间更新,保证滤波器往前走和高频的输出。还接受GPS、激光点云定位,或者是视觉定位的输出去做低频的状态更新。
2.Apollo自动定位技术
2.1三维几何变换
坐标系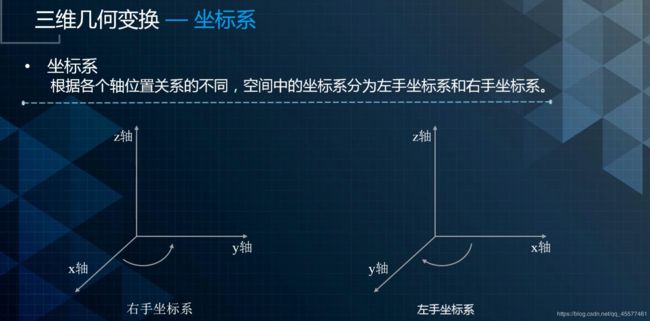
旋转
旋转是指在一个坐标系下,把一个点旋转到另一个位置的几何变换。
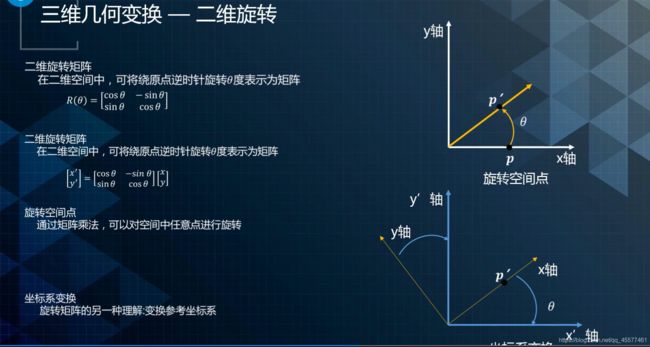
如上所示:将P旋转θ角到P’的位置,在二维坐标系下,由一个2×2的矩阵表示,如图中的R(θ)。点的旋转其实也可以理解为两个坐标系的一个旋转。
对于三维而言,多了一个维度,可以用3×3矩阵来表示。
分解来看,可以通过X轴Y轴Z轴分别去旋转,对应的分量分别是RX,RY和RZ。三维旋转矩阵可以由对应三个方向的基本旋转矩阵相乘来表示。三维旋转矩阵存在九个元素,对九个元素进行优化是非常复杂。通常情况下会使用是欧拉角或者四元数的方式进行优化,如下图所示。
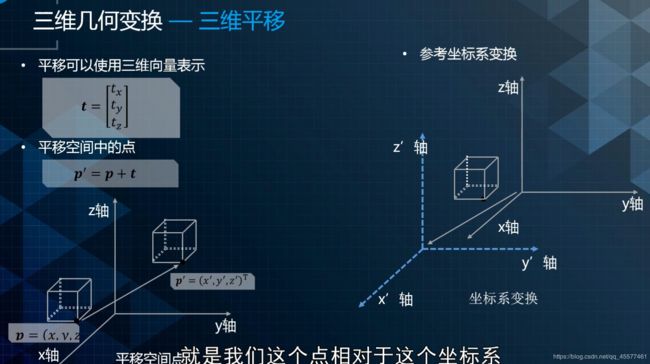
平移
平移是当前点相对于坐标原点的位置变化,通常由当前位置的坐标表示,由一个3x1的向量表示,如下所示。
刚体的位置和朝向
刚体是一种有限尺寸,可以忽略形变的固体。自然界不存在完美的刚体,但物体通常可以假定为完美刚体。自动驾驶中汽车可以认为是一个刚体。
刚体坐标系通常是取刚体内的一点P为原点建立的局部坐标系。刚体的位置可以看作刚体原点P相对于参考坐标系原点O所做的平移,可以使用三维平移向量表示。刚体的朝向可以由刚体原点P的朝向来表示。
2.2坐标系
ECI地心惯性坐标系
ECI地心惯性坐标系,也称i系,这个坐标系如下图所示:
它圆心就是地球的原点,Z轴沿地轴方向朝向北极, X轴和Y轴位于赤道平面内,与Z轴满足右手法则,并且X轴和Y轴分别指向两个恒星。也就是说不随着地球的自转而发生变化。它是一个非常固定的坐标系。IMU测量得到的加速度,角速度都是相对于这个坐标系的。
ECEF地心地固坐标系
ECEF地心地固坐标系也称为e系,它的原点也是地球的原点, Z轴指向北极, 它与ECI的区别就在于它的XY随着地球的自转而转动,它是以地球为基准的。它的X轴指向格林威治的子午面的交线, Y轴在赤道平面内与X轴、Z轴满足右手系法则,常用的如WGS84坐标系。其特点是与地球固定在一起,随地球一起转动。
当地水平坐标系
当地水平坐标系,一般也称为L系。如下图所示,它的原点位于载体所在的地球表面,X轴和Y轴在当地水平面内,分别指向东向和北向,Z轴垂直向上,与X轴和Y轴满足右手法则。在导航解算过程中通常也把该坐标系选取为导航坐标系(n系),也称为“东-北-天(E-N-U)”坐标系。
UTM坐标系
UTM(UNIVERSAL TRANSVERSE MERCARTOR GRIDSYSTEM,通用横轴墨卡托格网系统)坐标是一种平面直角坐标,这种坐标格网系统及其所依据的投影已经广泛用于地形图。其投影是一种“等角横轴割圆柱投影”,椭圆柱割地球与南纬80度,北纬84度两条等高圈,投影后两条相割的经线上没有变形,而中央经线上长度比为0.9996。该投影方法按经度把地球划分成了60个区域,那么每6度一个区域,例如北京其实在第50区。南北又做了划分,相当于把地球划分成很多块。
车体坐标系
车体坐标系原点在载体质量中心与载体固连处(相对于车载,选取原点位于后轴中心位置),X轴沿载体轴向指向右,Y轴指向前,Z轴与X轴和Y轴满足右手法则指向天向。该坐标系通常称为“右-前-上(R-F-U)”坐标系。它是一个局部坐标系,它与N系或者导航坐标系、当地水平坐标系之间的旋转关系表示现在车的姿态。
IMU坐标系
IMU坐标系其实和车体坐标系基本上是一样,它的原点在陀螺仪和加速度计的坐标原点,XYZ三个轴方向分别与陀螺仪和加速度计对应的轴向平行。在不考虑安装误差角的情况下,载体坐标系和IMU坐标系是一样的。
相机坐标系
相机坐标系以相机光心为原点,Xc轴和Yc轴与成像平面坐标系的x轴和y轴平行,Zc轴为摄像机的光轴,和图像平面垂直。由点O与Xc、Yc、Zc轴组成的坐标系成为相机的坐标系,如下图右边所示。通常情况下并不会将相机坐标系和其他的全局坐标系直接连接起来,因为已经选IMU作为汽车原点。通过一个外参,把相机和IMU关联起来,也就是标定的外部参数。当知道IMU在世界坐标系的姿态和位置就可以得到相机坐标系到世界坐标系的转换。
激光雷达坐标系
下图为激光雷达坐标系以及其俯视图,可以看出激光雷达坐标系的坐标原点位于多线束中点旋转轴的交点处,Z轴沿轴线向上,X和Y轴如俯视图所示。其测量的点坐标是在激光雷达坐标系下的三维坐标。
要转换到世界坐标系,可以使用相机坐标系下点转换到世界坐标系的类似方法。通过IMU坐标系到激光雷达坐标系的外參,以及IMU坐标系的姿态,得到激光雷达坐标系到世界坐标系的转换。
无人车定位信息涉及的坐标系
定位输出信息主要包括UTM坐标系的XY,IMU的姿态四元数, ENU坐标系下的速度。另外还输出一些和车体相关信息,例如车体姿态的四元数,车体坐标系下的加速度和角速度。这些输出的信息可以给感知和PNC使用。各个坐标系之间是一些基本的旋转关系。

3.百度无人车定位技术
下图是百度做自动驾驶汽车的一些车型,比较早的有宝马、北汽,后来有奇瑞到现在的MKZ。这个系列的车叫探路者,意思是要去探索未知的路。这套车的传感器配置非常贵,都用最好的惯导和最好激光雷达。其目的是用于探索一些新的算法,一些复杂的场景、有挑战的场景,主要是为了给工程师提供一个较好的平台,用更好的数据去开发更好的算法。
无人驾驶微循环车是和厦门金融合作,叫阿波龙。它配备了一个很便宜的惯导。激光雷达用了16线,再加上一些双目摄像头。低成本、林荫路。
无人驾驶物流车,是和新石器一起开发的,一般情况下可以用于小区的无人快递车或者是广场上面去卖饮料的无人车。
3.1 GNSS定位技术
GNSS定位技术中最著名的是GPS。GPS最早是由美国建立的,有24颗GPS卫星,L1、L2两个频率的波段。GPS具有定位(P)、测速(V)、授时(T)等功能。类似的系统还有北斗定位,俄罗斯的格罗纳斯和欧洲的伽利略定位。
它们的原理是TOA测距,有三颗卫星就可以交会两点,舍弃外部的空间点就可以得到自己测绘这个点。但是一般情况下,由于钟差,一般需要四颗卫星去做误差剔除。
GNSS定位其实是单点定位,没有用到基站,它的精度一般是5到10米。为了能够得到更精准的定位精度,引入了一些更好的方式,如载波定位技术。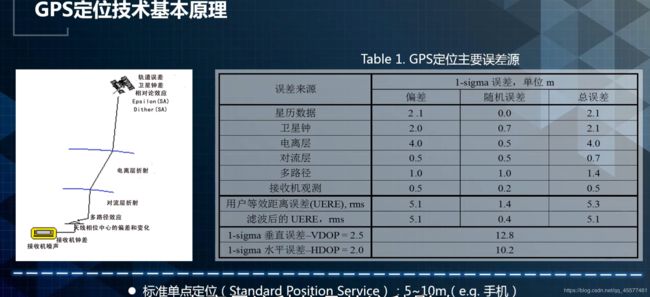
GNSS在无人车中的作用,大概可以分为三个部分,第一个部分是GPS授时。 第二是制作高精地图。第三是RTK在线定位,作为定位的一个模块使用。
GNSS的问题是可靠性,很容易受到电磁环境干扰。第二点就是对于比较差的环境,比如城市的高楼、峡谷、林荫路,对GNSS影响都很大。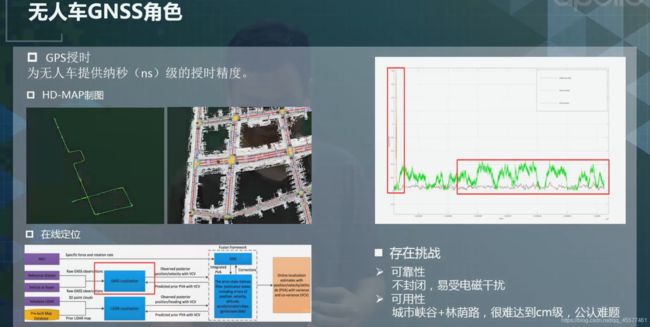
3.2载波定位技术
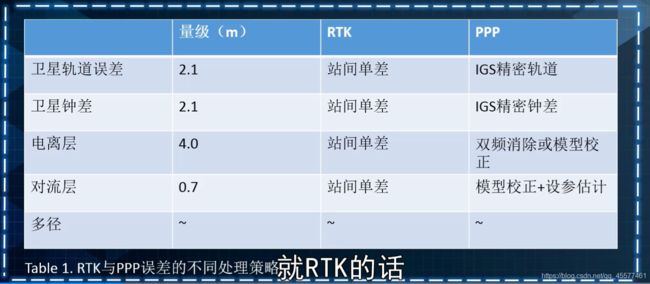
载波定位技术,载波由接收机内部环路锁相环给出的不足整周部分,伪距噪声0.5m~3m,载波噪声1/100周,在2mm。有RTK技术和PPP技术两类,它们都是为了确定载波的整周数,然后消除噪声,达到更精准的定位。
- RTK的工作原理如下:卫星把观测数据给基站,也给车端的移动站。基站根据多个卫星的钟差计算出误差项,然后把误差项传递给车端,车端用这个误差项消除观测误差,得到精准的位置。
优点:基本5秒内就可以提供厘米级定位精度;
缺点:硬件成本高,需要建基站,需要4G通信的双向链路,需要基站传数据。
发展趋势:终端低成本化、数据协议5G标准化。 - PPP可以简单理解为一个很强的单点,它有很多种基础基站的建设。这些基站通过卫星数据,把这些误差都在基站做分离处理,再传递给卫星。卫星已经做了误差的消除,再去对车端进行定位,得到一个非常高精度的定位信息。
优点:全球均匀布站100+,单向广播;
缺点:建15+min的收敛时间+接收GEO广播需授权。
发展趋势:LEO-GNSS增强。 - 二者的主要区别:
3.3激光点云定位技术
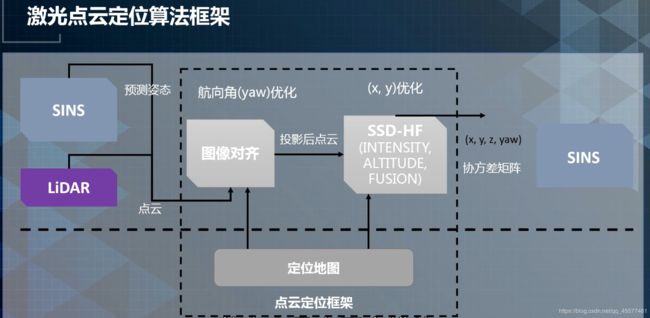
激光点云定位系统包括两个模块:图像对齐和SSD HF。
图像对齐模块主要是用于航向角的优化。点云定位里面会输出四个维度的信息,XYZ和Yaw(航向角)。
首先做航向角的优化,然后SSD-HF做XY优化,Z则由定位地图提供。定位地图是一种数据的的存储方式。激光点云定位的输入还包括预测位姿和实时点云数据。输出信息将会给融合算法,进行更加精确的定位。


3.4视觉定位技术
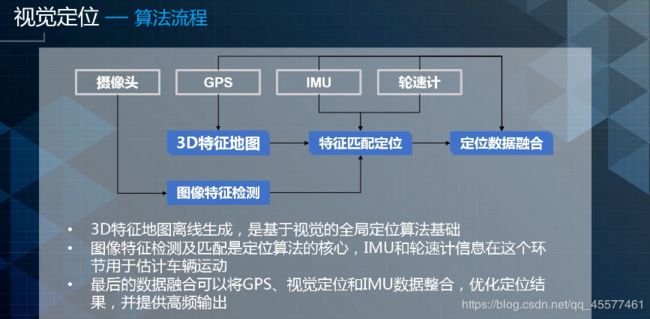
视觉定位的输出也是XYZ和Yaw,即位置和朝向。视觉定位通过摄像头识别图像中具有语义信息的稳定特征并与地图做匹配,得到位置和朝向信息。
视觉定位的流程主要包含三个部分,一是3D特征地图的离线的生成,第二是图像特征的检测,最后是数据的整合输出。
首先是摄像头进行图像特征的检测,主要是进行车道线和杆状物的检测。通过GPS给出的初始位置,基于初始位置对3D地图和摄像头检查到的信息进行特征匹配。用IMU和轮速计去做姿势的预测,给出一个不错的姿势。最后的结果输出给融合模块,融合可以将GPS、视觉定位、IMU数据整合,优化定位结果并提供高频输出。
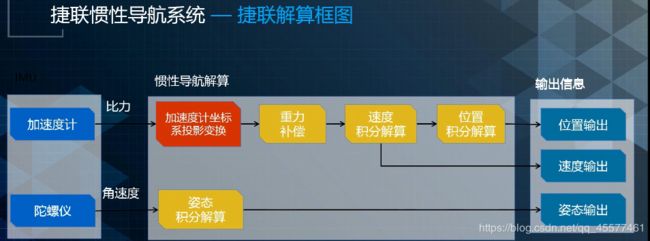
捷联惯性导航系统