Boxy Vehicle Detection in Large Images
Abstract
基于相机的目标检测与自动驾驶最近几年整体发展迅速。部分这些改进可以归因于公共数据集,使得全世界的研究者可以利用这些数据进行研究,避免个体队伍花费大量的时间收集与标注数据。当前车辆检测数据集与方法通常专注于解决坐标轴平行的bbox或者语义分割任务。坐标轴平行bbox通常会对车辆大小表示失真并且引入临近的道路内容。语义分割会更加精确,但是他们更难处理与应用在轨迹规划系统中。我们因此提出了一个用于基于图像的车辆检测数据集boxy dataset。Boxy是一个拥有199万标注数据,20万图像的最大的公开车辆检测数据集,包括车辆驾驶时阳光、雨水、夜间驾驶等情形。如果可以的话,车辆的标注会被分割成多个可见面,给人一种3Dbbox的感觉,使得表达更加精确。500万像素的图片最小几个像素的标注使得这个数据集特别具有挑战性。通过Boxy,我们为边界框、多边形和实时检测提供了初始的基准测试挑战。所有的基准都开源了,使得可以增加额外的度量方式与基准。
1、Introduction
感知系统特别是基于视觉的目标检测系统是自动驾驶的不可分割的组成部分。摄像机图片通常可以提供比其它传感器例如雷达或者激光雷达更高的分辨率。这使得我们可以完全理解车辆周边的情况并且在远距离进行车辆检测。颜色信息例如刹车灯与转向灯可以用来提供额外的属性信息,这些信息是其他传感器提供不了的。
公开数据集与基准可以为计算机视觉与车辆检测带来很多可能的发展。

1.1Vision Datasets
最优影响力的数据集之一ImageNet Large Scale Visual Recognition Challenge(ILSVRC)【25】见证了短短6年时间Top5准确率从28.2%下降到约3%。在相同的时间内,Pasca Visual Object Classes(VOC)【6】数据集与ILSVRC上的目标检测部分目标检测准确率也取得了巨大的提升【25】。这些数据集包含了几万到上百万标注样本,使得研究人员可以训练全新、更大、更有效的神经网络模型例如Faster-RCNN【22】,SSD【15】,YOLO【20,21】,与各种模型变体。除了用于目标检测的bbox标注外,Pascal VOC【6】与Micosoft Common Objects in Context(COCO)【14】提供了像素级别的标注。这使得我们可以创建模型用于进行像素级别的目标位置精确估计【16,23,1】。驾驶辅助系统与全自动车辆是这些目标检测与语义分割领域进步的理想应用。
1.2车辆检测数据集
对于自动驾驶应用来说对其它交通参与者快速、准确、可靠的检测需求相当紧迫。这样的需求已经牵引出许多基于视觉的车辆检测公开数据集【7,5,32,29,2,19,24,17,31,28,29】。KITTI视觉基准套件【7】是其中一个最大的数据集为自动驾驶问题提供例如测距等多样化标注。在KITTI数据集中,车辆是以3Dbbox的形式标注的。Cityscapes【5】提供了5000张图片的像素级完整标注与20000张粗标注的图像。BDD100K数据集包含了100000样本,标注了2Dbbox与像素级标注。
此外,还存在一些有平行坐标轴标注bbox(AABB)的数据集,例如Toyota Motor Europe motorway Dataset(TME)【2】,two Udacity datasets【31】,the Nexar Challenge2【17】,Mapillary Vistas【19】与Lisa Vehicle Dataset【28】。见表2中各自数据集大小。

除了人工标注的数据集外,也可以通过模拟数据训练检测模型。例如Synthia dataset【24】,包含200000张包含车辆像素级标注的图片组成。另外一个研究领域专注于利用模拟【3】创建逼真的图片。
我们提出Boxy dataset用于特别是高速公路行驶的车辆检测。所有的车辆都分割成可见面,形成类似3D的boxy表示,这种表示比AABB的表示包含更多的细节。据我们所知,数据集是目前公开的最大的车辆检测数据集,包含了200000张样本中1990806个手动标注的车辆位置。它包含了不同的天气情况与分辨率,500万像素图像,使得这个数据集相当有挑战性。
我们公布了在有或者无AABB检测任务的带有基准挑战的Boxy数据集,类似3D的检测使得可以将车辆检测算法在大规模难标注样本上进行对比。
2、The Boxy Vehicles Dataset
2.1 关键指标
- 200000万样本,大小1.1TB
- 500万像素的分辨率2464×2056
- 类3D与2Dbbox
- 1990806标注车辆
- 车辆标注平均复杂仅0.3%的图像背景
- 白天,黎明,黄昏的晴雨天场景
- 堵车与畅通无阻高速场景

2.2 Dataset Overview
Boxy是一个车辆检测的大新且有挑战的计算机视觉数据集。
其中一个挑战是相对图像大小来说较小的目标标注,这使得搜索空间很大。平均每个标注仅包含约0.3%的各自图像,大多数标注小于50像素,如图2与3中所示。我们还注意到,Boxy中还包含比大多数现有数据集中图片分辨率还高的标注目标。特征是对于实时检测来说,需要在输入分辨率,运行时间与准确率之间做权衡。
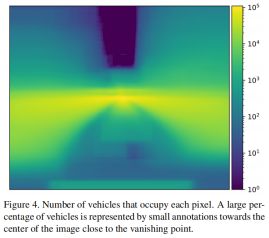
整体来说,车辆可能出现在图像的任意部位。然而,绝大多数情况下都聚集在具有独特分布的分布在平局相邻车道线消失点附近,见图4。密集区域外的车辆也需要高可靠的检测,特别是因为对于安全来说。相机的角度不会为了车辆检测做优化,但是还是需要可以拍到交通标志,交通灯与度量灯。
2.3 Image and Sensor Specifications
所有的样本都是由Sony IMX250芯片的mvBlueFOX3-2051相机使用全局快门拍摄的【10】。数据以2464×2056像素分辨率,15HZ、8bit彩色样本存储。每个像素值3*8bit,每张图像需要约15.2MB或者228MB每秒,并且需要流化、处理与存储。作为Boxy的一部分,我们为每张图片提供无损的轻量的5.5MB文件进行存储。为了进行快速下载与处理,我们也提供等量下采样的版本。
2.4 Recordings and Environment
所有的序列都是在San Francisco Bay Area称为加州85与92号公路与101与280跨州的高速公路录取。考虑到区域范围、有不同的交通场景、类3D标注、他们的尺寸、时间与天气情况,Boxy会是一个有挑战的数据集。

训练集、验证集与测试集不同序列的总览如表1。录像中大多数是晴天的场景,也包括大量的阴天、大雨、黄昏与夜间驾驶的场景。交通场景从轻度到重度拥堵,反映出了典型高速公路驾驶场景。
2.5 3D Boxes and Annotation Specifications
Axis aligned bounding boxes(AABB)、3Dbbox、像素级别的分割是车辆检测的标准方法。AABB通常不能将目标车辆紧紧包围,可能会引入临近车道信息(如图5所示),因此有可能会影响规划的性能。像素级分割对于计划来说可能会增加计算量并且引入噪声。

Boxy包含类似3D标注,由可见面包围成四边形。标注仅为图像,不包含3D点。为了简化标注过程和质量控制,我们用AABB标注车辆后部,用梯形标注车辆侧面。图6展示了样例标注。这种简化方式适用于数据集内所有的目标,除了直角车道上正在转弯的目标。

标注过程中一个难点是定义顶部平面。上平面按理来说应该与车顶平行,但是许多车的车顶是不规则的。图6展示了同一部车不同侧面标注的示例。对于远处的车辆来说,3D信息不足以保证车辆高度的精准与上下面平行的精准。一个可能的解决方案是与图像的消失掉做结合。
2.6 General Annotation Requirements
所有与摄像机方向相同的车辆都必须进行标注。包括了驶入、驶离、正常行驶的情况。大部分录像都是在车道分离的高速公路上拍摄的,这样对向的车辆不会对我们的行驶轨迹产生影响。
所有高速公路上行驶的车辆都被标注为车辆类。这包括了轿车、卡车、房车、船、拖车、工程车与摩托车等。尾部的bbox需要包含除了侧边与前边的镜像外的整个尾部。对于打在或者包含其他车辆的车辆目标,如图5与图9,只标注大车。
部分遮挡的车辆需要标注出他们整个车辆估计的大小与位置。最后最重要的是,只有能完全看的间且认得清的车辆才被标注出来。特别是小的、模糊的无法完全辨识的车辆不做标注。

2.7 Dataset Evaluation and Comparison
Boxy从图片数量、标注数量与每张图车的数量来看都是最大的车辆检测数据集之一,见表2。据我们所知,只有类似于ILSVRC Detection【25】、OpenImage【13】、COCO【14】这样的公开数据集才会有更多的图片数量。
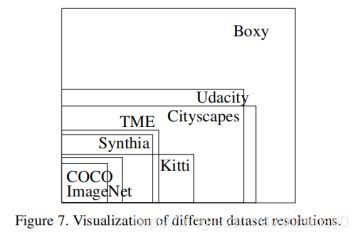
通常,用于自动驾驶的相机分辨率一般是两百万像素【5,7,17,2,31】。我们提供了500万像素的样本,比其它数据集分辨率都高,见表2。有些标注的车辆比其它数据集整张样本都打。图7给出了不同分辨率样本的尺寸对比。此外,目标相对于图像的照片平均仅仅为0.3%,而Cityscapes仅为1.0%,Kitti仅为1.65%,ImageNet仅为17%。
我们数据集另外的一个特点是类3Dbbox。Kitti的标注通过3D点云获得类3Dbbox,但是却达不到相同的标注距离。
然而,我们将所有类别的车辆归为一类,并没有提供市区道路的标注,简化的部分标注并且没有3D信息。Boxy也不提供Kitti所提供的高度精确的校准和传感器设置,或者Cityscapes和BDD100k中提供的像素级语义分段。我们的标注中有一小部分是不正确的,并且注释的详细程度在不同的图像之间可能略有不同。整体来说数据集应该是目标检测领域或者车辆检测领域最大最优挑战性的。
3、Vehicle Detection Baselines
对于我们的基准测试,我们将数据集分割为训练、验证和测试集,这样就不会分割记录,并且测试集反映了条件的变化,见表1。初始基准测试将覆盖2D、3d和实时检测,并且测试集的注释是私有的。所有基准最初都是基于平均精度进行评估的。
3.1 AABB Baselines
近些年来提出了许多目标检测算法,例如Overfeat【27】,R-CNN【9】,Fast-RCNN【8】,Faster-RCNN【22】,YOLO结构【20,21】,SSD【15】。对于这些通用的方法,可以基于准确率、速度、时延、便利程度与内存需求选择基础网络。基础网络可以从MobileNet【26】到ResNet系列【11】,到Inception【30】与NASNET结构【33】等结构中选择。此外,也提出了许多基于图像的3Dbbox检测方法【18,4】。
最为基准方法,我们选择使用MobileNetV2【26】作为前置网络的SSD作为速度优先的方法,NASNET-A(6@4032)为前置网络的Faster-RCNN作为准确率优先。我们利用TensorFlow Object Detection API【12】训练网络,使用COCO【14】训练预训练模型。
3.2 Refinetment by Keypoint Regression
第二步是优化轴向对齐的边界框,以便更好地表示车辆的真实形状。我们训练MobileNetV2【26】来检测每个检测到车辆的3Dbbox可见的8个角点。为了实现这个,所有检测的目标归一化到大小256*256,作为第二个网络的输入。我们将回归的任务转换成分类任务,在整副图像上随机采样bbox角点。对于基线模型,我们使用了50个bins,并添加了10%到30%的随机边缘来解释检测步骤中的不准确性。在推理过程中,会添加20%的常量余量。
标注几何信息的表达如2.5节所述,也就是每个车辆由相连的梯形框包围,使得我们可以减少回归值的数量。尾部可以由框的对角两个点表达,总共4个值。侧面比尾部增加两个额外的共享同一个轴的点,总共3个额外的值。

我们通过最小化整体的L(1)loss,通过将可见面分类lossLV(2)与回归lossLR相加得到。每个角点向量![]() ,交叉熵损失值在角点属于可见面的时候进行计算与相加,例如
,交叉熵损失值在角点属于可见面的时候进行计算与相加,例如![]() 。
。
3.3 Baseline Results
我们通过IOU大于0.7的平均准确率(AP)来评估检测方法。表3.3展示了在Nvidia GTX 1080TI显卡下测试集上不同模型的准确率与FPS。每个模型都接收归一化到分辨率1232*1028的图像输入,仅评估这个分辨率下大小大于5个像素的目标。

为了将baseline结果进行量化表达,我们希望读者观看视频附件。视觉上来说,3D检测看起来视觉效果更好,带来了明显的检测结果优化。有一些可复现的问题,例如如图8所示的可见面的误分类、迎面车辆检测与远距离的误检。图9展示了其他的一些有挑战性的样本。
后续的工作包括尝试不同的方法、潜在模型,提升整体准确率,并探索速度精度的权衡。
4、结论
我们提出了Boxy车辆数据集,一个包含约200万标注目标,20万样本的车辆检测最大公开数据集。不同天气、交通状况下的500万像素样本小目标、类3D检测组成了挑战集。平均标注仅占相机图像平均约0.3%。
利用提出的数据集,我们展示了AABB、类3D与事实检测的基准结果。基准测试的评估与展示完全开源,以便添加额外的度量标准与子任务,我们也计划扩展不同目标与度量方式。我们欢迎任何基准测试的建议。
未来我们希望数据集增加来自不同传感器的样本与城市环境的样本。
利用这个数据集可以进行许多研究方向的探索,例如速度、准确率权衡,不同分辨率测试,不同数据集融合,基于相机图像进行车辆控制,场景适配与探索对于自动驾驶应用比AP更合适的度量指标。