cs231n训练营学习笔记(9)卷积和池化
卷积具有部分连接和权重共享的特征,共享的权重就是卷积核,因为它划过所有图像分别和图像切片相乘,相当于很多的卷积核共同组成权重。
从函数角度解读卷积神经网络工作原理
每个卷积核(感受野receptive field)对应输出一个激活映射(activation map),每层ConvNet由多个卷积核输出的激活映射组成,
与前面线性分类器不同,前面的权重的每行对应该类的模板,输出是分数,相当于是一种特征吧。
卷积网络的权重,也就是卷积核对应的是滤波器,每层ConvNet也就是激活映射里面包含的是提取到的特征。
线性分类器是用模板点积得到距离,卷积是用滤波器得到距离以外的其它更复杂的特征。
于是,训练卷积网络,就是更新卷积核的值
卷积时候padding是为了获得和输入一样尺寸的输出
通常,卷积核是3*3,5*5,7*7的,对应的padding为1,2,3,可以通过公式计算证明
如果不padding,随着深度增加,activation maps尺寸减小,这样会不断地丢失边角的信息,这样不太好
也有1*1的卷积核改变深度
stride步长,当选用大的步长时,输出的是降采样的结果,分辨率降低。相当于是池化处理,但是某些时候比池化好一些,大概因为可以改变深度。
选择是构造一种平衡,参数数量、模型尺寸、还有过拟合之间的平衡。
池化用来减小输入激活的尺寸,使他们更小更容易控制,从而在最后有更少的参数,因为最后还是要接到FC上
池化还可以有效控制过拟合
因为不对深度处理,所以输入池化和输出的深度是相同的
一般不在池化时候padding
池化也是降采样,设定stride避免重叠效果更好
有发现认为,在训练一个良好的生成模型时,弃用pool层也是很重要的。比如变化自编码器(VAEs:variational autoencoders)和生成性对抗网络(GANs:generative adversarial networks)。
在向前传播经过汇聚层的时候,通常会把池中最大元素的索引记录下来(有时这个也叫作道岔(switches)),这样在反向传播的时候梯度的路由就很高效。
为什么最大值池化要好于均值池化,做检测分类任务时候,在一定区域内选择激活值更大的值更直观
特征图与参数量的计算方法
卷积的计算方式
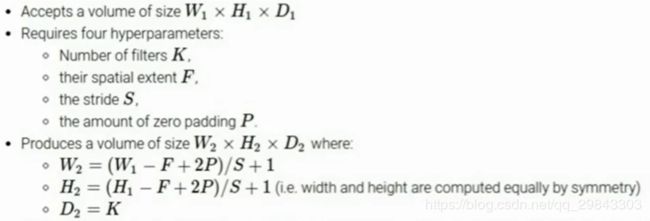
Fisher Yu和Vladlen Koltun的论文给卷积层引入了一个新的叫扩张(dilation)的超参数
让filter中元素之间有间隙也是可以的,这就叫做扩张
在某些设置中,扩张卷积与正常卷积结合起来非常有用,因为在很少的层数内更快地汇集输入图片的大尺度特征
目标检测和图像分割中感受野很重要,比如目标检测一般情况下要在最后一层特征图上做预测,那么特征图上的一个点能过映射到原图的多少像素,决定了网络能检测到的尺寸上限,而保证感受野就要靠下采样,下采样的结果就是小目标不容易被检测到;
针对上面的问题,多层特征图拉取分支能改善这个问题,因为小目标在越靠前的特征图上越容易体现,但是前面的特征图语义信息不够,比如在SSD中就存在这个问题;
扩张卷积的目的就是为了在不牺牲特征图尺寸的情况下增加感受野
虽然说它使感受野变大了,但是扩张的间隙权重参数都是0,那用0感受不是和没感受一样吗
推测是相当于没有牺牲感受野的同时做了下采样
既然是这样,那还是做了下采样,小目标还是不容易被检测到啊?
但是卷积的输入会出现问题,由于卷积核是有间隔的,这意味着不是所有的输入都参与计算
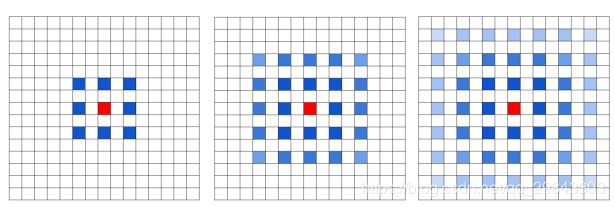
上图是同样的间隙扩张卷积三次,对应输入上的感受野中被计算的部分
解决方法将连续排布的扩张卷积的dilation rate设置为“锯齿状”,比如分别是[1,2,3],
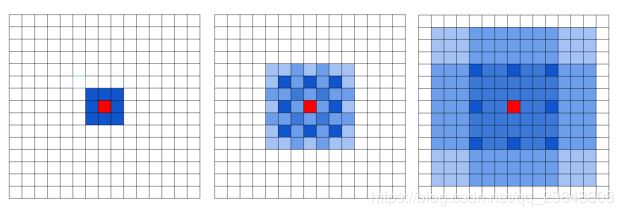
这样就没有遗漏了,这个感受野是目标检测的尺寸上限,不是说只检测这个尺寸大小的东西,既然能被计算到,那应该可以检测到小目标
另一篇博客理解为什么要将全连接层转化为卷积层
几个小滤波器卷积层的组合比一个大滤波器卷积层好
因为,多个小卷积层与非线性的激活层交替的结构,比单一大卷积层的结构更能提取出深层的更好的特征?为什么?
使用小滤波器的卷积层组合,而不是用一个带有大的滤波器的卷积层。前者使用的参数更少。
