【自动驾驶】卡尔曼滤波直观理解、数学公式及代码理解
直观理解
你住在深圳,你的好朋友小明住在乌鲁木齐。有一天,小明打算来找你玩,你想预订一家五星级餐馆,在他到深圳的当天晚上和他一起吃晚饭。但是小明是一名户外运动爱好者,他偏偏选择走路来深圳,你打开地图发现卧槽,这走路得走好几十天。

然而五星级餐厅如果不提前几天预定好话,当天是没有位置的。所以你问小明,哪一天才能到?然而他却没有正面回复,而是告诉你他从乌鲁木齐市中心出发以及他的速度。

乌鲁木齐到深圳全程约4275.3公里,这样的话四天多就能到了!但是根据你对小明体能的了解,你觉得这个估算不太靠谱。而且他路上还会经过雪岭、草岭、荒漠、戈壁各种地形,还有各种天气的原因,他很难保证每天100公里的前进速度。

于是你想了个办法,你先假设小明速度每天100km,然后每天晚上让他发个定位,告诉你他的位置在哪,然后你可以根据他的定位更新他的数学模型,预测之后的位置。

但是有个新的问题,就是他的GPS定位不是很准,可能是有十几公里的偏差,因此你也不能完全相信他的定位。

最后你决定两手抓,既相信自己的建立的数学模型,同时也参考GPS的定位,综合两者的结论来预测小明的位置。
例如,出发后第1天,根据你的数学模型,小明此时应该已经到了达坂城古镇,然而根据他发来的GPS定位显示还没走出市区,今天只走了10km。显然,你认为今天GPS的可信度高于自己的数学模型。
因此你综合“自己的数学模型”和“GPS信息”,得到一个新的数学模型——你认为小明目前的真正位置应该在距离市中心15km的地方,他的速度为每天12km,因此他第二天的位置在距离市中心27km的地方(这些数字是随便取得,大家看一看数字的变化就好)
之后的第三天、第四天、第N天你都采用上面的方法,随着你不断修正自己的数学模型,你的预测也会越来越准确,上面就是卡尔曼滤波的思想。
数学公式
接下来我们认真看一下卡尔曼滤波的公式,分为Station prediction(状态估计)与Measurement update(测量更新)两部分:

Station prediction
(1)公式一
在状态估计阶段,我们要估计物体的状态有位置 p x p_x px和速度 v x v_x vx,因此状态 x x x可由向量的形式表示为:
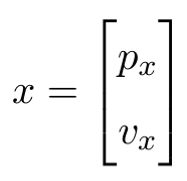
若第N-1时刻的状态用 x x x表示(即估计前),第N时刻的状态用 x ′ x' x′表示(即估计后),则 x ′ x' x′可写作:
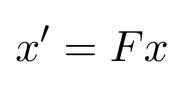
其中, F F F为状态转移矩阵,即表示第N时刻状态与第N-1时刻状态的关系:

这个很好理解,用高中物理知识就能明白,矩阵 F F F与 x x x相称后含义即为:
- 第N时刻的位置(即 x ′ x' x′中的 p x p_x px)= 第N-1时刻的位置(即 x x x中的 p x p_x px)+ 第N-1时刻的速度(即 x x x中的 v x v_x vx)*时间间隔(即 F F F中的 Δ t \Delta t Δt);
- 第N时刻的速度(即 x ′ x' x′中的 v x v_x vx)= 第N-1时刻的速度(即 x x x中的 v x v_x vx)(这里认为物体时匀速的)。
B B B输入增益矩阵, u u u表示输入向量, B ∗ u B*u B∗u表示有外部力量对物体施加力的作用。
同时,由于物体运动过程中存在噪声,我们认为该过程噪声为一个均值为0,协方差矩阵为Q的正态分布。
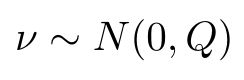
所以最终得到第一个公式:

(2)公式二
P P P表示协方差矩阵,即表示状态的不确定性, F F F为上面中提到的状态转移矩阵, Q Q Q表示状态转移中的噪声(也就是上面的 v v v中的 Q Q Q)。
![]()
协方差矩阵就是由协方差组成的矩阵。协方差类似于方差,只不过方差是只针对一个变量而言,协方差是一个升级版方差,可以用于多个变量,并且还可以得知不同变量之间的相关性。
由于在这里我们有两个变量(即位置和速度),因此 P P P是一个2*2的矩阵,即:
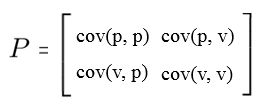
- c o v ( p , p ) cov(p,p) cov(p,p) 表示对于位置的方差,也可以理解为不确定性,因为若方差越小,则位置的确定性越大;
- c o v ( p , p ) cov(p,p) cov(p,p) 表示对于位置与速度的协方差;
- c o v ( p , p ) cov(p,p) cov(p,p) 表示对于速度与位置的协方差,实际与 c o v ( p , p ) cov(p,p) cov(p,p) 的值是一样的, P P P是一个对角阵;
- c o v ( v , v ) cov(v,v) cov(v,v) 表示对于位置的方差。
通过P可以反映出我们模型的对于估计的确定性程度。
若不考虑 Q Q Q,则表示“通过第N-1时刻的 P P P求得传递之后第N时刻的 P P P”,但是由于模型在传递过程中也是会存在噪声的,也就是相当于被估计物体移动这个动作本身就具有不确定性(即加速、减速或改变方向),因此考虑加入状态转移噪声 Q Q Q。代表了每一次运动后,不确定性都会增加。
(3) Q Q Q与 v v v的关系
前面提到, Q Q Q与 v v v满足下列关系,那么这到底是什么意思呢,为什么二者有关联,这个问题一开始也困扰了我很久,下面说说我的看法。
首先,我们先确定两者的维度,由矩阵加减法可知,矩阵 Q Q Q必然是2*2的, v v v是一个二维的列向量。
我一开始疑惑,为什么2*2的 Q Q Q最后会变成一个二维的列向量? Q不是与协方差矩阵有关吗?那么Q里面的四个元素就应该分别为下面四个(即与 P P P应该是一一对应的):
- 位置的方差的误差;
- 位置与速度的协方差的误差;
- 速度与位置的协方差的误差;
- 位置的方差的误差。
而 v v v若要和状态 x x x相加,则 v v v内两个元素必然一个代表位置,一个代表速度,那不就丢失了2. 位置与速度的协方差的误差和3. 速度与位置的协方差的误差吗?
造成这种困惑的原因是,没有理解分布的含义, v ∼ N ( 0 , Q ) v\sim N(0,Q) v∼N(0,Q)表示的是数据 v v v的分布是一个协方差为Q的正太分布,关键词是分布,也就是说 v v v是从这一堆特定分布中随机取出的一个数据。
我们生成一组(1000个)二维的,均值为0,协方差为[1 1.5; 1.5 3],满足正态分布的数据,以下为matlab代码:
mu = [0 0];
Q = [1 1.5; 1.5 3];
rng('default') % For reproducibility
V = mvnrnd(mu,Q,1000);
plot(V(:,1),V(:,2),'+')
绘制散点图观察分布,确实是我们想要的正态分布。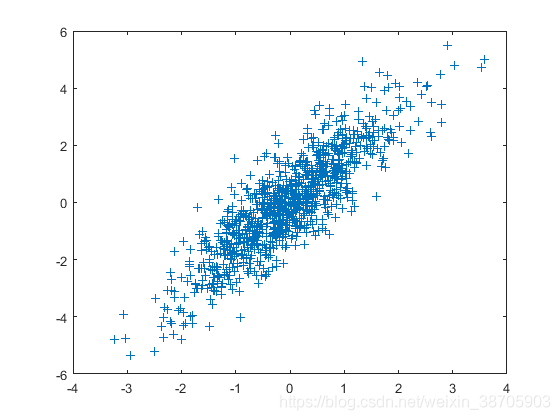
再去看生成的每个样本(即每一行),其实他们都是二维的。有1000个样本,每个样本维度是2,因此是1000*2。

在代码中, Q Q Q维度是2*2, v v v的两个维度对应位置和速度,事实证明: v ∼ N ( 0 , Q ) v\sim N(0,Q) v∼N(0,Q)这个关系是没有问题的,他们各自的维度也是没毛病的!
上面的代码中,我刻意使用了大写的 V V V,而不是小写,因为 v v v代表的是单个样本(即单独一行)。在实际状态估计的时候, x ′ = F x + B u + v x'=Fx+Bu+v x′=Fx+Bu+v中的 v v v,就是指从 V V V中随机抽取的一个样本。
你发现了没有,这就是分布的神奇所在!因为这是一个二维的分布,所以得到的数据 v v v必然是二维的!分布只与样本的位置有关,但是当 v v v的数量足够多的时候,宏观的去看这一组数据的时候,就可以呈现出我们想要满足一定均值、协方差条件的分布。
举一个例子, Q Q Q代表一个班级, v v v代表班级里的某一个人,老师要从班级里面随机选一个人出去参加跑步(只能选一个),老师只能看到两个维度:身高、体重。
她选了一个平均身高为175,平均体重为60kg,身高方差为15,体重方差为20,身体与体重协方差为10(即身高越高体重也越大)的班级。
最后随机选出了一个人,这个人身高180,体重70,这个人就是实实在在的 v v v。
最后说一下 Q Q Q与 v v v的关系:
- Q Q Q表示过程噪声,这些噪声会影响的是位置、速度、位置与速度的相关性,是从数据的整体分布的角度去影响;
- v v v是指满足上述分布的具体某一个噪声,这个噪声是切切实实的影响位置与速度,是直接加到我们的状态上的;
- Q Q Q与 v v v是指同一种噪声,即过程噪声,但是 Q Q Q是是从宏观的角度体现出噪声分布的特点, v v v则是具体某一个过程噪声。
Measurement update
(1)公式一
z z z为第N-1时刻的测量值(因为只能观测到速度,因此其含义为速度值)。 H H H表示测量矩阵,因为我们的 x ′ x' x′是状态,里面既有位置信息也有速度信息,而我们能够观测到的只有位置信息,因此需要乘个 H H H除去速度信息。

具体怎么除去呢,其实很简单,只要令 H = [ 1 , 0 ] H=[1,0] H=[1,0]即可,因为速度对应的权重为0,所以 H H H与 x ′ x' x′相乘之后就只剩下位置信息了。
当乘以 H H H后, z z z与 H x ′ Hx' Hx′维度就相同了, z z z为测量得到的实际位置信息(你可以认为是一种反馈), H x ′ Hx' Hx′为模型估计值(你可以当作一种理论值),因此两者相减便可得到测量的误差值 y y y,然后用这个误差 y y y去修正我们的模型,以便让我们的模型在下一次预测中更加的准确。
(2)公式二、三
R R R代表测量误差(即传感器本身的误差), K K K为传说中的卡尔曼增益, S S S为一个计算卡尔曼增益的中间值,一般时候也可以把下面两行直接写成一行把 S S S省略掉。
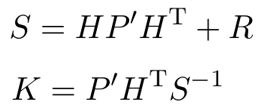
具体卡尔曼增益的推导请看最后面的P.S.,这里说下卡尔曼增益 K K K的含义。 K K K实际是在权衡模型与实际测量到底哪一个更准确。
H H H是常数我们不妨假设 H H H为1,这样可以将 K K K简化为:
K = P ′ H T H P ′ H T + R = P ′ P ′ + R = 1 1 + R P ′ K=\frac{P'H^T}{HP'H^T+R}=\frac{P'}{P'+R}=\frac{1}{1+\frac{R}{P'}} K=HP′HT+RP′HT=P′+RP′=1+P′R1
模型的不确定性对应 P ′ P' P′,测量的不确定性对应 R R R。
- 若 R > P ′ R>P' R>P′,则说明测量的不确定性更大,此时K较小,更新时偏向于相信模型;
- 若 R < P ′ R
(3)公式四、五
在计算得到卡尔曼增益 K K K后,便对之前的模型进行修正更新,下面这两个公式都与 K K K有关我们同时看。

前面说到,若 K K K变小,则偏向于相信模型,在此也可以得到验证,不妨假设一种极端情况, K K K=0,也就是 R R R比 P ′ P' P′大很多很多(说明测量的数据相比于模型更不靠谱),那么根据上面的两个公式,此时:
x = x ′ , P = P ′ x=x', P=P' x=x′,P=P′
也就是说对测量的数据完全不理会了,对模型的更新不造成影响,我只相信我原本的模型,完全不相信测量所得的反馈数据。
当 K K K慢慢变大的时候,与测量相关的数据(误差 y y y与测量误差 H H H)对于状态 x x x与 P P P的更新影响也越大。
P.S.
关于预测方程的具体推导,可以看卡尔曼滤波器推导与解析 - 案例与图片,非常详细!
最核心的地方在于:根据高斯函数的性质,得到“两个旧高斯分布推出一个新高斯分布”的公式,然后把“模型”和“传感器”分别当作就高斯分布,然后套公式,就可以得到新高斯分布“更新后的模型”:
即把:
![]()
代入到下面的公式中:
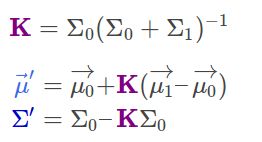
然后把H消掉就是预测过程的公式了(以上来张图片来自卡尔曼滤波器推导与解析 - 案例与图片)
(4)卡尔曼滤波的思路
下面将所有公式串起来,说一下整体思路:
- 首先我们会有一个被预测物体的数学模型,我们用这个模型去预测物体未来的运动轨迹。
- 然而这个数学模型是不完美的(运动中存在噪声模型本身也具有不确定性),因此我们会通过传感器去采集物体实际的运动数据,与我们的预测值比较,利用误差来修正我们模型。
- 但是我们又并不完全相信传感器的数据,因为我们传感器也有误差。所以我们会比较“传感器的误差”和“模型的误差”看谁比较小。 在更新模型的时候,误差比较小的一方占的比比重会更大。
- 起初数学模型会非常地不准确,通过不断地循环步骤1~3,不断地迭代“更新-预测”,就可以逐步得到一个准确地模型
举一个形象的例子:
有一个科学家提出一个“理论”,但是他知道这个“理论”不一定是完全正确的,有不完美的地方,因此他不断地做实验,每天都去根据“实验结果”更新他原有的理论。
当“实验结果”出现于“理论”冲突时,他会先思考实验出错的概率和理论出错的概率。
- 如果“实验结果”只是偶尔与“理论”冲突,那他可能认为这更有可能实验误差造成的,因为在他第二天新的“理论”中,会大部分保留前一天的“理论”内容,“实验结果”只占他新理论中的一小部分;
- 如果“实验结果”总是与“理论”冲突,他就会认为是这个不够“理论”完善,在更新“理论”时,他会加入更多在“实验结果”中的发现,甚至推翻其原有的“理论”。
这个过程很类似自动控制原理的思想,都是利用误差反馈,只不过自动控制原理中侧重于控制,被控对象的数学模型是固定的(即一开始数学模型就是非常准确的),而在卡尔曼滤波中侧重于预测,被控对象的数学模型是一直不断地被修正(即最初的数学模型不一定是准确地)。
代码理解
看公式可能还是有点抽象,接下来我们用代码来实现一个卡尔曼滤波器级加强我们的理解,以下为matlab代码(如果没有matlab的话,用octave也是可以运行的):
(1)Station prediction
- 由于 x ′ = F ∗ x + B ∗ u + v x' = F * x + B*u+v x′=F∗x+B∗u+v预测的是平均状态,而过程噪声 v v v本身均值就为0,因此在代码中不需要加上 v v v。
% 状态估计
function [x, P] = prediction(x, F, B, u, P, Q)
x = F * x + B*u;
P = F * P * F'+Q;
end
(2)Measurement update
% 测量更新函数
function [x, P] = update(x, z, H, P, R, I)
y = z - H * x;
S = H * P *H' + R;
K = P * H' * inv(S);
x = x + K * y;
P = (I - K*H)*P;
end
(3)设置初始值
- x x x是任意取的,可以是准确的也可以是不准确的,后面的讨论会提到;
- P P P也是任意取得,在此我们认为位置与速度正相关,并且位置和速度有极大的不确定性,因此选取 P = [ 1000 , 100 ; 100 , 1000 ] P = [1000, 100; 100, 1000] P=[1000,100;100,1000];
- Q Q Q的选取就很复杂了,实际应用中是通过实验得到的,在此我们随便取一个值;
- 由于我们假设不存在外部动作,因此 u = [ 0 ; 0 ] u = [0; 0] u=[0;0], B B B也是随便取的,真正考虑外力的时候要根据外力作用的物理原理去设置对应的 B B B和 u u u;
- 测量噪声 R R R由你的传感器决定,这里随便取了一个值。
% 设置初始位置和速度
x = [0; 0];
% 设置不确定性矩阵初始值,以下设置即认为:
% 位置与速度不相关,并且位置和速度有极大的不确定性
P = [1000, 100; 100 1000];
% 设置过程噪声
Q = [1, 0.5; 2, 3];
% 指定外部动作
B = [1 0; 0 1];
u = [0; 0];
% 构建状态函数
F = [1, 1; 0 1];
% 构建测量函数,表示仅可观测位置而不是速度
H = [1, 0];
% 观测不确定性矩阵
R = 1;
I = [1, 0; 0 1];
(4)设想物体的实际运动过程并设置观测值
- 我们不妨假设物体实际运动之后11个时刻的位置分别为2、4、6、8、10、12、14、16、18、20、22;
- 由于测量也是不准确的,所以我们根据条件1做出一些假设,假设之后10个时刻测量值是[2.3, 3.8, 6.2, 7.5, 9.6, 11, 13.5, 17, 18.5, 20.4];
- 在第11个时刻的位置是22,我们并没有放到测量结果中,因为我们要用这个值去判断当更新了10次之后,模型是否能够预测出物体下一时刻出现在22,以此来判断卡尔曼滤波是否对模型的准确性进行有效的更新。
% 实际所得的位置测量值
measurements = [2.3, 3.8, 6.2, 7.5, 9.6, 11, 13.5, 17, 18.5, 20.4];
(5)迭代过程
for i = 1:1:length(measurements)
fprintf('**********第%d论迭代开始**********\n',i)
% 首先测量更新
[x, P] = update(x, measurements(i), H, P, R, I);
fprintf('*****开始第%d次更新*****',i)
x
P
% 然后状态估计
[x, P] = prediction(x, F, B, u, P, Q);
fprintf('\n')
fprintf('*****开始第%d次预测*****',i)
x
P
fprintf('\n')
end
(6)完整代码及运行结果
clc;clear;
% 设置初始位置和速度
x = [0; 0];
% 设置不确定性矩阵初始值,以下设置即认为:
% 位置与速度不相关,并且位置和速度有极大的不确定性
P = [1000, 100; 100, 1000];
% 设置过程噪声
Q = [1, 0.5; 2, 3];
% 指定外部动作
B = [1 0; 0 1];
u = [0; 0];
% 构建状态函数
F = [1, 1; 0 1];
% 构建测量函数,表示仅可观测位置而不是速度
H = [1, 0];
% 观测不确定性矩阵
R = 1;
I = [1, 0; 0 1];
% 实际所得的位置测量值
measurements = [2.3, 3.8, 6.2, 7.5, 9.6, 11, 13.5, 17, 18.5, 20.4];
for i = 1:1:length(measurements)
fprintf('**********第%d论迭代开始**********\n',i)
% 首先测量更新
[x, P] = update(x, measurements(i), H, P, R, I);
fprintf('*****开始第%d次更新*****',i)
x
P
% 然后状态估计
[x, P] = prediction(x, F, B, u, P, Q);
fprintf('\n')
fprintf('*****开始第%d次预测*****',i)
x
P
fprintf('\n')
end
% 状态估计
function [x, P] = prediction(x, F, B, u, P, Q)
x = F * x + B*u;
P = F * P * F'+Q;
end
% 测量更新函数
function [x, P] = update(x, z, H, P, R, I)
y = z - H * x;
S = H * P *H' + R;
K = P * H' * inv(S);
x = x + K * y;
P = (I - K*H)*P;
end
最新一次对位置的预测为22.1900,非常接近我们的理想值22,说明模型经过修正后越来越准确了。

(7)讨论
-
如果测量次数足够多的话,初始状态 x x x不准确也没有关系,例如取 x = [ − 10 ; 100 ] x = [-10; 100] x=[−10;100],最后预测位置结果为22.1899,差别不大。同样,初始 P P P设置很大也没关系,因为在初始阶段我们确实认为自己的模型具有很大的不确定性。(当然 P P P初始设置很小也可以,因为 P P P是在不断更新的)
-
每次更新后, P P P值变小,说明对于位置和速度的不确定性降低。每次预测后,因为存在过程噪声, P P P值又会变大,因为物体移动导致位置和速度的不确定性增加了。
-
每次更新后, x x x值经过修正后,会向实际的测量值贴合,可以看出测量的结果确实是在慢慢地修正模型。
-
你可以不更新,选连续预测再后一次的位置,预测位置结果为23.9263,与我们预想的结果24很接近