自动预测保险理赔:机器学习之特征预处理(Kaggle保险索赔竞赛案例)
原文地址:https://yq.aliyun.com/articles/65158?spm=5176.8091938.0.0.3Wl7HH
摘要: 针对Kaggle保险索赔竞赛给定的数据集,本文详细介绍了如何利用python对数据集进行分析并对特种进行预处理操作。以保险索赔竞赛案例和详细的操作步骤,生动形象的讲解了自动预测保险索赔的算法流程。
本文由北邮@爱可可-爱生活 老师推荐,阿里云云栖社区组织翻译。
以下为译文:
机器学习:特征预处理
我正在参加Kaggle竞赛,这是预测问题的竞赛,问题表述如下:
保险理赔是多么严重
当你在严重车祸中受到损伤,你重点关心的事是:家人,朋友和其他所爱的人。你希望你时间或精力花在最后的地方是将合同交给保险代理人,这也是为什么美国的私人保险公司Allstate正在不断寻求新的想法,给超过1600万受保的家庭提升理赔服务。
Allstate公司目前正在开发自动预测理赔的成本及严重程度的算法。在本次招募的挑战中,Kagglers被邀请,通过构造的精确预测理赔严重程度的算法来展示自己的创意及其灵活应用技术知识。有追求的竞争者将证明更好的方法去预测理赔的严重程度,这也成为Allstate公司确保用户无忧体验的努力中的一部分。
可以在这里查看数据,并轻松地在Excel中打开这些数据集,然后查看这些数据集中的变量/特征。数据集中有116个类别变量和14个连续变量,现在开始分析它
导入所有必要的模块:
# import required libraries
# pandas for reading data and manipulation
# scikit learn to one hot encoder and label encoder
# sns and matplotlib to visualize
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.feature_extraction import DictVectorizer
import operator
所有的这些模块应安装在你的机器上。本文使用的是Python 2.7.11。如果你已经安装这些模块,你可以简单地做下列操作
pip install
Example:
pip install pandas
使用pandas读取数据集
# read data from csv file
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')查看数据集
TRAIN DATA
**************************************
id cat1 cat2 cat3 cat4 cat5 cat6 cat7 cat8 cat9 ... cont6 \
0 1 A B A B A A A A B ... 0.718367
1 2 A B A A A A A A B ... 0.438917
2 5 A B A A B A A A B ... 0.289648
3 10 B B A B A A A A B ... 0.440945
4 11 A B A B A A A A B ... 0.178193
cont7 cont8 cont9 cont10 cont11 cont12 cont13 \
0 0.335060 0.30260 0.67135 0.83510 0.569745 0.594646 0.822493
1 0.436585 0.60087 0.35127 0.43919 0.338312 0.366307 0.611431
2 0.315545 0.27320 0.26076 0.32446 0.381398 0.373424 0.195709
3 0.391128 0.31796 0.32128 0.44467 0.327915 0.321570 0.605077
4 0.247408 0.24564 0.22089 0.21230 0.204687 0.202213 0.246011
cont14 loss
0 0.714843 2213.18
1 0.304496 1283.60
2 0.774425 3005.09
3 0.602642 939.85
4 0.432606 2763.85
[5 rows x 132 columns]
**************************************
TEST DATA
**************************************
id cat1 cat2 cat3 cat4 cat5 cat6 cat7 cat8 cat9 ... cont5 \
0 4 A B A A A A A A B ... 0.281143
1 6 A B A B A A A A B ... 0.836443
2 9 A B A B B A B A B ... 0.718531
3 12 A A A A B A A A A ... 0.397069
4 15 B A A A A B A A A ... 0.302678
cont6 cont7 cont8 cont9 cont10 cont11 cont12 \
0 0.466591 0.317681 0.61229 0.34365 0.38016 0.377724 0.369858
1 0.482425 0.443760 0.71330 0.51890 0.60401 0.689039 0.675759
2 0.212308 0.325779 0.29758 0.34365 0.30529 0.245410 0.241676
3 0.369930 0.342355 0.40028 0.33237 0.31480 0.348867 0.341872
4 0.398862 0.391833 0.23688 0.43731 0.50556 0.359572 0.352251
cont13 cont14
0 0.704052 0.392562
1 0.453468 0.208045
2 0.258586 0.297232
3 0.592264 0.555955
4 0.301535 0.825823
[5 rows x 131 columns]**************************************
TRAIN DATA
**************************************
id cat1 cat2 cat3 cat4 cat5 cat6 cat7 cat8 cat9 cat10 cat11 cat12 cat13 \
0 1 A B A B A A A A B A B A A
1 2 A B A A A A A A B B A A A
2 5 A B A A B A A A B B B B B
3 10 B B A B A A A A B A A A A
4 11 A B A B A A A A B B A B A
cat14 cat15 cat16 cat17 cat18 cat19 cat20 cat21 cat22 cat23 cat24 cat25 \
0 A A A A A A A A A B A A
1 A A A A A A A A A A A A
2 A A A A A A A A A A A A
3 A A A A A A A A A B A A
4 A A A A A A A A A B A A
cat26 cat27 cat28 cat29 cat30 cat31 cat32 cat33 cat34 cat35 cat36 cat37 \
0 A A A A A A A A A A A A
1 A A A A A A A A A A A A
2 A A A A A A A A A A B A
3 A A A A A A A A A A A A
4 A A A A A A A A A A A A
cat38 cat39 cat40 cat41 cat42 cat43 cat44 cat45 cat46 cat47 cat48 cat49 \
0 A A A A A A A A A A A A
1 A A A A A A A A A A A A
2 A A A A A A A A A A A A
3 A A A A A A A A A A A A
4 A A A A A A A A A A A A
cat50 cat51 cat52 cat53 cat54 cat55 cat56 cat57 cat58 cat59 cat60 cat61 \
0 A A A A A A A A A A A A
1 A A A A A A A A A A A A
2 A A A A A A A A A A A A
3 A A A A A A A A A A A A
4 A A A A A A A A A A A A
cat62 cat63 cat64 cat65 cat66 cat67 cat68 cat69 cat70 cat71 cat72 cat73 \
0 A A A A A A A A A A A A
1 A A A A A A A A A A A A
2 A A A A A A A A A A A A
3 A A A A A A A A A A A B
4 A A A A A A A A A A B A
cat74 cat75 cat76 cat77 cat78 cat79 cat80 cat81 cat82 cat83 cat84 cat85 \
0 A B A D B B D D B D C B
1 A A A D B B D D A B C B
2 A A A D B B B D B D C B
3 A A A D B B D D D B C B
4 A A A D B D B D B B C B
cat86 cat87 cat88 cat89 cat90 cat91 cat92 cat93 cat94 cat95 cat96 cat97 \
0 D B A A A A A D B C E A
1 D B A A A A A D D C E E
2 B B A A A A A D D C E E
3 D B A A A A A D D C E E
4 B C A A A B H D B D E E
cat98 cat99 cat100 cat101 cat102 cat103 cat104 cat105 cat106 cat107 cat108 \
0 C T B G A A I E G J G
1 D T L F A A E E I K K
2 A D L O A B E F H F A
3 D T I D A A E E I K K
4 A P F J A A D E K G B
cat109 cat110 cat111 cat112 cat113 cat114 cat115 cat116 cont1 cont2 \
0 BU BC C AS S A O LB 0.726300 0.245921
1 BI CQ A AV BM A O DP 0.330514 0.737068
2 AB DK A C AF A I GK 0.261841 0.358319
3 BI CS C N AE A O DJ 0.321594 0.555782
4 H C C Y BM A K CK 0.273204 0.159990
cont3 cont4 cont5 cont6 cont7 cont8 cont9 \
0 0.187583 0.789639 0.310061 0.718367 0.335060 0.30260 0.67135
1 0.592681 0.614134 0.885834 0.438917 0.436585 0.60087 0.35127
2 0.484196 0.236924 0.397069 0.289648 0.315545 0.27320 0.26076
3 0.527991 0.373816 0.422268 0.440945 0.391128 0.31796 0.32128
4 0.527991 0.473202 0.704268 0.178193 0.247408 0.24564 0.22089
cont10 cont11 cont12 cont13 cont14 loss
0 0.83510 0.569745 0.594646 0.822493 0.714843 2213.18
1 0.43919 0.338312 0.366307 0.611431 0.304496 1283.60
2 0.32446 0.381398 0.373424 0.195709 0.774425 3005.09
3 0.44467 0.327915 0.321570 0.605077 0.602642 939.85
4 0.21230 0.204687 0.202213 0.246011 0.432606 2763.85
**************************************
TEST DATA
**************************************
id cat1 cat2 cat3 cat4 cat5 cat6 cat7 cat8 cat9 cat10 cat11 cat12 cat13 \
0 4 A B A A A A A A B A B A A
1 6 A B A B A A A A B A A A A
2 9 A B A B B A B A B B A B B
3 12 A A A A B A A A A A A A A
4 15 B A A A A B A A A A A A A
cat14 cat15 cat16 cat17 cat18 cat19 cat20 cat21 cat22 cat23 cat24 cat25 \
0 A A A A A A A A A A A A
1 A A A A A A A A A B B A
2 B A A A A A A A A B A A
3 A A A A A A A A A A A A
4 A A A A A A A A A A A A
cat26 cat27 cat28 cat29 cat30 cat31 cat32 cat33 cat34 cat35 cat36 cat37 \
0 A A A A A A A A A A A A
1 A A A A A A A A A A A A
2 A A A A A A A A A A B A
3 A A A A A A A A A A B A
4 A A A A A A A A A A A A
cat38 cat39 cat40 cat41 cat42 cat43 cat44 cat45 cat46 cat47 cat48 cat49 \
0 A A A A A A A A A A A A
1 A A A A A A A A A A A A
2 B B A A A A A A A A A A
3 B A A B A A A A A A A A
4 A A A A A A A A A A A A
cat50 cat51 cat52 cat53 cat54 cat55 cat56 cat57 cat58 cat59 cat60 cat61 \
0 A A A A A A A A A A A A
1 A A A A A A A A A A A A
2 A A A A A A A B A A A A
3 A A A A A A A A A A A A
4 B A A A A A A A A A A A
cat62 cat63 cat64 cat65 cat66 cat67 cat68 cat69 cat70 cat71 cat72 cat73 \
0 A A A A A A A A A A A A
1 A A A A A A A A A A B A
2 A A A A A A A A A A A A
3 A A A A A A A A A A B A
4 A A A A A A A A A A A A
cat74 cat75 cat76 cat77 cat78 cat79 cat80 cat81 cat82 cat83 cat84 cat85 \
0 A A A D B B D D B B C B
1 A B A D B B D D B B C B
2 A A B D B B B B B D C B
3 A A A D B D B D B B A B
4 A A A D B B D D B B C B
cat86 cat87 cat88 cat89 cat90 cat91 cat92 cat93 cat94 cat95 cat96 cat97 \
0 D B A A A A A D C C E C
1 B B A A A A A D D D E A
2 B B A B A A A D D C E E
3 D D A A A G H D D C E E
4 B B A A A A A D B D E A
cat98 cat99 cat100 cat101 cat102 cat103 cat104 cat105 cat106 cat107 cat108 \
0 D T H G A A G E I L K
1 A P B D A A G G G F B
2 A D G Q A D D E J G A
3 D T G A A D E E I K K
4 A P A A A A F E G E B
cat109 cat110 cat111 cat112 cat113 cat114 cat115 cat116 cont1 cont2 \
0 BI BC A J AX A Q HG 0.321594 0.299102
1 BI CO E G X A L HK 0.634734 0.620805
2 BI CS C U AE A K CK 0.290813 0.737068
3 BI CR A AY AJ A P DJ 0.268622 0.681761
4 AB EG A E I C J HA 0.553846 0.299102
cont3 cont4 cont5 cont6 cont7 cont8 cont9 \
0 0.246911 0.402922 0.281143 0.466591 0.317681 0.61229 0.34365
1 0.654310 0.946616 0.836443 0.482425 0.443760 0.71330 0.51890
2 0.711159 0.412789 0.718531 0.212308 0.325779 0.29758 0.34365
3 0.592681 0.354893 0.397069 0.369930 0.342355 0.40028 0.33237
4 0.263570 0.696873 0.302678 0.398862 0.391833 0.23688 0.43731
cont10 cont11 cont12 cont13 cont14
0 0.38016 0.377724 0.369858 0.704052 0.392562
1 0.60401 0.689039 0.675759 0.453468 0.208045
2 0.30529 0.245410 0.241676 0.258586 0.297232
3 0.31480 0.348867 0.341872 0.592264 0.555955
4 0.50556 0.359572 0.352251 0.301535 0.825823
你可能会发现打印了两次相同的东西,第一次Python打印的是小数量的列和前五个观察结果,然而第二次打印的是所有的列和5个观察结果,这是因为
确保在头部有5,否则它会在屏幕上打印所有的一切,这将会是不漂亮的。查看训练集和测试集所有的列表示
print 'columns in train set : ', train.columns
print 'columns in test set : ', test.columns
这里存在两个数据集中的不需要分析的ID列,此外,将保留训练集中的损失列作为一个独立变量
# remove ID column. No use.
train.drop('id',axis=1,inplace=True)
test.drop('id',axis=1,inplace=True)
loss = train.drop('loss', axis = 1, inplace = True)
查看连续变量和其基本统计分析
# high level statistics. mean media mode count and quartiles
# note - this will work only for the continous variables
# not for the categorical variables
print train.describe()
print test.describe()## train
cont1 cont2 cont3 cont4 \
count 188318.000000 188318.000000 188318.000000 188318.000000
mean 0.493861 0.507188 0.498918 0.491812
std 0.187640 0.207202 0.202105 0.211292
min 0.000016 0.001149 0.002634 0.176921
25% 0.346090 0.358319 0.336963 0.327354
50% 0.475784 0.555782 0.527991 0.452887
75% 0.623912 0.681761 0.634224 0.652072
max 0.984975 0.862654 0.944251 0.954297
cont5 cont6 cont7 cont8 \
count 188318.000000 188318.000000 188318.000000 188318.000000
mean 0.487428 0.490945 0.484970 0.486437
std 0.209027 0.205273 0.178450 0.199370
min 0.281143 0.012683 0.069503 0.236880
25% 0.281143 0.336105 0.350175 0.312800
50% 0.422268 0.440945 0.438285 0.441060
75% 0.643315 0.655021 0.591045 0.623580
max 0.983674 0.997162 1.000000 0.980200
cont9 cont10 cont11 cont12 \
count 188318.000000 188318.000000 188318.000000 188318.000000
mean 0.485506 0.498066 0.493511 0.493150
std 0.181660 0.185877 0.209737 0.209427
min 0.000080 0.000000 0.035321 0.036232
25% 0.358970 0.364580 0.310961 0.311661
50% 0.441450 0.461190 0.457203 0.462286
75% 0.566820 0.614590 0.678924 0.675759
max 0.995400 0.994980 0.998742 0.998484
cont13 cont14
count 188318.000000 188318.000000
mean 0.493138 0.495717
std 0.212777 0.222488
min 0.000228 0.179722
25% 0.315758 0.294610
50% 0.363547 0.407403
75% 0.689974 0.724623
max 0.988494 0.844848在很多竞争中,会发现有一些特征是在训练集中,但不在测试集中,反之亦然。
# at this point, it is wise to check whether there are any features that
# are there is one of the dataset but not in other
missingFeatures = False
inTrainNotTest = []
for feature in train.columns:
if feature not in test.columns:
missingFeatures = True
inTrainNotTest.append(feature)
if len(inTrainNotTest)>0:
print ', '. join(inTrainNotTest), ' features are present in training set but not in test set'
inTestNotTrain = []
for feature in test.columns:
if feature not in train.columns:
missingFeatures = True
inTestNotTrain.append(feature)
if len(inTestNotTrain)>0:
print ', '. join(inTestNotTrain), ' features are present in test set but not in training set'在这种情况下,将看到训练集和测试集之间存在不同的列。
现在区类别变量和连续变量,对于给定的数据集,有两种方式去找到它们:
1.变量中有‘cat’和‘cont’,定义它们;
2.利用pandas考虑数据类型;
# find categorical variables
# in this problem, categorical variables are start with cat which is easy
# to identify
# in other problems it not might be like that
# we will see two ways to identify this in this problem
# we will also find the continous or numerical variables
## 1. by name
categorical_train = [var for var in train.columns if 'cat' in var]
categorical_test = [var for var in test.columns if 'cat' in var]
continous_train = [var for var in train.columns if 'cont' in var]
continous_test = [var for var in test.columns if 'cont' in var]
## 2. by type = object
categorical_train = train.dtypes[train.dtypes == "object"].index
categorical_test = test.dtypes[test.dtypes == "object"].index
continous_train = train.dtypes[train.dtypes != "object"].index
continous_test = test.dtypes[test.dtypes != "object"].index连续变量之间的相关性
查看这些变量之间的相关性,这样做的目的是为了除去高度相关的变量
# lets check for correlation between continous data
# correlation between numerical variables is something like this
# if we increase one variable, there is a siginficant almost increase/decrease
# in the other variable. it varies from -1 to 1
correlation_train = train[continous_train].corr()
correlation_test = train[continous_test].corr()
# for the purpose of this analysis, we will consider to variables to
# highly correlation if the correlation is more than 0.6
threshold = 0.6
for i in range(len(correlation_train)):
for j in range(len(correlation_train)):
if (i>j) and (correlation_train.iloc[i,j]>threshold):
print ("%s and %s = %.2f" % (train.columns[i],train.columns[j],correlation_train.iloc[i,j]))
for i in range(len(correlation_test)):
for j in range(len(correlation_test)):
if (i>j) and (correlation_test.iloc[i,j]>threshold):
print ("%s and %s = %.2f" % (test.columns[i],test.columns[j],correlation_test.iloc[i,j]))
# we can remove one of the two highly correlatied variables to improve performancecat6 and cat1 = 0.76
cat7 and cat6 = 0.66
cat9 and cat1 = 0.93
cat9 and cat6 = 0.80
cat10 and cat1 = 0.81
cat10 and cat6 = 0.88
cat10 and cat9 = 0.79
cat11 and cat6 = 0.77
cat11 and cat7 = 0.75
cat11 and cat9 = 0.61
cat11 and cat10 = 0.70
cat12 and cat1 = 0.61
cat12 and cat6 = 0.79
cat12 and cat7 = 0.74
cat12 and cat9 = 0.63
cat12 and cat10 = 0.71
cat12 and cat11 = 0.99
cat13 and cat6 = 0.82
cat13 and cat9 = 0.64
cat13 and cat10 = 0.71
cat6 and cat1 = 0.76
cat7 and cat6 = 0.66
cat9 and cat1 = 0.93
cat9 and cat6 = 0.80
cat10 and cat1 = 0.81
cat10 and cat6 = 0.88
cat10 and cat9 = 0.79
cat11 and cat6 = 0.77
cat11 and cat7 = 0.75
cat11 and cat9 = 0.61
cat11 and cat10 = 0.70
cat12 and cat1 = 0.61
cat12 and cat6 = 0.79
cat12 and cat7 = 0.74
cat12 and cat9 = 0.63
cat12 and cat10 = 0.71
cat12 and cat11 = 0.99
cat13 and cat6 = 0.82
cat13 and cat9 = 0.64
cat13 and cat10 = 0.71
查看目前在类别变量处的标签,即使没有任何不同的列,一些标签可能不会在这个或其它数据集中出现
# lets check for factors in the categorical variables
for feature in categorical_train:
print feature, 'has ', len(train[feature].unique()), 'values. Unique values are :: ', train[feature].unique()
for feature in categorical_test:
print feature, 'has ', len(test[feature].unique()), 'values. Unique values are :: ', test[feature].unique()
# lets take a look whether the unique values/factors are not present in each of the dataset
# for example cat1 in both the datasets has values only A & B. Sometimes
# it may happen that some new value is present in the test set which maybe ruin your model
featuresDone = []
for feature in categorical_train:
if feature in categorical_test:
if set(train[feature].unique()) - set(test[feature].unique()) != set([]):
print 'Train set has ', len(train[feature].unique()), 'values. Unique values are :: ', train[feature].unique(), '\n'
print 'test set has ', len(test[feature].unique()), 'values. Unique values are :: ', test[feature].unique(), '\n'
print 'Missing vaues are : ', set(train[feature].unique()) - set(test[feature].unique())
featuresDone.append(feature)
for feature in categorical_test:
if (feature in categorical_train) and (feature not in featuresDone):
if set(train[feature].unique()) - set(test[feature].unique()) != set([]):
print 'Train set has ', len(train[feature].unique()), 'values. Unique values are :: ', train[feature].unique(), '\n'
print 'test set has ', len(test[feature].unique()), 'values. Unique values are :: ', test[feature].unique(), '\n'
print 'Missing vaues are : ', set(train[feature].unique()) - set(test[feature].unique())
featuresDone.append(feature)cat1 has 2 values. Unique values are :: ['A' 'B']
cat2 has 2 values. Unique values are :: ['B' 'A']
cat3 has 2 values. Unique values are :: ['A' 'B']
cat4 has 2 values. Unique values are :: ['B' 'A']
cat5 has 2 values. Unique values are :: ['A' 'B']
cat6 has 2 values. Unique values are :: ['A' 'B']
cat7 has 2 values. Unique values are :: ['A' 'B']
cat8 has 2 values. Unique values are :: ['A' 'B']
cat9 has 2 values. Unique values are :: ['B' 'A']
cat10 has 2 values. Unique values are :: ['A' 'B']
cat11 has 2 values. Unique values are :: ['B' 'A']
cat12 has 2 values. Unique values are :: ['A' 'B']
cat13 has 2 values. Unique values are :: ['A' 'B']
cat14 has 2 values. Unique values are :: ['A' 'B']
cat15 has 2 values. Unique values are :: ['A' 'B']
cat16 has 2 values. Unique values are :: ['A' 'B']
cat17 has 2 values. Unique values are :: ['A' 'B']
cat18 has 2 values. Unique values are :: ['A' 'B']
cat19 has 2 values. Unique values are :: ['A' 'B']
cat20 has 2 values. Unique values are :: ['A' 'B']
cat21 has 2 values. Unique values are :: ['A' 'B']
cat22 has 2 values. Unique values are :: ['A' 'B']
cat23 has 2 values. Unique values are :: ['B' 'A']
cat24 has 2 values. Unique values are :: ['A' 'B']
cat25 has 2 values. Unique values are :: ['A' 'B']
cat26 has 2 values. Unique values are :: ['A' 'B']
cat27 has 2 values. Unique values are :: ['A' 'B']
cat28 has 2 values. Unique values are :: ['A' 'B']
cat29 has 2 values. Unique values are :: ['A' 'B']
cat30 has 2 values. Unique values are :: ['A' 'B']
cat31 has 2 values. Unique values are :: ['A' 'B']
cat32 has 2 values. Unique values are :: ['A' 'B']
cat33 has 2 values. Unique values are :: ['A' 'B']
cat34 has 2 values. Unique values are :: ['A' 'B']
cat35 has 2 values. Unique values are :: ['A' 'B']
cat36 has 2 values. Unique values are :: ['A' 'B']
cat37 has 2 values. Unique values are :: ['A' 'B']
cat38 has 2 values. Unique values are :: ['A' 'B']
cat39 has 2 values. Unique values are :: ['A' 'B']
cat40 has 2 values. Unique values are :: ['A' 'B']
cat41 has 2 values. Unique values are :: ['A' 'B']
cat42 has 2 values. Unique values are :: ['A' 'B']
cat43 has 2 values. Unique values are :: ['A' 'B']
cat44 has 2 values. Unique values are :: ['A' 'B']
cat45 has 2 values. Unique values are :: ['A' 'B']
cat46 has 2 values. Unique values are :: ['A' 'B']
cat47 has 2 values. Unique values are :: ['A' 'B']
cat48 has 2 values. Unique values are :: ['A' 'B']
cat49 has 2 values. Unique values are :: ['A' 'B']
cat50 has 2 values. Unique values are :: ['A' 'B']
cat51 has 2 values. Unique values are :: ['A' 'B']
cat52 has 2 values. Unique values are :: ['A' 'B']
cat53 has 2 values. Unique values are :: ['A' 'B']
cat54 has 2 values. Unique values are :: ['A' 'B']
cat55 has 2 values. Unique values are :: ['A' 'B']
cat56 has 2 values. Unique values are :: ['A' 'B']
cat57 has 2 values. Unique values are :: ['A' 'B']
cat58 has 2 values. Unique values are :: ['A' 'B']
cat59 has 2 values. Unique values are :: ['A' 'B']
cat60 has 2 values. Unique values are :: ['A' 'B']
cat61 has 2 values. Unique values are :: ['A' 'B']
cat62 has 2 values. Unique values are :: ['A' 'B']
cat63 has 2 values. Unique values are :: ['A' 'B']
cat64 has 2 values. Unique values are :: ['A' 'B']
cat65 has 2 values. Unique values are :: ['A' 'B']
cat66 has 2 values. Unique values are :: ['A' 'B']
cat67 has 2 values. Unique values are :: ['A' 'B']
cat68 has 2 values. Unique values are :: ['A' 'B']
cat69 has 2 values. Unique values are :: ['A' 'B']
cat70 has 2 values. Unique values are :: ['A' 'B']
cat71 has 2 values. Unique values are :: ['A' 'B']
cat72 has 2 values. Unique values are :: ['A' 'B']
cat73 has 3 values. Unique values are :: ['A' 'B' 'C']
cat74 has 3 values. Unique values are :: ['A' 'B' 'C']
cat75 has 3 values. Unique values are :: ['B' 'A' 'C']
cat76 has 3 values. Unique values are :: ['A' 'C' 'B']
cat77 has 4 values. Unique values are :: ['D' 'C' 'B' 'A']
cat78 has 4 values. Unique values are :: ['B' 'A' 'C' 'D']
cat79 has 4 values. Unique values are :: ['B' 'D' 'A' 'C']
cat80 has 4 values. Unique values are :: ['D' 'B' 'A' 'C']
cat81 has 4 values. Unique values are :: ['D' 'B' 'A' 'C']
cat82 has 4 values. Unique values are :: ['B' 'A' 'D' 'C']
cat83 has 4 values. Unique values are :: ['D' 'B' 'A' 'C']
cat84 has 4 values. Unique values are :: ['C' 'A' 'D' 'B']
cat85 has 4 values. Unique values are :: ['B' 'A' 'C' 'D']
cat86 has 4 values. Unique values are :: ['D' 'B' 'C' 'A']
cat87 has 4 values. Unique values are :: ['B' 'C' 'D' 'A']
cat88 has 4 values. Unique values are :: ['A' 'D' 'E' 'B']
cat89 has 8 values. Unique values are :: ['A' 'B' 'C' 'E' 'D' 'H' 'I' 'G']
cat90 has 7 values. Unique values are :: ['A' 'B' 'C' 'D' 'F' 'E' 'G']
cat91 has 8 values. Unique values are :: ['A' 'B' 'G' 'C' 'D' 'E' 'F' 'H']
cat92 has 7 values. Unique values are :: ['A' 'H' 'B' 'C' 'D' 'I' 'F']
cat93 has 5 values. Unique values are :: ['D' 'C' 'A' 'B' 'E']
cat94 has 7 values. Unique values are :: ['B' 'D' 'C' 'A' 'F' 'E' 'G']
cat95 has 5 values. Unique values are :: ['C' 'D' 'E' 'A' 'B']
cat96 has 8 values. Unique values are :: ['E' 'D' 'G' 'B' 'F' 'A' 'I' 'C']
cat97 has 7 values. Unique values are :: ['A' 'E' 'C' 'G' 'D' 'F' 'B']
cat98 has 5 values. Unique values are :: ['C' 'D' 'A' 'E' 'B']
cat99 has 16 values. Unique values are :: ['T' 'D' 'P' 'S' 'R' 'K' 'E' 'F' 'N' 'J' 'C' 'M' 'H' 'G' 'I' 'O']
cat100 has 15 values. Unique values are :: ['B' 'L' 'I' 'F' 'J' 'H' 'C' 'M' 'A' 'G' 'O' 'N' 'K' 'D' 'E']
cat101 has 19 values. Unique values are :: ['G' 'F' 'O' 'D' 'J' 'A' 'C' 'Q' 'M' 'I' 'L' 'R' 'S' 'E' 'N' 'H' 'B' 'U'
'K']
cat102 has 9 values. Unique values are :: ['A' 'C' 'B' 'D' 'G' 'E' 'F' 'H' 'J']
cat103 has 13 values. Unique values are :: ['A' 'B' 'C' 'F' 'E' 'D' 'G' 'H' 'I' 'L' 'K' 'J' 'N']
cat104 has 17 values. Unique values are :: ['I' 'E' 'D' 'K' 'H' 'F' 'G' 'P' 'C' 'J' 'L' 'M' 'N' 'O' 'B' 'A' 'Q']
cat105 has 20 values. Unique values are :: ['E' 'F' 'H' 'G' 'I' 'D' 'J' 'K' 'M' 'C' 'A' 'L' 'N' 'P' 'T' 'Q' 'R' 'O'
'B' 'S']
cat106 has 17 values. Unique values are :: ['G' 'I' 'H' 'K' 'F' 'J' 'E' 'L' 'M' 'D' 'A' 'C' 'N' 'O' 'R' 'B' 'P']
cat107 has 20 values. Unique values are :: ['J' 'K' 'F' 'G' 'I' 'M' 'H' 'L' 'E' 'D' 'O' 'C' 'N' 'A' 'Q' 'P' 'U' 'B'
'R' 'S']
cat108 has 11 values. Unique values are :: ['G' 'K' 'A' 'B' 'D' 'I' 'F' 'H' 'E' 'C' 'J']
cat109 has 84 values. Unique values are :: ['BU' 'BI' 'AB' 'H' 'K' 'CD' 'BQ' 'M' 'G' 'BL' 'L' 'AL' 'N' 'CL' 'R' 'F'
'BJ' 'AR' 'AT' 'S' 'AS' 'BO' 'X' 'D' 'BM' 'I' 'BH' 'CI' 'CF' 'C' 'AM' 'U'
'BE' 'BR' 'CJ' 'AE' 'A' 'Q' 'AW' 'T' 'AJ' 'AH' 'BA' 'BV' 'CC' 'CA' 'BG'
'BB' 'O' 'BD' 'AV' 'AX' 'AQ' 'AA' 'AI' 'AU' 'BX' 'AP' 'CK' 'Y' 'CH' 'BS'
'AN' 'AO' 'BC' 'CE' 'E' 'BY' 'CB' 'BT' 'P' 'BK' 'AF' 'B' 'BF' 'CG' 'V'
'ZZ' 'AY' 'BP' 'BN' 'J' 'AG' 'AK']
cat110 has 131 values. Unique values are :: ['BC' 'CQ' 'DK' 'CS' 'C' 'EB' 'DW' 'AM' 'AI' 'EG' 'CL' 'BS' 'BT' 'CO' 'CM'
'EL' 'AY' 'W' 'EE' 'AC' 'DX' 'CI' 'DT' 'A' 'V' 'DM' 'EF' 'DL' 'DA' 'BP'
'DH' 'CF' 'N' 'T' 'CR' 'X' 'CH' 'EM' 'DC' 'AX' 'BG' 'CJ' 'EA' 'AD' 'U'
'AK' 'BX' 'AW' 'G' 'BA' 'L' 'AP' 'CG' 'R' 'DU' 'I' 'AR' 'O' 'DF' 'AT' 'E'
'AB' 'AU' 'DI' 'CN' 'CP' 'AL' 'ED' 'DJ' 'AO' 'CY' 'BE' 'BJ' 'D' 'AA' 'CK'
'CV' 'BK' 'BB' 'AE' 'BO' 'P' 'DO' 'CT' 'AJ' 'BR' 'Y' 'DR' 'BQ' 'BL' 'B'
'BW' 'H' 'DP' 'DG' 'AG' 'BN' 'J' 'CW' 'DV' 'Q' 'DY' 'EI' 'AV' 'DQ' 'BU'
'K' 'BF' 'BD' 'DS' 'DE' 'BM' 'BY' 'CD' 'BI' 'DD' 'DB' 'AH' 'CC' 'DN' 'CU'
'BV' 'CX' 'AN' 'EK' 'EJ' 'AS' 'AF' 'CB' 'EH' 'S']
cat111 has 16 values. Unique values are :: ['C' 'A' 'G' 'E' 'I' 'M' 'W' 'S' 'K' 'O' 'Q' 'U' 'F' 'B' 'Y' 'D']
cat112 has 51 values. Unique values are :: ['AS' 'AV' 'C' 'N' 'Y' 'J' 'AH' 'K' 'U' 'E' 'AK' 'AI' 'AE' 'A' 'L' 'F' 'AP'
'AD' 'AF' 'AL' 'AN' 'S' 'AW' 'I' 'AR' 'AX' 'AU' 'AQ' 'O' 'AO' 'R' 'H' 'G'
'AC' 'AT' 'AG' 'X' 'AA' 'Q' 'AY' 'D' 'BA' 'P' 'B' 'AM' 'M' 'T' 'W' 'V'
'AB' 'AJ']
cat113 has 61 values. Unique values are :: ['S' 'BM' 'AF' 'AE' 'Y' 'AX' 'H' 'K' 'L' 'A' 'J' 'AK' 'N' 'M' 'AJ' 'AT' 'F'
'BC' 'AY' 'AD' 'BG' 'BO' 'AS' 'BD' 'AN' 'I' 'BF' 'BK' 'AW' 'AG' 'BJ' 'AO'
'Q' 'AM' 'X' 'AU' 'BN' 'BH' 'AI' 'C' 'AV' 'AQ' 'AH' 'G' 'E' 'BA' 'AL' 'BI'
'U' 'AB' 'V' 'O' 'BB' 'AP' 'B' 'BL' 'BE' 'T' 'P' 'AC' 'AR']
cat114 has 19 values. Unique values are :: ['A' 'J' 'E' 'C' 'F' 'L' 'N' 'I' 'R' 'U' 'O' 'B' 'Q' 'V' 'D' 'X' 'W' 'S'
'G']
cat115 has 23 values. Unique values are :: ['O' 'I' 'K' 'P' 'Q' 'L' 'J' 'R' 'N' 'M' 'H' 'G' 'F' 'A' 'S' 'W' 'T' 'C'
'E' 'D' 'B' 'X' 'U']
cat116 has 326 values. Unique values are :: ['LB' 'DP' 'GK' 'DJ' 'CK' 'LO' 'IE' 'LY' 'GS' 'HK' 'DC' 'MP' 'DS' 'LE' 'HQ'
'HJ' 'GC' 'BY' 'HX' 'HL' 'HG' 'MD' 'LF' 'LM' 'CB' 'CS' 'KQ' 'HN' 'LQ' 'KW'
'IT' 'LN' 'CW' 'LC' 'GX' 'GE' 'CP' 'HB' 'GI' 'GM' 'CR' 'JR' 'HA' 'EE' 'BA'
'LJ' 'IH' 'HV' 'GU' 'HM' 'CY' 'IC' 'KD' 'KI' 'DN' 'MG' 'LL' 'KN' 'LH' 'DF'
'EY' 'LW' 'KA' 'EK' 'DK' 'EO' 'CG' 'K' 'HC' 'DI' 'FB' 'IG' 'FR' 'CI' 'EC'
'KR' 'HI' 'IU' 'MC' 'BP' 'JW' 'FH' 'IF' 'E' 'DA' 'KL' 'LX' 'IL' 'KB' 'IQ'
'EL' 'JX' 'H' 'GN' 'CD' 'DH' 'AC' 'FD' 'ME' 'KC' 'FT' 'CT' 'DM' 'GL' 'ES'
'JL' 'BX' 'II' 'HP' 'ED' 'CU' 'EN' 'FG' 'MJ' 'KE' 'CF' 'EB' 'DD' 'EI' 'FX'
'EA' 'BO' 'KP' 'EP' 'FC' 'GB' 'JU' 'LV' 'CO' 'EF' 'BD' 'HW' 'LI' 'GT' 'HH'
'KJ' 'CN' 'B' 'FE' 'GA' 'FW' 'IY' 'MO' 'JG' 'ID' 'DX' 'FA' 'LA' 'HR' 'GJ'
'GO' 'KT' 'GW' 'U' 'MI' 'GP' 'F' 'DU' 'KM' 'BV' 'DT' 'IM' 'LD' 'GR' 'HD'
'BS' 'AJ' 'KX' 'LR' 'ML' 'KU' 'CE' 'IA' 'DE' 'R' 'AO' 'MU' 'AK' 'CX' 'HY'
'EH' 'MA' 'GH' 'LK' 'DL' 'AX' 'IN' 'BI' 'JM' 'JF' 'KK' 'DR' 'LT' 'GF' 'AW'
'KY' 'CA' 'MK' 'DV' 'EG' 'DW' 'MN' 'V' 'CM' 'GY' 'AF' 'JC' 'MR' 'JE' 'IP'
'KV' 'KH' 'BW' 'MQ' 'D' 'HF' 'CV' 'BL' 'FL' 'GV' 'CQ' 'BM' 'JB' 'J' 'FU'
'AG' 'EJ' 'CH' 'MW' 'X' 'DG' 'AV' 'EW' 'O' 'DO' 'BK' 'FS' 'T' 'CL' 'Y'
'JQ' 'I' 'AL' 'JJ' 'HT' 'FF' 'JA' 'GD' 'FV' 'BQ' 'M' 'S' 'EU' 'P' 'FJ'
'AR' 'LG' 'IR' 'GQ' 'MM' 'AY' 'MF' 'GG' 'KG' 'JD' 'L' 'KS' 'AH' 'JV' 'EV'
'CC' 'AB' 'FK' 'JY' 'G' 'W' 'BC' 'AM' 'KF' 'LU' 'IK' 'BU' 'AT' 'JP' 'Q'
'IJ' 'JO' 'JH' 'AS' 'JN' 'BF' 'AD' 'FP' 'MV' 'AA' 'CJ' 'DY' 'IB' 'AN' 'EQ'
'JT' 'BG' 'AP' 'MB' 'JK' 'FI' 'MS' 'HE' 'C' 'IV' 'IO' 'BT' 'DQ' 'FM' 'HO'
'MH' 'MT' 'FO' 'JI' 'FQ' 'AU' 'FN' 'BB' 'HU' 'IX' 'AE']
cat1 has 2 values. Unique values are :: ['A' 'B']
cat2 has 2 values. Unique values are :: ['B' 'A']
cat3 has 2 values. Unique values are :: ['A' 'B']
cat4 has 2 values. Unique values are :: ['A' 'B']
cat5 has 2 values. Unique values are :: ['A' 'B']
cat6 has 2 values. Unique values are :: ['A' 'B']
cat7 has 2 values. Unique values are :: ['A' 'B']
cat8 has 2 values. Unique values are :: ['A' 'B']
cat9 has 2 values. Unique values are :: ['B' 'A']
cat10 has 2 values. Unique values are :: ['A' 'B']
cat11 has 2 values. Unique values are :: ['B' 'A']
cat12 has 2 values. Unique values are :: ['A' 'B']
cat13 has 2 values. Unique values are :: ['A' 'B']
cat14 has 2 values. Unique values are :: ['A' 'B']
cat15 has 2 values. Unique values are :: ['A' 'B']
cat16 has 2 values. Unique values are :: ['A' 'B']
cat17 has 2 values. Unique values are :: ['A' 'B']
cat18 has 2 values. Unique values are :: ['A' 'B']
cat19 has 2 values. Unique values are :: ['A' 'B']
cat20 has 2 values. Unique values are :: ['A' 'B']
cat21 has 2 values. Unique values are :: ['A' 'B']
cat22 has 2 values. Unique values are :: ['A' 'B']
cat23 has 2 values. Unique values are :: ['A' 'B']
cat24 has 2 values. Unique values are :: ['A' 'B']
cat25 has 2 values. Unique values are :: ['A' 'B']
cat26 has 2 values. Unique values are :: ['A' 'B']
cat27 has 2 values. Unique values are :: ['A' 'B']
cat28 has 2 values. Unique values are :: ['A' 'B']
cat29 has 2 values. Unique values are :: ['A' 'B']
cat30 has 2 values. Unique values are :: ['A' 'B']
cat31 has 2 values. Unique values are :: ['A' 'B']
cat32 has 2 values. Unique values are :: ['A' 'B']
cat33 has 2 values. Unique values are :: ['A' 'B']
cat34 has 2 values. Unique values are :: ['A' 'B']
cat35 has 2 values. Unique values are :: ['A' 'B']
cat36 has 2 values. Unique values are :: ['A' 'B']
cat37 has 2 values. Unique values are :: ['A' 'B']
cat38 has 2 values. Unique values are :: ['A' 'B']
cat39 has 2 values. Unique values are :: ['A' 'B']
cat40 has 2 values. Unique values are :: ['A' 'B']
cat41 has 2 values. Unique values are :: ['A' 'B']
cat42 has 2 values. Unique values are :: ['A' 'B']
cat43 has 2 values. Unique values are :: ['A' 'B']
cat44 has 2 values. Unique values are :: ['A' 'B']
cat45 has 2 values. Unique values are :: ['A' 'B']
cat46 has 2 values. Unique values are :: ['A' 'B']
cat47 has 2 values. Unique values are :: ['A' 'B']
cat48 has 2 values. Unique values are :: ['A' 'B']
cat49 has 2 values. Unique values are :: ['A' 'B']
cat50 has 2 values. Unique values are :: ['A' 'B']
cat51 has 2 values. Unique values are :: ['A' 'B']
cat52 has 2 values. Unique values are :: ['A' 'B']
cat53 has 2 values. Unique values are :: ['A' 'B']
cat54 has 2 values. Unique values are :: ['A' 'B']
cat55 has 2 values. Unique values are :: ['A' 'B']
cat56 has 2 values. Unique values are :: ['A' 'B']
cat57 has 2 values. Unique values are :: ['A' 'B']
cat58 has 2 values. Unique values are :: ['A' 'B']
cat59 has 2 values. Unique values are :: ['A' 'B']
cat60 has 2 values. Unique values are :: ['A' 'B']
cat61 has 2 values. Unique values are :: ['A' 'B']
cat62 has 2 values. Unique values are :: ['A' 'B']
cat63 has 2 values. Unique values are :: ['A' 'B']
cat64 has 2 values. Unique values are :: ['A' 'B']
cat65 has 2 values. Unique values are :: ['A' 'B']
cat66 has 2 values. Unique values are :: ['A' 'B']
cat67 has 2 values. Unique values are :: ['A' 'B']
cat68 has 2 values. Unique values are :: ['A' 'B']
cat69 has 2 values. Unique values are :: ['A' 'B']
cat70 has 2 values. Unique values are :: ['A' 'B']
cat71 has 2 values. Unique values are :: ['A' 'B']
cat72 has 2 values. Unique values are :: ['A' 'B']
cat73 has 3 values. Unique values are :: ['A' 'B' 'C']
cat74 has 3 values. Unique values are :: ['A' 'B' 'C']
cat75 has 3 values. Unique values are :: ['A' 'B' 'C']
cat76 has 3 values. Unique values are :: ['A' 'B' 'C']
cat77 has 4 values. Unique values are :: ['D' 'C' 'B' 'A']
cat78 has 4 values. Unique values are :: ['B' 'D' 'C' 'A']
cat79 has 4 values. Unique values are :: ['B' 'D' 'A' 'C']
cat80 has 4 values. Unique values are :: ['D' 'B' 'C' 'A']
cat81 has 4 values. Unique values are :: ['D' 'B' 'C' 'A']
cat82 has 4 values. Unique values are :: ['B' 'A' 'D' 'C']
cat83 has 4 values. Unique values are :: ['B' 'D' 'A' 'C']
cat84 has 4 values. Unique values are :: ['C' 'A' 'D' 'B']
cat85 has 4 values. Unique values are :: ['B' 'D' 'C' 'A']
cat86 has 4 values. Unique values are :: ['D' 'B' 'C' 'A']
cat87 has 4 values. Unique values are :: ['B' 'D' 'C' 'A']
cat88 has 4 values. Unique values are :: ['A' 'D' 'E' 'B']
cat89 has 8 values. Unique values are :: ['A' 'B' 'D' 'C' 'F' 'H' 'E' 'G']
cat90 has 6 values. Unique values are :: ['A' 'B' 'C' 'D' 'F' 'E']
cat91 has 8 values. Unique values are :: ['A' 'G' 'B' 'C' 'E' 'D' 'F' 'H']
cat92 has 8 values. Unique values are :: ['A' 'H' 'B' 'C' 'G' 'I' 'D' 'E']
cat93 has 5 values. Unique values are :: ['D' 'E' 'C' 'B' 'A']
cat94 has 7 values. Unique values are :: ['C' 'D' 'B' 'E' 'F' 'A' 'G']
cat95 has 5 values. Unique values are :: ['C' 'D' 'E' 'A' 'B']
cat96 has 9 values. Unique values are :: ['E' 'B' 'G' 'D' 'F' 'I' 'A' 'C' 'H']
cat97 has 7 values. Unique values are :: ['C' 'A' 'E' 'G' 'D' 'F' 'B']
cat98 has 5 values. Unique values are :: ['D' 'A' 'C' 'E' 'B']
cat99 has 17 values. Unique values are :: ['T' 'P' 'D' 'H' 'R' 'F' 'K' 'S' 'N' 'C' 'E' 'J' 'I' 'G' 'M' 'U' 'O']
cat100 has 15 values. Unique values are :: ['H' 'B' 'G' 'A' 'F' 'I' 'L' 'K' 'J' 'N' 'O' 'M' 'D' 'C' 'E']
cat101 has 17 values. Unique values are :: ['G' 'D' 'Q' 'A' 'F' 'M' 'L' 'O' 'C' 'I' 'J' 'S' 'R' 'E' 'B' 'H' 'K']
cat102 has 7 values. Unique values are :: ['A' 'C' 'B' 'E' 'D' 'G' 'F']
cat103 has 14 values. Unique values are :: ['A' 'D' 'C' 'B' 'E' 'F' 'G' 'I' 'H' 'K' 'J' 'M' 'L' 'N']
cat104 has 17 values. Unique values are :: ['G' 'D' 'E' 'F' 'H' 'K' 'I' 'O' 'L' 'C' 'J' 'M' 'N' 'P' 'B' 'A' 'Q']
cat105 has 18 values. Unique values are :: ['E' 'G' 'F' 'H' 'I' 'D' 'J' 'A' 'L' 'C' 'K' 'N' 'M' 'P' 'O' 'T' 'B' 'Q']
cat106 has 18 values. Unique values are :: ['I' 'G' 'J' 'D' 'F' 'K' 'H' 'E' 'L' 'M' 'A' 'O' 'C' 'N' 'R' 'B' 'Q' 'P']
cat107 has 20 values. Unique values are :: ['L' 'F' 'G' 'K' 'E' 'D' 'C' 'M' 'H' 'I' 'J' 'A' 'O' 'S' 'P' 'N' 'Q' 'U'
'R' 'B']
cat108 has 11 values. Unique values are :: ['K' 'B' 'A' 'G' 'D' 'F' 'E' 'H' 'J' 'I' 'C']
cat109 has 74 values. Unique values are :: ['BI' 'AB' 'K' 'G' 'BU' 'M' 'I' 'O' 'BO' 'CD' 'T' 'BQ' 'R' 'X' 'AR' 'E'
'BL' 'CI' 'S' 'AL' 'BH' 'N' 'U' 'F' 'AS' 'AQ' 'AW' 'CC' 'AN' 'AJ' 'C' 'AT'
'D' 'H' 'CA' 'A' 'AX' 'L' 'BD' 'V' 'BX' 'AH' 'CL' 'AM' 'BA' 'BR' 'AO' 'AE'
'AY' 'BB' 'BJ' 'AP' 'BN' 'AI' 'Q' 'BS' 'CK' 'AU' 'CE' 'BC' 'BG' 'AD' 'Y'
'BK' 'AA' 'CG' 'AV' 'P' 'AF' 'CB' 'CF' 'BE' 'CH' 'ZZ']
cat110 has 123 values. Unique values are :: ['BC' 'CO' 'CS' 'CR' 'EG' 'CL' 'EL' 'BT' 'EB' 'CQ' 'BS' 'C' 'W' 'DX' 'CM'
'A' 'EF' 'CI' 'DL' 'AI' 'BP' 'N' 'DJ' 'CT' 'E' 'DW' 'CH' 'V' 'AM' 'DK'
'EA' 'BR' 'DR' 'D' 'EE' 'T' 'AP' 'I' 'AC' 'CY' 'DM' 'AL' 'CK' 'AD' 'AY'
'CF' 'CD' 'BG' 'AK' 'DA' 'DC' 'DQ' 'BA' 'U' 'CX' 'BJ' 'AV' 'AR' 'K' 'CG'
'DT' 'CN' 'O' 'BO' 'DU' 'CJ' 'AX' 'DH' 'BX' 'AH' 'AU' 'AB' 'BV' 'EM' 'L'
'BH' 'DI' 'DB' 'DE' 'CV' 'DO' 'BQ' 'AW' 'AJ' 'J' 'CU' 'P' 'CP' 'DS' 'BL'
'AO' 'AA' 'DF' 'DG' 'CC' 'X' 'BF' 'AE' 'BU' 'AT' 'BB' 'B' 'ED' 'Y' 'G'
'BE' 'DD' 'DY' 'DP' 'R' 'CW' 'DN' 'AG' 'BW' 'BY' 'EK' 'CA' 'AS' 'EJ' 'BM'
'Q' 'S' 'EN']
cat111 has 16 values. Unique values are :: ['A' 'E' 'C' 'G' 'K' 'I' 'Q' 'U' 'M' 'O' 'S' 'F' 'L' 'W' 'Y' 'B']
cat112 has 51 values. Unique values are :: ['J' 'G' 'U' 'AY' 'E' 'AN' 'AG' 'R' 'N' 'AV' 'AW' 'AS' 'AJ' 'AU' 'T' 'AH'
'AK' 'AF' 'D' 'L' 'AP' 'AI' 'K' 'A' 'AM' 'AT' 'AO' 'O' 'F' 'AD' 'C' 'S'
'AC' 'AA' 'X' 'Y' 'AE' 'AL' 'W' 'Q' 'I' 'B' 'M' 'AR' 'BA' 'AX' 'H' 'V'
'AB' 'P' 'AQ']
cat113 has 60 values. Unique values are :: ['AX' 'X' 'AE' 'AJ' 'I' 'BC' 'S' 'Y' 'L' 'A' 'AO' 'AN' 'N' 'BM' 'AK' 'Q'
'BK' 'J' 'M' 'AV' 'H' 'AD' 'AS' 'AW' 'BN' 'K' 'AG' 'BJ' 'F' 'BG' 'AF' 'AU'
'BO' 'AT' 'BH' 'BD' 'AI' 'AY' 'BF' 'AM' 'E' 'AH' 'C' 'BI' 'AB' 'BA' 'BB'
'O' 'B' 'AQ' 'V' 'BL' 'G' 'AP' 'U' 'AA' 'R' 'AR' 'AL' 'P']
cat114 has 18 values. Unique values are :: ['A' 'C' 'E' 'N' 'I' 'O' 'F' 'J' 'R' 'L' 'U' 'V' 'Q' 'B' 'W' 'G' 'D' 'S']
cat115 has 23 values. Unique values are :: ['Q' 'L' 'K' 'P' 'J' 'I' 'H' 'O' 'M' 'N' 'R' 'G' 'S' 'A' 'F' 'T' 'U' 'X'
'W' 'D' 'C' 'E' 'B']
cat116 has 311 values. Unique values are :: ['HG' 'HK' 'CK' 'DJ' 'HA' 'HY' 'MD' 'KC' 'GC' 'DT' 'HX' 'GE' 'HV' 'HJ' 'DA'
'HL' 'KB' 'JR' 'EP' 'DF' 'DP' 'LN' 'IE' 'GK' 'KW' 'CD' 'CR' 'CG' 'GS' 'LF'
'IF' 'HQ' 'FB' 'LL' 'LQ' 'JE' 'GL' 'LM' 'LB' 'LO' 'DC' 'HB' 'GT' 'CS' 'GX'
'BD' 'CI' 'IC' 'CW' 'EC' 'CH' 'KI' 'MG' 'JW' 'JU' 'HM' 'IT' 'IH' 'IG' 'LY'
'MC' 'EL' 'FH' 'MO' 'KD' 'GU' 'MJ' 'KA' 'FD' 'HH' 'DK' 'AC' 'GI' 'LW' 'BY'
'HN' 'CU' 'BU' 'BO' 'GM' 'KU' 'FR' 'EO' 'CN' 'EI' 'HC' 'LI' 'DS' 'EA' 'ME'
'E' 'GA' 'CB' 'LV' 'CP' 'GN' 'KL' 'CX' 'DH' 'CA' 'BV' 'BX' 'JL' 'KJ' 'EF'
'DD' 'AQ' 'FC' 'GP' 'LX' 'FT' 'HP' 'CM' 'BP' 'CO' 'GJ' 'KR' 'JX' 'KN' 'KP'
'K' 'IU' 'EK' 'LC' 'DO' 'LJ' 'R' 'LT' 'FU' 'KX' 'LD' 'HW' 'DI' 'GW' 'EE'
'GB' 'L' 'KQ' 'BQ' 'EY' 'FE' 'MP' 'MK' 'KS' 'DN' 'LA' 'EN' 'DM' 'AF' 'HD'
'FX' 'FG' 'CQ' 'IM' 'AW' 'EH' 'LK' 'IN' 'DG' 'JC' 'B' 'MU' 'FF' 'KT' 'CT'
'GR' 'IL' 'IQ' 'MI' 'GY' 'MQ' 'AO' 'FA' 'ED' 'I' 'DW' 'AX' 'DU' 'ES' 'EJ'
'HI' 'EB' 'GO' 'LG' 'LE' 'MN' 'BK' 'CL' 'ML' 'IY' 'JM' 'H' 'MA' 'EM' 'AK'
'KE' 'CF' 'HF' 'AJ' 'II' 'Y' 'DX' 'ID' 'GV' 'EW' 'KK' 'HR' 'CV' 'DR' 'IP'
'LH' 'MM' 'BS' 'FW' 'AR' 'GG' 'EG' 'MW' 'KM' 'DL' 'MS' 'JY' 'FP' 'JF' 'BW'
'KY' 'FY' 'GD' 'S' 'CE' 'GH' 'AN' 'KV' 'DE' 'GF' 'AI' 'HT' 'IA' 'BA' 'LR'
'N' 'JP' 'EU' 'JQ' 'BC' 'U' 'MR' 'JG' 'T' 'J' 'BG' 'BM' 'KF' 'IR' 'ET' 'Q'
'MV' 'KO' 'HE' 'JA' 'FK' 'KG' 'FV' 'O' 'BJ' 'JH' 'JV' 'JB' 'IW' 'AD' 'BT'
'F' 'AU' 'IJ' 'AE' 'IV' 'AA' 'DB' 'G' 'JK' 'JJ' 'LP' 'CJ' 'MX' 'BR' 'AV'
'BH' 'JS' 'FQ' 'M' 'FM' 'KH' 'ER' 'AG' 'A' 'AL' 'FL' 'BN' 'BE' 'IS' 'DV'
'FJ' 'CY' 'MH' 'LU' 'BB' 'LS' 'D' 'HS' 'FI' 'EX']
Train set has 8 values. Unique values are :: ['A' 'B' 'C' 'E' 'D' 'H' 'I' 'G']
test set has 8 values. Unique values are :: ['A' 'B' 'D' 'C' 'F' 'H' 'E' 'G']
Missing vaues are : set(['I'])
Train set has 7 values. Unique values are :: ['A' 'B' 'C' 'D' 'F' 'E' 'G']
test set has 6 values. Unique values are :: ['A' 'B' 'C' 'D' 'F' 'E']
Missing vaues are : set(['G'])
Train set has 7 values. Unique values are :: ['A' 'H' 'B' 'C' 'D' 'I' 'F']
test set has 8 values. Unique values are :: ['A' 'H' 'B' 'C' 'G' 'I' 'D' 'E']
Missing vaues are : set(['F'])
Train set has 19 values. Unique values are :: ['G' 'F' 'O' 'D' 'J' 'A' 'C' 'Q' 'M' 'I' 'L' 'R' 'S' 'E' 'N' 'H' 'B' 'U'
'K']
test set has 17 values. Unique values are :: ['G' 'D' 'Q' 'A' 'F' 'M' 'L' 'O' 'C' 'I' 'J' 'S' 'R' 'E' 'B' 'H' 'K']
Missing vaues are : set(['U', 'N'])
Train set has 9 values. Unique values are :: ['A' 'C' 'B' 'D' 'G' 'E' 'F' 'H' 'J']
test set has 7 values. Unique values are :: ['A' 'C' 'B' 'E' 'D' 'G' 'F']
Missing vaues are : set(['H', 'J'])
Train set has 20 values. Unique values are :: ['E' 'F' 'H' 'G' 'I' 'D' 'J' 'K' 'M' 'C' 'A' 'L' 'N' 'P' 'T' 'Q' 'R' 'O'
'B' 'S']
test set has 18 values. Unique values are :: ['E' 'G' 'F' 'H' 'I' 'D' 'J' 'A' 'L' 'C' 'K' 'N' 'M' 'P' 'O' 'T' 'B' 'Q']
Missing vaues are : set(['S', 'R'])
Train set has 84 values. Unique values are :: ['BU' 'BI' 'AB' 'H' 'K' 'CD' 'BQ' 'M' 'G' 'BL' 'L' 'AL' 'N' 'CL' 'R' 'F'
'BJ' 'AR' 'AT' 'S' 'AS' 'BO' 'X' 'D' 'BM' 'I' 'BH' 'CI' 'CF' 'C' 'AM' 'U'
'BE' 'BR' 'CJ' 'AE' 'A' 'Q' 'AW' 'T' 'AJ' 'AH' 'BA' 'BV' 'CC' 'CA' 'BG'
'BB' 'O' 'BD' 'AV' 'AX' 'AQ' 'AA' 'AI' 'AU' 'BX' 'AP' 'CK' 'Y' 'CH' 'BS'
'AN' 'AO' 'BC' 'CE' 'E' 'BY' 'CB' 'BT' 'P' 'BK' 'AF' 'B' 'BF' 'CG' 'V'
'ZZ' 'AY' 'BP' 'BN' 'J' 'AG' 'AK']
test set has 74 values. Unique values are :: ['BI' 'AB' 'K' 'G' 'BU' 'M' 'I' 'O' 'BO' 'CD' 'T' 'BQ' 'R' 'X' 'AR' 'E'
'BL' 'CI' 'S' 'AL' 'BH' 'N' 'U' 'F' 'AS' 'AQ' 'AW' 'CC' 'AN' 'AJ' 'C' 'AT'
'D' 'H' 'CA' 'A' 'AX' 'L' 'BD' 'V' 'BX' 'AH' 'CL' 'AM' 'BA' 'BR' 'AO' 'AE'
'AY' 'BB' 'BJ' 'AP' 'BN' 'AI' 'Q' 'BS' 'CK' 'AU' 'CE' 'BC' 'BG' 'AD' 'Y'
'BK' 'AA' 'CG' 'AV' 'P' 'AF' 'CB' 'CF' 'BE' 'CH' 'ZZ']
Missing vaues are : set(['CJ', 'BF', 'B', 'AG', 'BM', 'AK', 'J', 'BT', 'BV', 'BP', 'BY'])
Train set has 131 values. Unique values are :: ['BC' 'CQ' 'DK' 'CS' 'C' 'EB' 'DW' 'AM' 'AI' 'EG' 'CL' 'BS' 'BT' 'CO' 'CM'
'EL' 'AY' 'W' 'EE' 'AC' 'DX' 'CI' 'DT' 'A' 'V' 'DM' 'EF' 'DL' 'DA' 'BP'
'DH' 'CF' 'N' 'T' 'CR' 'X' 'CH' 'EM' 'DC' 'AX' 'BG' 'CJ' 'EA' 'AD' 'U'
'AK' 'BX' 'AW' 'G' 'BA' 'L' 'AP' 'CG' 'R' 'DU' 'I' 'AR' 'O' 'DF' 'AT' 'E'
'AB' 'AU' 'DI' 'CN' 'CP' 'AL' 'ED' 'DJ' 'AO' 'CY' 'BE' 'BJ' 'D' 'AA' 'CK'
'CV' 'BK' 'BB' 'AE' 'BO' 'P' 'DO' 'CT' 'AJ' 'BR' 'Y' 'DR' 'BQ' 'BL' 'B'
'BW' 'H' 'DP' 'DG' 'AG' 'BN' 'J' 'CW' 'DV' 'Q' 'DY' 'EI' 'AV' 'DQ' 'BU'
'K' 'BF' 'BD' 'DS' 'DE' 'BM' 'BY' 'CD' 'BI' 'DD' 'DB' 'AH' 'CC' 'DN' 'CU'
'BV' 'CX' 'AN' 'EK' 'EJ' 'AS' 'AF' 'CB' 'EH' 'S']
test set has 123 values. Unique values are :: ['BC' 'CO' 'CS' 'CR' 'EG' 'CL' 'EL' 'BT' 'EB' 'CQ' 'BS' 'C' 'W' 'DX' 'CM'
'A' 'EF' 'CI' 'DL' 'AI' 'BP' 'N' 'DJ' 'CT' 'E' 'DW' 'CH' 'V' 'AM' 'DK'
'EA' 'BR' 'DR' 'D' 'EE' 'T' 'AP' 'I' 'AC' 'CY' 'DM' 'AL' 'CK' 'AD' 'AY'
'CF' 'CD' 'BG' 'AK' 'DA' 'DC' 'DQ' 'BA' 'U' 'CX' 'BJ' 'AV' 'AR' 'K' 'CG'
'DT' 'CN' 'O' 'BO' 'DU' 'CJ' 'AX' 'DH' 'BX' 'AH' 'AU' 'AB' 'BV' 'EM' 'L'
'BH' 'DI' 'DB' 'DE' 'CV' 'DO' 'BQ' 'AW' 'AJ' 'J' 'CU' 'P' 'CP' 'DS' 'BL'
'AO' 'AA' 'DF' 'DG' 'CC' 'X' 'BF' 'AE' 'BU' 'AT' 'BB' 'B' 'ED' 'Y' 'G'
'BE' 'DD' 'DY' 'DP' 'R' 'CW' 'DN' 'AG' 'BW' 'BY' 'EK' 'CA' 'AS' 'EJ' 'BM'
'Q' 'S' 'EN']
Missing vaues are : set(['BD', 'EI', 'EH', 'AF', 'H', 'BN', 'BI', 'BK', 'CB', 'DV', 'AN'])
Train set has 16 values. Unique values are :: ['C' 'A' 'G' 'E' 'I' 'M' 'W' 'S' 'K' 'O' 'Q' 'U' 'F' 'B' 'Y' 'D']
test set has 16 values. Unique values are :: ['A' 'E' 'C' 'G' 'K' 'I' 'Q' 'U' 'M' 'O' 'S' 'F' 'L' 'W' 'Y' 'B']
Missing vaues are : set(['D'])
Train set has 61 values. Unique values are :: ['S' 'BM' 'AF' 'AE' 'Y' 'AX' 'H' 'K' 'L' 'A' 'J' 'AK' 'N' 'M' 'AJ' 'AT' 'F'
'BC' 'AY' 'AD' 'BG' 'BO' 'AS' 'BD' 'AN' 'I' 'BF' 'BK' 'AW' 'AG' 'BJ' 'AO'
'Q' 'AM' 'X' 'AU' 'BN' 'BH' 'AI' 'C' 'AV' 'AQ' 'AH' 'G' 'E' 'BA' 'AL' 'BI'
'U' 'AB' 'V' 'O' 'BB' 'AP' 'B' 'BL' 'BE' 'T' 'P' 'AC' 'AR']
test set has 60 values. Unique values are :: ['AX' 'X' 'AE' 'AJ' 'I' 'BC' 'S' 'Y' 'L' 'A' 'AO' 'AN' 'N' 'BM' 'AK' 'Q'
'BK' 'J' 'M' 'AV' 'H' 'AD' 'AS' 'AW' 'BN' 'K' 'AG' 'BJ' 'F' 'BG' 'AF' 'AU'
'BO' 'AT' 'BH' 'BD' 'AI' 'AY' 'BF' 'AM' 'E' 'AH' 'C' 'BI' 'AB' 'BA' 'BB'
'O' 'B' 'AQ' 'V' 'BL' 'G' 'AP' 'U' 'AA' 'R' 'AR' 'AL' 'P']
Missing vaues are : set(['BE', 'AC', 'T'])
Train set has 19 values. Unique values are :: ['A' 'J' 'E' 'C' 'F' 'L' 'N' 'I' 'R' 'U' 'O' 'B' 'Q' 'V' 'D' 'X' 'W' 'S'
'G']
test set has 18 values. Unique values are :: ['A' 'C' 'E' 'N' 'I' 'O' 'F' 'J' 'R' 'L' 'U' 'V' 'Q' 'B' 'W' 'G' 'D' 'S']
Missing vaues are : set(['X'])
Train set has 326 values. Unique values are :: ['LB' 'DP' 'GK' 'DJ' 'CK' 'LO' 'IE' 'LY' 'GS' 'HK' 'DC' 'MP' 'DS' 'LE' 'HQ'
'HJ' 'GC' 'BY' 'HX' 'HL' 'HG' 'MD' 'LF' 'LM' 'CB' 'CS' 'KQ' 'HN' 'LQ' 'KW'
'IT' 'LN' 'CW' 'LC' 'GX' 'GE' 'CP' 'HB' 'GI' 'GM' 'CR' 'JR' 'HA' 'EE' 'BA'
'LJ' 'IH' 'HV' 'GU' 'HM' 'CY' 'IC' 'KD' 'KI' 'DN' 'MG' 'LL' 'KN' 'LH' 'DF'
'EY' 'LW' 'KA' 'EK' 'DK' 'EO' 'CG' 'K' 'HC' 'DI' 'FB' 'IG' 'FR' 'CI' 'EC'
'KR' 'HI' 'IU' 'MC' 'BP' 'JW' 'FH' 'IF' 'E' 'DA' 'KL' 'LX' 'IL' 'KB' 'IQ'
'EL' 'JX' 'H' 'GN' 'CD' 'DH' 'AC' 'FD' 'ME' 'KC' 'FT' 'CT' 'DM' 'GL' 'ES'
'JL' 'BX' 'II' 'HP' 'ED' 'CU' 'EN' 'FG' 'MJ' 'KE' 'CF' 'EB' 'DD' 'EI' 'FX'
'EA' 'BO' 'KP' 'EP' 'FC' 'GB' 'JU' 'LV' 'CO' 'EF' 'BD' 'HW' 'LI' 'GT' 'HH'
'KJ' 'CN' 'B' 'FE' 'GA' 'FW' 'IY' 'MO' 'JG' 'ID' 'DX' 'FA' 'LA' 'HR' 'GJ'
'GO' 'KT' 'GW' 'U' 'MI' 'GP' 'F' 'DU' 'KM' 'BV' 'DT' 'IM' 'LD' 'GR' 'HD'
'BS' 'AJ' 'KX' 'LR' 'ML' 'KU' 'CE' 'IA' 'DE' 'R' 'AO' 'MU' 'AK' 'CX' 'HY'
'EH' 'MA' 'GH' 'LK' 'DL' 'AX' 'IN' 'BI' 'JM' 'JF' 'KK' 'DR' 'LT' 'GF' 'AW'
'KY' 'CA' 'MK' 'DV' 'EG' 'DW' 'MN' 'V' 'CM' 'GY' 'AF' 'JC' 'MR' 'JE' 'IP'
'KV' 'KH' 'BW' 'MQ' 'D' 'HF' 'CV' 'BL' 'FL' 'GV' 'CQ' 'BM' 'JB' 'J' 'FU'
'AG' 'EJ' 'CH' 'MW' 'X' 'DG' 'AV' 'EW' 'O' 'DO' 'BK' 'FS' 'T' 'CL' 'Y'
'JQ' 'I' 'AL' 'JJ' 'HT' 'FF' 'JA' 'GD' 'FV' 'BQ' 'M' 'S' 'EU' 'P' 'FJ'
'AR' 'LG' 'IR' 'GQ' 'MM' 'AY' 'MF' 'GG' 'KG' 'JD' 'L' 'KS' 'AH' 'JV' 'EV'
'CC' 'AB' 'FK' 'JY' 'G' 'W' 'BC' 'AM' 'KF' 'LU' 'IK' 'BU' 'AT' 'JP' 'Q'
'IJ' 'JO' 'JH' 'AS' 'JN' 'BF' 'AD' 'FP' 'MV' 'AA' 'CJ' 'DY' 'IB' 'AN' 'EQ'
'JT' 'BG' 'AP' 'MB' 'JK' 'FI' 'MS' 'HE' 'C' 'IV' 'IO' 'BT' 'DQ' 'FM' 'HO'
'MH' 'MT' 'FO' 'JI' 'FQ' 'AU' 'FN' 'BB' 'HU' 'IX' 'AE']
test set has 311 values. Unique values are :: ['HG' 'HK' 'CK' 'DJ' 'HA' 'HY' 'MD' 'KC' 'GC' 'DT' 'HX' 'GE' 'HV' 'HJ' 'DA'
'HL' 'KB' 'JR' 'EP' 'DF' 'DP' 'LN' 'IE' 'GK' 'KW' 'CD' 'CR' 'CG' 'GS' 'LF'
'IF' 'HQ' 'FB' 'LL' 'LQ' 'JE' 'GL' 'LM' 'LB' 'LO' 'DC' 'HB' 'GT' 'CS' 'GX'
'BD' 'CI' 'IC' 'CW' 'EC' 'CH' 'KI' 'MG' 'JW' 'JU' 'HM' 'IT' 'IH' 'IG' 'LY'
'MC' 'EL' 'FH' 'MO' 'KD' 'GU' 'MJ' 'KA' 'FD' 'HH' 'DK' 'AC' 'GI' 'LW' 'BY'
'HN' 'CU' 'BU' 'BO' 'GM' 'KU' 'FR' 'EO' 'CN' 'EI' 'HC' 'LI' 'DS' 'EA' 'ME'
'E' 'GA' 'CB' 'LV' 'CP' 'GN' 'KL' 'CX' 'DH' 'CA' 'BV' 'BX' 'JL' 'KJ' 'EF'
'DD' 'AQ' 'FC' 'GP' 'LX' 'FT' 'HP' 'CM' 'BP' 'CO' 'GJ' 'KR' 'JX' 'KN' 'KP'
'K' 'IU' 'EK' 'LC' 'DO' 'LJ' 'R' 'LT' 'FU' 'KX' 'LD' 'HW' 'DI' 'GW' 'EE'
'GB' 'L' 'KQ' 'BQ' 'EY' 'FE' 'MP' 'MK' 'KS' 'DN' 'LA' 'EN' 'DM' 'AF' 'HD'
'FX' 'FG' 'CQ' 'IM' 'AW' 'EH' 'LK' 'IN' 'DG' 'JC' 'B' 'MU' 'FF' 'KT' 'CT'
'GR' 'IL' 'IQ' 'MI' 'GY' 'MQ' 'AO' 'FA' 'ED' 'I' 'DW' 'AX' 'DU' 'ES' 'EJ'
'HI' 'EB' 'GO' 'LG' 'LE' 'MN' 'BK' 'CL' 'ML' 'IY' 'JM' 'H' 'MA' 'EM' 'AK'
'KE' 'CF' 'HF' 'AJ' 'II' 'Y' 'DX' 'ID' 'GV' 'EW' 'KK' 'HR' 'CV' 'DR' 'IP'
'LH' 'MM' 'BS' 'FW' 'AR' 'GG' 'EG' 'MW' 'KM' 'DL' 'MS' 'JY' 'FP' 'JF' 'BW'
'KY' 'FY' 'GD' 'S' 'CE' 'GH' 'AN' 'KV' 'DE' 'GF' 'AI' 'HT' 'IA' 'BA' 'LR'
'N' 'JP' 'EU' 'JQ' 'BC' 'U' 'MR' 'JG' 'T' 'J' 'BG' 'BM' 'KF' 'IR' 'ET' 'Q'
'MV' 'KO' 'HE' 'JA' 'FK' 'KG' 'FV' 'O' 'BJ' 'JH' 'JV' 'JB' 'IW' 'AD' 'BT'
'F' 'AU' 'IJ' 'AE' 'IV' 'AA' 'DB' 'G' 'JK' 'JJ' 'LP' 'CJ' 'MX' 'BR' 'AV'
'BH' 'JS' 'FQ' 'M' 'FM' 'KH' 'ER' 'AG' 'A' 'AL' 'FL' 'BN' 'BE' 'IS' 'DV'
'FJ' 'CY' 'MH' 'LU' 'BB' 'LS' 'D' 'HS' 'FI' 'EX']
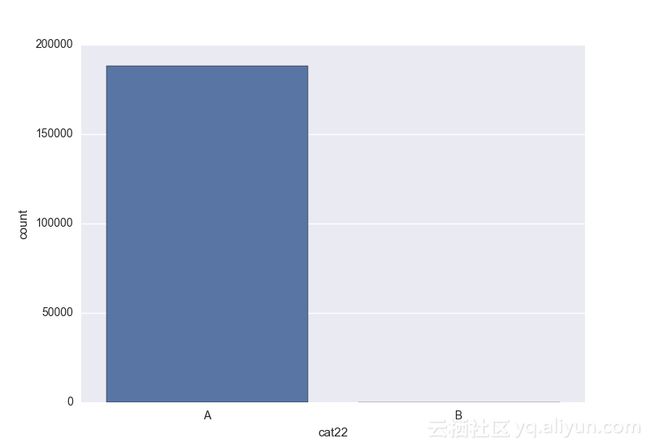
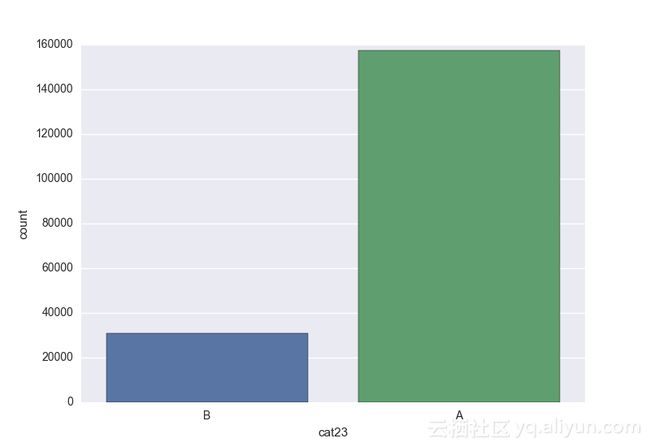
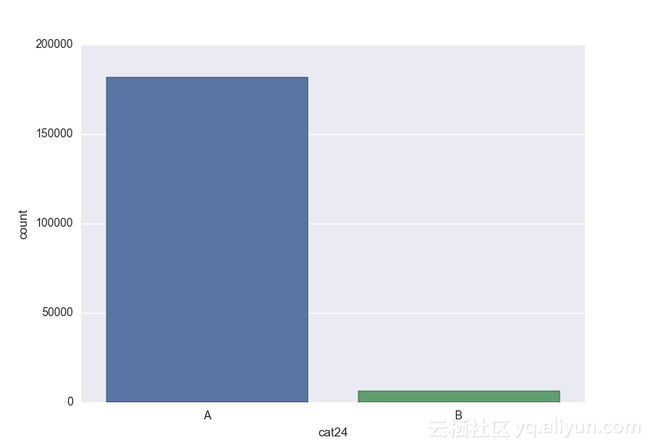
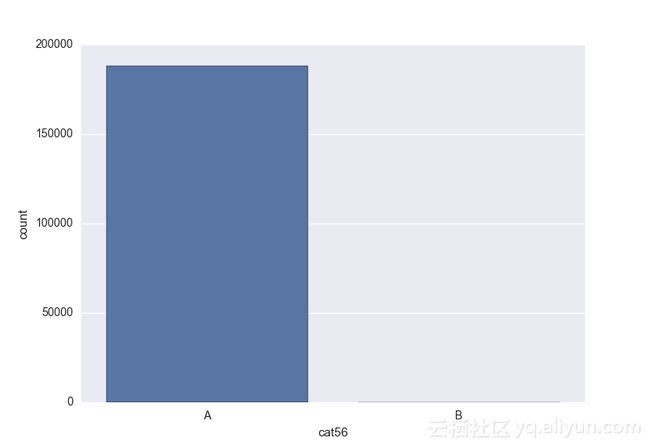
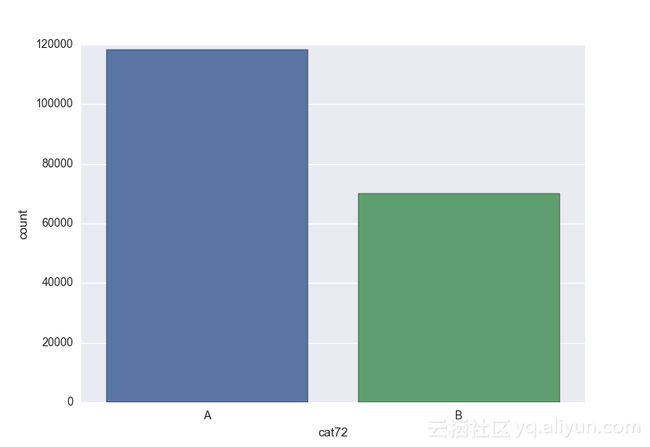
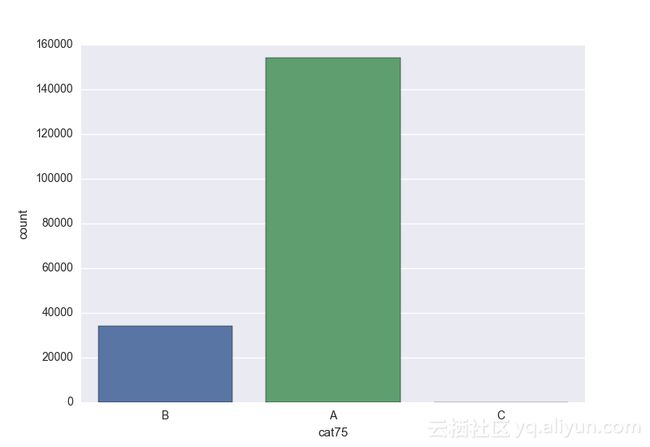
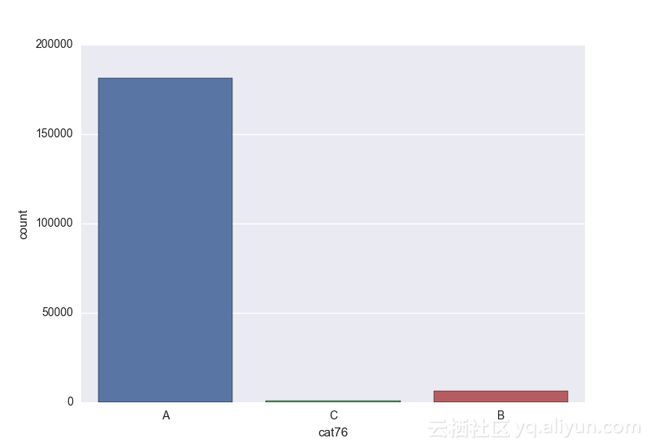
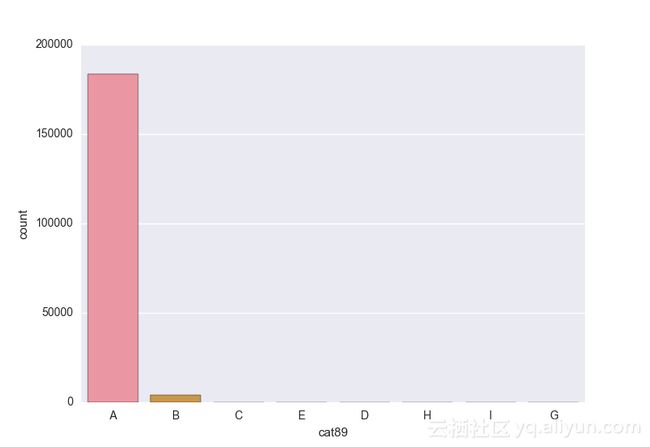
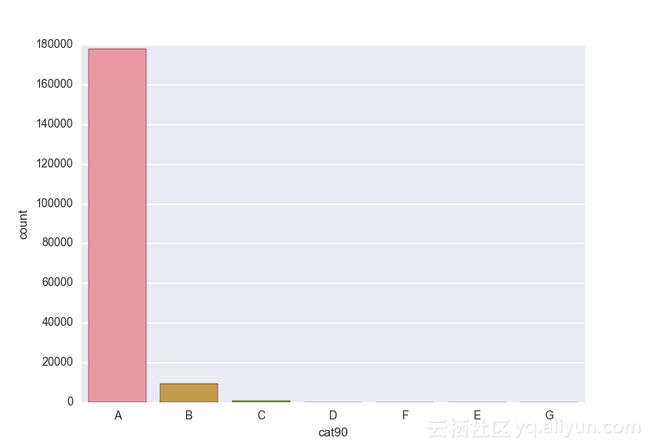
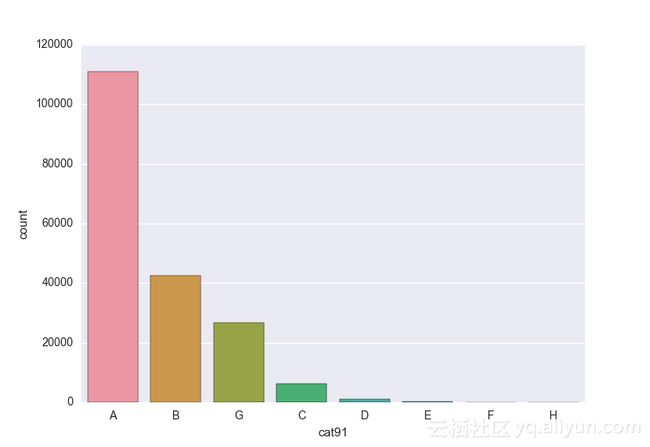
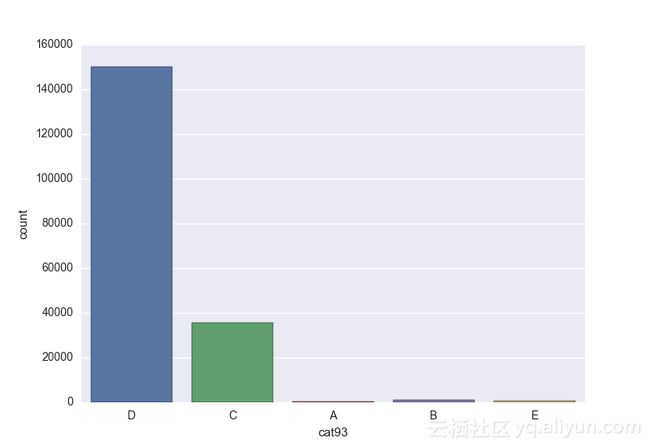
Missing vaues are : set(['BF', 'FS', 'W', 'BL', 'BI', 'HU', 'JN', 'JO', 'JI', 'DY', 'JD', 'FN', 'FO', 'IB', 'JT', 'DQ', 'IX', 'C', 'AB', 'GQ', 'CC', 'AH', 'AM', 'AP', 'AS', 'AT', 'IO', 'V', 'AY', 'X', 'EV', 'EQ', 'MF', 'MB', 'IK', 'MT', 'P', 'HO'])画出类别变量并查看变量分布
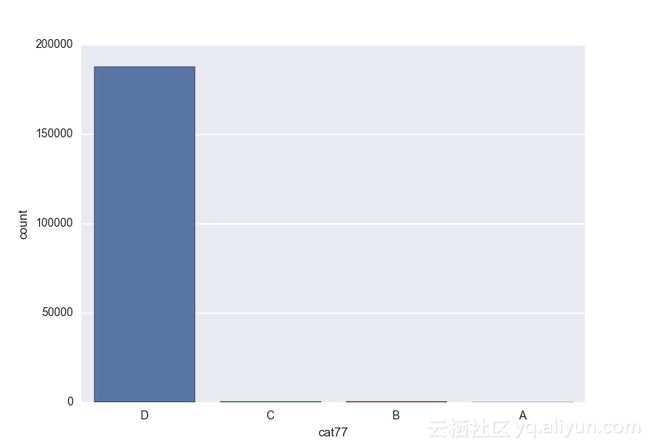
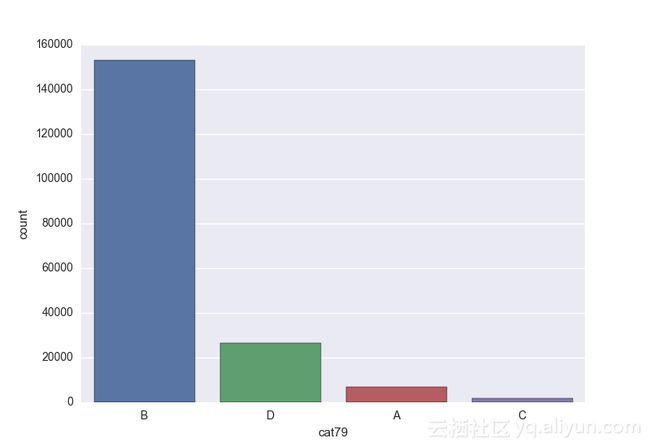
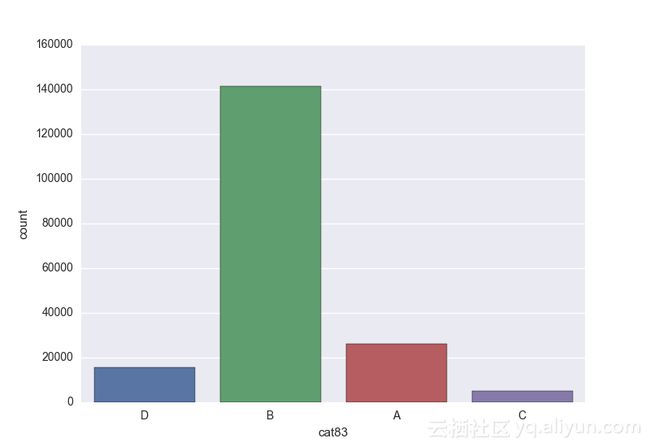
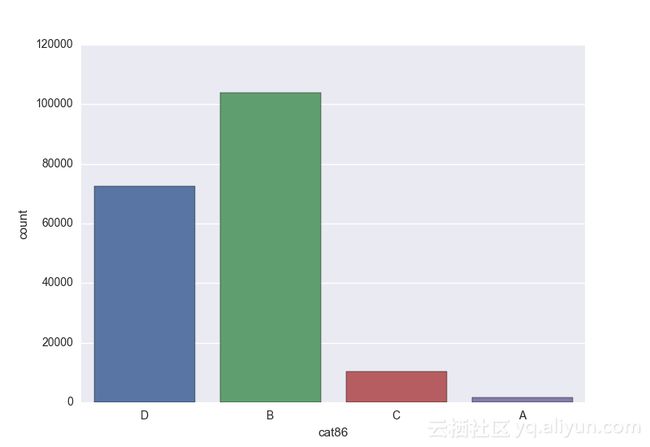
# lets visualize the values in each of the features
# keep in mind you'll be seeing a lot of plots now
# better is use ipython/jupyter notebook to plot inline plots
for feature in categorical_train:
sns.countplot(x = train[feature], data = train)
plt.show()
for feature in categorical_test:
sns.countplot(x = test[feature], data = test)
plt.show()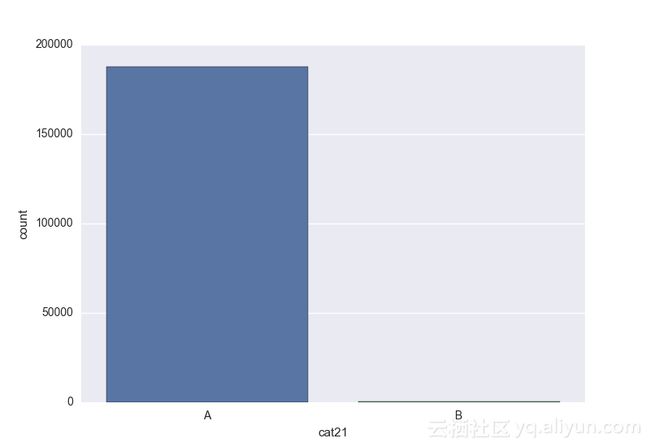
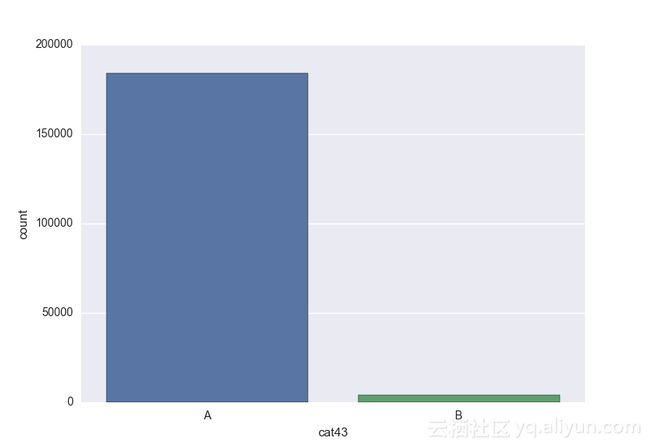
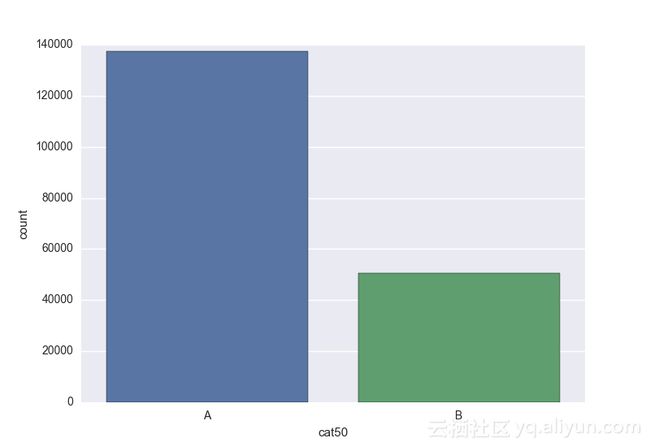
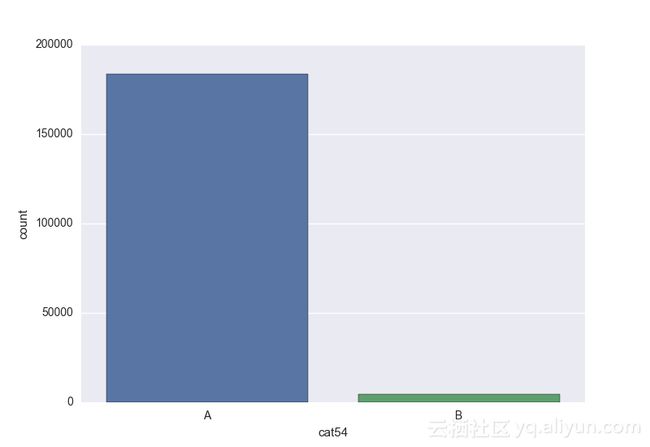
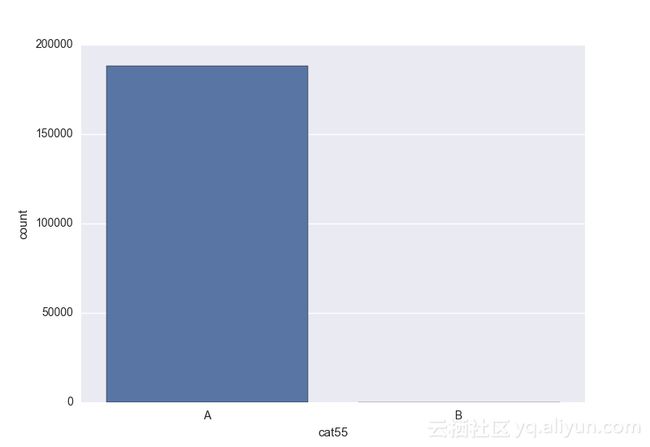
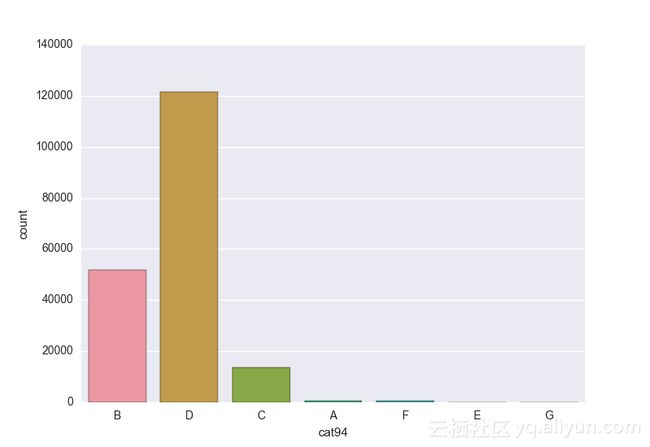
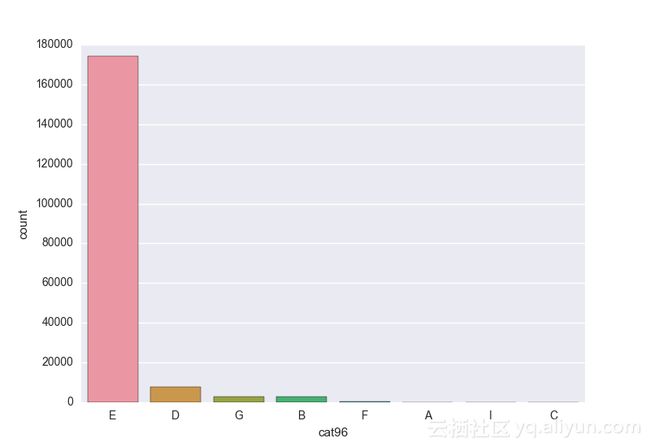
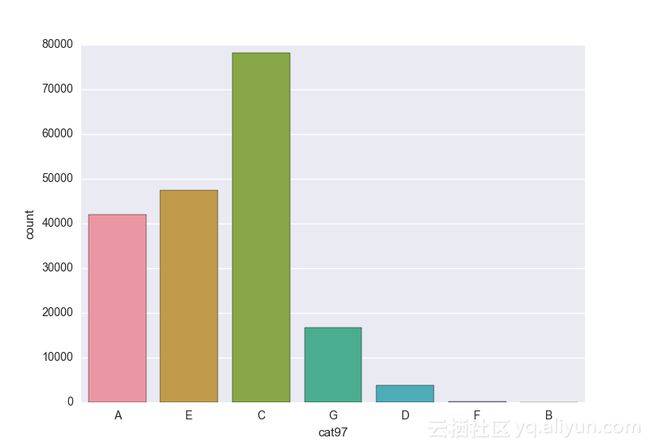
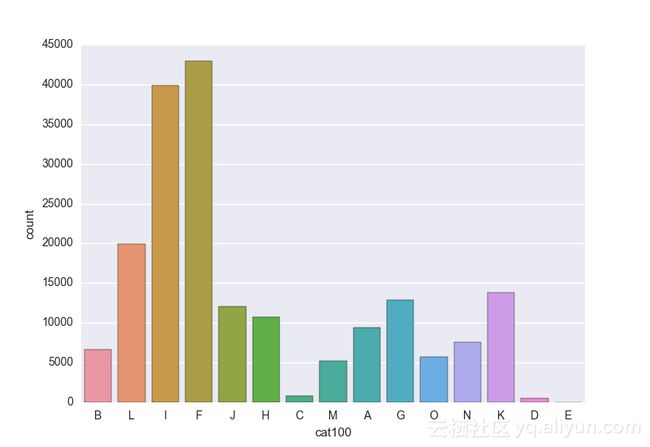
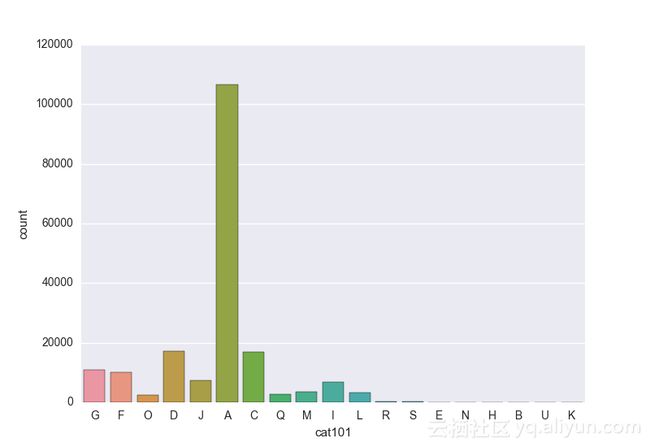
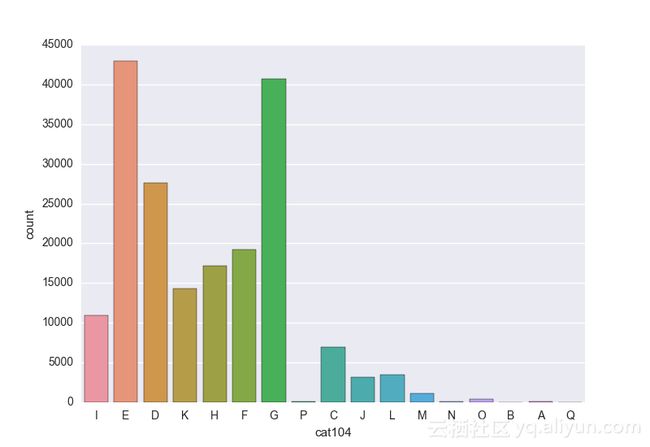
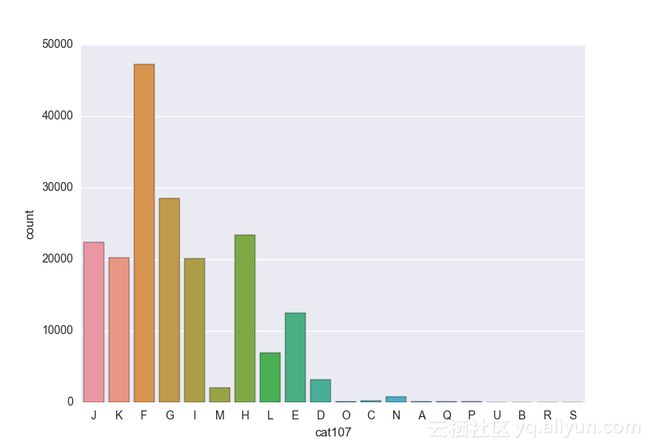

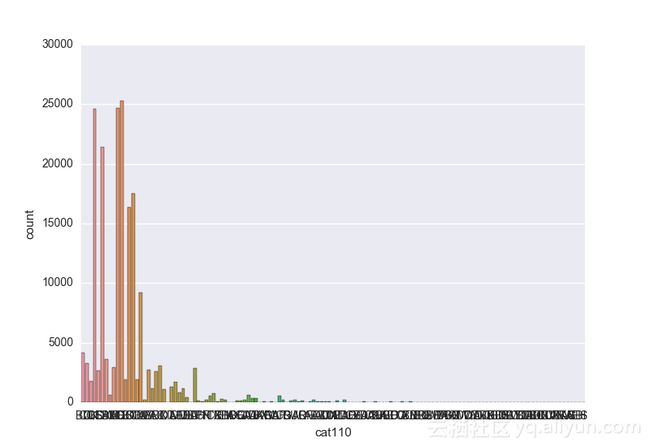
类别变量的一个热点—编码
使用一个热门aka方案编码分类整型特征,这个变换的输入应该是整型矩阵,
表示通过分类特征获取的值;输出将是稀疏矩阵,其中每一列对应于一个特征的可能值。
1. 第一种方法是使用 dictvectorizer对特征中的标签进行编码
# cat1 to cat72 have only two labels A and B
# cat73 to cat 108 have more than two labels
# cat109 to cat116 have many labels
# moreover you must have noticed that some labels are missing in some features of train/test dataset
# this might become a problem when working with multiple datasets
# to avoid this, we will merge data before doing onehotencoding
train_test = pd.concat(train, test).reset_index(drop=True)
categorical = train_test.dtypes[train_test.dtypes == "object"].index
# lets check for factors in the categorical variables
for feature in categorical:
print feature, 'has ', len(train_test[feature].unique()), 'values. Unique values are :: ', train_test[feature].unique()
# 1. one hot encoding all categorical variables
v = DictVectorizer()
train_test_qual = v.fit_transform(train_test[categorical].to_dict('records'))
print 'total vocabulary :: ', train_test_qual.vocabulary_
print 'total number of columns', len(train_test_qual.vocabulary_.keys())
print 'total number of new columns added ', len(train_test_qual.vocabulary_.keys()) - len(categorical)
# it can be seen that we are adding too many new variables. This encoding is important
# since machine learning algorithms dont understand strings and we have to convert string factors
# as numeric factors which increase our dimensionality
new_df = pd.DataFrame(X_qual.toarray(), columns= [i[0] for i in sorted(v.vocabulary_.items(), key=operator.itemgetter(1))])
new_df = pd.concat([new_df, train_test], axis=1)
# remove initial categorical variables
new_df.drop(categorical, axis=1, inplace=True)
# take back the train and test set from the above data
train_featured = new_df.iloc[:train.shape[0], :]
test_featured = new_df.iloc[train.shape[0]:, :]
train_featured[continous_train] = train[continous_train]
test_featured[continous_train] = test[continous_train]
train_featured['loss'] = loss2. 第二种方法是使用pandas获得虚拟变量
# 2. using get dummies from pandas
new_df2 = train_test
dummies = pd.get_dummies(train_test[categorical], drop_first = True)
new_df2 = pd.concat([new_df2, dummies], axis=1)
new_df2.drop(categorical, inplace=True, axis=1)
# take back the train and test set from the above data
train_featured2 = new_df2.iloc[:train.shape[0], :]
test_featured2 = new_df2.iloc[train.shape[0]:, :]
train_featured2[continous_train] = train[continous_train]
test_featured2[continous_train] = test[continous_train]
train_featured2['loss'] = loss
3. 其中一些变量只有两个标签或者某些变量有两个以上的标签,一种方法是使用因式分解将这些标签转化为数字
# 3. pd.factorize
new_df3 = train_test
for feature in new_df3.columns:
new_df3[feature] = pd.factorize(new_df3[feature], sort=True)[0]
# take back the train and test set from the above data
train_featured3 = new_df3.iloc[:train.shape[0], :]
test_featured3 = new_df3.iloc[train.shape[0]:, :]
train_featured3[continous_train] = train[continous_train]
test_featured3[continous_train] = test[continous_train]
train_featured3['loss'] = loss
4. 另外一种方法是将虚拟变量和因式分解混合起来使用
# 4. mixed model
# what we can do is mix these models since cat1 to cat72 just have 2 labels, so we can factorize
# these variables
# for the rest we can make dummies
new_df4 = train_test
for feature in new_df4.columns[:72]:
new_df4[feature] = pd.factorize(new_df4[feature], sort=True)[0]
dummies = pd.get_dummies(train_test[categorical[73:]], drop_first = True)
new_df4 = pd.concat([new_df4, dummies], axis=1)
new_df4.drop(categorical[73:], inplace=True, axis=1)
# take back the train and test set from the above data
train_featured4 = new_df4.iloc[:train.shape[0], :]
test_featured4 = new_df4.iloc[train.shape[0]:, :]
train_featured4[continous_train] = train[continous_train]
test_featured4[continous_train] = test[continous_train]
train_featured4['loss'] = loss以下是整个代码
# import required libraries
# pandas for reading data and manipulation
# scikit learn to one hot encoder and label encoder
# sns and matplotlib to visualize
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.feature_extraction import DictVectorizer
import operator
# read data from csv file
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
# let's take a look at the train and test data
print '**************************************'
print 'TRAIN DATA'
print '**************************************'
print train.head(5)
print '**************************************'
print 'TEST DATA'
print '**************************************'
print test.head(5)
# the above code wont print all columns.
# to print all columns
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
# let's take a look at the train and test data again
print '**************************************'
print 'TRAIN DATA'
print '**************************************'
print train.head(5)
print '**************************************'
print 'TEST DATA'
print '**************************************'
print test.head(5)
# remove ID column. No use.
train.drop('id',axis=1,inplace=True)
test.drop('id',axis=1,inplace=True)
loss = train.drop('loss', axis = 1, inplace = True)
# high level statistics. mean media mode count and quartiles
# note - this will work only for the continous variables
# not for the categorical variables
print train.describe()
print test.describe()
# at this point, it is wise to check whether there are any features that
# are there is one of the dataset but not in other
missingFeatures = False
inTrainNotTest = []
for feature in train.columns:
if feature not in test.columns:
missingFeatures = True
inTrainNotTest.append(feature)
if len(inTrainNotTest)>0:
print ', '. join(inTrainNotTest), ' features are present in training set but not in test set'
inTestNotTrain = []
for feature in test.columns:
if feature not in train.columns:
missingFeatures = True
inTestNotTrain.append(feature)
if len(inTestNotTrain)>0:
print ', '. join(inTestNotTrain), ' features are present in test set but not in training set'
# find categorical variables
# in this problem, categorical variables are start with cat which is easy
# to identify
# in other problems it not might be like that
# we will see two ways to identify this in this problem
# we will also find the continous or numerical variables
## 1. by name
categorical_train = [var for var in train.columns if 'cat' in var]
categorical_test = [var for var in test.columns if 'cat' in var]
continous_train = [var for var in train.columns if 'cont' in var]
continous_test = [var for var in test.columns if 'cont' in var]
## 2. by type = object
categorical_train = train.dtypes[train.dtypes == "object"].index
categorical_test = test.dtypes[test.dtypes == "object"].index
continous_train = train.dtypes[train.dtypes != "object"].index
continous_test = test.dtypes[test.dtypes != "object"].index
# lets check for correlation between continous data
# correlation between numerical variables is something like this
# if we increase one variable, there is a siginficant almost increase/decrease
# in the other variable. it varies from -1 to 1
correlation_train = train[continous_train].corr()
correlation_test = train[continous_test].corr()
# for the purpose of this analysis, we will consider to variables to
# highly correlation if the correlation is more than 0.6
threshold = 0.6
for i in range(len(correlation_train)):
for j in range(len(correlation_train)):
if (i>j) and (correlation_train.iloc[i,j]>threshold):
print ("%s and %s = %.2f" % (train.columns[i],train.columns[j],correlation_train.iloc[i,j]))
for i in range(len(correlation_test)):
for j in range(len(correlation_test)):
if (i>j) and (correlation_test.iloc[i,j]>threshold):
print ("%s and %s = %.2f" % (test.columns[i],test.columns[j],correlation_test.iloc[i,j]))
####cat6 and cat1 = 0.76
####cat7 and cat6 = 0.66
####cat9 and cat1 = 0.93
####cat9 and cat6 = 0.80
####cat10 and cat1 = 0.81
####cat10 and cat6 = 0.88
####cat10 and cat9 = 0.79
####cat11 and cat6 = 0.77
####cat11 and cat7 = 0.75
####cat11 and cat9 = 0.61
####cat11 and cat10 = 0.70
####cat12 and cat1 = 0.61
####cat12 and cat6 = 0.79
####cat12 and cat7 = 0.74
####cat12 and cat9 = 0.63
####cat12 and cat10 = 0.71
####cat12 and cat11 = 0.99
####cat13 and cat6 = 0.82
####cat13 and cat9 = 0.64
####cat13 and cat10 = 0.71
# we can remove one of the two highly correlatied variables to improve performance
# lets check for factors in the categorical variables
for feature in categorical_train:
print feature, 'has ', len(train[feature].unique()), 'values. Unique values are :: ', train[feature].unique()
for feature in categorical_test:
print feature, 'has ', len(test[feature].unique()), 'values. Unique values are :: ', test[feature].unique()
# lets take a look whether the unique values/factors are not present in each of the dataset
# for example cat1 in both the datasets has values only A & B. Sometimes
# it may happen that some new value is present in the test set which maybe ruin your model
featuresDone = []
for feature in categorical_train:
if feature in categorical_test:
if set(train[feature].unique()) - set(test[feature].unique()) != set([]):
print 'Train set has ', len(train[feature].unique()), 'values. Unique values are :: ', train[feature].unique(), '\n'
print 'test set has ', len(test[feature].unique()), 'values. Unique values are :: ', test[feature].unique(), '\n'
print 'Missing vaues are : ', set(train[feature].unique()) - set(test[feature].unique())
featuresDone.append(feature)
for feature in categorical_test:
if (feature in categorical_train) and (feature not in featuresDone):
if set(train[feature].unique()) - set(test[feature].unique()) != set([]):
print 'Train set has ', len(train[feature].unique()), 'values. Unique values are :: ', train[feature].unique(), '\n'
print 'test set has ', len(test[feature].unique()), 'values. Unique values are :: ', test[feature].unique(), '\n'
print 'Missing vaues are : ', set(train[feature].unique()) - set(test[feature].unique())
featuresDone.append(feature)
# lets visualize the values in each of the features
# keep in mind you'll be seeing a lot of plots now
# better is use ipython/jupyter notebook to plot inline plots
for feature in categorical_train:
sns.countplot(x = train[feature], data = train)
#plt.show()
for feature in categorical_test:
sns.countplot(x = test[feature], data = test)
#plt.show()
# cat1 to cat72 have only two labels A and B
# cat73 to cat 108 have more than two labels
# cat109 to cat116 have many labels
# moreover you must have noticed that some labels are missing in some features of train/test dataset
# this might become a problem when working with multiple datasets
# to avoid this, we will merge data before doing onehotencoding
train_test = pd.concat(train, test).reset_index(drop=True)
categorical = train_test.dtypes[train_test.dtypes == "object"].index
# lets check for factors in the categorical variables
for feature in categorical:
print feature, 'has ', len(train_test[feature].unique()), 'values. Unique values are :: ', train_test[feature].unique()
# 1. one hot encoding all categorical variables
v = DictVectorizer()
train_test_qual = v.fit_transform(train_test[categorical].to_dict('records'))
print 'total vocabulary :: ', train_test_qual.vocabulary_
print 'total number of columns', len(train_test_qual.vocabulary_.keys())
print 'total number of new columns added ', len(train_test_qual.vocabulary_.keys()) - len(categorical)
# it can be seen that we are adding too many new variables. This encoding is important
# since machine learning algorithms dont understand strings and we have to convert string factors
# as numeric factors which increase our dimensionality
new_df = pd.DataFrame(X_qual.toarray(), columns= [i[0] for i in sorted(v.vocabulary_.items(), key=operator.itemgetter(1))])
new_df = pd.concat([new_df, train_test], axis=1)
# remove initial categorical variables
new_df.drop(categorical, axis=1, inplace=True)
# take back the train and test set from the above data
train_featured = new_df.iloc[:train.shape[0], :]
test_featured = new_df.iloc[train.shape[0]:, :]
train_featured[continous_train] = train[continous_train]
test_featured[continous_train] = test[continous_train]
train_featured['loss'] = loss
# 2. using get dummies from pandas
new_df2 = train_test
dummies = pd.get_dummies(train_test[categorical], drop_first = True)
new_df2 = pd.concat([new_df2, dummies], axis=1)
new_df2.drop(categorical, inplace=True, axis=1)
# take back the train and test set from the above data
train_featured2 = new_df2.iloc[:train.shape[0], :]
test_featured2 = new_df2.iloc[train.shape[0]:, :]
train_featured2[continous_train] = train[continous_train]
test_featured2[continous_train] = test[continous_train]
train_featured2['loss'] = loss
# 3. pd.factorize
new_df3 = train_test
for feature in new_df3.columns:
new_df3[feature] = pd.factorize(new_df3[feature], sort=True)[0]
# take back the train and test set from the above data
train_featured3 = new_df3.iloc[:train.shape[0], :]
test_featured3 = new_df3.iloc[train.shape[0]:, :]
train_featured3[continous_train] = train[continous_train]
test_featured3[continous_train] = test[continous_train]
train_featured3['loss'] = loss
# 4. mixed model
# what we can do is mix these models since cat1 to cat72 just have 2 labels, so we can factorize
# these variables
# for the rest we can make dummies
new_df4 = train_test
for feature in new_df4.columns[:72]:
new_df4[feature] = pd.factorize(new_df4[feature], sort=True)[0]
dummies = pd.get_dummies(train_test[categorical[73:]], drop_first = True)
new_df4 = pd.concat([new_df4, dummies], axis=1)
new_df4.drop(categorical[73:], inplace=True, axis=1)
# take back the train and test set from the above data
train_featured4 = new_df4.iloc[:train.shape[0], :]
test_featured4 = new_df4.iloc[train.shape[0]:, :]
train_featured4[continous_train] = train[continous_train]
test_featured4[continous_train] = test[continous_train]
train_featured4['loss'] = loss
## this we can use for training and testing in the model
文章原标题《Machine Learning:Pre-processing features》,作者:Chris Rudzki
文章为简译,更为详细的内容,请查看原文
翻译者: uncle_ll