各位小伙儿伴儿,一定深受过采集微信公众号之苦吧!特别是!!!!!!公共号历史信息!!!这丫除了通过中间代理采集APP、还真没什么招数能拿到数据啊!

直到············
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:101677771
大致意思是说以后发布文章的时候可以直接插入其它公众号的文章了。

诶妈呀!这不是一直需要的采集接口嘛!啧啧 天助我也啊!来来·········下面大致的说一下方法。
1、首先你需要一个订阅号! 公众号、和企业号是否可行我不清楚。因为我木有·····
2、其次你需要登录!
微信公众号登录我没仔细看。
这个暂且不说了,我使用的是selenium 驱动浏览器获取Cookie的方法、来达到登录的效果。
3、使用requests携带Cookie、登录获取URL的token(这玩意儿很重要每一次请求都需要带上它)像下面这样:
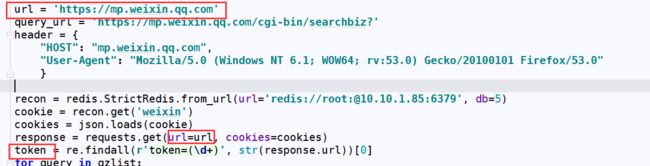
4、使用获取到的token、和公众号的微信号(就是数字+字符那种)、获取到公众号的fakeid(你可以理解公众号的标识)
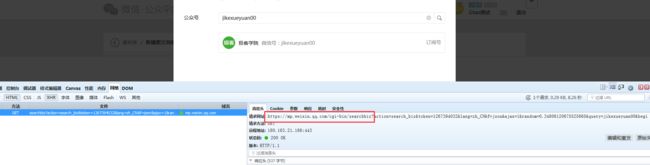
我们在搜索公众号的时候浏览器带着参数以GET方法想红框中的URL发起了请求。请求参数如下:
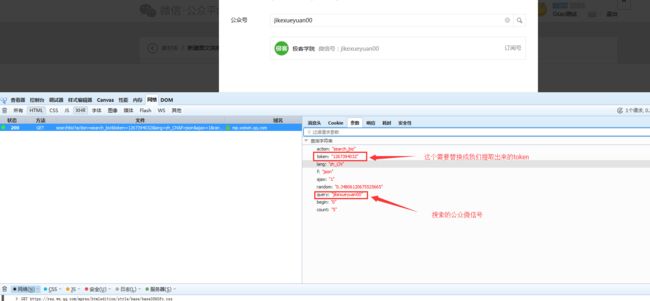
请求相应如下:
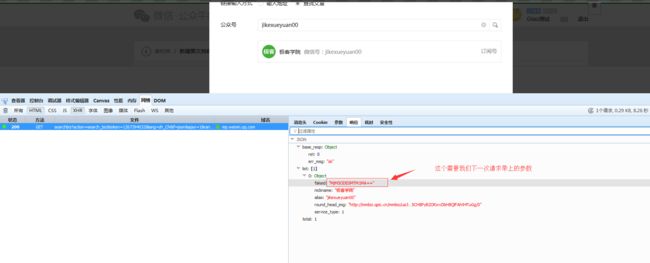
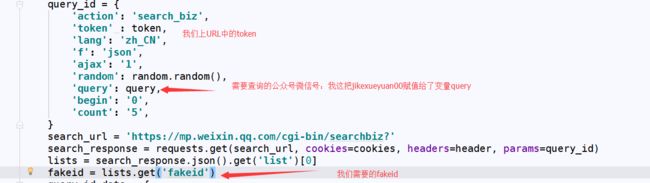
代码如下:
好了 我们再继续:
5、点击我们搜索到的公众号之后、又发现一个请求:
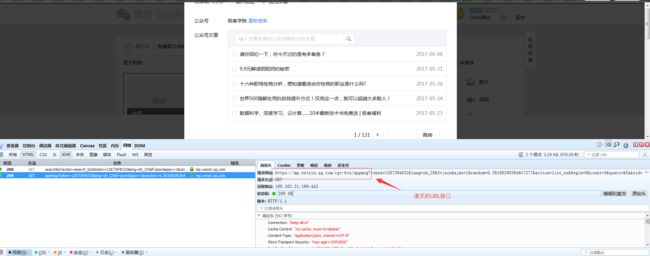
请求参数如下:
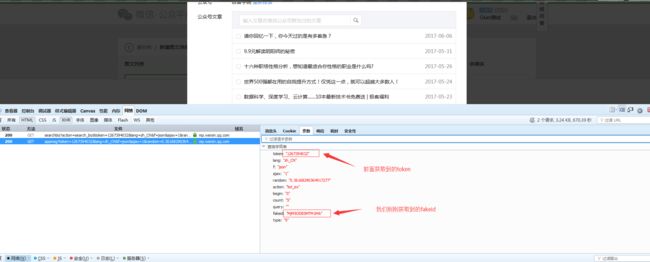
返回如下:
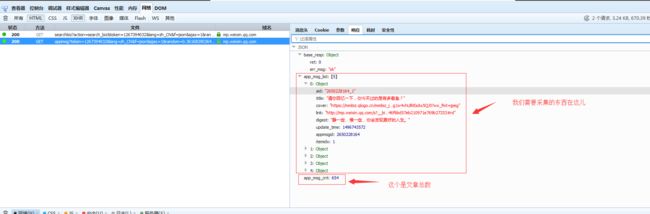
代码如下:
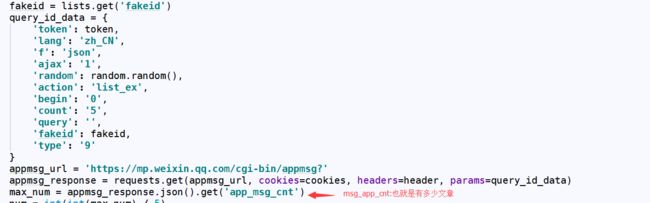
好了···最后一步、获取所有文章需要处理一下翻页、翻页请求如下:
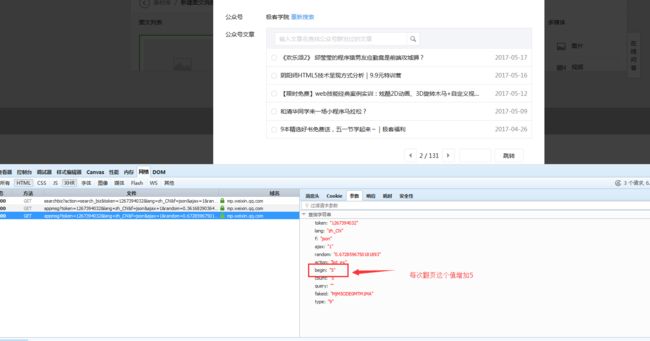
我大概看了一下、极客学院每一页大概至少有5条信息、也就是总文章数/5 就是有多少页。但是有小数、我们取整,然后加1就是总页数了。
代码如下:
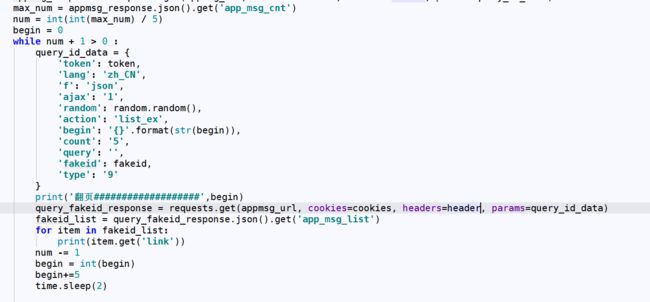
item.get(‘link’)就是我们需要的公众号文章连接啦!继续请求这个URL提取里面的内容就是啦!
以下是完整的测试代码:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
from selenium import webdriver
import time
import json
from pprint import pprint
post = {}
driver = webdriver.Chrome(executable_path='C:\chromedriver.exe')
driver.get('https://mp.weixin.qq.com/')
time.sleep(2)
driver.find_element_by_xpath("./*//input[@id='account']").clear()
driver.find_element_by_xpath("./*//input[@id='account']").send_keys('你的帐号')
driver.find_element_by_xpath("./*//input[@id='pwd']").clear()
driver.find_element_by_xpath("./*//input[@id='pwd']").send_keys('你的密码')
# 在自动输完密码之后记得点一下记住我
time.sleep(5)
driver.find_element_by_xpath("./*//a[@id='loginBt']").click()
# 拿手机扫二维码!
time.sleep(15)
driver.get('https://mp.weixin.qq.com/')
cookie_items = driver.get_cookies()
for cookie_item in cookie_items:
post[cookie_item['name']] = cookie_item['value']
cookie_str = json.dumps(post)
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
import requests
import redis
import json
import re
import random
import time
gzlist = ['yq_Butler']
url = 'https://mp.weixin.qq.com'
header = {
"HOST": "mp.weixin.qq.com",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0"
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
response = requests.get(url=url, cookies=cookies)
token = re.findall(r'token=(\d+)', str(response.url))[0]
for query in gzlist:
query_id = {
'action': 'search_biz',
'token' : token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'query': query,
'begin': '0',
'count': '5',
}
search_url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz?'
search_response = requests.get(search_url, cookies=cookies, headers=header, params=query_id)
lists = search_response.json().get('list')[0]
fakeid = lists.get('fakeid')
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '0',
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
appmsg_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
max_num = appmsg_response.json().get('app_msg_cnt')
num = int(int(max_num) / 5)
begin = 0
while num + 1 > 0 :
query_id_data = {
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1',
'random': random.random(),
'action': 'list_ex',
'begin': '{}'.format(str(begin)),
'count': '5',
'query': '',
'fakeid': fakeid,
'type': '9'
}
print('翻页###################',begin)
query_fakeid_response = requests.get(appmsg_url, cookies=cookies, headers=header, params=query_id_data)
fakeid_list = query_fakeid_response.json().get('app_msg_list')
for item in fakeid_list:
print(item.get('link'))
num -= 1
begin = int(begin)
begin+=5
time.sleep(2)
|