通俗易懂的--大文件上传,断点续传
文件上传呢,肯定少不了先获得/读取文件,咱们一步一步往下看~
通过File API读取文件
一种通过 File API 规范与本地文件交互的标准方式。
允许我们异步读取存储在用户计算机上的文件(或者原始数据缓冲区)的内容,可以监控读取进度、找出错误并确定加载何时完成。使用File或Blob对象指定要读取的文件或数据。
基于文件流(form-data)
最简单的例子就是通过表单获取上传的文件信息啦~
<input id="input" type="file">
<script>
const input = document.querySelector('input[type=file]')
input.addEventListener('change', ()=>{
console.log(input.files);//返回一个数组,里面是上传的文件
}
script>
console.log(input.files) 输出内容~
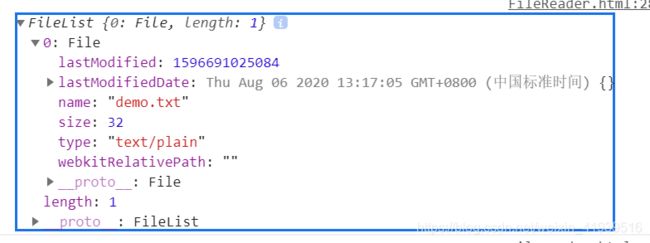
FileReader
戳此看更详细的解读
很显然,上面的文件信息并不能获取文件的内容。终于到了我们的FileReader出场啦,它的功能是读取(解析)文件!
我们获取了 File引用后,实例化 FileReader 对象,以便将其内容读取到内存中。加载结束后,将触发读取程序的 onload事件,而其 result属性可用于访问文件数据。
FileReader包括四个异步读取文件的选项:
FileReader.readAsBinaryString(Blob|File) - result属性将包含二进制字符串形式的 file/blob 数据。每个字节均由一个 [0…255] 范围内的整数表示。
FileReader.readAsText(Blob|File, opt_encoding) - result属性将包含文本字符串形式的 file/blob 数据。该字符串在默认情况下采用“UTF-8”编码。使用可选编码参数可指定其他格式。
FileReader.readAsDataURL(Blob|File) - result 属性将包含编码为数据网址的 file/blob 数据。
FileReader.readAsArrayBuffer(Blob|File) - result属性将包含ArrayBuffer 对象形式的 file/blob 数据。
对FileReader 对象调用其中某一种读取方法后,可使用onloadstart、onprogress、onload、onabort、onerror和 onloadend跟踪其进度。
废话不多说,直接上例子吧,看完就理顺了!
<input id="input" type="file">
<script>
const input = document.querySelector('input[type=file]')
input.addEventListener('change', ()=>{
const reader = new FileReader()
reader.readAsDataURL(input.files[0]) // input.files[0]为第一个文件
console.log(reader);//输出结果看下图~
reader.onload = ()=>{
const img = new Image()
img.src = reader.result;// reader.result为获取结果
document.body.appendChild(img)
}
}, false)
script>
console.log(reader) 输出结果~

分割文件
有时候上传的文件非常的大,可能会导致上传速度非常慢,为了提高上传速度,所以就有了文件切片的思想,通过彼此独立的字节范围块读取和发送文件。然后,由服务器组件负责按正确顺序重建文件。
使用Blob.slice方法来对文件进行分割,同时该方法在不同的浏览器使用方式不同。
兼容代码~
const blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
下面看具体代码实例~
<input type="file" id="files" name="file" />
Read bytes:
<span class="readBytesButtons">
<button data-startbyte="0" data-endbyte="4">1-5button>
<button data-startbyte="5" data-endbyte="14">6-15button>
<button data-startbyte="6" data-endbyte="7">7-8button>
<button>entire filebutton>
span>
<div id="byte_range">div>
<div id="byte_content">div>
<script>
function readBlob(opt_startByte, opt_stopByte) {
var files = document.getElementById('files').files;
if (!files.length) {
alert('Please select a file!'); return;
}
var file = files[0];
var start = parseInt(opt_startByte) || 0;
var stop = parseInt(opt_stopByte) || file.size - 1;
var reader = new FileReader();
// If we use onloadend, we need to check the readyState.
reader.onloadend = function(evt) {
if (evt.target.readyState == FileReader.DONE) { // DONE == 2
document.getElementById('byte_content').textContent = evt.target.result;
console.log(start)
document.getElementById('byte_range').textContent = ['Read bytes: ', start + 1, ' - ', stop + 1, ' of ', file.size, ' byte file'].join('');
}
};
const blobSlice =
File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice;
reader.readAsBinaryString(blobSlice.call(file,start,stop+1))
}
document.querySelector('.readBytesButtons').addEventListener('click', function(evt) {
if (evt.target.tagName.toLowerCase() == 'button') {
var startByte = evt.target.getAttribute('data-startbyte');
var endByte = evt.target.getAttribute('data-endbyte');
readBlob(startByte, endByte);
}
}, false);
script>
监控读取进度
使用异步事件处理时还能顺便获得一项优势,那就是能够监控文件的读取进度;这对于读取大文件、查找错误和预测读取完成时间非常实用。onloadstart和 onprogress事件可用于监控读取进度。
断点续传
解决了大文件上传速度差的问题,如果很不幸,突然遇到网络中断了,已经上传的部分还得重新上传(害!),是可忍熟不可忍!!断点续传来助力!
具体就是——已上传的部分跳过,只传未上传的部分。
重新上传的时候使用spark-md5来生成文件 hash,区分此文件是否已上传。
- 为每个分段生成 hash 值,使用 spark-md5 库
- 将上传成功的分段信息保存到本地
- 重新上传时,进行和本地分段 hash 值的对比,如果相同的话则跳过,继续下一个分段的上传
那就顺便补充一下spark-md5的知识吧~
js-spark-md5
一个前端类包,戳此下载
作用:无需上传文件就快速获取本地文件md5。
md5:每个文件的md5值都是唯一的,我们可以根据通过 SparkMD5去给每个文件生成一个hash值,这有什么好处呢?
正因为每个文件的md5是一样的,那么,我们在做文件上传的时候,就只要在前端先获取要上传的文件md5,并把文件md5传到服务器,对比之前文件的md5,如果存在相同的md5,我们只要把文件的名字传到服务器关联之前的文件即可,并不需要再次去上传相同的文件,再去耗费存储资源、上传的时间、网络带宽,实现真正意义上的“秒传”!
下面来唠一下它怎么用?
(1)直接通过构造函数SparkMD5调用方法
var hexHash = SparkMD5.hash('Hi there');
//生成一个十六进制哈希 d9385462d3deff78c352ebb3f941ce12
var rawHash = SparkMD5.hash('Hi there', true);
//生成一个原始哈希(二进制数据) Ô
ŒÙ
(2)下面这种比较普遍~
var spark = new SparkMD5();
spark.append('Hi');
spark.append(' there');
var hexHash = spark.end(); // hex hash
var rawHash = spark.end(true); // raw hash(binary string)
console.log(hexHash);//十六进制哈希 d9385462d3deff78c352ebb3f941ce12
console.log(rawHash);//原始哈希(二进制数据) Ô
ŒÙ
ps:SparkMD5还有很多其他的方法,详情请戳此,下面也会讲一些常用的~
上代码!!
demo(大文件上传+断点续传),有需要的小伙伴可以去看看我写的demo
ps:上传文件到服务器的话,一般是用FormData对象,此时content-type就是multipart/form-data,这个demo里面也有用到~
希望看到这里的你,已经懂啦!