黄仁勋从煤气灶下取出最新GPU:7nm全新安培架构,售价20万美元,训练性能顶6张V100...
晓查 贾浩楠 发自 凹非寺
量子位 报道 | 公众号 QbitAI
深黑的皮衣,苍白的头发。
熟悉的老黄又来了,但是少了宽敞的会场和粉丝的尖叫。
因为美国疫情的原因,英伟达和其他科技公司一样,把今年的GPU技术大会(GTC 2020)改成线上举行。
然而让人意想不到的是,今年的GTC甚至都没有采用直播形式,而是直接一口气放出7段视频,还是黄仁勋在家提前录好的。偷懒程度可能仅次于苹果直接上架新品。
就算Zoom不安全,老黄你好歹用别的软件直播一下啊。
不知道是不是听过玩家圈里2080Ti煤气灶的梗,老黄昨天发了一段预热视频:在自家煤气灶下方取出了一个超大的的设备——一个装有8个GPU的服务器主板,号称全球最大图形卡。
老黄的意思是不是说,这台GPU能热到和烤箱一样的程度呢。
从体积来看,这不可能是一台消费级显卡,难道RTX 3080没有了?
很遗憾,是的。
今年的GTC没有RTX系列游戏显卡的更新。但是已经服役3年的V100迎来了继任者,全新基于安培架构的专业级GPU——A100。在AI训练这件事上,一片顶过去六片。

这台AI运算性能怪兽进一步加强了张量运算能力,加入新的支持稀疏张量运算的张量核心,以后黄教主GPU似乎可以改称TPU了。
至于A100性能参数如何,下面开始详解。
首款安培架构GPU问世
V100的“V”代表Volta架构,A100的“A”则代表Ampere架构。
最新的A100 GPU集成了超过540亿个晶体管,这使它荣获全球最大尺寸的7nm制程处理器的称号。
黄教主解释道,如此高的集成度已经达到了现今半导体工艺的极限,A100是人类有史以来生产过的最大的处理器内核,也是人类有史以来集成度最高的计算机处理器。
英伟达大幅度提升了A100的张量计算核心(Tensor cores)的性能,FP32性能达到19.5万亿次/秒。包含6912个CUDA核心、40GB内存和1.6TB/s的内存带宽。
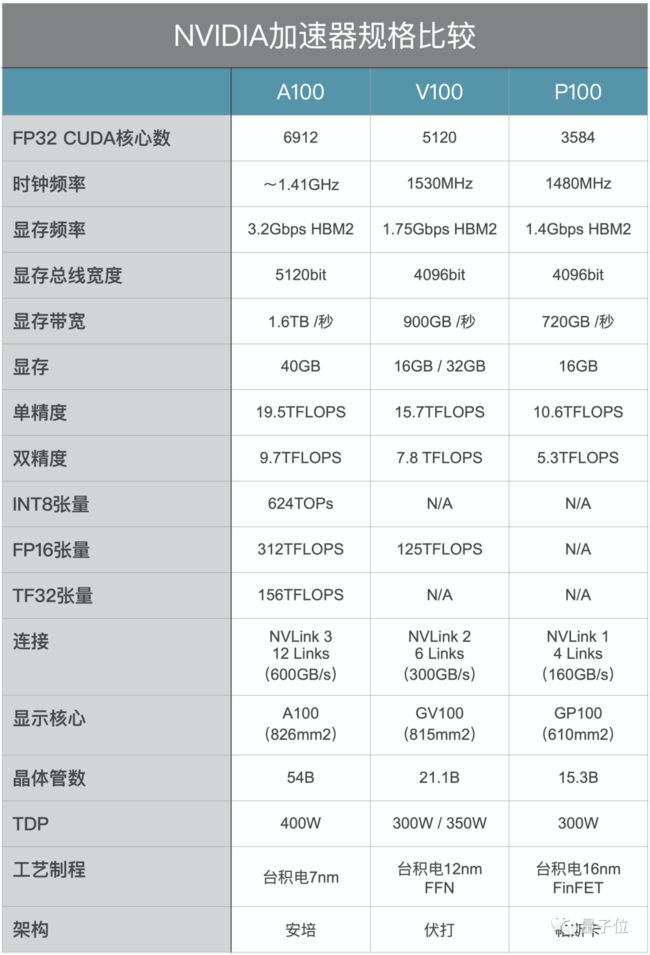
但集成了如此优秀的性能的GPU,你却不能用它来玩任何3A大作。
A100本身也不是游戏显卡。在单精度和双精度浮点算力上,A100相比V100提升不大,但是张量核心的运算能力有了很大的提高,FP16张量算力几乎是V100的2.5倍。
而且V100还新加入了对32位张量浮点运算(TF32)的支持,能更好地处理AI运算中的稀疏张量。
加入对稀疏张量的优化后,A100在FP16精度上的算力是V100的5倍,而在INT8上则提升了200倍!
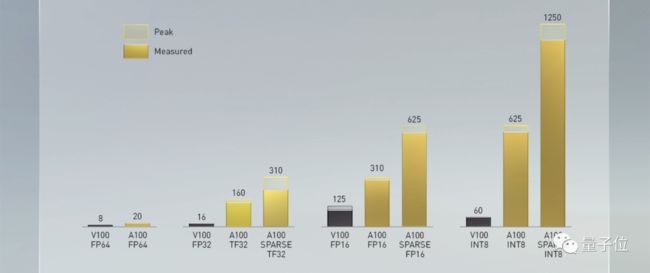
这次强大的张量核心,给A100在AI上带来了性能的飞跃。以NLP领域的BERT算法为例,A100 比 V100在训练速度上提升6倍,在推理速度上提升了7倍。
 显存带宽的提升也非常可观,多层HBM2内存可提供总计1.6 TB/s的带宽,比前代提升了78%。
显存带宽的提升也非常可观,多层HBM2内存可提供总计1.6 TB/s的带宽,比前代提升了78%。
英伟达将把A100应用到堆栈AI系统,就是老黄前几天从自家烤箱中拿出来的那个「预热」好的GPU板。这个全新的堆栈AI系统称为DGX A100,集成了8块A100。
DGX A100系统能够达到5千万亿次/s的浮点计算性能。这要归功于这8颗A100,使用了Nvidia的第三代NVLink进行集成。
8个GPU组合在一起,意味着有320GB的GPU内存和12.4TB/s的内存带宽。系统还包括15TB的第4代NVMe内部存储,为AI训练任务提供强大的支持。
这套系统的价格不菲,DGX A100的售价为19.9万美元,堪称史上最贵“烤箱”。
但是黄教主就是刀法娴熟,之前对消费级显卡精准切削,现在对DGX A100精准“切蛋糕”。

这套刀法叫做多实例GPU(MIG),可将单个A100 GPU划分为多达七个独立的GPU。
也就是说,使用DGX A100系统的研究人员和科学家可以将任务拆分成多达56个实例,将众多小规模任务分散在强大的GPU上。
买不起A100没关系,可以再找几个人众筹啊。
DGX A100系统已经开始发售,首先将应用在美国阿贡国家实验室对COVID-19新冠病毒的研究中。
黄仁勋说:“DGX A100系统的算力将帮助研究人员探索治疗方法和疫苗,并研究病毒的传播,使科学家能够在数月或数日内完成数年的AI加速工作。”
除了科研机构外,英伟达表示,微软、亚马逊、谷歌、阿里、百度、腾讯、浪潮、联想等大型云服务提供商计划将A100 整合到自己的产品中。
自动驾驶芯片性能提升6倍
在本次GTC大会主题演讲中,黄仁勋宣布,通过即将推出的Orin系统芯片(SoC)系列和A100 GPU,对现有的英伟达自动驾驶专用平台DRIVEAGX进行扩展。

此次扩展的范围覆盖从ADAS系统到DRIVEAGX PegasusRobotaxi平台。
新DRIVEAGX平台将会搭载一款新型Orin SoC。它的功率仅为5瓦,但性能却可达到10TOPS。
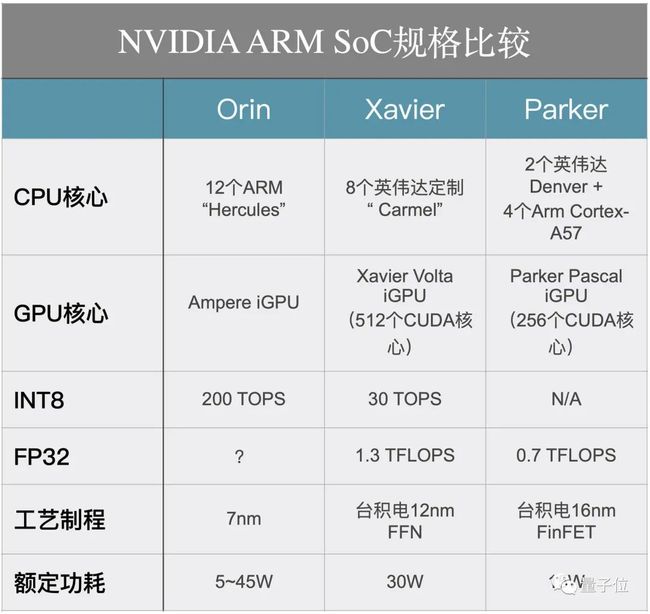
新平台还凭借两个Orin SoC和两块A100 GPU,实现2000TOPS的性能,满足自动驾驶所需的更高分辨率传感器输入,以及更先进的自动驾驶算法。
该架构是英伟达自动驾驶SoC迄今为止最大的性能飞跃,将DRIVE系统的性能提高了6倍。
现在,已经有小马智行、法拉第未来、Canoo等电动汽车和自动驾驶初创公司宣布与英伟达合作,在研发的汽车或自动驾驶产品中使用DRIVEAGX计算平台。
新边缘AI芯片
本次线上GTC 2020还发布了两款性能强大的EGX边缘AI平台产品:适用于较大型商业通用服务器上的EGXA100,和适用于微型边缘服务器的Jetson Xavier NX。
 这两款产品能够在边缘提供安全、高性能的AI处理能力。
这两款产品能够在边缘提供安全、高性能的AI处理能力。
EGX Jetson Xavier NX是全球体积最小、性能最强大的AI算力平台,适用于微型服务器和边缘智能物联网盒。
新主板的外观与Jetson Nano Developer Kit完全相同。在连接方面,它仍然拥有HDMI和DisplayPort接口,4个USB 3.0接口,一个microUSB接口,以及常见的GPIO接口选项。为了将摄像头连接到系统,它还配备了两个MIPI CSI-2端口连接器。
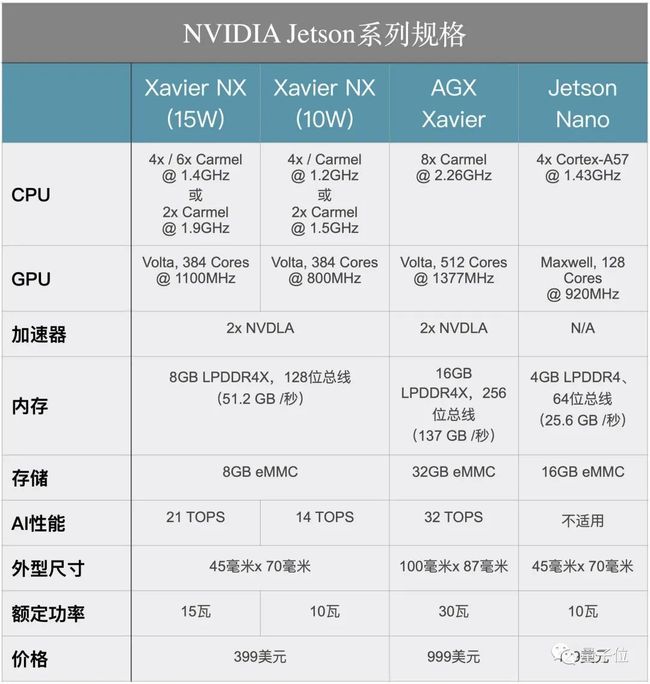
Xavier NX本身不是新东西,但是这次英伟达开始以开发者套件形式出售,价格和单机相同,都是399美元。与Jetson Nano的被动散热方案相比,新的开发套件采用了主动式散热风扇。
平台自带英伟达提供的 “云-native “支持,提供了边缘AI系统部署的解决方案,包括AI模型实例,帮助用户入门AI开发。
其他更新
除了A100、自动驾驶AGX、边缘平台Jetson Xavier NX外,英伟达还推出了:
1、GPU加速应用框架——NVIDIA Jarvis
2、开源社区合作,为Apache Spark 3.0提供端到端GPU加速
3、NIVIDIA医疗平台Clara重大性能拓展
4、25/50 Gb/s智能以太网卡NVIDIA Mellanox ConnectX-6LxSmartNIC

游戏显卡呢?
这次英伟达并未推出游戏显卡,其实也在意料之中。
老黄向来以刀法精准著称,去年才发布了20系的Super显卡,在中端显卡之间插入空位,低端显卡又有1660卡位,实在是没有动力升级啊。
况且在消费级显卡上使用7nm工艺,将比上一代的12nm制程提升太多,此前有传言称,3080Ti的性能比2080Ti提升40%。
果真如此的话,黄仁勋就真的把牙膏挤爆了。
安培架构都来了,RTX 3080还会远吗?更何况安培架构提升还这么大,下一代游戏显卡性能可期啊!
参考链接:
https://www.youtube.com/playlist?list=PLZHnYvH1qtOZ2BSwG4CHmKSVHxC2lyIPL
— 完 —
北大历史博士直播开讲
博物馆真有趣
带小朋友去博物馆该看什么?怎么看?
5月18日晚7:30,考察过500多个国内外博物馆、遗址、考古现场的资深博物馆专家、北京大学中国古代史博士王珊,将面向7-15岁孩子和家长直播开讲,带大家“云”游六大省级博物馆和它们的镇馆之宝,扫描下图二维码参与▽

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !