tensorflow 的 image segmentation 的准确率指标如何构建
上周在做一个 GCN 语义分割模型的过程中,遭遇了挺多麻烦的,一一记录一下,为自己以后遇到相似问题时提供一些解决的思路。以下是我自己在做的项目的代码地址,
Label
以往的分类问题很简单,label 就是一个稀疏向量。但是语义分割问题不同,它的 label 就是一张图片,我们再根据这张图像中每个像素点的颜色,查表之后证实每个像素点分属什么类别,然后再赋予每个点一个稀疏向量。推广的说,如果输入的张量的维度是是 [BATCH_SIZE, W, H, C],对应的 label 张量的尺寸就是 [BATCH_SIZE, W, H, NUM_CLASSES]。具体怎么写呢?我所学习的是如下链接中链接在此的相应定义。
def one_hot_it(label, label_values):
"""
Convert a segmentation image label array to one-hot format
by replacing each pixel value with a vector of length num_classes
# Arguments
label: The 2D array segmentation image label
label_values
# Returns
A 2D array with the same width and hieght as the input, but
with a depth size of num_classes
"""
# st = time.time()
# w = label.shape[0]
# h = label.shape[1]
# num_classes = len(class_dict)
# x = np.zeros([w,h,num_classes])
# unique_labels = sortedlist((class_dict.values()))
# for i in range(0, w):
# for j in range(0, h):
# index = unique_labels.index(list(label[i][j][:]))
# x[i,j,index]=1
# print("Time 1 = ", time.time() - st)
# st = time.time()
# https://stackoverflow.com/questions/46903885/map-rgb-semantic-maps-to-one-hot-encodings-and-vice-versa-in-tensorflow
# https://stackoverflow.com/questions/14859458/how-to-check-if-all-values-in-the-columns-of-a-numpy-matrix-are-the-same
semantic_map = []
for colour in label_values:
# colour_map = np.full((label.shape[0], label.shape[1], label.shape[2]), colour, dtype=int)
equality = np.equal(label, colour)
class_map = np.all(equality, axis = -1)
semantic_map.append(class_map)
semantic_map = np.stack(semantic_map, axis=-1)
# print("Time 2 = ", time.time() - st)
return semantic_map但是返回的结果实际上是由 True 和 False 构成的张量,不知道具体在计算时是否会有影响。查看了 numpy 的函数后发现, numpy.all 有一个用法可以返回数值而不是布尔型,所以更改之后我自己的通过给出图片来计算 label 的函数如下。
def to_one_hot(label, label_values = [[0, 0, 0], [128, 0, 0]], boolean = True):
semantic_map = []
if boolean:
for colour in label_values:
equality = np.equal(label, colour)
class_map = np.all(equality, axis = -1)
semantic_map.append(class_map)
else:
for colour in label_values:
equality = np.equal(label, colour)
out = np.zeros([1056, 1920], dtype = np.float)
class_map = np.all(equality, axis = -1, out = out)
semantic_map.append(out)
semantic_map = np.stack(semantic_map, axis = -1)
return semantic_map
Accuracy
语义分割问题和我自己之前接触过的分类问题,在准确率即 ACCURACY 的计算上有若干不同。我一开始没有想太多,因为感觉用上面那个 Github 其中的计算公式有点麻烦,所以自己写了如下的代码,结果发现代码会卡在这个位置无法继续向下运行。
def cal_global_accuracy(logits, labels):
'''
对给入的 batch_size 数据进行计算,计算它们的 global_accuracy.
'''
batch_size, h, w, _ = labels.shape.as_list()
#print(batch_size)
total = batch_size*h*w
cnt = 0
for i in range(batch_size):
for j in range(h):
for k in range(w):
if logits[i][j][k] == labels[i][j][k]:
cnt += 1
return float(cnt)/float(total)具体在运行时也没有报错的表现,但是,在任务管理器中可以看到该程序所占据 CPU 越来越多,也就意味着这个地方实际上是一直在运行,很可能是我写的三层循环嵌套很严重的占用了内存空间,导致无法进行。我把这部分代码屏蔽掉之后就可以顺利运行了。
训练时损失 Loss 为 Nan
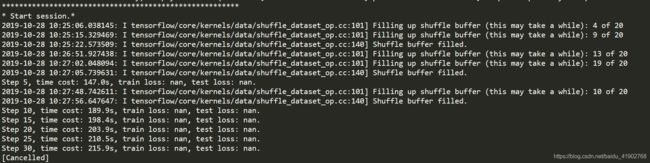
我暂时屏蔽了 accuracy 计算的部分。从图中可以看到无论是训练还是测试,损失都是 nan。首先判断的问题,就是如果计算的对象类型不对应,一个是浮点一个是 bool 那肯定是会报错的,想到的办法之一就是之前的 Accuracy 部分,将原本是 Boolean 类型的 label 转化成数值类型。但是改进之后还是照旧,考虑到我的对象是在图片中筛选出车道,实际上车道点是很少的,所以加上使用了 random_crop,使得很有可能出现整张图片都是同一种类的情况;或者,不至于都是同一类,但是其中一类的数量特别少时也是不利于训练的进行的。会不会依然是类似的问题,也就是 label 的尺寸和之前做分类时不同呢?之前,经过全连接层处理之后的结果都是 [BATCH_SIZE, NUM_CLASSES],但是现在处理完是 [BATCH_SIZE, W, H, NUM_CLASSES],为了严谨起见我就选择了一个 Fallten 函数来处理,示意代码如下。
X = tf.placeholder(tf.float16, [BATCH_SIZE, IMG_H, IMG_W, IMG_C])
Y = tf.placeholder(tf.float16, [BATCH_SIZE, IMG_H, IMG_W, NUM_CLASSES])
_pred = GCN.build_gcn(X, NUM_CLASSES)
#logits 是前向传播的结果,labels 是正确的标签
_pred_flatten = tf.layers.Flatten()(_pred)
Y_flatten = tf.layers.Flatten()(Y)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = _pred_flatten, labels = Y_flatten)) 可惜,处理之后还是不行。查看了处理之后的shape,发现了一个问题,此时我使用的batch_size 为 2,Fallten 后得到的张量的尺寸是 (2, 4055040), 4055040 = 1920*1056*2,其实我理想的是 (2*1920*1056, 2),次数的单独的 2 就是 NUM_CLASSES,这样子去计算交叉熵才合理。这种张量的拆解组合操作,基本上使用 stack、unstack 和 concat 这三个函数可以实现。
def label_before_cal_loss(input):
'''
将图片的 label 以及网络计算输出的结果,给到计算交叉熵之前,需要把原本四维的
张量转化成二维的张量》
'''
output = input
while len(output.shape) > 2:
output = tf.unstack(output, axis = 0)
output = tf.concat(output, axis = 0)
return output我还取消使用 random_crop 用完整的图片,以避免说随机截取到的图片里面只有一个类别,但是也是不行。 此时我使用的batch_size 为 2,可以看到其实还是很快的,可以适当将 batch_size 再提高一点点。
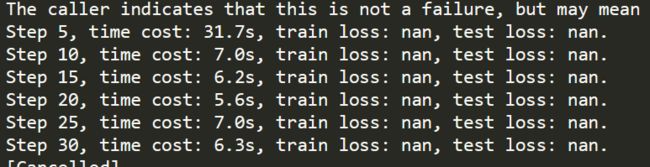
所以,我猜测可能是不能够直接使用 tensorflow 定义的损失函数,需要自己定义权重不同的损失函数,否则按照损失函数的计算公式,当其中一个类比例非常低是,确实会出现这种情况,并且也不利于梯度下降,所以需要对比重少的类别赋予更高的权重。