Hive 下的 Apache Zeppelin 集成部署
文章目录
- 一、Zeppelin简介
- Zeppelin特性
- Apache Spark 集成
- 数据可视化
- 二、Zeppelin的安装部署
- 使用Beeline连接hive测试
- 下载 Zeppelin
- 修改配置文件
- 启动zeppelin
作为大数据研究分析,我越发觉得有必要能有一款快速上手,能够适合单一数据处理、但后端处理语言繁多的场景相关的开源工具。最近我找到了一款Apache Zeppelin,下面是我初步实战初步收获。
一、Zeppelin简介
Apache Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化。背后可以接入不同的数据处理引擎,包括spark, hive, tajo等,原生支持scala, java, shell, markdown等。它的整体展现和使用形式和Databricks Cloud是一样的,就是来自于当时的demo。
Zeppelin可实现你所需要的:
- 数据采集
- 数据发现
- 数据分析
- 数据可视化和协作
支持多种语言,默认是scala(背后是spark shell),SparkSQL, Markdown 和 Shell。

甚至可以添加自己的语言支持。如何写一个zeppelin解释器
Zeppelin特性
Apache Spark 集成
Zeppelin 提供了内置的 Apache Spark 集成。你不需要单独构建一个模块、插件或者库。
Zeppelin的Spark集成提供了:
- 自动引入SparkContext 和 SQLContext
- 从本地文件系统或maven库载入运行时依赖的jar包。更多关于依赖载入器
- 可取消job 和 展示job进度
数据可视化
一些基本的图表已经包含在Zeppelin中。可视化并不只限于SparkSQL查询,后端的任何语言的输出都可以被识别并可视化。
Bank
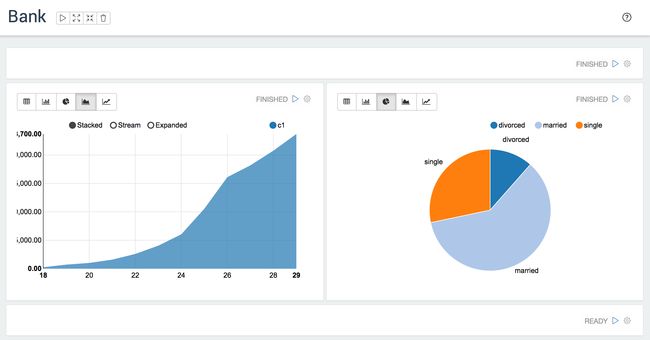
动态表格
Zeppelin 可以在你的笔记本中动态地创建一些输入格式。
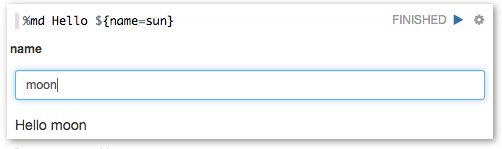
协作
Notebook 的 URL 可以在协作者间分享。 Zeppelin 然后可以实时广播任何变化,就像在 Google docs 中一样。

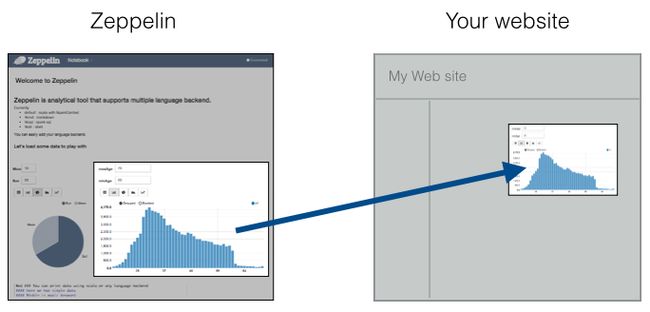
发布
Zeppelin提供了一个URL用来仅仅展示结果,那个页面不包括Zeppelin的菜单和按钮。这样,你可以轻易地将其作为一个iframe集成到你的网站。
二、Zeppelin的安装部署
需要准备的的软件
[root@hw1 /]# echo $JAVA_HOME;
/opt/soft/jdk180
[root@hw1 /]# echo $HADOOP_HOME;
/opt/soft/hadoop260
[root@hw1 /]# jps
15120 SecondaryNameNode
14739 NameNode
14886 DataNode
15286 ResourceManager
15391 NodeManager
1791 Jps
使用Beeline连接hive测试
在 hive 文件夹下的 conf 里的 hive-site.xml 配置环境变量
[root@hw1 conf]# vi hive-site.xml
<property>
<name>hive.server2.authentication</name>
<value>NONE</value>
</property>
<property>
<name>hive.server2.thrift.client.user</name>
<value>root</value>
<description>Username to use against thrift client</description>
</property>
<property>
<name>hive.server2.thrift.client.password</name>
<value>root</value>
<description>Password to use against thrift client</description>
</property>
Beeline 要与HiveServer2配合使用 服务端启动hiveserver2 ,客户的通过beeline两种方式连接到hive
nohup hive --service matestore &
hiveserver2
beeline -u jdbc:hive2://localhost:10000/default -n root
!quit退出
下载 Zeppelin
wget http://archive.apache.org/dist/zeppelin/zeppelin-0.7.3/zeppelin-0.8.1-bin-all.tgz
解压 本文安装路径十 /opt/soft 并改名 zeppelin081
解压完毕后查看
[root@hw1 soft]# ls
derby.log fun.jar hive110 shoppings-1.0-SNAPSHOT.jar
encry.jar hadoop260 jdk180 zeppelin081
[root@hw1 soft]#
配置环境变量 拷贝hive配置文档
[root@hw1 soft]# cp /opt/soft/hive110/conf/hive-site.xml /opt/soft/zeppelin081/conf/
[root@hw1 soft]# cp /opt/soft/hadoop260/share/hadoop/common/hadoop-common-2.6.0-cdh5.14.2.jar /opt/soft/zeppelin081/interpreter/jdbc/
[root@hw1 soft]# cp /opt/soft/hive110/lib/hive-jdbc-1.1.0-cdh5.14.2-standalone.jar /opt/soft/zeppelin081/interpreter/jdbc/
修改配置文件
在conf文件夹目录下
[root@hw1 conf]# cp zeppelin-site.xml.template zeppelin-site.xml
[root@hw1 conf]# cp zeppelin-env.sh.template zeppelin-env.sh
vi zeppelin-env.sh
// 修改
export JAVA_HOME=/opt/soft/jdk180
export HADOOP_CONF_DIR=/opt/soft/hadoop260/etc/hadoop
vi zeppelin-site.xml
// 将端口号修改 避免与tomcat重复
<property>
<name>zeppelin.server.addr</name>
<value>192.168.56.122</value>
<description>Server address</description>
</property>
<property>
<name>zeppelin.server.port</name>
<value>9090</value>
<description>Server port.</description>
</property>
启动zeppelin
[root@hw1 ~]# cd /opt/soft/zeppelin081/bin
[root@hw1 bin]# ls
common.cmd functions.sh interpreter.sh zeppelin-daemon.sh
common.sh install-interpreter.sh stop-interpreter.sh zeppelin.sh
functions.cmd interpreter.cmd zeppelin.cmd
[root@hw1 bin]# ./zeppelin-daemon.sh start
[root@hw1 bin]# ./zeppelin-daemon.sh start
Zeppelin start [ OK ]
启动成功 则可通过浏览器以及配置的端口号查看
