邻近算法(KNN算法)
-
邻近算法
锁定
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是 数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
- k最邻近分类算法
- k-NearestNeighbor
- 用于分类,对未知事物的识别
目录
右图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。

K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 KNN方法虽然从原理上也依赖于极限定理,但在类别决策时,只与极少量的相邻样本有关。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
KNN算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻居,将这些邻居的属性的平均值赋给该样本,就可以得到该样本的属性。更有用的方法是将不同距离的邻居对该样本产生的影响给予不同的 权值(weight),如权值与距离成反比。
1. 准备数据,对数据进行 预处理
2. 选用合适的数据结构存储训练数据和测试元组
3. 设定参数,如k
4.维护一个大小为k的的按距离由大到小的 优先级队列,用于存储最近邻训练元组。随机从训练元组中选取k个元组作为初始的最近邻元组,分别计算测试元组到这k个元组的距离,将训练元组标号和距离存入优先级队列
5. 遍历训练元组集,计算当前训练元组与测试元组的距离,将所得距离L 与优先级队列中的最大距离Lmax
6. 进行比较。若L>=Lmax,则舍弃该元组,遍历下一个元组。若L < Lmax,删除优先级队列中最大距离的元组,将当前训练元组存入优先级队列。
7. 遍历完毕,计算优先级队列中k 个元组的多数类,并将其作为测试元组的类别。
8. 测试元组集测试完毕后计算误差率,继续设定不同的k值重新进行训练,最后取误差率最小的k 值。
[1]
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2. 适合对稀有事件进行分类;
3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
[1]
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
可理解性差,无法给出像决策树那样的规则。
[1]
kNN算法因其提出时间较早,随着其他技术的不断更新和完善,kNN算法的诸多不足之处也逐渐显露,因此许多kNN算法的改进算法也应运而生。
针对以上算法的不足,算法的改进方向主要分成了分类效率和分类效果两方面。
分类效率:事先对样本属性进行约简,删除对分类结果影响较小的属性,快速的得出待分类样本的类别。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
分类效果:采用权值的方法(和该样本距离小的邻居权值大)来改进,Han等人于2002年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法WAkNN (weighted adjusted k nearest neighbor),以促进分类效果;而Li等人于2004年提出由于不同分类的文件本身有数量上有差异,因此也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。
一、算法概述
1、kNN算法又称为k近邻分类(k-nearest neighbor classification)算法。
最简单平凡的分类器也许是那种死记硬背式的分类器,记住所有的训练数据,对于新的数据则直接和训练数据匹配,如果存在相同属性的训练数据,则直接用它的分类来作为新数据的分类。这种方式有一个明显的缺点,那就是很可能无法找到完全匹配的训练记录。
kNN算法则是从训练集中找到和新数据最接近的k条记录,然后根据他们的主要分类来决定新数据的类别。该算法涉及3个主要因素:训练集、距离或相似的衡量、k的大小。
2、代表论文
Discriminant Adaptive Nearest Neighbor Classification
Trevor Hastie and Rolbert Tibshirani
IEEE TRANSACTIONS ON PAITERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 18, NO. 6, JUNE 1996
http://www.stanford.edu/~hastie/Papers/dann_IEEE.pdf
3、行业应用
客户流失预测、欺诈侦测等(更适合于稀有事件的分类问题)
二、算法要点
1、指导思想
kNN算法的指导思想是“近朱者赤,近墨者黑”,由你的邻居来推断出你的类别。
计算步骤如下:
1)算距离:给定测试对象,计算它与训练集中的每个对象的距离
2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类
2、距离或相似度的衡量
什么是合适的距离衡量?距离越近应该意味着这两个点属于一个分类的可能性越大。
觉的距离衡量包括欧式距离、夹角余弦等。
对于文本分类来说,使用余弦(cosine)来计算相似度就比欧式(Euclidean)距离更合适。
3、类别的判定
投票决定:少数服从多数,近邻中哪个类别的点最多就分为该类。
加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
三、优缺点
1、优点
简单,易于理解,易于实现,无需估计参数,无需训练
适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)
特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好
2、缺点
懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢
可解释性较差,无法给出决策树那样的规则。
四、常见问题
1、k值设定为多大?
k太小,分类结果易受噪声点影响;k太大,近邻中又可能包含太多的其它类别的点。(对距离加权,可以降低k值设定的影响)
k值通常是采用交叉检验来确定(以k=1为基准)
经验规则:k一般低于训练样本数的平方根
2、类别如何判定最合适?
投票法没有考虑近邻的距离的远近,距离更近的近邻也许更应该决定最终的分类,所以加权投票法更恰当一些。
3、如何选择合适的距离衡量?
高维度对距离衡量的影响:众所周知当变量数越多,欧式距离的区分能力就越差。
变量值域对距离的影响:值域越大的变量常常会在距离计算中占据主导作用,因此应先对变量进行标准化。
4、训练样本是否要一视同仁?
在训练集中,有些样本可能是更值得依赖的。
可以给不同的样本施加不同的权重,加强依赖样本的权重,降低不可信赖样本的影响。
5、性能问题?
kNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。
懒惰的后果:构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。
已经有一些方法提高计算的效率,例如压缩训练样本量等。
6、能否大幅减少训练样本量,同时又保持分类精度?
浓缩技术(condensing)
编辑技术(editing)
最简单平凡的分类器也许是那种死记硬背式的分类器,记住所有的训练数据,对于新的数据则直接和训练数据匹配,如果存在相同属性的训练数据,则直接用它的分类来作为新数据的分类。这种方式有一个明显的缺点,那就是很可能无法找到完全匹配的训练记录。
kNN算法则是从训练集中找到和新数据最接近的k条记录,然后根据他们的主要分类来决定新数据的类别。该算法涉及3个主要因素:训练集、距离或相似的衡量、k的大小。
2、代表论文
Discriminant Adaptive Nearest Neighbor Classification
Trevor Hastie and Rolbert Tibshirani
IEEE TRANSACTIONS ON PAITERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 18, NO. 6, JUNE 1996
http://www.stanford.edu/~hastie/Papers/dann_IEEE.pdf
3、行业应用
客户流失预测、欺诈侦测等(更适合于稀有事件的分类问题)
二、算法要点
1、指导思想
kNN算法的指导思想是“近朱者赤,近墨者黑”,由你的邻居来推断出你的类别。
计算步骤如下:
1)算距离:给定测试对象,计算它与训练集中的每个对象的距离
2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类
2、距离或相似度的衡量
什么是合适的距离衡量?距离越近应该意味着这两个点属于一个分类的可能性越大。
觉的距离衡量包括欧式距离、夹角余弦等。
对于文本分类来说,使用余弦(cosine)来计算相似度就比欧式(Euclidean)距离更合适。
3、类别的判定
投票决定:少数服从多数,近邻中哪个类别的点最多就分为该类。
加权投票法:根据距离的远近,对近邻的投票进行加权,距离越近则权重越大(权重为距离平方的倒数)
三、优缺点
1、优点
简单,易于理解,易于实现,无需估计参数,无需训练
适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型)
特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好
2、缺点
懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢
可解释性较差,无法给出决策树那样的规则。
四、常见问题
1、k值设定为多大?
k太小,分类结果易受噪声点影响;k太大,近邻中又可能包含太多的其它类别的点。(对距离加权,可以降低k值设定的影响)
k值通常是采用交叉检验来确定(以k=1为基准)
经验规则:k一般低于训练样本数的平方根
2、类别如何判定最合适?
投票法没有考虑近邻的距离的远近,距离更近的近邻也许更应该决定最终的分类,所以加权投票法更恰当一些。
3、如何选择合适的距离衡量?
高维度对距离衡量的影响:众所周知当变量数越多,欧式距离的区分能力就越差。
变量值域对距离的影响:值域越大的变量常常会在距离计算中占据主导作用,因此应先对变量进行标准化。
4、训练样本是否要一视同仁?
在训练集中,有些样本可能是更值得依赖的。
可以给不同的样本施加不同的权重,加强依赖样本的权重,降低不可信赖样本的影响。
5、性能问题?
kNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。
懒惰的后果:构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。
已经有一些方法提高计算的效率,例如压缩训练样本量等。
6、能否大幅减少训练样本量,同时又保持分类精度?
浓缩技术(condensing)
编辑技术(editing)
1.1 Cover和Hart在1968年提出了最初的邻近算法
1.2 分类(classification)算法
1.3 输入基于实例的学习(instance-based learning), 懒惰学习(lazy learning)
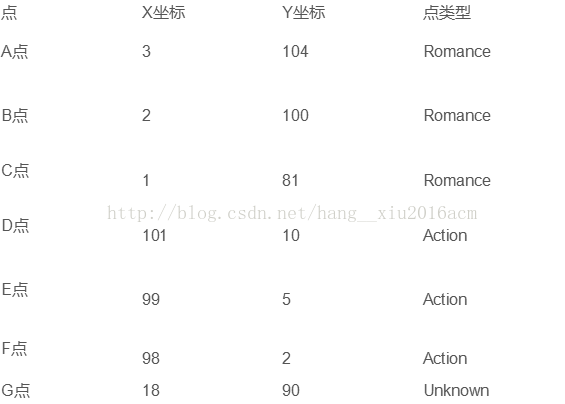
2. 例子:


3. 算法详述
3.1 步骤:
为了判断未知实例的类别,以所有已知类别的实例作为参照
选择参数K
计算未知实例与所有已知实例的距离
选择最近K个已知实例
根据少数服从多数的投票法则(majority-voting),让未知实例归类为K个最邻近样本中最多数的类别
3.2 细节:
关于K
关于距离的衡量方法:
3.2.1 Euclidean Distance 定义
未知电影属于什么类型?
电影属于什么类型?

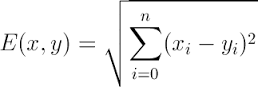

4. 算法优缺点:
4.1 算法优点
简单
易于理解
容易实现
通过对K的选择可具备丢噪音数据的健壮性
4.2 算法缺点
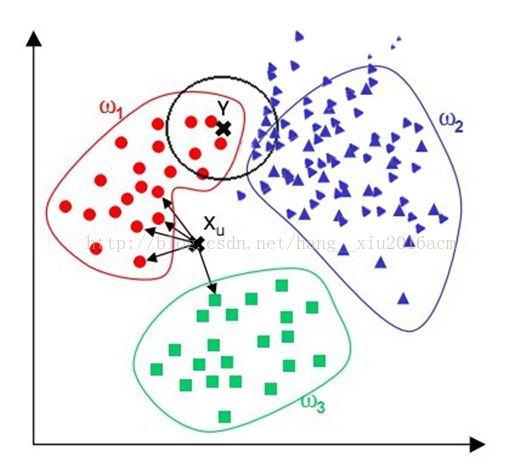
需要大量空间储存所有已知实例
算法复杂度高(需要比较所有已知实例与要分类的实例)
当其样本分布不平衡时,比如其中一类样本过大(实例数量过多)占主导的时候,新的未知实例容易被归类为这个主导样本,因为这类样本实例的数量过大,但这个新的未知实例实际并木接近目标样本
5. 改进版本
考虑距离,根据距离加上权重
比如: 1/d (d: 距离)
1 数据集介绍:
虹膜
150个实例
萼片长度,萼片宽度,花瓣长度,花瓣宽度
(sepal length, sepal width, petal length and petal width)
类别:
Iris setosa, Iris versicolor, Iris virginica.
2. 利用Python的机器学习库sklearn: SkLearnExample.py
from sklearn import neighbors
from sklearn import datasets
knn = neighbors.KNeighborsClassifier()
iris = datasets.load_iris()
print iris
knn.fit(iris.data, iris.target)
predictedLabel = knn.predict([[0.1, 0.2, 0.3, 0.4]])
print predictedLabel
3. KNN 实现Implementation:
# Example of kNN implemented from Scratch in Python
import csv
import random
import math
import operator
def loadDataset(filename, split, trainingSet=[] , testSet=[]):
with open(filename, 'rb') as csvfile:
lines = csv.reader(csvfile)
dataset = list(lines)
for x in range(len(dataset)-1):
for y in range(4):
dataset[x][y] = float(dataset[x][y])
if random.random() < split:
trainingSet.append(dataset[x])
else:
testSet.append(dataset[x])
def euclideanDistance(instance1, instance2, length):
distance = 0
for x in range(length):
distance += pow((instance1[x] - instance2[x]), 2)
return math.sqrt(distance)
def getNeighbors(trainingSet, testInstance, k):
distances = []
length = len(testInstance)-1
for x in range(len(trainingSet)):
dist = euclideanDistance(testInstance, trainingSet[x], length)
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1))
neighbors = []
for x in range(k):
neighbors.append(distances[x][0])
return neighbors
def getResponse(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1]
if response in classVotes:
classVotes[response] += 1
else:
classVotes[response] = 1
sortedVotes = sorted(classVotes.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedVotes[0][0]
def getAccuracy(testSet, predictions):
correct = 0
for x in range(len(testSet)):
if testSet[x][-1] == predictions[x]:
correct += 1
return (correct/float(len(testSet))) * 100.0
def main():
# prepare data
trainingSet=[]
testSet=[]
split = 0.67
loadDataset(r'D:\MaiziEdu\DeepLearningBasics_MachineLearning\Datasets\iris.data.txt', split, trainingSet, testSet)
print 'Train set: ' + repr(len(trainingSet))
print 'Test set: ' + repr(len(testSet))
# generate predictions
predictions=[]
k = 3
for x in range(len(testSet)):
neighbors = getNeighbors(trainingSet, testSet[x], k)
result = getResponse(neighbors)
predictions.append(result)
print('> predicted=' + repr(result) + ', actual=' + repr(testSet[x][-1]))
accuracy = getAccuracy(testSet, predictions)
print('Accuracy: ' + repr(accuracy) + '%')
main()
3.3 举例