scikit-learn Tutorial 学习笔记#001
参考:An introduction to machine learning with scikit-learn
机器学习研究什么
一般来讲,一个学习问题(learning problem)就是通过研究一些已知样本数据来预测未知数据的性质的问题。
学习问题可以大致被分为两类:监督学习 supervised learning 和非监督学习 unsupervised learning 。
- 监督学习:数据中包含我们想要对未知数据预测的性质。其又可分为:
- 分类问题 classification:样本从属于两个或以上的类别,需要机器通过学习已知样本来预测未标记类别的数据属于哪一类。如判断单个手写阿拉伯数字是0-9中的哪个数字。
- 回归问题 regression:所要预测的结果是连续的变量。如预测鲑鱼的长度关于其年龄和重量的函数。
- 非监督学习:数据中不含需要预测的性质。又可分为:
- 聚类问题 clustering:将具有相似特征的数据分成一类。
- 密度估计 density estimation:判断输入数据的分布。
- 数据可视化 visualization:将高维数据降到2-3维以将其可视化。
上述「已知样本数据」一般被称为训练集(training set) ,用来评估测试效果的数据即测试集(testing set)。
读取样例数据集
scikit-learn 库自带有一些数据集。如为研究分类问题的鸢尾花数据集 iris 和手写数字数据集 digits 。
在 python shell 中输入
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> digits = datasets.load_digits()即可将这两个数据集读取到这两个对象中了。
dataset 是一个类似字典的对象。数据的特征(features)存储在 .data 成员中,它总是一个二维数组,大小为 (n_samples, n_features) 。而对于监督学习问题来说,所要预测的性质(即响应数据 response data)则存储在 .target 成员中。
以 digits 数据集为例:
>>> print(digits.data)
[[ 0. 0. 5. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 10. 0. 0.]
[ 0. 0. 0. ..., 16. 9. 0.]
...,
[ 0. 0. 1. ..., 6. 0. 0.]
[ 0. 0. 2. ..., 12. 0. 0.]
[ 0. 0. 10. ..., 12. 1. 0.]]
>>> digits.target
array([0, 1, 2, ..., 8, 9, 8])学习与预测
对于手写数字的分类问题,我们的任务就是用训练集拟合(fit)一个评估器 estimator 然后用它来预测(predict)未知样本的分类。在 scikit-learn 中,一个分类问题的 estimator 就是一个实现了 fit(X, y)和predict(T)方法的对象。
首先定义这个对象:
>>> from sklearn import svm
>>> clf = svm.SVC(gamma=0.001, C=100.) # as it is a classifier之后我们用除最后一个样本以外的所有样本作为训练集来 fit 这个分类器:
>>> clf.fit(digits.data[:-1], digits.target[:-1])
SVC(C=100.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma=0.001, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)用 fit 后的分类器预测一下最后一个样本的分类:
>>> clf.predict(digits.data[-1:])
array([8])可以查看一下预测是否正确:
>>> digits.target[-1:]
array([8])结果正确。可以再借助 matplotlib 直观的看一下这最后一个样本长什么样:
import matplotlib.pyplot as plt
plt.figure(1, figsize=(3, 3))
plt.imshow(digits.images[-1], cmap=plt.cm.gray_r, interpolation='nearest')
plt.show()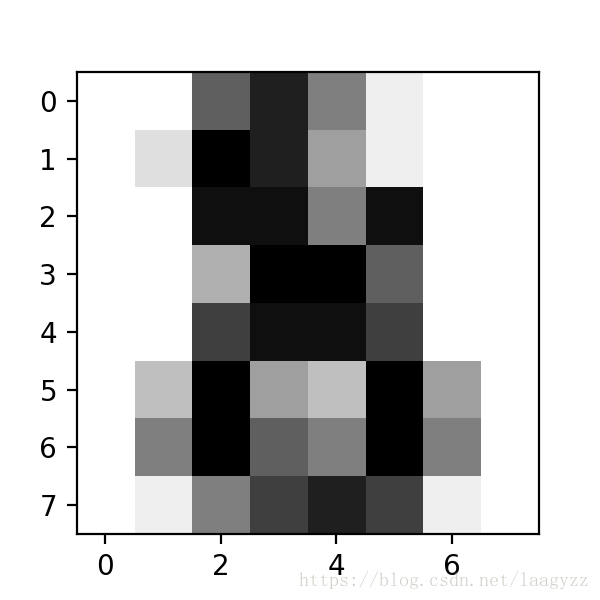
大概可以看出来是数字 8 。
存储模型
训练一个模型有时是需要许多成本的,因此你也许想将训练好的模型存储起来,python 的 pickle 库和 sklearn 中的 joblib 可以帮助你做到这一点。
>>> from sklearn import svm
>>> from sklearn import datasets
>>> clf = svm.SVC()
>>> iris = datasets.load_iris()
>>> X, y = iris.data, iris.target
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> import pickle
>>> s = pickle.dumps(clf)
>>> clf2 = pickle.loads(s)
>>> clf2.predict(X[0:1])
array([0])
>>> y[0]
0
from sklearn.externals import joblib
joblib.dump(clf, 'filename.pkl') 重启 shell 后:
>>> from sklearn import datasets
>>> iris = datasets.load_iris()
>>> X, y = iris.data, iris.target
# 读取之前储存的模型
>>> clf = joblib.load('filename.pkl')
>>> clf.predict(X[0:1])
array([0])惯例
scikit-learn 的评估器还遵从一些特殊的规则来规范其行为。
类型转换
- 一般情况下,输入数据会被转换成
float64:
>>> import numpy as np
>>> from sklearn import random_projection
>>> rng = np.random.RandomState(0)
>>> X = rng.rand(10, 2000)
>>> X = np.array(X, dtype='float32')
>>> X.dtype
dtype('float32')
>>> transformer = random_projection.GaussianRandomProjection()
>>> X_new = transformer.fit_transform(X)
>>> X_new.dtype
dtype('float64')- 回归问题的目标数据会被转换成
float64,而分类问题则不会。
重新拟合
可以通过 sklearn.pipeline.Pipeline.set_params 方法来调整参数重新拟合,覆盖之前的模型。
>>> import numpy as np
>>> from sklearn.svm import SVC
>>> rng = np.random.RandomState(0)
>>> X = rng.rand(100, 10)
>>> y = rng.binomial(1, 0.5, 100)
>>> X_test = rng.rand(5, 10)
>>> clf = SVC()
>>> clf.set_params(kernel='linear').fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='linear',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict(X_test)
array([1, 0, 1, 1, 0])
>>> clf.set_params(kernel='rbf').fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
>>> clf.predict(X_test)
array([0, 0, 0, 1, 0])用set_params()调整kernel参数后模型改变,预测的结果不同。
多类别还是多标签
当使用多类分类器 multiclass classifiers 时,学习和预测的行为和目标数据的形式有关。如
>>> from sklearn.svm import SVC
>>> from sklearn.multiclass import OneVsRestClassifier
>>> X = [[1, 2], [2, 4], [4, 5], [3, 2], [3, 1]]
>>> y = [0, 0, 1, 1, 2]
>>> classif = OneVsRestClassifier(estimator=SVC(random_state=0))
>>> classif.fit(X, y).predict(X)
array([0, 0, 1, 1, 2])这里目标数据y = [0, 0, 1, 1, 2],于是预测的结果则是array([0, 0, 1, 1, 2])。
而如果将y的形式用 LabelBinarizer改为二维的二元标签形式:
>>> y = LabelBinarizer().fit_transform(y)
>>> y
array([[1, 0, 0],
[1, 0, 0],
[0, 1, 0],
[0, 1, 0],
[0, 0, 1]])
>>> classif.fit(X, y).predict(X)
array([[1, 0, 0],
[1, 0, 0],
[0, 1, 0],
[0, 0, 0],
[0, 0, 0]])那么预测的结果也如y的形式,只是注意到第四和第五个样本中全为0,说明三个类别都不符合 fit 后的模型。这与转换形式前的预测结果是不同的。
而如果是多标签问题,即每个样本的目标数据可能包含多个不同的标签,则必须用上述二位的二元标签形式:
>>> from sklearn.preprocessing import MultiLabelBinarizer
>>> y = [[0, 1], [0, 2], [1, 3], [0, 2, 3], [2, 4]]
>>> classif.fit(X, y).predict(X)如果直接fit,则会报错:
ValueError: You appear to be using a legacy multi-label data representation. Sequence of sequences are no longer supported; use a binary array or sparse matrix instead.用 MultiLabelBinarizer 变换y的形式后:
>>> y = MultiLabelBinarizer().fit_transform(y)
>>> y
array([[1, 1, 0, 0, 0],
[1, 0, 1, 0, 0],
[0, 1, 0, 1, 0],
[1, 0, 1, 1, 0],
[0, 0, 1, 0, 1]])
>>> classif.fit(X, y).predict(X)
array([[1, 1, 0, 0, 0],
[1, 0, 1, 0, 0],
[0, 1, 0, 1, 0],
[1, 0, 1, 0, 0],
[1, 0, 1, 0, 0]])