Storm 原理机制杂记
Storm:
Storm是Twitter开源的分布式实时计算系统,Storm通过简单的API使开发者可以可靠地处理无界持续的流数据,进行实时计算,开发语言为Clojure和Java,非JVM语言可以通过stdin/stdout以JSON格式协议与Storm进行通信。Storm的应用场景很多:实时分析、在线机器学习、持续计算、分布式RPC、ETL处理,等等。
storm的优点是全内存计算,因为内存寻址速度是硬盘的百万倍以上,所以storm的速度相比较hadoop非常快(瓶颈是内存,cpu)
缺点就是不够灵活:必须要先写好topology结构来等数据进来分析,如果我们需要对几百个维度进行组合分析,那么。。另外推荐storm的DRPC实在太有用了
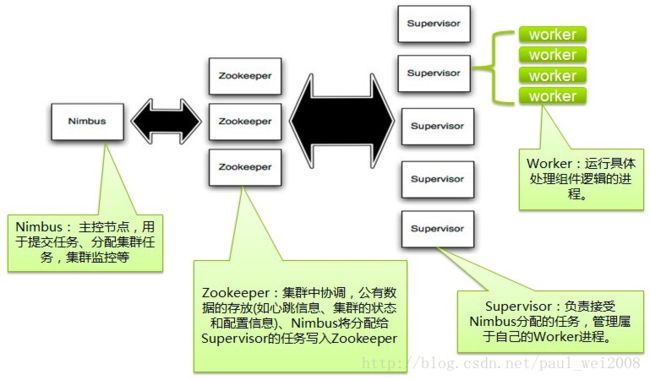
Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:
1. Worker(进程)
2. Executor(线程)
3. Task(逻辑概念任务,物理概念叫executor线程,Storm0.8后多个task由一个excutor执行)
// builder.setBolt("uvbolt", new UvBolt(),2).setNumTasks(4).fieldsGrouping("pvbolt", new Fields("pid","uid")) ;
// UvBolt开启4个task实例(bolt实例),右2个线程执行,如果不设置tasknumber,默认2个线程执行2个task,默认一个线程一个task,每个线程执行task是串行,开启4个task,相同pid,uid进入相同task
hadoop:电梯 storm:扶梯
调整消息不可靠:
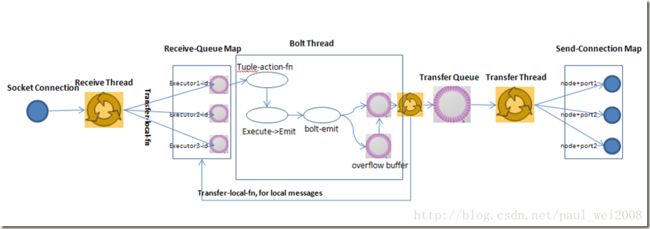
下图简要描述了这3者之间的关系: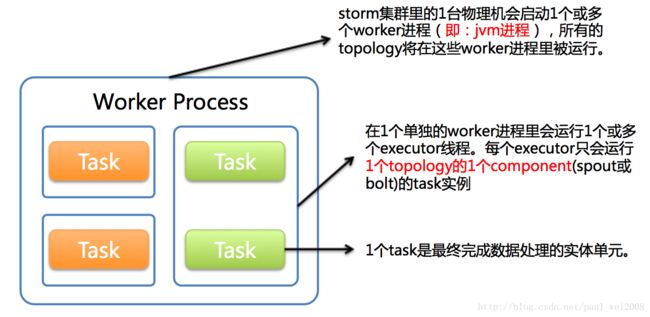
1个worker进程执行的是1个topology的子集(注:不会出现1个worker为多个topology服务)。1个worker进程会启动1个或多个executor线程来执行1个topology的component(spout或bolt)。因此,1个运行中的topology就是由集群中多台物理机上的多个worker进程组成的。
executor是1个被worker进程启动的单独线程。每个executor只会运行1个topology的1个component(spout或bolt)的task(注:task可以是1个或多个,storm默认是1个component只生成1个task,executor线程里会在每次循环里顺序调用所有task实例)。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task。
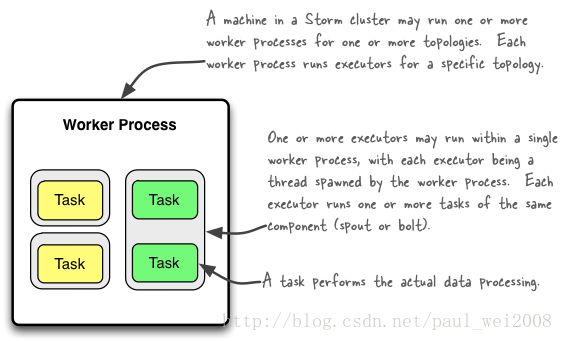

备注:一个灰格一个线程,绿色task四个,由2个线程同时完成,其它启动多线程默认一线程执行一个task,
Task,执行具体数据处理的相关实体,也就是用户实现的Spout/Blot实例。Storm中,一个executor可能会对应一个或者多个task
Config conf = new Config(); conf.setNumWorkers(2); // use two worker processestopologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // parallelism hinttopologyBuilder.setBolt("green-bolt", new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping("blue-spout");topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6) .shuffleGrouping("green-bolt");StormSubmitter.submitTopology( "mytopology", conf, topologyBuilder.createTopology() );
//默认一个excutor一个task.动态调整workprocess和excutors,通过rebalance,无需重启storm
# Reconfigure the topology "mytopology" to use 5 worker processes, # the spout "blue-spout" to use 3 executors and # the bolt "yellow-bolt" to use 10 executors.
$ storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2) .setNumTasks(4) .shuffleGrouping("blue-spout");//每个excutor执行两个task
建议:一般机器数量=task数量 (component:spolt or bolt)
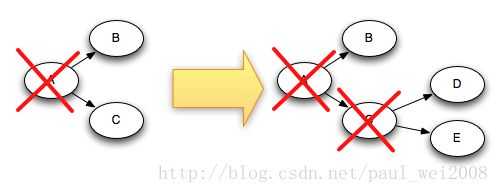
For example, if tuples "D" and "E" were created based on tuple "C", here's how the tuple tree changes when "C" is acked:
Since "C" is removed from the tree at the same time that "D" and "E" are added to it
比如说一个topology中要启动300个线程来运行spout/bolt, 而指定的worker进程数量是60个, 那么storm将会给每个worker分配5个线程来跑spout/bolt
CoordinatedBolt的原理:
Storm:java和clojure语言
Storm是一个分布式的、高容错的实时计算系统。
Storm对于实时计算的的意义相当于Hadoop对于批处理的意义。Hadoop为我们提供了Map和Reduce原语,使我们对数据进行批处理变的非常的简单和优美。同样,Storm也对数据的实时计算提供了简单Spout和Bolt原语。
Storm适用的场景:
1、流数据处理:Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中。
2、分布式RPC:由于Storm的处理组件都是分布式的,而且处理延迟都极低,所以可以Storm可以做为一个通用的分布式RPC框架来使用。
实时查询服务:
全内存:直接提供数据读取服务,定期dump到磁盘或数据库进行持久化。
半内存:使用Redis、Memcache、MongoDB、BerkeleyDB等内存数据库提供数据实时查询服务,由这些系统进行持久化操作,先内存,再Redis
全磁盘:使用HBase等以分布式文件系统(HDFS)为基础的NoSQL数据库,对于key-value引擎,关键是设计好key的分布。
Storm常见模式——批处理:Storm对流数据进行实时处理时,一种常见场景是批量一起处理一定数量的tuple元组,而不是每接收一个tuple就立刻处理一个tuple,这样可能是性能的考虑,或者是具体业务的需要。
例如,批量查询或者更新数据库,如果每一条tuple生成一条sql执行一次数据库操作,数据量大的时候,效率会比批量处理的低很多,影响系统吞吐量。当然,如果要使用Storm的可靠数据处理机制的话,应该使用容器将这些tuple的引用缓存到内存中,直到批量处理的时候,ack这些tuple

- Intra-worker communication in Storm (inter-thread on the same Storm node): LMAX Disruptor
- Inter-worker communication (node-to-node across the network): ZeroMQ or Netty
- Inter-topology communication: nothing built into Storm, you must take care of this yourself with e.g. a messaging system such as Kafka/RabbitMQ, a database, etc.