[+] 词汇相似度计算
1. 任务和环境介绍
任务:实现5种词汇相似度计算方法。
数据:wordsim353
评价方法:Spearman’s rank correlation coefficient
环境:Ubuntu 服务器(4 Intel(R) Xeon(R) CPU E5-2609 v3 @1.90GHz),Anacanda2.4(64-bit),python2.7
基本方法:(1)基于语义词典(Wordnet)的词汇相似度(2)word2vec训练得到词汇向量计算相似度(3)lda训练得到词汇向量计算相似度(4)利用GoogleNews语料得到词汇相似度模型(5)利用Google搜索结果计算相似度。
2. 词汇相似度计算方法
2.1 基于语义词典(Wordnet)的词汇相似度计算
方法: 调用python的工具包nltk, 其中包含了wordnet词典。基于词汇的层次结构计算相似度。其中词汇相似度采用词汇所有语义相似度的最大值。
2.1.1 基于路径的方法
基于上位词层次结构中相互连接的概念之间的最短路径的打分。同义词集与自身比较将返回最大值。
path_similarity(sense1,sense2) # 词在词典层次结构中的最短路径
wup_similarity(sense1, sense2) # Wu-Palmer 提出的最短路径
lch_similarity(sense1,sense2) # Leacock Chodorow 最短路径加上类别信息
2.1.2 基于互信息的方法
res_similarity(sense1, sense2, brown_ic) # -log P(LCS(c1,c2))
jcn_similarity(sense1, sense2, brown_ic) # 1/(IC(s1) + IC(s2) - 2 * IC(lcs))
lin_similarity(sense1, sense2, semcor_ic) # 2 * IC(lcs) / (IC(s1) + IC(s2))
执行:>>python wordSimByWordNet.py
2.2. 基于语料(Wikipedia)统计的词汇相似度计算
主要思想:利用英文维基百科语料库训练得到word-embedding(词向量),然后计算词汇相似度,分别采用了Word2vec和LDA训练得到词汇向量。
具体方法如下:
(1)获取英文wikipedia数据(压缩后的12G):
>> wget http://download.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz
(2)解压缩wikipedia数据(解压缩后53G),并利用WikiExtractor(Python 写的一个维基百科抽取器)抽取文本内容。
>>bunzip2 enwiki-latest-pages-articles.xml.bz
>>python WikiExtractor.py –cb 1000M -o extracted enwiki-latest-pages-articles.xml
参数 -b1000M 表示以 1000M 为单位切分文件,默认是 1M。
(3)提取文本内容
>> WikiExtractor.py -cb 250K -o extracted enwiki-latest-pages-articles.xml.bz
(4)解压后将文本内容合并到一个文件中(合并后17G)
>>bash mergeWikiCorpus.sh
考虑到语料库太大,实验资源有限,随机抽取了2.4G文本内容(mergeData.txt)作为最终的语料库。
2.2.1 基于 Word2vec 得到词汇向量计算词汇相似度
由于语料库中存在部分中文,空行,xml标记等无意义信息,需要对数据进行预处理:去除中文,空行和xml标记等。
>>python word2vectorPreprocess.py
处理完后得到1.6G,6779664条信息,作为word2vec的输入文件:word2vecInput.txt。
资源:Google word2vec https://code.google.com/p/word2vec/
>> word2vecStart.sh
time ./word2vec -train /home/xilian/wordSim/wikiDump/word2vecInput.txt -output /home/xilian/wordSim/wikivectors.txt -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 0 -iter 100
-train word2vecInput.txt 表示的是输入文件,
-output wikivectors.txt 表示输出文件,
-cbow 0表示不使用cbow模型,默认为Skip-Gram模型
-size 200 每个单词的向量维度是200,
-window 8 训练的窗口大小为8就是考虑一个词前8个和后8个词语,
-negative 25 -hs 0使用NEG方法,不使用HS方法,
-sampe指采样的阈值,如果一个词语在训练样本中出现的频率越大,就越会被采样,
-binary为1指的是结果二进制存储,为0是普通存储(词语-对应的向量),
-threads 20 线程数,
-iter 100 表示迭代100次。
除了以上参数,word2vec还有几个参数对我们比较有用比如-alpha设置学习速率,默认的为0.025. –min-count设置最低频率,默认是5,如果一个词语在文档中出现的次数小于5,那么就会丢弃。-classes设置聚类(k-means聚类)个数。
根据得到的wikivectors.txt计算词汇相似度
>>python wordSimByWord2vec.py wikivectors.txt
2.2.2 基于LDA得到词汇向量计算词汇相似度
资源:GibbsLDA++(C++实现) http://gibbslda.sourceforge.net/
>>ldaStart.sh
src/lda -est -alpha 0.25 -beta 0.1 -ntopics 200 -niters 1000 -savestep 500 -twords 30 -dfile /home/xilian/wordSim/wikiDump/ldaInput.txt
-alpha LDA的超参数,默认值为50/K(K为topics个数)
-beta LDA的超参数,默认值为0.1
-ntopics topics个数为200
-niters 迭代次数为1000
-savestep 每迭代500次保存一次
-twords 每个topic下的词汇
-dfile 输入文件位置
根据得到的wikildavectors.txt计算词汇相似度。
>> python wordSimByLda.py wikildavectors.txt
注意:LDA得到的是topic在word上的分布,需要转换得到word在topic的分布,作为word的向量。
2.2.3 基于GoogleNews 语料计算词汇相似度
资源:基于word2vec项目给出的googleNews语料得到词汇向量。
基本方法:调用gensim的Word2vec 模型,利用googleNews向量得到词汇向量模型,进而计算词汇相似度。
Word2vecModel = Word2Vec.load_word2vec_format('GoogleNews-vectors-negative300.bin', binary=True)
>> python wordSimByGoogleNews.py
2.3 基于检索页面数量计算词汇相似度
基本方法:根据google搜索返回的页面数量,利用WebJaccard计算相似度:
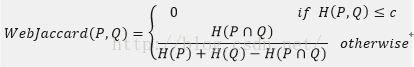
>> python wordSimByGoogleSearch.py
3. 结果评价
3.1 实验结果
Table1:Spearman’s rank correlation coefficient at different datasets
| method |
set1 |
set2 |
combined |
|
| 1-WordNet |
Path |
0.326779 |
0.241554 |
0.29944 |
| Wu palmer |
0.362558 |
0.259056 |
0.333324 |
|
| L&C |
0.330725 |
0.240651 |
0.301192 |
|
| Resnik |
0.378036 |
0.235003 |
0.331832 |
|
| J&C |
0.364753 |
0.15869 |
0.283424 |
|
| Lin |
0.273019 |
0.129281 |
0.21594 |
|
| Word2vecModel |
2-GoogleNews |
0.665139 |
0.658315 |
0.700017 |
| Wiki corpus |
3-Word2vec |
0.599437 |
0.594213 |
0.610703 |
| 4-LDA |
0.658085 |
0.450128 |
0.550376 |
|
| Search Result |
5-GoogleSearch |
0.268631 |
0.04014 |
0.140247 |
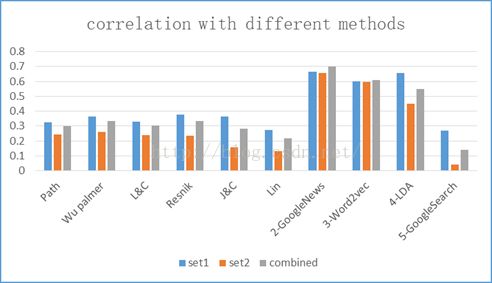
Graph 1:Spearman’s rank correlation coefficient at different datasets
3.2 结果分析
基于WordNet语义关系计算词汇相似度的方法比较简单, 可以利用词汇的同义词关系、语义解释、例句等信息。但存在一些缺点,(1)有些词不被语义词典所包含:实体、新词等。(2)大部分方法依赖于上下位层次关系:限于名词,对于形容词和动词并不完善。(3)不同词性的词处于不同层次结构中,不能计算相似度。
基于语料统计计算词汇相似度的方法比较多,本文尝试了Word2vec,LDA,GoogleNews三种方法,从图1可以看到,基于语料统计的方法的计算结果明显高于基于语义词典的方法。Word2vec计算结果相关系数接近60%,GoogleNews模型在65%~70%之间,是因为考虑到计算复杂性问题,Word2vec只选取了1.6G作为训练数据,而GoogleNews模型利用了更多的语料信息,所以后者结果高于前者。LDA的最高结果达到了65%,假如利用更多的语料信息训练,Word2vec和LDA的结果都可能提高。
最后一种方案基于google检索结果计算词汇相似度,最高只有26%的相关系数。这种方法显得有点简单粗暴,没有考虑到词汇之间的层次关系和语义关系,导致结果比较低。
另外,还考虑可以利用频繁模式挖掘fpgrowth和SVM方法,fpgrowth统计所有的二项集,基于共现频率计算相似度;二分类SVM可将wordnet词典中的同义词当做正类,非同义词当做负类,进行训练。实验未完成,所以报告里省略了。
相关代码之后会发布在博客中