2017CS231n李飞飞深度视觉识别笔记(十)——循环神经网络
第十讲 循环神经网络
课时1 RNN,LSTM,GRU
上一章中讨论了CNN的架构有关内容,这一节中将讨论有关RNN的内容。
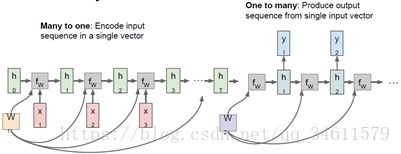
在之前的学习中,提到了一种称为vanilla的前馈网络,所有网络架构都有这种基础架构,会接收一些输入,输入是固定尺寸的对象,比如一幅图片或一片向量,它在通过一些隐藏层后给出单一的输出结果,比如一个分类;但是在机器学习中,有时候希望有更加灵活的机器能够处理的数据类型,所以这时候RNN就有了很大的发挥空间,用RNN来处理各种类型的输入和输出数据,一旦使用RNN,就可以实现1对多模型、多对1,模型以及多对多模型。
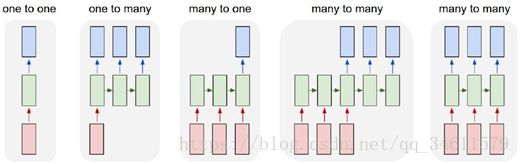
因此,RNN非常重要,即使对有固定输入大小和固定输出大小的问题,RNN也同样很有用,例如想要对输入进行序列化处理,收到了一个固定大小的输入,如一幅图像,要做出分类决策,即图像中的数字是多少,这里将不是做单一的前向传播,而是看看图片,观察图片的各种不同部分,然后在完成一组观察后作出最终决策。
总体而言,每个RNN网络都有一个小小的循环核心单元,它把x作为输入,将其传入RNN,RNN有一个内部隐藏态,这一隐藏态会在RNN每次读取新的输入时更新,然后当模型下一次读取输入时,这一内部隐藏态会将结果反馈至模型。
这个循环过程的计算公式:在RNN模块中对某种循环关系用f函数进行了计算,这一f函数依赖权重W,它接收隐藏态![]() 和当前态
和当前态![]() ,然后会输出下一个隐藏态或者更新后的隐藏态,称为
,然后会输出下一个隐藏态或者更新后的隐藏态,称为![]() 。
。
![]()
当读取下一个输入时,这个新的隐藏态![]() 将作为输入传入同一个函数,同时读取下一个输入
将作为输入传入同一个函数,同时读取下一个输入![]() ,如果想要在网络的每一步产生输出,那么可以增加全连接层,每一步将
,如果想要在网络的每一步产生输出,那么可以增加全连接层,每一步将![]() 作为输入,根据,每一步的隐藏态来做出决策。
作为输入,根据,每一步的隐藏态来做出决策。
![]()
RNN的计算图如下:
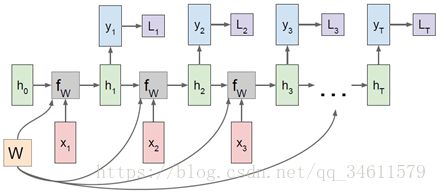
在每个计算步长中,重复使用这相同的权重矩阵,所以看到这个![]() 块每次在接收不同的h和不同的x,但都在使用相同的w权重;如果将反向传播的原理应用到这个模型中,会得到在每一个时步下计算出的梯度,最终的w梯度是所有时步下独立计算出的梯度之和;同样可以直接把
块每次在接收不同的h和不同的x,但都在使用相同的w权重;如果将反向传播的原理应用到这个模型中,会得到在每一个时步下计算出的梯度,最终的w梯度是所有时步下独立计算出的梯度之和;同样可以直接把![]() 写在计算图上,这样每个计算步长下输出的
写在计算图上,这样每个计算步长下输出的![]() 重新作为输入给之后的神经网络输出该时步下的
重新作为输入给之后的神经网络输出该时步下的![]() ,然后可以计算每个时步对应的损失值,得到每个时步的损失值后将它们加起来得到最终损失。
,然后可以计算每个时步对应的损失值,得到每个时步的损失值后将它们加起来得到最终损失。
课时2 语言模型
下面举一个具体的例子,它会经常被应用到递归神经网络的领域,这个问题就是语言模型。
在语言模型的问题中,我们想要读取一些语句从而让神经网络在一定程度上学会生成自然语言,这在字符水平上是可行的,让模型逐个生成字符,同样可以在单词层面上让模型逐个生成单词。
想象一个字符级的语言模型,网络会读取一串字符序列,然后需要去预测这个文本流的下一个字符是什么,在这里有很小的字符表helo以及训练序列样例 “hello”,在这个语言模型的训练阶段,将这个字符序列作为输入项,考虑每个输入实例是一个字母,所以要想办法在神经网络中表示这些字母,找出在神经网络中整个单词的表示方式,这个例子中的表示方式如下:
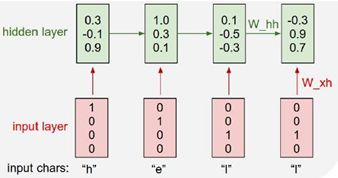
然后随着网络的前向传播,该输入进入一个RNN单元内,之后输出,即网路对组成单词的每个字母的预测,也就是认为接下来最可能出现的字母。
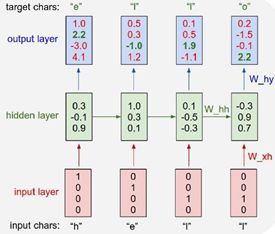
不断重复上述的过程,如果用不同的字母序列去训练这个模型,最终它会学习如何基于之前出现过的字符来预测接下来出现的字符。
考虑模型在之后的测试阶段会发生什么,我们可能会用该模型测试一下样本,并使用这个训练好的神经网络模型去生成新的文本;采用的方法是通过输入一些文本的前缀来测试这个模型,在这个实例中,这些前缀只是一个字母h,在递归神经网络的第一步输入字母h,它会产生一个基于词库中所有的字母得分的分布,在训练阶段,使用这些得分去输出一个结果,所以使用一个softmax函数,把这些得分转换为一个概率分布,然后从这些概率分布中得到样本输出去生成序列中的第二个字母。
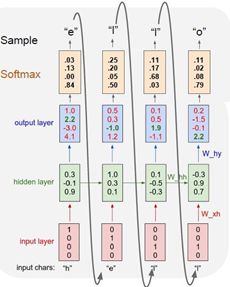
在实际的反向传播过程中,通常采用一种近似方法,称之为沿时间截断反向传播方法,这个方法的思想是即使输入序列很长,甚至趋近于无限,采用的方法是在训练模型时前向计算若干步,也就是会计算机若干子序列的损失值,然后沿着这个子序列反向传播误差,并计算梯度更新参数,重复此过程;
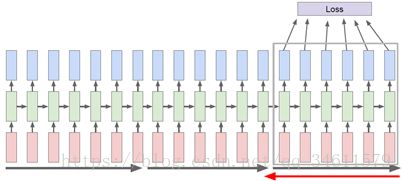
沿时间截断反向传播方法是一种近似估计梯度的方法,这种方法不用反向传播遍历本来非常长的序列。
这里有一个实例:https://gist.github.com/karpathy/d4dee566867f8291f086。
课时3 图像标注
在之前的学习内容中多次提到了图像标注模型,想训练一个模型用来输入一个图像,然后输出自然语言的图像语义信息。
这里的输出语义信息可能是可变长度的字符序列,可能不同的标签有不同的字母数量,所以这很适用于RNN模型,因为模型看上去有一部分卷积网络用来处理输入的图像信息,还有很多这个位置工作的卷积神经网络,它们将产生图像的特征向量,然后输入到接下来的循环神经网络语言模型的第一个时序。
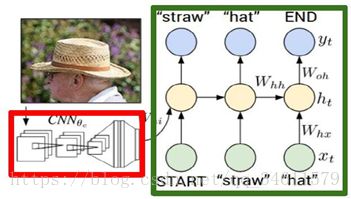
这是之前看到过的字符级语言模型,把图像输入通过卷积神经网络,用末尾的4096维的向量作为第一个初始化输入,得到词汇表中的所有分数的分布,从分布中采样并在下一次时间步时当作输入传回,最后就能生成完整的句子。
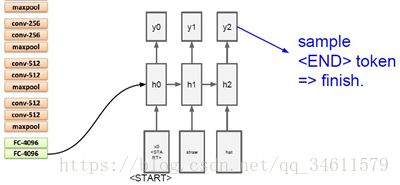
经过这些训练之后,可以得到很好的结果,如下:

接下来将讨论一个稍微高级的模型:注意力模型。
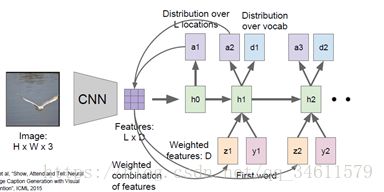
通常的方式是相比于产生一个单独的向量来整合整个图像,卷及网络倾向于产生由向量构成的网络,即可能从每个图片中特殊的地方都用一个向量表示,当把这个模型向前运行时,除了在每一步中采样,也会产生一个分布,即在图像中它想要看的位置,图像位置的分布可以看成是一种模型在训练过程中应该关注哪里的张量;第一个隐藏状态计算在图片位置上的分布,它将会回到向量集合,给出一个概要矢量,这可能会把注意力集中在图像的一部分上;现在这个概要向量得到了反馈作为神经网络下一时间步的额外输入,将会产生两个输出:一个是词汇表上的分布;一个是图像位置的分布;整个过程重复继续下去:
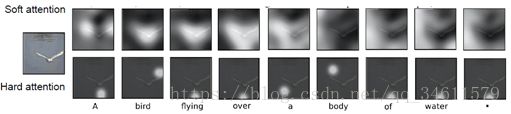
当训练完模型后,可以看到它会在图像中转移注意力,在生成每个图片标题的单词时,可以看到它生成标题:A bird flying over a body of water.但是可以看到它的注意力在图片中的不同地方变换。
课时4 视觉问答
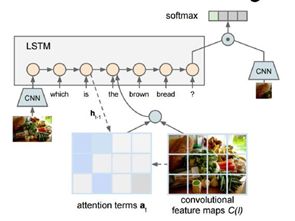
模型准备将两个东西输入:图像和输入自然语言描述的问题;如下图:

可以将这个认为是CNN和RNN连接起来得到的模型,模型需要将自然语言序列作为输入;可以设想针对输入问题的每个元素建立递归神经网络,从而将输入的问题概括为一个向量,然后可以用CNN将图像也概括(为一个向量),现在CNN把得出的向量和输入问题的向量结合,通过RNN编程预测答案的概率分布,有时候会把soft attention也结合到视觉问答之中。
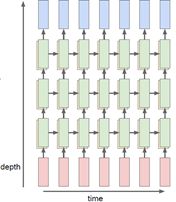
目前为止,讨论的单层递归神经网络只有一种隐藏状态,另一种经常会见到的是多层递归神经网络,如下图中的3层循环神经网络结构:
下面给出了Vanilla的基本函数形式:
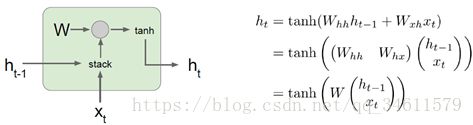
当尝试计算梯度时,反向传播在这个结构中如何进行,在反向传播过程中,会得到![]() 的导数以及关于
的导数以及关于![]() 的损失函数的导数,在反向传播通过这个单元时,需要计算关于
的损失函数的导数,在反向传播通过这个单元时,需要计算关于![]() 的损失函数导数:
的损失函数导数:
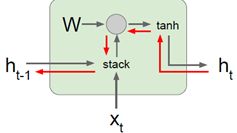
意味着经过其中一个Vanilla递归神经网络单元时,实际是和部分权重矩阵相乘,可以设想把许多递归神经网络单元连接成一个序列。梯度流穿过一系列这样的层会发生什么呢?

当要计算关于![]() 的损失函数的梯度时,反向传播需要经过递归神经网络的每一个单元,每次反向传播经过一个单元时都要使用其中某一个W的转置,这意味着最终的表达式对
的损失函数的梯度时,反向传播需要经过递归神经网络的每一个单元,每次反向传播经过一个单元时都要使用其中某一个W的转置,这意味着最终的表达式对![]() 的梯度的表达式将会包含很多权重矩阵因子。
的梯度的表达式将会包含很多权重矩阵因子。
这里有一个常用的方法来解决梯度爆炸的问题,称为梯度截断;在计算梯度后,如果梯度L2范式大于某个阈值,就将它剪断并做除法,这样梯度就有最大阈值;

而对于梯度消失的问题,常用的方法是改变为更加复杂的RNN结构;
这也就是使用LSTM的原因,即长短期记忆网络;它是递归神经网络的一种更高级的递归结构,LSTM常被设计用来缓解梯度消失和梯度爆炸的问题。
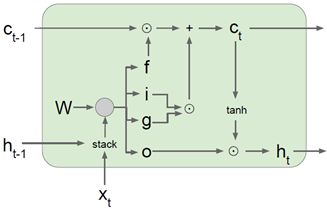
LSTM的函数形式如下:

之前提到的vanilla递归神经网络,它具备隐藏状态,在每个时间步中,利用递归关系来更新隐藏状态;现在考虑LSTM,在每个时间步中都维持两个隐藏状态:一个是![]() ,另一个是
,另一个是![]() 叫做单元状态,这个叫单元状态的向量相当于保留在LSTM内部的隐藏状态并且不会完全暴露到外部去。
叫做单元状态,这个叫单元状态的向量相当于保留在LSTM内部的隐藏状态并且不会完全暴露到外部去。
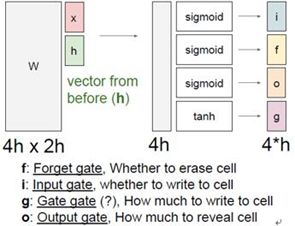
在LSTM中第一件事就是给定前一时刻的隐藏状态![]() 和当前时刻的输入向量
和当前时刻的输入向量![]() ,然后拿上一时间步的隐藏状态和当前的输入堆叠在一起,然后乘上一个非常大的权重矩阵W,计算得到4个不同的门向量,可以注意到4个门都用了不同的非线性函数。
,然后拿上一时间步的隐藏状态和当前的输入堆叠在一起,然后乘上一个非常大的权重矩阵W,计算得到4个不同的门向量,可以注意到4个门都用了不同的非线性函数。
LSTM的示意图如下:
使用LSTM进行反向传播时,通过单元状态的路径是一种梯度高速公路,它使梯度相对畅通无阻地从模型的末端的损失函数返回到模型最开始的初始单元状态。
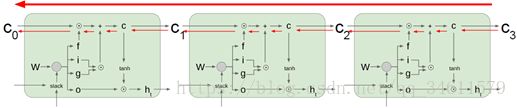
因此会发现LSTM实际上跟残差网络非常相似,在残差网路中有一条反向穿过网络的身份认证链接路径,它为梯度反向传播提供了一条高速公路:

在自然环境中还会看见许多循环神经网络结构的其他类型的变化,比如GRU称之为门控循环单元,MUT等;
总结:
循环神经网络可以帮助解决大量新的问题,它们有时候容易受到梯度消失或者梯度爆炸的影响,但是可以通过权重裁剪和精妙的网络结构来解决;在神经网络和循环神经网络之间有很多重叠的部分,有助于更好的理解。