LruCache 源码解析
文章结构
- 一、概述
- 二、LruCache 的基本使用
- 1. 初始化
- 2. 读/写缓存
- 3. LruCache 的其他方法
- create
- entryRemoved
- 三、LruCache 的源码分析
- 1. LruCache 的成员
- 2. LruCache 的构造方法
- 3. LruCache#put
- 4. LruCache#get
- 四、LruCache 的总结
一、概述
LruCache 是一种内存缓存算法,全称为 Least Recently Used,即近期最少使用算法。当我们需要对一些数据进行缓存以便下次进行展示时,我们就可以考虑使用该类进行相关数据的缓存。它比较普遍的使用场景是对从网络中下载下来的图片进行缓存,一来可以节省再次加载时的网络资源消耗,二来可以提高再次加载时的速度,可见它还是非常有用的。
接下来看看 Google 官方对它的描述:
A cache that holds strong references to a limited number of values. Each time a value is accessed, it is moved to the head of a queue. When a value is added to a full cache, the value at the end of that queue is evicted and may become eligible for garbage collection.
这段话翻译过来可以分解成如下几点:
- 它是一个持有强引用类型的缓存。
- 每当访问缓存的值时,被访问值就会移动到缓存队列的头部。
- 当缓存队列存满时,它就会将队列尾部,也就是最不常被访问的值踢出去,以便保存新值。
而对于该算法的实现,其实没有想象中的那么复杂,这要归功于 LinkedHashMap,其实 LruCache 内部就是维护了一个 LinkedHashMap 的成员,通过对 LinkedHashMap 的操作,可以很简单地实现近期最少使用算法。接下来,笔者会对 LruCache 的使用进行举例,然后再对源码进行分析。
二、LruCache 的基本使用
LruCache 的使用可简单地分为如下 3 部分:
- 初始化
- 读/写缓存
1. 初始化
初始化的代码如下所示:
LruCache<String, Bitmap> lruCache = new LruCache<String, Bitmap>(10 * 1024 * 1024){
@Override
protected int sizeOf(String key, Bitmap value) {
return value.getByteCount();
}
};
我们在概述中说过 LruCache 在内部维护了一个 LinkedHashMap,所以它也是以键值对的形式来存储值的。在这里我们以缓存图片为例,键我们指定为 String 类型,而值我们就指定为 Bitmap 类型。
然后看到构造方法的参数,我们这里传入的是 10*1024*1024,这个参数表示的是缓存的最大值,我们这里以 byte 作为单位,所以传入 10*1024*1024 也就表示我们的缓存最大为 10Mb。
需要注意一点的是 LruCache 内部实际上没有指定缓存的单位,我们可以自己进行任意的定义,甚至可以使用个数来作为缓存单位,当然推荐还是使用实际占用的大小作为缓存值的参考。
还有一点,我们这里使用的是匿名内部类的方式初始化 lruCache,我们重写了 sizeOf 方法,这个方法用于返回每个缓存值的大小以便 LruCache 内部的缓存计算,所以这里我们直接返回的就是 Bitmap#getByteCount,返回该 Bitmap 对象的字节数,这个方法不重写的话默认返回值为 1。
2. 读/写缓存
在初始化完 LruCache 对象之后,我们就可以进行写缓存的操作了。它的操作非常简单,如下所示:
lruCache.put("test.png", bitmap);
可以看到通过 LruCache#put 方法,就可以完成对一个 Bitmap 对象的缓存,它的 key 值为 "test.png"。
在缓存了我们想要缓存的 Bitmap 数据之后,在合适的时候,我们就可以通过读缓存将缓存值读取出来,它的代码也很简单:
Bitmap bitmap = lruCache.get("test.png");
通过 LruCache#get 方法,传入对应的 key 值,就可以读到我们之前的缓存了,要注意 key 值不能为空,并且在取得 Bitmap 的值之后应当进行非空判断才能使用,因为 get 方法有可能会返回 null。
3. LruCache 的其他方法
我们在初始化 LruCache 对象的时候除了重写 sizeOf 方法之外,我们还可以重写下面 2 个方法:
create
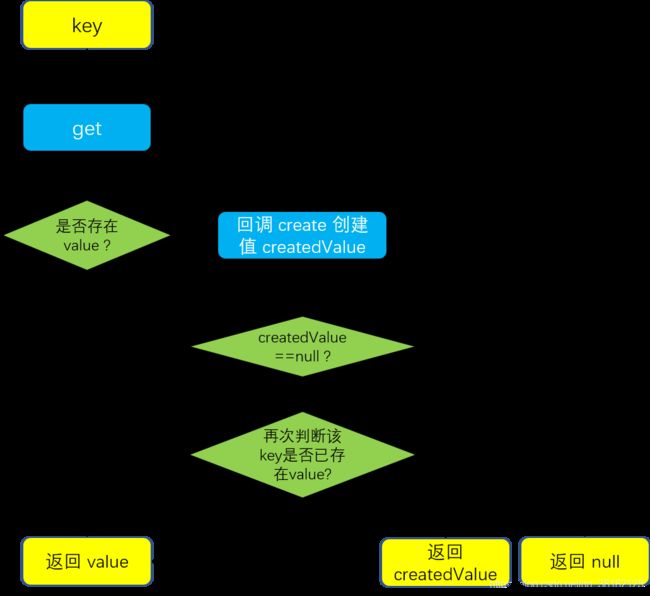
这个方法默认的返回值是 null,它是在 get 方法内部被调用的,如果在 LruCache 内部没有 get 方法传入的 key 所对应的值时,就会通过回调 create 方法来创建该 key 的值 createdValue,需要注意的是如果此时该 key 值在 create 创建完该值之前恰好通过 put 方法缓存入了一个该 key 的新值,那么 createdValue 就会和这个新值发生冲突,这时候的决策是放弃 create 方法产生的值。
它的回调流程可如下图所示:
entryRemoved
这个方法默认是个空实现方法,它的实现如下所示:
protected void entryRemoved(boolean evicted, K key, V oldValue, V newValue) {}
- 第一个参数
evicted是一个标志位,为true表示该缓存值要被移除,为false表示该缓存值要被替换。 - 第二个参数表示的是要替换或者移除的
key值。 - 第三个参数表示的是要替换或者移除的缓存值。
- 第四个参数表示的是要替换的新值,这个参数只有在
evicted为false时才不为空。
在官方的解释中,它被重写的理由如下:
If your cached values hold resources that need to be explicitly released, override {@link #entryRemoved}.
即如果缓存值中所持有的资源如果很明确地需要被释放掉,那么我们就可以重写该方法。它会在如下场景中被回调:
-
在调用
LruCache#put缓存一个新值时,如果该key已经存在于缓存队列中的话,就会回调该方法,回调传入的值为entryRemoved(flase, key, oldValue, newValue)。 -
在回调
create方法产生一个新值时,如果create所产生的值createdValue所对应的key已经存在于缓存队列中了,也会回调该方法,回调传入的值为entryRemoved(false, key, createdValue, mapValue)。 -
当对缓存区由于缓存已满进行清理的时候,也会回调该方法,此时传入的值是
entryRemoved( true, key, value, null),其中key和value代表被移除的键值对。 -
当我们调用
LruCache#remove移除某个键值对时,只要该键值对的值不为空,就会回调该方法,此时传入的值是:entryRemoved(false, key, previous, null)。
在讲解完了 LruCache 的基本使用之后,接下来我们就从源码的角度来分析 LruCache 的实现。
三、LruCache 的源码分析
源码分析的步骤笔者是按照 LruCache 的使用进行展开的,按照如下进行分析:
LruCache的成员LruCache的构造方法LruCache#put方法LruCache#get方法
1. LruCache 的成员
LruCache 的成员如下代码所示:
public class LruCache<K, V> {
private final LinkedHashMap<K, V> map; // 缓存键值对的 map
/** Size of this cache in units. Not necessarily the number of elements. */
private int size; // 已缓存的大小
private int maxSize; // 最大缓存值
private int putCount; // put 方法调用次数
private int createCount; // 通过 create 方法产生的缓存值数量
private int evictionCount; // 由于缓存溢出时移除的缓存数量
private int hitCount; // 查找缓存时的命中次数
private int missCount; // 查找缓存时的未命中次数
......
}
这些成员的功能通过上面的注释我们就能知道的一清二楚了,我们只需重点关注前 3 个成员:map 它是用于缓存我们的键值对的,它是 LruCache 的关键;size 用于记录当前缓存的大小;而 maxSize 是最大缓存值,它的值在构造方法中传入。
在这里我们要弄清楚一个问题,为什么 LruCache 要选用 LinkedHashMap 进行键值对的存储?
这是由 LinkedHashMap 的特性所决定的。我们都知道,LinkedHashMap 有两种存值的顺序,第一种是插入顺序,第二种则是访问顺序。它的存值方式可以在初始化时通过构造方法进行设置:
LinkedHashMap<String, Bitmap> map = new LinkedHashMap<String, Bitmap>(0, 0.75f, true);
看到这个初始化的代码,LinkedHashMap 构造方法的 3 个参数含义如下:
- initialCapacity:初始化容量,即
Map的初始大小。 - loadFactor:负载因子。
- accessOrder:这是个标志位,表示是否按访问顺序进行迭代。
在前面的时候我们介绍过 LruCache 算法是近期最少使用算法,即最近使用过的缓存就会优先放置在缓存队列的头部,而最近最少使用的缓存则放置在尾部。所以根据这个需求,我们很明显能感受出来 LruCache 对 LinkedHashMap 应当是使用基于访问顺序的。
2. LruCache 的构造方法
接下来我们就来看看 LruCache 的唯一构造方法里面做了什么:
public LruCache(int maxSize) {
if (maxSize <= 0) {
throw new IllegalArgumentException("maxSize <= 0");
}
this.maxSize = maxSize;
this.map = new LinkedHashMap<K, V>(0, 0.75f, true);
}
可以看到它的构造方法所做的事非常简单,首先会对 maxSize 的值进行判断,小于等于 0 则会抛出异常。接下来会将该值赋值给成员 maxSize,然后对 map 进行初始化,可以看到,它的初始化正如我们前面所说的,是基于访问顺序迭代的 LinkedHashMap。
分析完构造方法之后,我们接下来继续分析 put 方法。
3. LruCache#put
put 方法的实现如下所示:
public final V put(K key, V value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
size += safeSizeOf(key, value);
previous = map.put(key, value);
if (previous != null) {
size -= safeSizeOf(key, previous);
}
}
if (previous != null) {
entryRemoved(false, key, previous, value);
}
trimToSize(maxSize);
return previous;
}
可以看到 put 方法的 key 和 value 均不能为空,否则会抛出异常。
接下来在同步块中,第 9 行,首先计算当前的缓存大小,调用的是 size 加上 safeSizeOf 方法的返回值,我们都知道 size 表示的就是当前的缓存大小,那么 safeSizeOf 方法里面做了什么呢,我们进去看看:
private int safeSizeOf(K key, V value) {
int result = sizeOf(key, value);
if (result < 0) {
throw new IllegalStateException("Negative size: " + key + "=" + value);
}
return result;
}
关键看到第 2 行,通过调用 sizeOf 方法进行计算,而 sizeOf 方法正是我们在初始化 LruCache 实例时重写的那个方法,用于计算每个缓存值的大小,如果这个方法不重写,默认返回值为 1。
继续回到 put 方法中的第 10 行,调用 LinkedHashMap#put 方法进行存值,并用 previous 接收这个方法的返回值用于判断这个 key 在 map 中是否是存在的,如果 previous 不为空的话,证明 key 之前在 map 中是存在的,所以此时 put 做的是一个 value 的替换,size 还需要减掉之前 previous 占有的部分。
第 16 行,如果 previous 不为空的话,就会回调 entryRemoved 方法,这个方法我们之前讲过是个空实现。
紧接着在第 20 行,调用了 trimToSize 方法,这个方法是用于对于缓存进行调整的,实现如下:
public void trimToSize(int maxSize) {
while (true) {
K key;
V value;
synchronized (this) {
if (size < 0 || (map.isEmpty() && size != 0)) {
throw new IllegalStateException(getClass().getName()
+ ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize) {
break;
}
Map.Entry<K, V> toEvict = map.eldest();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= safeSizeOf(key, value);
evictionCount++;
}
entryRemoved(true, key, value, null);
}
}
这个方法做的主要工作就是将 size 和 maxSize 的值进行比较,如果 size > maxSize,说明需要进行缓存的清理,那么它就会在一个 while 中不断地调用 LinkedHashMap#eldest 方法取出最近最不常被访问到的缓存,然后通过 LinkedHashMap#remove 方法移除,直到 size <= maxSize,才会跳出这个循环。每个被清理的缓存都会调用 entryRemoved 方法进行通知。
分析完了 trimToSize 方法的功能之后,我们继续回到 put 方法,最后就是返回 previous 的值了。
总结一下 put 方法:
put方法的key和value均不能为空,为空会抛出异常。- 键值对的保存实际上是通过调用
LinkedHashMap#put方法保存到map中,保存的时候会检查是否key已经存在于map中了,如果不存在直接插入,存在的话就会进行值的替换,然后进行当前缓存大小的计算。 - 缓存大小的计算借助于
size和safeSizeOf方法,而safeSizeOf方法内部实际调用了sizeOf方法,这个方法是我们在外部进行重写的方法。 - 在插入值之后,最后 put 方法会调用
trimToSize方法进行缓存的调整,这个方法内部会一直移除最近不常使用的缓存值直到当前的缓存大小小于等于最大缓存大小。
分析完了 put 方法,接下来我们来分析 get 方法。
4. LruCache#get
get 方法的实现如下:
public final V get(K key) {
if (key == null) {
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
mapValue = map.get(key);
if (mapValue != null) {
hitCount++;
return mapValue;
}
missCount++;
}
V createdValue = create(key);
if (createdValue == null) {
return null;
}
synchronized (this) {
createCount++;
mapValue = map.put(key, createdValue);
if (mapValue != null) {
// There was a conflict so undo that last put
map.put(key, mapValue);
} else {
size += safeSizeOf(key, createdValue);
}
}
if (mapValue != null) {
entryRemoved(false, key, createdValue, mapValue);
return mapValue;
} else {
trimToSize(maxSize);
return createdValue;
}
}
第 2 行,key 值不能为空,否则就会抛出异常。
第 8 行,在同步块中,通过 LinkedHashMap#get 方法获取 key 对应的 value,如果 value 值不为空的话,直接返回;如果为空的话,就会在第 16 行通过调用 create 方法进行对 createdValue 的赋值,这个方法的返回值默认为空,我们可以在子类中重写这个方法。
第 17 行,如果 createdValue 的值也为 null 的话,就直接返回 null,否则的话第 23 行,在这个同步块中,我们会通过 LinkedHashMap#put 方法将 key-createdValue 这个键值对存入 map 中,在这里我们还通过 mapValue 来接收 LinkedHashMap#put 方法的返回值。
第 25 行,这个 if 有必要特别说明一下,这个 if 主要是用于判断此时该 key 是否已经存在 value 了,因为在我们通过 create 方法给 createdValue 赋值的时候有可能在其它线程中调用了 put 方法对这个 key 所在的键值对进行了存储,所以在这里的判断就是为了防止这种情况的出现。如果此时 key 已存在 value 的话,就重新调用 LinkedHashMap#put 方法将 key-value 值存储起来,抛弃 createdValue。
第 33 行,如果 mapValue 不为空的话,就会调用 entryRemoved 方法,然后返回 mapValue 的值,否则的话就会通过 trimToSize 对缓存进行调整,然后返回 createdValue 的值。
get 方法可以通过我们前面的一张图进行总结:
至此,我们对于 LruCache 的使用以及源码的解析就分析完了,当然 LruCache 里面还有一些方法如 remove 我们还没有分析,不过它的实现并不复杂,相信大家对余下的代码分析是完全 OK 的,接下来我们就来对 LruCache 做一个简单的总结。
四、LruCache 的总结
LruCache全称 Least Recently Used,即最近最少使用算法。LruCache构造方法传入的是最大缓存的大小,我们可以选择是否对它的sizeOf方法进行重写,推荐重写。LruCache其实就是通过内部维护一个LinkedHashMap进行缓存的维护,将LinkedHashMap初始化为访问顺序迭代的方式,从而很容易地实现了最近最少使用的思想。LruCache的put/get方法实际上就是调用了LinkedHashMap对象的put/get方法,只不过在方法内部还做了些额外的工作,例如在put方法最后会调用trimToSize进行缓存的调整,而get方法则是会在得到的value为空时尝试通过create方法进行赋值,这个方法的默认实现为空,可在子类中重写。
希望本篇文章对你有所帮助~
有问题可以在下方给我留言,感谢观看!