SuperGlue:Learning Feature Matching with Graph Neural Networks 解读与实验
说明
- 本文基于vincentqin对SuperGlue的翻译博客,做了一些补充整理,并在响应章节贴了对应的代码。
- 由于SuperGlue是做特征匹配的,所以可以用来做一个简单的frame-by-frame的VO,我基于SuperGlue实现了一个简单的VO,对比了传统的ORB,SIFT特征,以及暴力匹配和FLANN匹配方法,请参考https://github.com/Shiaoming/Python-VO。
CVPR 2020 Oral,效果太好了
摘要
- 提出了一种能够同时进行特征匹配以及滤除外点的网络;
- 特征匹配是通过求解可微分最优化转移问题( optimal transport problem)来解决,损失函数由GNN来构建;
- 基于注意力机制提出了一种灵活的内容聚合机制,这使得SuperGlue能够同时感知潜在的3D场景以及进行特征匹配。
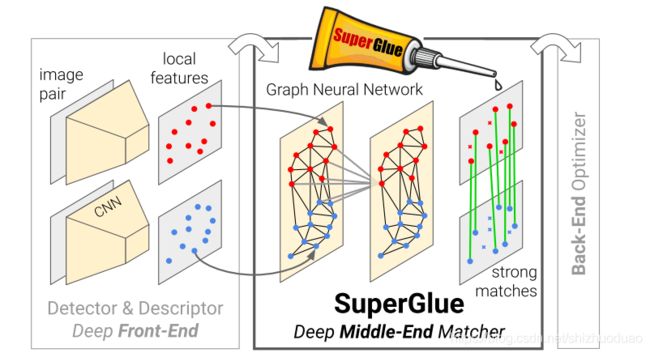
相关工作
局部特征匹配
传统的特征可分5步走:
- 提取特征点;
- 计算描述子;
- 最近邻匹配;
- 滤除外点(计算最优次优比,RANSAC,交叉验证以及neighborhood consensus);
- 求解几何约束;
最近的一些工作主要集中在设计特异性更好的稀疏特征上,而它们的匹配算法仍然依赖于NN等策略:在做匹配时并没有考虑特征的结构相似性以及外观相似性。
图像视角变化较小时可以使用光流法跟踪(如:Kimera VIO)。
图匹配
这类方法将特征的匹配问题描述成“quadratic assignment problems”,这是一个NP-hard问题,求解这类问题需要复杂不切实际的算子。后来的研究者将这个问题化简成“linear assignment problems”,但仅仅用了一个浅层模型,相比之下SuperGlue利用深度神经网络构建了一种合适的代价进行求解。此处需要说明的是图匹配问题可以认为是一种“optimal transport”问题,它是一种有效但简单的近似解的广义线性分配,即Sinkhorn算法。
图匹配(Graph Matching)试图在两个或多个图(graph)结构之间,建立节点与节点的对应关系。在计算机视觉领域,图匹配算法通常被用于求解多个图像(image)之间,关键点到关键点的匹配关系:

如:Deep Learning of Graph Matching,CVPR 2018
深度点云匹配
点云匹配的目的是通过在元素之间聚集信息来设计置换等价或不变函数。一些算法同等的对待这些元素,还有一些算法主要关注于元素的局部坐标或者特征空间。注意力机制可以通过关注特定的元素和属性来实现全局以及依赖于数据的局部聚合,因而更加全面和灵活。SuperGlue借鉴了这种注意力机制。
框架(The SuperGlue Architecture)
Motivation
特征匹配必须满足的硬性要求是:
- 至多有1个匹配点;(约束1)
- 有些点由于遮挡等原因并没有匹配点。(约束2)
一个成熟的特征匹配模型应该做到:
既能够找到特征之间的正确匹配,又可以鉴别错误匹配。
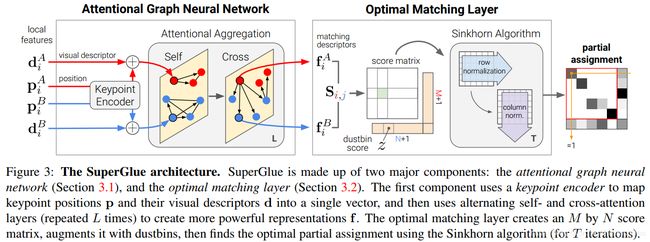
整个框架由两个主要模块组成:注意力GNN以及最优匹配层。
- 注意力GNN,将特征点以及描述子编码成为一个向量(该向量可以理解为特征匹配向量),随后利用自我注意力以及交叉注意力来回增强(重复 L L L次)这个向量 f f f的特征匹配性能;
- 最优匹配层,通过计算特征匹配向量的内积得到匹配度得分矩阵,然后通过Sinkhorn算法(迭代 T T T次)解算出最优特征分配矩阵。
Formulation
-
两张图片 A A A, B B B;
-
每张图片上都有特征点位置 p p p 以及对应的描述子 d d d,用 ( p , d ) (p,d) (p,d) 来表示图像特征;
-
第 i i i 个特征可以表示为 p i : = ( x , y , c ) p_i:=(x,y,c) pi:=(x,y,c),
其中: c c c 表示特征点提取置信度; ( x , y ) (x,y) (x,y) 表示特征坐标;描述子可以表示为 d i ∈ R D d_i \in R^D di∈RD,其中 D D D 表示特征维度,这里的特征可以是CNN特征,如SuperPoint,或者是传统特征SIFT。假设图像 A A A, B B B 分别有 M M M, N N N个特征,可以表示为 A : = 1 , … , M A:={1,…,M} A:=1,…,M 以及 B : = 1 , … , N B:={1,…,N} B:=1,…,N。
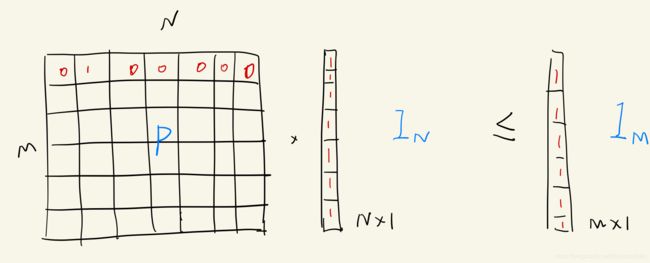
Partial Assignment
约束1和2 意味着对应关系来自两组关键点之间的部分分配(partial assignment,即只有一部分关键点匹做了匹配,其余的没有匹配)。我们给出一个软分配矩阵(soft assignment matrix) P ∈ [ 0 , 1 ] M × N \bold P\in[0,1]^{M\times N} P∈[0,1]M×N,根据上述约束,有如下关系:
设计网络的目标就是从两个局部特征集合预测这个矩阵 P \bold P P。
上面的公式表示矩阵 P \bold P P 每行和每列至多只有一个1,即每行和每列最多只有一个匹配。
Attentional Graph Neural Network
除了 keypoints 的位置 p p p 和其visual appearance d d d 之外,融合其他 contextual 线索在直觉上可以增加 keypoints 的 distinctiveness。
- 比如可以使用一个 keypoint 和与其共视 keypoints 之间的 spatial 和 visual 的关系(比如:引用一堆文献)。
- 在第二幅图像里的 keypoints 可以帮助解决 ambiguities (通过比较候选匹配,估计相对光度或全局的几何信息等)
这里有个有意思的说法:另外一个具有启发性的观点是人类在寻找匹配点过程是具有参考价值的。想一下人类是怎样进行特征匹配的,人类通过来回浏览两个图像试探性筛选匹配关键点,并进行来回检查(如果不是匹配的特征,观察一下周围有没有匹配的更好的点,直到找到匹配点/或没有匹配)。上述过程人们通过主动寻找上下文来增加特征点特异性,这样可以排除一些具有奇异性的匹配。
本文的核心就是利用基于注意力机制的GNN实现上述过程,即模拟了人类进行特征匹配。
Keypoint Encoder
每个 keypoint i i i 的 intial representation ( 0 ) x i ^{(0)}\bold x_i (0)xi 结合了 visual appearance (即特征描述子 d d d) 和 location(即位置 p p p)。使用MLP将位置 p p p 嵌入到高维空间:
上式实际上是将视觉外观以及特征点位置进行了耦合,这使后续的注意力机制能够充分考虑到特征的外观以及位置相似度。
class KeypointEncoder(nn.Module):
""" Joint encoding of visual appearance and location using MLPs"""
""" feature_dim: 256, layers: [32, 64, 128, 256]"""
def __init__(self, feature_dim, layers):
super().__init__()
self.encoder = MLP([3] + layers + [feature_dim]) # MLP([3, 32, 64, 128, 256, 256])
nn.init.constant_(self.encoder[-1].bias, 0.0)
def forward(self, kpts, scores):
inputs = [kpts.transpose(1, 2), scores.unsqueeze(1)]
return self.encoder(torch.cat(inputs, dim=1))
def MLP(channels: list, do_bn=True):
""" Multi-layer perceptron """
n = len(channels)
layers = []
for i in range(1, n):
layers.append(
nn.Conv1d(channels[i - 1], channels[i], kernel_size=1, bias=True))
if i < (n-1):
if do_bn:
layers.append(nn.BatchNorm1d(channels[i]))
layers.append(nn.ReLU())
return nn.Sequential(*layers)
Multiplex Graph Neural Network
想象有这么一个 graph,它的 nodes 是两幅图像的 keypoints。假设它有两种类型的 undirected edges(multiplex graph):
- Intra-image edges(self edges): ε s e l f \varepsilon_{self} εself,它连接了来自图像内部 keypoint
- Inter-image edges(cross edges): ε c r o s s \varepsilon_{cross} εcross,它连接本图 keypoint i i i 与另外一张图所有 keypoints

使用 message passing fomulation [23,4] 来沿着两种 edges 传递信息。最后,这个 multiplex GNN 从每个节点的高维度状态开始,通过同时合并所有节点所有边的的信息在每层上面计算一个更新的 representation。
设 ( l ) x i A ^{(l)}\bold x_i^A (l)xiA 为图像 A A A 上第 i i i 个元素在第 l l l 层的 intermediate representation。message m ε → i \bold m_{\varepsilon \rightarrow i} mε→i 是所有 keypoints j : ( i , j ) ∈ E {j:(i,j)\in E} j:(i,j)∈E 联合后的结果,其中 ε ∈ { ε s e l f , ε c r o s s } \varepsilon \in \{\varepsilon_{self},\varepsilon_{cross}\} ε∈{εself,εcross}。则,对 A A A 中所有 keypoints i i i 传递更新的残差信息(residual message passing update)为:
其中 [ ⋅ ∣ ∣ ⋅ ] [⋅||⋅] [⋅∣∣⋅] 表示串联操作。同样的,图像 B B B 上所有 keypoints 也按类似的形式更新。
网络层数是固定的 L L L 层,每层有不同的参数,串联起来交替合并 self 和 cross 的 edges。即从 l = 1 l=1 l=1 开始:
- l l l 为奇数: ε = ε s e l f \varepsilon = \varepsilon_{self} ε=εself
- l l l 为偶数: ε = ε c r o s s \varepsilon = \varepsilon_{cross} ε=εcross
这里的self-/cross-attention实际上就是模拟了人类来回浏览匹配的过程,其中self-attention是为了使得特征更加具有匹配特异性,而cross-attention是为了用这些具有特异性的点做图像间特征的相似度比较。
Attentional Aggregation
文章的亮点之一就是将注意力机制用于特征匹配,这到底是如何实现的呢?
注意力机制将 self 以及 cross 信息聚合得到 m ε → i \bold m_{\varepsilon \rightarrow i} mε→i,其中:
- self edge 利用了 self-attention [61]
- cross edge 利用了 cross-attention
类似于数据库检索,想要查询(query) q i \bold q_i qi,基于元素的属性即键(key) k i \bold k_i ki ,检索到了某些元素的值(value) v j \bold v_ j vj。message 可以按照加权平均的方式来计算:

其中注意力权重 α i j \alpha_{ij} αij 是 key-query 的 softmax 相似度, α i j = Softmax j ( q i T k j ) \alpha_{ij}=\text{Softmax}_j(\bold q_i^T \bold k_j) αij=Softmaxj(qiTkj)。
这里的 key,query以及 value 是通过GNN 的features 线性映射得到的。令待查询点特征点 i i i 位于查询图像Q上,所有的源特征点位于图像S上,其中 ( Q , S ) ∈ { A , B } 2 (Q,S)\in\{A,B\}^2 (Q,S)∈{A,B}2,则:
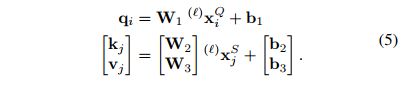
每一层 ℓ ℓ ℓ 都有其对应的一套投影参数,这些参数被所有的keypoints 共享。
最后B 图上 i i i 匹配的特征描述子为:

下图展示了每层self-attention以及across-attention中权重αijαij的结果。按照匹配从难到易,文中画出了3个不同的特征点作为演示,绿色特征点(容易),蓝色特征点(中等)以及红色特征点(困难)。对于self-attention,初始时它(某个特征)关联了图像上所有的点(首行),然后逐渐地关注在与该特征相邻近的特征点(尾行)。同样地,cross-attention主要关注去匹配可能的特征点,随着层的增加,它逐渐减少匹配点集直到收敛。绿色特征点在第9层就已经趋近收敛,而红色特征直到最后才能趋紧收敛(匹配)。可以看到无论是self还是cross,它们关注的区域都会随着网络层深度的增加而逐渐缩小。

einsum参考
################# 此 attention 为全文最重要的创新点
# query: [Batch_size, 64, 4, N0]
# key: [Batch_size, 64, 4, N1]
# value: [Batch_size, 64, 4, N1]
def attention(query, key, value):
dim = query.shape[1]
# q^T * k: [Batch_size, 4, N0, N1]
scores = torch.einsum('bdhn,bdhm->bhnm', query, key) / dim**.5
# softmax(q^T * k): [Batch_size, 4, N0, N1]
prob = torch.nn.functional.softmax(scores, dim=-1)
# 公式(4): return [Batch_size, 64, 4, N0], [Batch_size, 4, N0, N1]
return torch.einsum('bhnm,bdhm->bdhn', prob, value), prob
class MultiHeadedAttention(nn.Module):
""" Multi-head attention to increase model expressivitiy """
# num_heads=4, d_model=256
def __init__(self, num_heads: int, d_model: int):
super().__init__()
assert d_model % num_heads == 0
self.dim = d_model // num_heads #64
self.num_heads = num_heads #4
self.merge = nn.Conv1d(d_model, d_model, kernel_size=1)
# proj: [conv1d, conv1d, conv1d]
self.proj = nn.ModuleList([deepcopy(self.merge) for _ in range(3)])
# query: [Batch_size, 256, N0]
# key: [Batch_size, 256, N1]
# value: [Batch_size, 256, N1]
def forward(self, query, key, value):
batch_dim = query.size(0)
# 公式(5)
# 对query,key,value各自做一个conv1d,然后resize
# query,key,value:[Batch_size, 64, 4, N0/N1]
query, key, value = [l(x).view(batch_dim, self.dim, self.num_heads, -1)
for l, x in zip(self.proj, (query, key, value))]
# softmax及公式(4)
# x: [Batch_size, 64, 4, N0]
# prob: [Batch_size, 4, N0, N1]
x, prob = attention(query, key, value)
self.prob.append(prob)
# return: [Batch_size, 256, N0]
return self.merge(x.contiguous().view(batch_dim, self.dim*self.num_heads, -1))
class AttentionalPropagation(nn.Module):
# feature_dim: 256, num_heads: 4
def __init__(self, feature_dim: int, num_heads: int):
super().__init__()
self.attn = MultiHeadedAttention(num_heads, feature_dim)
# mlp : [512, 512, 256]
self.mlp = MLP([feature_dim*2, feature_dim*2, feature_dim])
nn.init.constant_(self.mlp[-1].bias, 0.0)
# x: [Batch_size, 256, N0]
# source: [Batch_size, 256, N1]
def forward(self, x, source):
# 公式(4):message
message = self.attn(x, source, source) # [Batch_size, 256, N0]
# 公式(3)后半部分:MLP(x||m)
return self.mlp(torch.cat([x, message], dim=1)) # [Batch_size, 256, N0]
class AttentionalGNN(nn.Module):
# feature_dim: 256, layer_names: ['self', 'cross'] * 9
def __init__(self, feature_dim: int, layer_names: list):
super().__init__()
self.layers = nn.ModuleList([
AttentionalPropagation(feature_dim, 4)
for _ in range(len(layer_names))])
self.names = layer_names
# desc0: [Batch_size, 256, N0]
# desc1: [Batch_size, 256, N1]
def forward(self, desc0, desc1):
for layer, name in zip(self.layers, self.names):
layer.attn.prob = []
if name == 'cross':
src0, src1 = desc1, desc0
else: # if name == 'self':
src0, src1 = desc0, desc1
# 公式(3)
# delta0: [Batch_size, 256, N0]
# delta1: [Batch_size, 256, N1]
delta0, delta1 = layer(desc0, src0), layer(desc1, src1)
desc0, desc1 = (desc0 + delta0), (desc1 + delta1)
return desc0, desc1
Optimal matching layer
接下来的任务就是去构建partial assignment matrix P \bold P P。对于一般的graph matching 流程,assignment matrix $\bold P $ 可以通过计算一个 score matrix S ∈ R M × N \bold S \in R ^{M \times N} S∈RM×N来实现。具体而言,可以在公式(1)的约束下,通过最大化总体得分即 ∑ i , j S i , j P i , j \sum_{i,j}\bold S_{i,j} \bold P_{i,j} ∑i,jSi,jPi,j 可得到 $\bold P $。上述过程和求解一个linear assignment problem是等价的。
assignment problem:分配问题
假设有4个工人(workers)a,b,c,d,有4项任务(job)p,q,r,s,每个工人干每一项活的成本都不同(可以理解为不同工人的技术能力不同,薪资待遇也不同),那么便可构造一个代价矩阵(cost matrix) C C C:

……
Score Prediction
去计算 M × N M\times N M×N 个潜在匹配得分是不可取的,于是作者就用GNN得到的 f i A f_i^A fiA 以及 f i B f_i^B fiB 计算相似度(此处使用内积)得到pairwise score:
与 learned 的 visual descriptors 不同的是,这里的 f i A f_i^A fiA 和 f i B f_i^B fiB 没有经过normalize,因为不同的feature 幅度不同,可以反映预测的confidence。
Occlusion and Visibility
将 S S S 扩充一个dustbin 通道,直接把没有匹配的赋值给该通道即可(这样做的作用在于可以滤出错误的匹配点):

图像 A A A 上的keypoint 可以被分配到图像 B B B 上某个keypoint 或者dustbin,每个dustbin 最后有 N(A图像)和M(B图像)个匹配。设 a = [ 1 M T , N ] T \bold a=[\bold 1_M^T,N]^T a=[1MT,N]T, b = [ 1 N T , M ] T \bold b=[\bold 1_N^T,M]^T b=[1NT,M]T,则公式(1)的约束变为:

- 具体实现代码里也有
Sinkhorn Algorithm
求解最大化总体得分可由“Sinkhorn Algorithm”[52,12]进行求解(GPU,differentiable)。
Loss
GNN网络以及optimal matching layer都是可微的,这使得反向传播训练成为可能。网络训练使用了一种监督学习的方式,即有了匹配的真值 M = { ( i , j ) } ⊂ A × B M=\{(i,j)\}\subset A×B M={(i,j)}⊂A×B(如,由真值相对位姿变换得到的匹配关系)。当给定真值标签,就可以去最小化assignment P ˉ \bar{\bold P} Pˉ 的负对数似然函数:

这个监督学习的目标是同时最大化精度以及匹配的召回率。
Comparisons to related work
略
Implementation details
所有inermediate representation (key, query value, descriptors) 的维度都是 D=256。
层数 L=9。
Sinkhorn 迭代次数 T=100。
Pytorch实现。
12M 参数。
NVIDIA GTX 1080: 69ms (15fps)
其余参考原文 Appendix。
def forward(self, data):
"""Run SuperGlue on a pair of keypoints and descriptors"""
desc0, desc1 = data['descriptors0'], data['descriptors1']
kpts0, kpts1 = data['keypoints0'], data['keypoints1']
if kpts0.shape[1] == 0 or kpts1.shape[1] == 0: # no keypoints
shape0, shape1 = kpts0.shape[:-1], kpts1.shape[:-1]
return {
'matches0': kpts0.new_full(shape0, -1, dtype=torch.int),
'matches1': kpts1.new_full(shape1, -1, dtype=torch.int),
'matching_scores0': kpts0.new_zeros(shape0),
'matching_scores1': kpts1.new_zeros(shape1),
}
# Keypoint normalization based on image size
# (let keypoints range be 0~1)
kpts0 = normalize_keypoints(kpts0, data['image0'].shape) # [Batch_size, N0, 2]
kpts1 = normalize_keypoints(kpts1, data['image1'].shape) # [Batch_size, N1, 2]
# Keypoint MLP encoder.
desc0 = desc0 + self.kenc(kpts0, data['scores0']) # [Batch_size, 256, N0]
desc1 = desc1 + self.kenc(kpts1, data['scores1']) # [Batch_size, 256, N1]
# Multi-layer Transformer network.
desc0, desc1 = self.gnn(desc0, desc1)
# Final MLP projection.
mdesc0, mdesc1 = self.final_proj(desc0), self.final_proj(desc1)
# Compute matching descriptor distance.
scores = torch.einsum('bdn,bdm->bnm', mdesc0, mdesc1)
scores = scores / self.config['descriptor_dim']**.5
# Run the optimal transport.
scores = log_optimal_transport(
scores, self.bin_score,
iters=self.config['sinkhorn_iterations'])
# Get the matches with score above "match_threshold".
max0, max1 = scores[:, :-1, :-1].max(2), scores[:, :-1, :-1].max(1)
indices0, indices1 = max0.indices, max1.indices
mutual0 = arange_like(indices0, 1)[None] == indices1.gather(1, indices0)
mutual1 = arange_like(indices1, 1)[None] == indices0.gather(1, indices1)
zero = scores.new_tensor(0)
mscores0 = torch.where(mutual0, max0.values.exp(), zero)
mscores1 = torch.where(mutual1, mscores0.gather(1, indices1), zero)
valid0 = mutual0 & (mscores0 > self.config['match_threshold'])
valid1 = mutual1 & valid0.gather(1, indices1)
indices0 = torch.where(valid0, indices0, indices0.new_tensor(-1))
indices1 = torch.where(valid1, indices1, indices1.new_tensor(-1))
return {
'matches0': indices0, # use -1 for invalid match
'matches1': indices1, # use -1 for invalid match
'matching_scores0': mscores0,
'matching_scores1': mscores1,
}
Experiments
Homography estimation
Dataset:Oxford and Paris dataset

能够获得非常高的匹配召回率(98.3%)同时获得超高的精度,比传统的暴力匹配都好了一大截。
- NN: Nearest Neighbor
NN 的变体:
PointCN [33]
OANet:Order-Aware Nerwork [71]
表中前两列参数为图像四个角的重投影误差。
后两列:
P:percision
R:recall
Indoor pose estimation
Dataset
ScanNet,230M for training,1500 test pairs
Metric
与先前工作[33,71,7]一致,统计5°,10°,15°的情况下的 pose error。
pose error是最大的旋转角度和平移的error。
使用RANSAC计算essential matrix,从而估计相对pose。
也统计了match precision 和 matching score(一个match是否正确基于他的epipolar distance判断)。
Baseline
Result
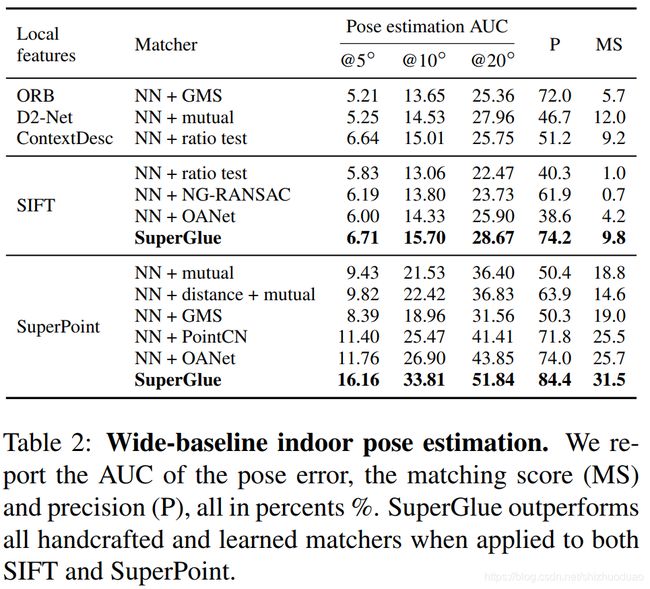
Outdoor pose estimation
Dataset
PhotoTourism:有ground truth pose,sparse 3D models(使用offline的sfm得到的)
MegaDepth:depth(stereo得到),与PhotoTourism重复的被移除了
Results
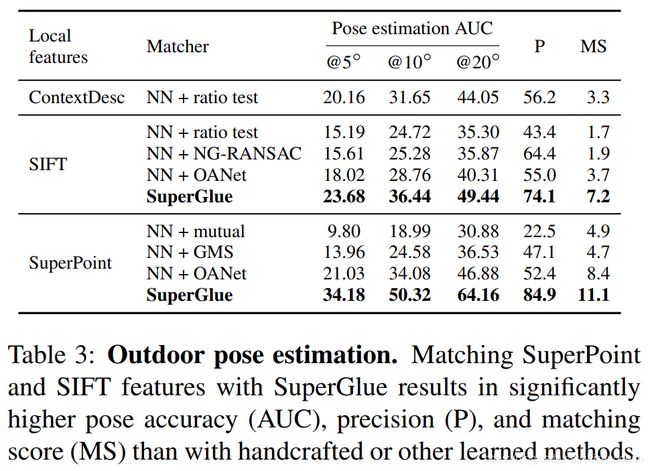
Understanding SuperGluse
Ablation Study

Visualizing attention
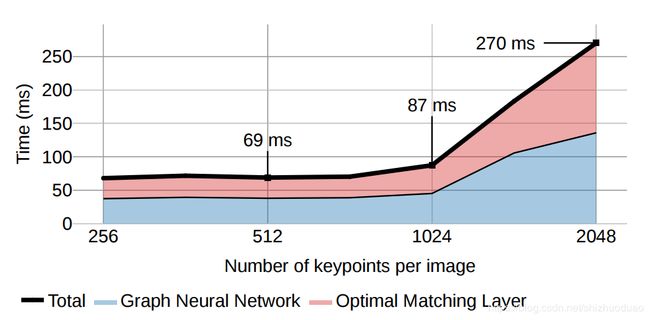
网络耗时
在NVIDIA GeForce GTX 1080 GPU跑了500次的结果,512个点69ms(14.5fps),1024个点87ms(11.5fps)。
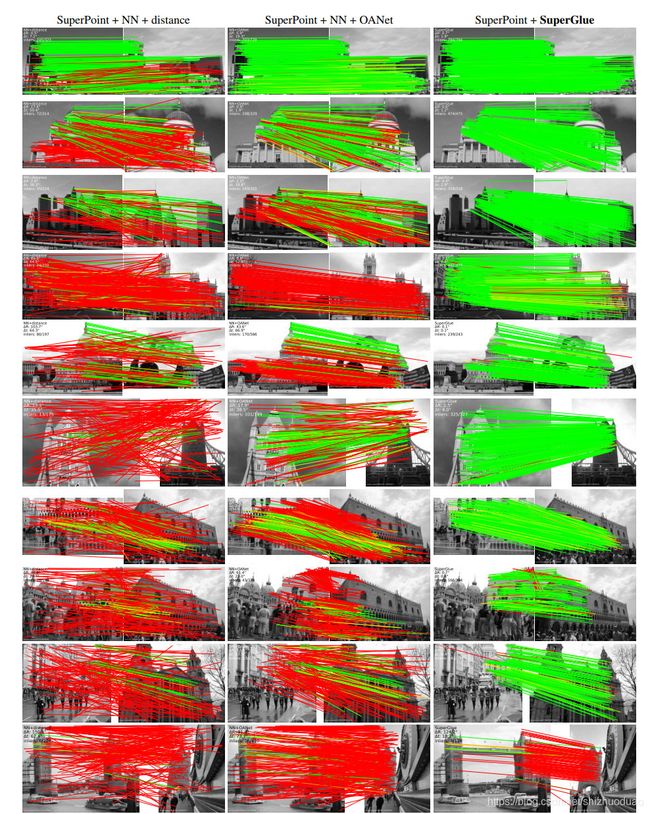
更多匹配结果
第一列是SuperPoint+暴力匹配结果,第二列是SuperPoint+OAnet(ICCV 2019)结果,第三列是SuperPoint+SuperGlue结果。能看到SuperGlue惊人的特征匹配能力,尤其是在大视角变化时优势明显(红线表示错误匹配,绿线表示正确匹配)。


结论
本文展示了基于注意力的图神经网络对局部特征匹配的强大功能。 SuperGlue的框架使用两种注意力:(i)自我注意力,可以增强局部描述符的接受力;以及(ii)交叉注意力,可以实现跨图像交流,并受到人类来回观察方式的启发进行匹配图像。文中方法通过解决最优运输问题,优雅地处理了特征分配问题以及遮挡点。实验表明,SuperGlue与现有方法相比有了显着改进,可以在极宽的基线室内和室外图像对上进行高精度的相对姿势估计。此外,SuperGlue可以实时运行,并且可以同时使用经典和深度学习特征。
总而言之,论文提出的可学习的中后端(middle-end)算法以功能强大的神经网络模型替代了手工启发式技术,该模型同时在单个统一体系结构中执行上下文聚合,匹配和过滤外点。作者最后提到:若与深度学习前端结合使用,SuperGlue是迈向端到端深度学习SLAM的重要里程碑。(when combined with a deep front-end, SuperGlue is a major milestone towards end-to-end deep SLAM)
简单实验

扩展实验
说明
由于SuperGlue是做特征匹配的,所以可以用来做VO,我做了一个简单的frame-by-frame的VO:https://github.com/Shiaoming/Python-VO,它对比的特征有:
- ORB
- SIFT
- SuperPoint
- 可以扩展更多特征描述子(欢迎pull request)
对比的匹配方法有:
- KNN
- FLANN
- SuperGlue
- 可以扩展更多匹配方法(欢迎pull request)
实验的数据集:
- KITTI
- 更多数据集逐渐扩展支持
实验结果
SuperPoint + SuperGlue在KITTI sequence 00上的frame-by-frame VO轨迹:

不同的特征与匹配方式在KITTI sequence 00上结果对比:
