paddlepaddle梦幻联动青春有你2看着小姐姐学AI-用数据剖析你的爱豆
想知道109位小姐姐都是哪里人嘛?是否在节目里听到了熟悉的乡音。人美声甜身材好的小姐姐们是如何自我管理的,统计一下她们的体重来一探究竟。让我们在aistudio上利用python的和我们搜集到的数据来剖析一下吧!
Day03 深度学习常用Python库
numpy是Python科学计算库的基础。包含了强大的N维数组对象和向量运算。其语法操作与matlab有极大相似之处。更多学习,可参考numpy中文网:https://www.numpy.org.cn/
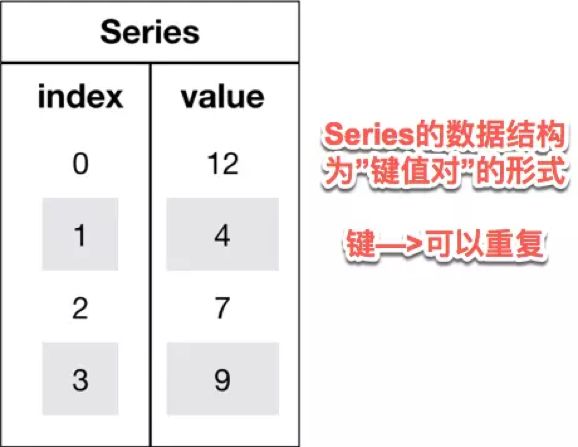
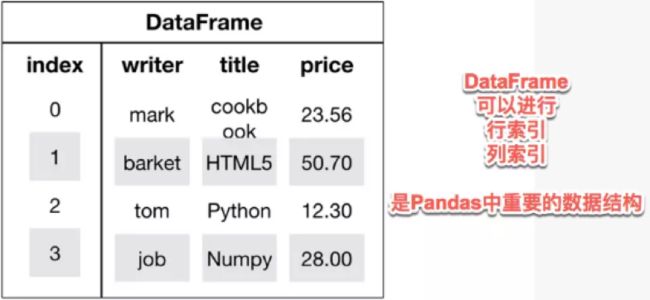
pandas是建立在numpy基础上的高效数据分析处理库,是Python的重要数据分析库。
Matplotlib是一个主要用于绘制二维图形的Python库。用途:绘图、可视化。其也是防matlab plot风格的画图包,非常简便易用。
PIL库是一个具有强大图像处理能力的第三方库。用途:图像处理。可以帮助我们对图像进行剪裁、旋转、明亮度等数据增强处理。
下面就让我们用这几项工具完成任务吧:
homework03 《青春有你2》对选手数据可视化
matplotlib原生的工具对中文支持有点儿问题,需要加入中文字体。
# 下载中文字体
wget https://mydueros.cdn.bcebos.com/font/simhei.ttf
# 将字体文件复制到matplotlib字体路径
cp simhei.ttf /opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/matplotlib/mpl-data/fonts/ttf/
# 一般只需要将字体文件复制到系统字体目录下即可,但是在aistudio上该路径没有写权限,所以此方法不能用
# !cp simhei.ttf /usr/share/fonts/
# 创建系统字体文件路径
mkdir .fonts
# 复制文件到该路径
cp simhei.ttf .fonts/
# 由于使用notebook可能会存在缓存的问题,即使安装了字体,也有可能出现字体显示问题,清空缓存然后重启重新运行即可。
rm -rf .cache/matplotlib
查看你pick的小姐姐们都是来自哪里的?
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
#显示matplotlib生成的图形
%matplotlib inline
with open('data/data31557/20200422.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#绘制小姐姐区域分布柱状图,x轴为地区,y轴为该区域的小姐姐数量
zones = []
for star in json_array:
zone = star['zone']
zones.append(zone)
print(len(zones))
print(zones)
zone_list = []
count_list = []
for zone in zones:
if zone not in zone_list:
count = zones.count(zone)
zone_list.append(zone)
count_list.append(count)
print(zone_list)
print(count_list)
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.figure(figsize=(20,15))
plt.bar(range(len(count_list)), count_list,color='r',tick_label=zone_list,facecolor='#9999ff',edgecolor='white')
# 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''《青春有你2》参赛选手''',fontsize = 24)
plt.savefig('/home/aistudio/work/result/bar_result.jpg')
plt.show()

利用强力的pandas工具 高效简便打到同样的效果:
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
import pandas as pd
#显示matplotlib生成的图形
%matplotlib inline
df = pd.read_json('data/data31557/20200422.json')
#print(df)
grouped=df['name'].groupby(df['zone'])
s = grouped.count()
zone_list = s.index
count_list = s.values
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.figure(figsize=(20,15))
plt.bar(range(len(count_list)), count_list,color='r',tick_label=zone_list,facecolor='#9999ff',edgecolor='white')
# 这里是调节横坐标的倾斜度,rotation是度数,以及设置刻度字体大小
plt.xticks(rotation=45,fontsize=20)
plt.yticks(fontsize=20)
plt.legend()
plt.title('''《青春有你2》参赛选手''',fontsize = 24)
plt.savefig('/home/aistudio/work/result/bar_result02.jpg')
plt.show()

想知道小姐姐们为什么上镜这么好看嘛?让我们仔(bu)仔(huai)细(hao)细(yi)探究一下
import matplotlib.pyplot as plt
import numpy as np
import json
import matplotlib.font_manager as font_manager
#显示matplotlib生成的图形
%matplotlib inline
with open('data/data31557/20200422.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
#绘制小姐姐体重分布饼图 显示首先提取所有选手体重
weights = []
weights_list = []
weights_list = [0,0,0,0]
for star in json_array:
# 取出weight中的数字
weight = star['weight'][:-2]
weight = float(weight)
weights.append(weight)
for weight in weights:
# print(weight < 45)
if weight < 45.0:
weights_list[0] += 1
elif weight < 50.0:
weights_list[1] += 1
elif weight < 55.0:
weights_list[2] += 1
else:
weights_list[3] += 1
print(len(weights))
print(weights)
print(weights_list)
total_num = len(weights)
# 计算体重占比
percent_list = []
for weights in weights_list:
percent_list.append(float(weights)/total_num)
print(percent_list)
category = ['<=45kg', '45-50kg', '50-55kg', '>55kg']
color = ['blue','orange', 'green', 'red']
# 设置显示中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
plt.figure(figsize=(8,8))
plt.pie(percent_list, # 数值信息
labels= category, # 标签信息
explode=[0, 0.05, 0.1, 0.15], # 距离圆中心的距离
colors= color, # 颜色
autopct='%1.2f%%', # 在饼图中,显示百分数
)
plt.legend()
plt.title('《青春有你2》参赛选手体重比例',fontsize = 20)
plt.savefig('/home/aistudio/work/result/pie_result.jpg')
plt.show()
