
\documentclass[10pt,a4paper]{article} \usepackage{ctex} \begin{document} good morning!\ 中文English中文 \end{document}
传统的添加文献的方法:
//--------------------------------------
\begin{thebibliography}{}
这里输入文献
\end{thebibliography}
//-------------------------------------
这种添加文献的方法比较原始,不适合管理大型文献,手工操作繁琐,麻烦,目前更好的解决方案为:
在tex文档中, 指定文献数据库和文献格式文件,创建了文献数据库就可以在所需排版参考文献的位置使用文献格式命令和文献数据库命令
1.首先在tex里加上两个宏包
\usepackage{cite}
\usepackage{hyperref}
2.删除tex论文中的这两行:
\begin{thebibliography}{}
\end{thebibliography}
3.在要插入文献的位置 添加下面两行
\bibliographystyle{文献的格式,如IEEEtran}
\bibliography{文献数据库的名字}
解释:
数据库内存放我们自己搜集整理的各种文献,可以从各大数据库IEEE, WebScience,Springer,ElserVierew...下载bibtex文献形式,可以结合使用JabRef文献管理软件管理所有文献,
文献的格式一般所要投稿的期刊会给出,如IEEE会刊的IEEEtran即为其文献格式,这样在插入文献时,tex会自动转换为IEEE指定的文献样式,简单快捷,JabRef开源免费,适合大型文献的管理和应用.
- 1.添加文献的格式文件到tex文档中,如" \bibliographystyle{文献格式名} ", 文献格式名扩展名为.bst,这里不需要添加扩展名,只需添加相应的文件格式名即可
- 2.添加自己的文献数据库.bib文件到tex文档中,如 "\献数据1名字,文bibliography{文献数据库2名字,...} " ,文献数据库的扩展名为.bib,同上,也不需要在大括号里添加扩展名,只需添加相应的数据库名即可
latex中如何设置sci期刊名(如图所示,分单双页、左右对齐)

开头添加: \documentclass[journal,twoside]{IEEEtran}, 注:必须在选项参数里添加上twoside,否则,无效果.
tex文中采用\markboth{xxx-期刊名}{xxx-文章题目信息等}
为什么要用 Jabref?
JabRef 是一个开源的参考文献管理软件,使用 Java 语言编写,所以天生具有跨平台特性,通用于安装有 Java 支持的 Windows, Linux 和 Mac,软件主页在:http://jabref.sourceforge.net/ 。它可以很方便地管理下载到本机的文献,生成 BibTeX 文献数据库,供 LaTeX 或其它软件使用,可以与 Kile, Emacs, Vim, WinEdt 等多种软件结合使用。
写论文的工具有两大类:一类是用 LaTex,一类是用 Microsoft Word。两类都是工具,内容才是实质,无论如何,只要文章的内容好就行。不过现在就是在讨论工具嘛:
如果你想日子好过些,远离 Word。
用 Jabref 的好处是,无论是用 LaTeX 还是 Word,它都支持。
- LaTeX。直接装一个 Jabref 就好了。
- Word。Jabref 之外还需要装Bibtex4Word。
其实,如果细说,Jabref 就是一个高级的 BibTeX 文件管理工具。说 Jabref 支持 Word 也是靠着Bibtex4Word 让 Word 能结合 BibTeX 使用。说到底,远离 Word 吧。用Bibtex4Word支持 Word 是一种不得已而为之的方法,因为很多时候用 Word 是无法避免的。
Jabref 是免费的,不用费尽心思去找各种激活文件。
Mendeley 目前只能去 Google Scholar 找文献信息,很多时候返回的结果还需要手工修正。
Papers 在查找文献信息的时候很不错,管理也很不错。Windows 版的还比较简陋。Mac 版的 Papers3虽然是正式版,但是功能还不完善;Papers2虽然功能完善,但是缺少了 Dropbox 同步。是的,因为 Papers 是收费软件,我当然期待它完美无缺。Linux 版还木有。
至于其他的 Endnote 什么的,没用过,觉得都是是上个世纪的产品。
BibTeX 是什么?
BibTeX 是 TeX 的衍生系统,专门处理参考文献。具体BibTex 和 TeX 结合的实现机理我不清楚,也觉得没必要。只需要知道 BibTeX 是通过一种以 .bib 的文本文件体现就够了。文本文件的优点就不必说了,跨平台,无论什么平台的电脑都能打开。体积小,传输也方便。
JabRef 适合什么人使用?总的来说 JabRef 最大的特点就是使用 BibTeX 格式的数据库,所以它最适合 LaTeX 用户使用;如果仅仅使用它的管理功能,也可以用于本地电子书的管理;对于使用 M$ Office 写论文的用户来说,EndNote 是最好的选择,它能集成到 M$ Word 中,所以不推荐使用 JabRef。
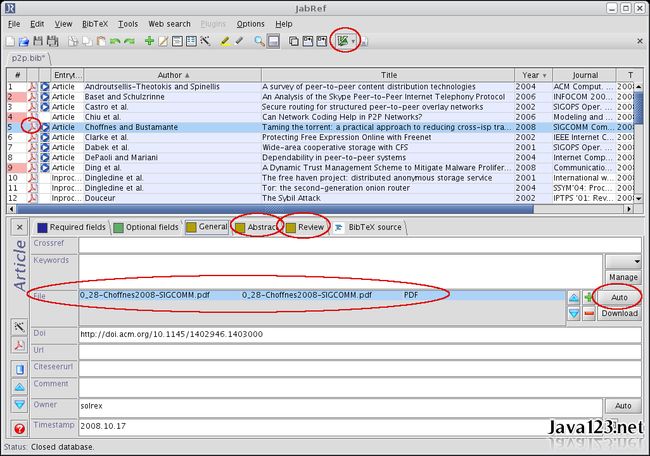
附:JabRef的下载列表:http://jabref.sourceforge.net/ ,JabRef基本界面:
在文章中插入文献时可以用命令\cite{Tremonti2004}来完成,编译后,会tex编译系统会在文后自动插入相应的文献,如下所示:

其他latex中的一些小问题总结(不断更新... ... ... )
如何实现双击pdf文件中的文字跳转到源文件相应的位置?
右击选择“点击以跳转到行(ctrl+click)”,或者按ctrl键加单击文字,会自动跳转到源文件的相应内容上去。
如果以上出现问题,很大可能原因是,你的源文件放在了中文目录下。
部分期刊模板下表格、图片的引用会出现不正确的问题。比如第一张图片定义的label为label{fig1},tex文件中引用ref{fig1},但编译后出现的是Figure 2或是Figure x.x。
解决方法:
在figure(table类似)环境中,先写caption{}再写label{},也就是说,一定要把label{}放在caption{}后面。
2.算法命令\REQUIRE和\ENSURE显示为Input:和Output:
\usepackage{algorithm} 宏包,在tex文中写伪代码时遇到的问题: \usepackage{algorithm}
% \usepackage{algorithmic}

总结: 排版可能需要的包
\usepackage{algorithm} //format of the algorithm
\usepackage{algorithmic} //format of the algorithm
\usepackage{multirow} //multirow for format of table
\usepackage{amsmath}
\usepackage{xcolor}
DeclareMathOperator*{argmin}{argmin} //argmin或argmax公式的排版
\enewcommand{algorithmicrequire}{ extbf{Input:}} //Use Input in the format of Algorithm
\enewcommand{algorithmicensure}{ extbf{Output:}} //UseOutput in the format of Algorithm
排版图片可能需要的包:
usepackage{graphics}
usepackage{graphicx}
usepackage{epsfig}
算法的排版举例:
\begin{algorithm}[htb] %算法的开始
\caption{ Framework of ensemble learning for our system.} %算法的标题
\label{alg:Framwork} %给算法一个标签,这样方便在文中对算法的引用
\begin{algorithmic}[1] %这个1 表示每一行都显示数字
\REQUIRE ~~\ %算法的输入参数:Input
The set of positive samples for current batch, $P_n$;\
The set of unlabelled samples for current batch, $U_n$;\
Ensemble of classifiers on former batches, $E_{n-1}$;
\ENSURE ~~\ %算法的输出:Output
Ensemble of classifiers on the current batch, $E_n$;
\STATE Extracting the set of reliable negative and/or positive samples $T_n$ from $U_n$ with help of $P_n$; label{code:fram:extract} %算法的一个陈述,对应算法的一个步骤或公式之类的; label{ code:fram:extract }对此行的标记,方便在文中引用算法的某个步骤
\STATE Training ensemble of classifiers $E$ on $T_n cup P_n$, with help of data in former batches; label{code:fram:trainbase}
\STATE $E_n=E_{n-1}cup E$; label{code:fram:add}
\STATE Classifying samples in $U_n-T_n$ by $E_n$; label{code:fram:classify}
\STATE Deleting some weak classifiers in $E_n$ so as to keep the capacity of $E_n$; label{code:fram:select}
\RETURN $E_n$; %算法的返回值
\end{algorithmic}
\end{algorithm}
排版效果图:
在文中对算法和算法的某个步骤的引用:Therefore, in step
ef{code:fram:extract} of algorithm
ef{alg:Framwork}, we extract $T_n$, a set of reliable negative samples
1、 For和While循环语句的排版举例
(1) 排版效果图
(2)排版代码
\begin{algorithm}[h]
\caption{An example for format For & While Loop in Algorithm}
\begin{algorithmic}[1]
\FOR{each $iin [1,9]$}
\STATE initialize a tree $T_{i}$ with only a leaf (the root);\
\STATE $T=Tigcup T_{i};$\
\ENDFOR
\FORALL {$c$ such that $cin RecentMBatch(E_{n-1})$} label{code:TrainBase:getc}
\STATE $T=T cup PosSample(c)$; label{code:TrainBase:pos}
\ENDFOR;
\FOR{$i=1$; $i
3. 在LaTex中的注释有3种:
1. 用%注释一行文字, 在%后的文字都不予编译;
2. 用\iffalse .... \fi 包含一段文字, 被包含的文字被注释掉了;
3. 用\begin{comment} ... \end{comment} 包含被注释的文字, 但是需要在引言区包括相应的宏包, 即 \usepackage{verbatim}.