spark资源调度源码浅谈
纸上得来终觉浅,觉知还是要撸代码
此文章适合以下人群参考:
1.接触过spark,有spark基础的同学
2.知其然不知其所以然的同学
3.对于源码好奇的同学
4.大神勿看
大家都知道,大数据中,其实最紧张的就是资源,那么如何利用有限的资源提高运算与吞吐,就是一个框架的核心。一直觉得spark是一个不错的大数据框架,那么spark怎么解决资源调度的问题?
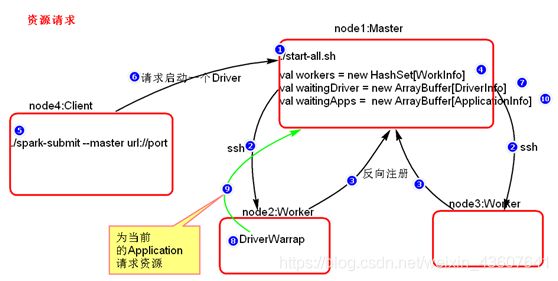
下面我们简单梳理一下spark的资源调度流程。首选,集群启动worker向master汇报资源,master掌握集群资源,client提交任务后,master会在worker中创建一个driver,driver向master请求资源,master分配资源在worker中创建excutor,最后driver分发task任务并监听。那么这个过程在代码是如何实现的?我们提交的命令如何解析?集群之间怎么通信?下面是我撸了两天spark资源调度的代码的一些小总结。我看的是1.6版本的源码,有兴趣的同学可以下载下来,一起跟下
一、寻找程序入口
1。查看执行任务的命令脚本start-all.sh中看到会执行下面两个脚本

2。我可以在start-master.sh脚本中可以看到,master的启动执行类为CLASS=“org.apache.spark.deploy.master.Master”

3。查看start-slaves.sh脚本可以看到,其实本质上还是执行的是start-slave.sh
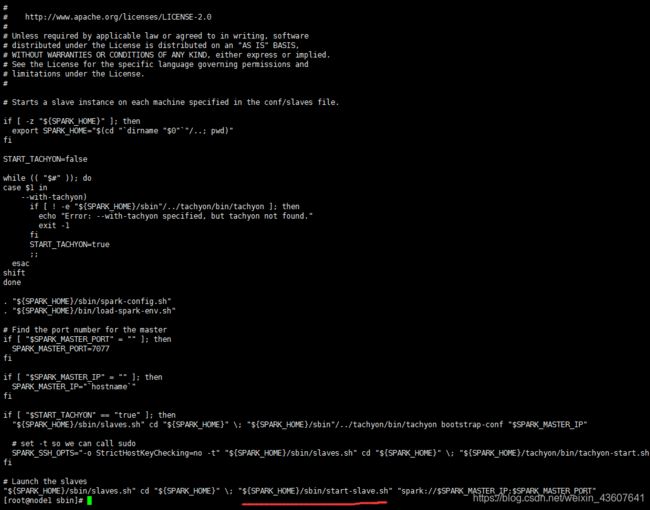
4。查看start-slave.sh可以找到org.apache.spark.deploy.worker.Worker 这个包

由上可以知道,spark启动的时候分别执行的是master包中的Master和worker包中的Worker
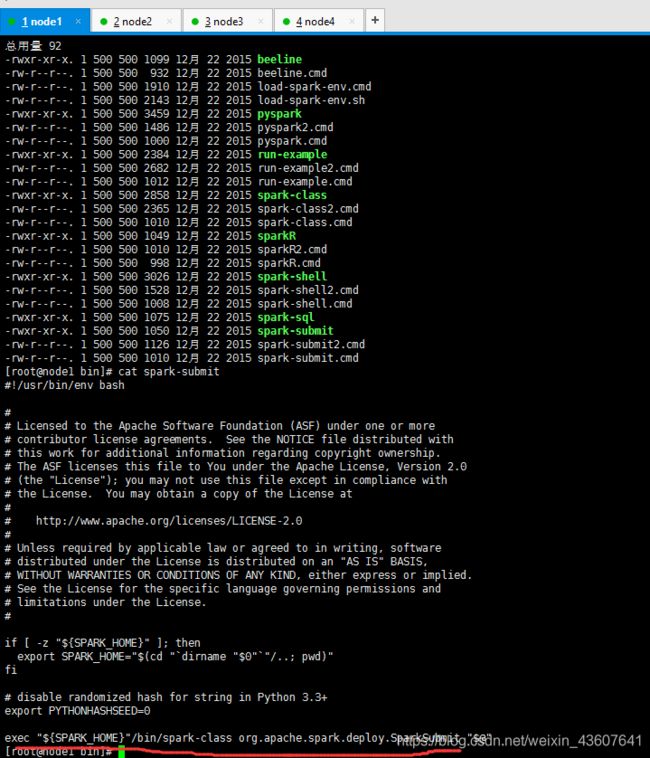
5.查看提交任务命令。spark-submit.sh,可以找到任务提交的时候,执行的的是/bin/spark-class org.apache.spark.deploy.SparkSubmit中的程序
二、解析任务提交命令
1.根据spark-submit.sh脚本中可以知道,整个资源调度起源于
package org.apache.spark.deploy 这个类中的SparkSubmit的方法
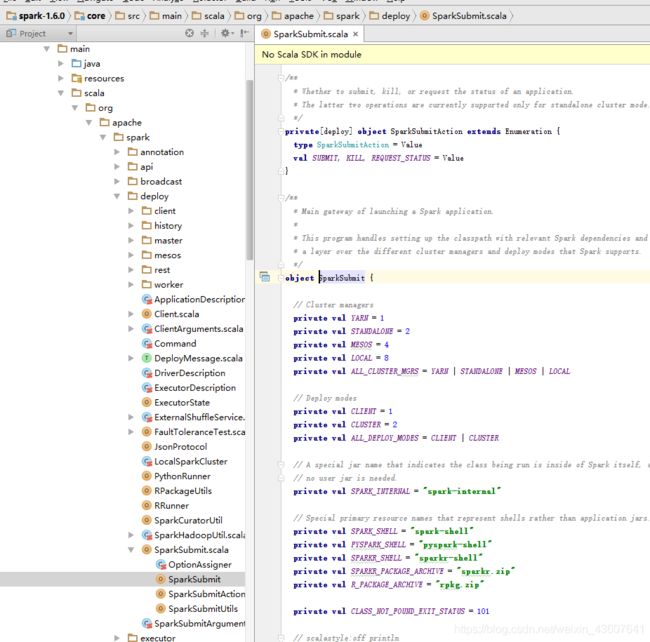
2。在这个类中寻找main函数入口
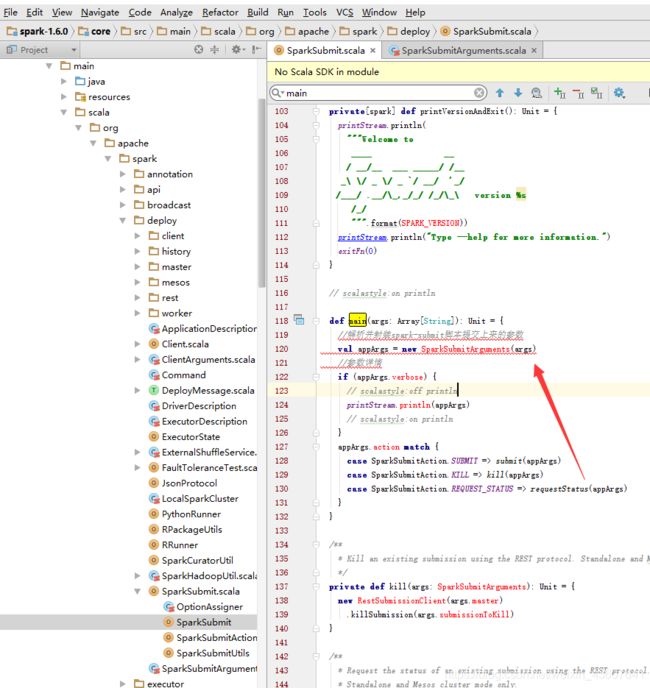
3、如上图,我们可以看到经过SparkSubmitArguments 后解析出一些kill,submit等命令。查看SparkSubmitArguments 参数解析类对象,找到action
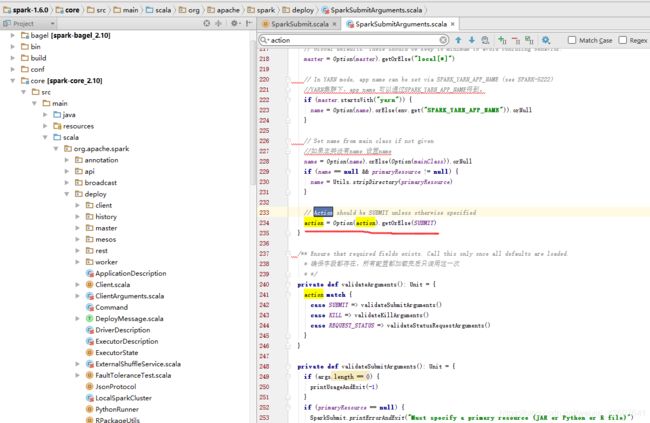
由234行代码可以看到,判断一下是否有值,如果没有值则提交submit命令任务
4.回到SparkSubmit中的main函数,找到submit方法,点进来

5.如上方法反悔了一个四元组,参数,环境变量,系统配置,主类。点入次方法
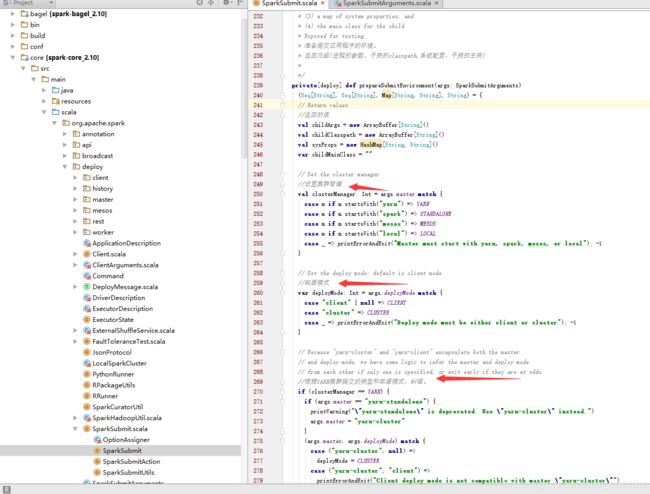
如上图所示,该方法中设置了集群的部署模式,集群管理,纠错。这个方法中设置大量的提交参数的判断与设置,例如R语言与mesos资源管理的配合不支持、py的设置,有兴趣的自己研究下。
我们以standalone cluster模式来跟踪代码
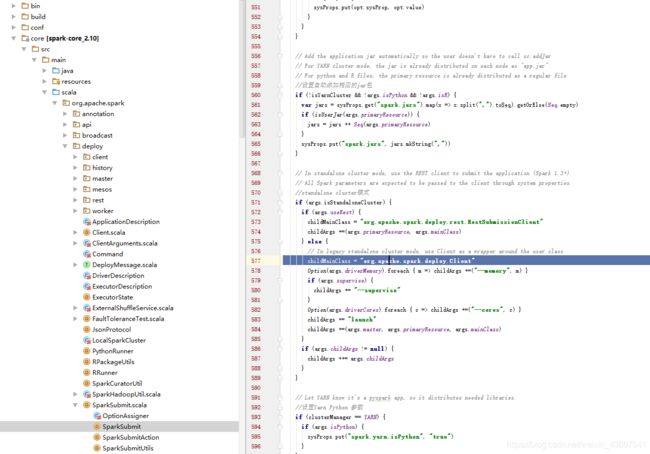
我们看到,通过standalone cluster集群模式启动,启动的是org.apache.spark.deploy.Client这个客户端。
6.返回 submit这个方法。往下看可以看到执行了doRunMain
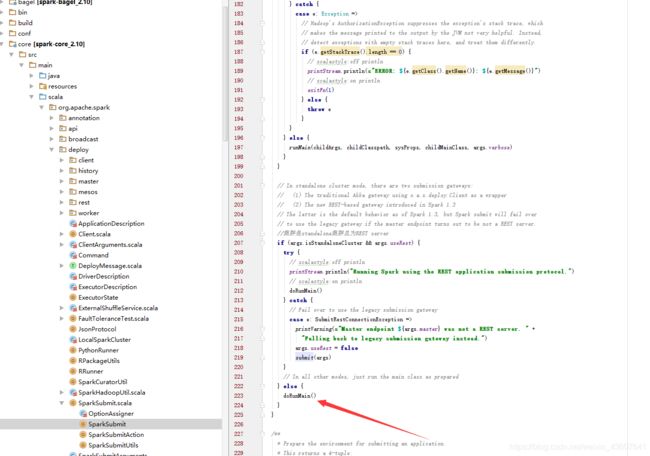
7.doRunMain中执行了runMain,透传了上面解析出来的四个参数
runMain(childArgs, childClasspath, sysProps, childMainClass, args.verbose)

8.点击runMain,可以看到通过反射的方式生成了我们的Client类。

反射获取这个类的方法

给类传参数(childArgs)

三、进行通信
1.找到我们上面反射生成的Client类main方法,这里通过driver找到对应的master节点,进行通信

2.点击rpcEnv.setupEndpoint进入发送消息通信

跳过匿名函数

点入透传方法类,AkkaRpcEndpointRef,跟踪AkkaRpcEndpointRef代码可以知道,155行 endpointRef.init()执行了匿名方法actorRef
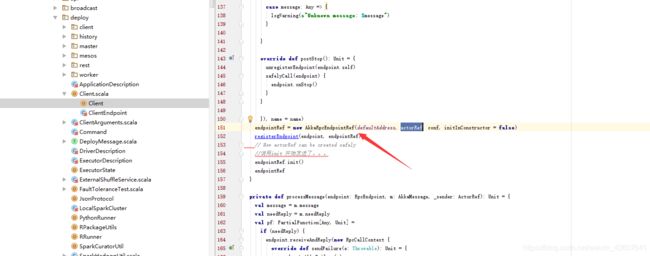
我们回到actorRef方法内,103行启动了我们传入的EndPoint

3.点入endpoint.onStart()方法,是个空的,回到rpcEnv.setupEndpoint方法,顶入这个新建的Client中找到onStart方法

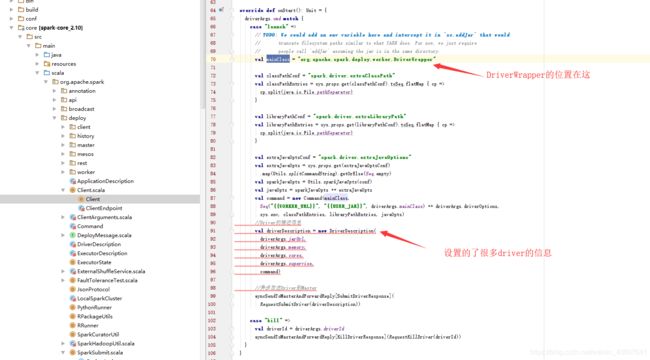
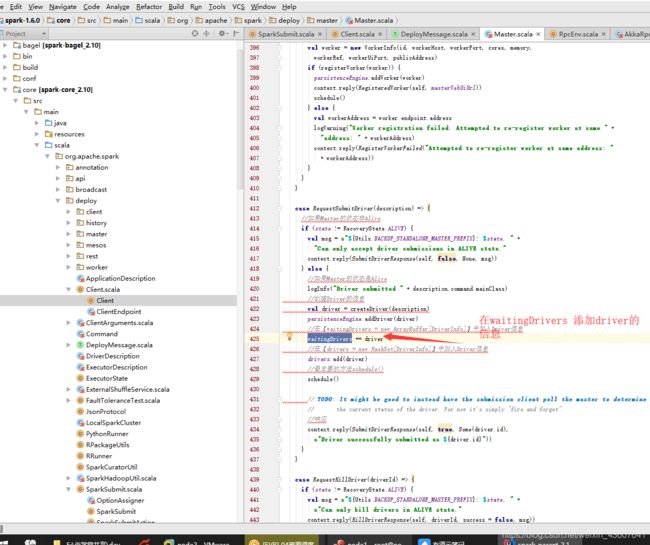
4.点RequestSubmitDriver方法,找到master的方法
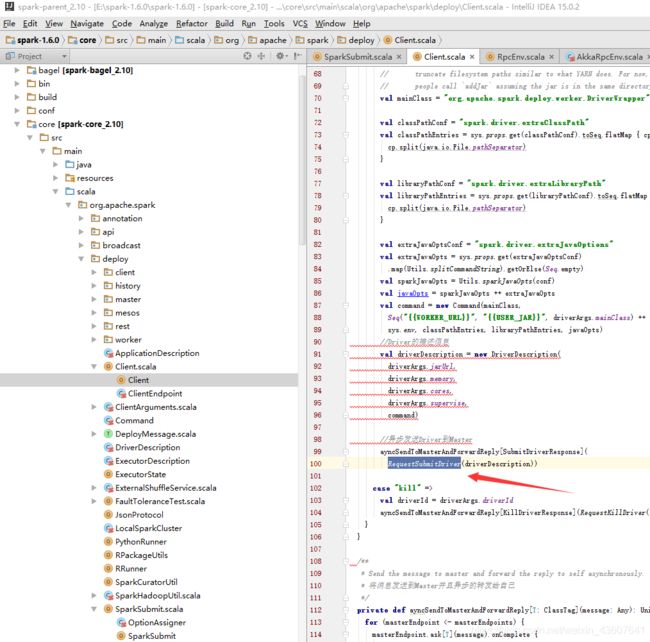

如下图,可以看出在此添加driver的信息
四、分配资源
1.点击入Master类中的schedule方法,这是最核心的资源调度(通过注解我们可以知道,此方法在新的app任务进来,或者资源变动的时候加载)

launchDriver 提交driver
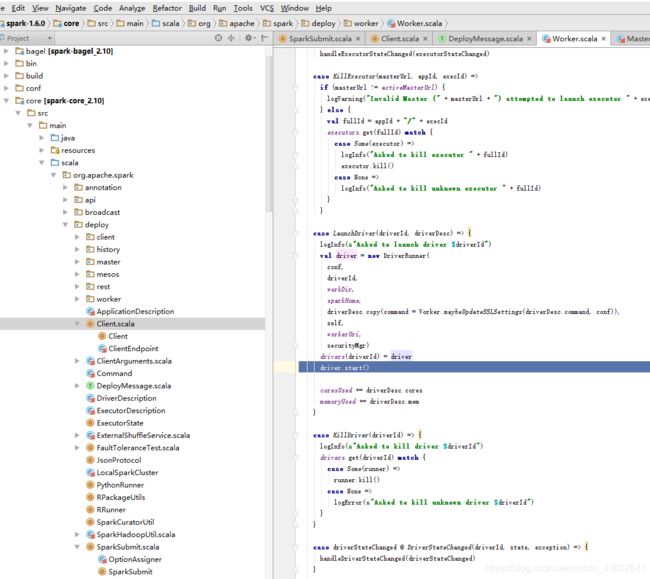
2.点击launchDriver


3。在worker机器上启动driver程序,由上面可以知道其实启动的就是driverWrapper
4。回到Masster的schedule方法

5。在各个worker 中启动excutor反向注册给driver。点击startExecutorsOnWorkers
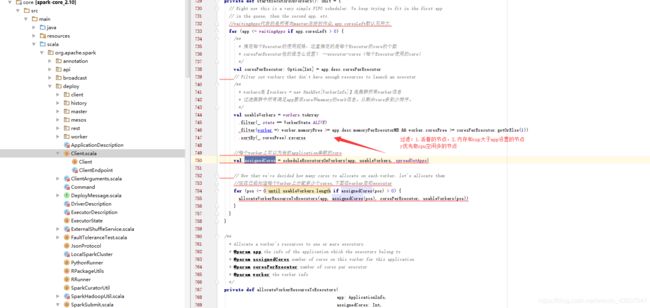
6。如下图,点击startExecutorsOnWorkers,startExecutorsOnWorkers计算筛选出符合的节点

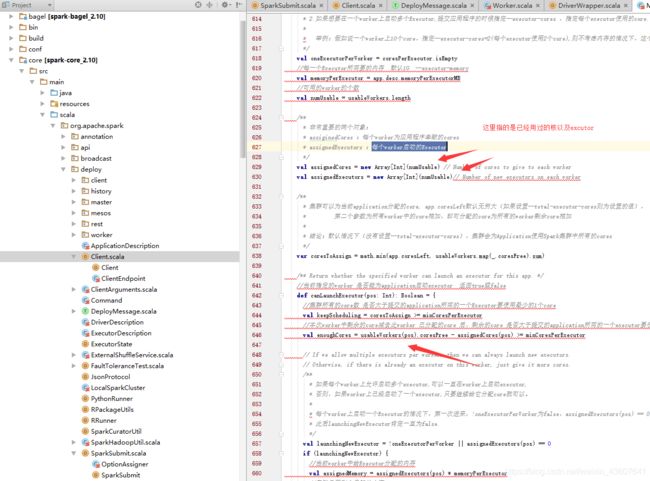
核心计算代码如下,采用两个轮训计算,我们可以看出如果不设置–executor-cores的核数,系统会在一台worker上启动一个excutor占用完该worker资源core
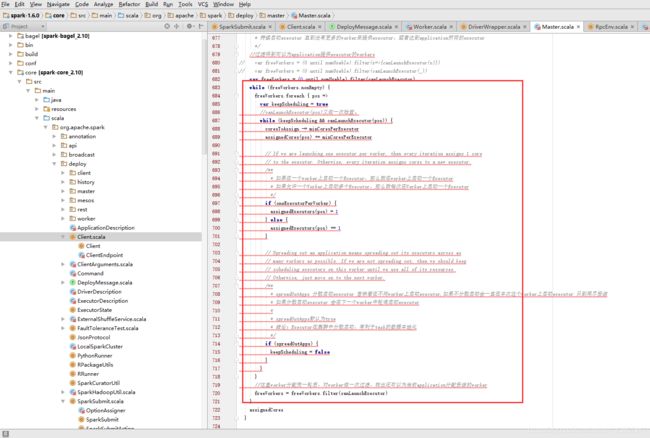
7.返回startExecutorsOnWorkers,allocateWorkerResourceToExecutors执行资源按上面计算的信息进行分发

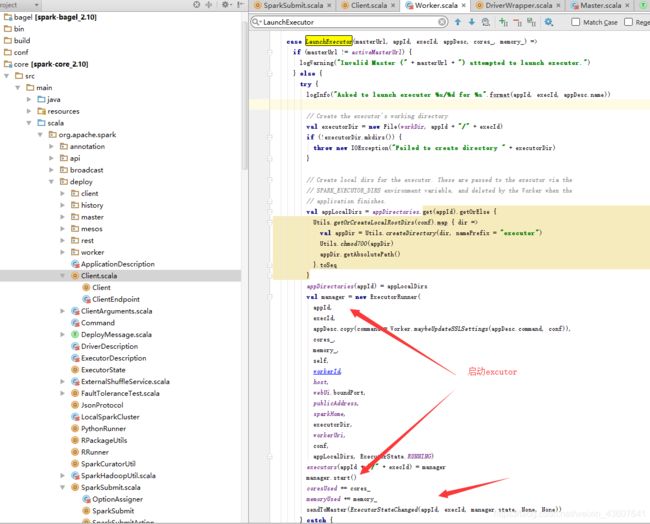
8。点击allocateWorkerResourceToExecutors,launchExecutor方法启动excutor

9.点击launchExecutor,816行代码可以看到(LaunchExecutor),master通过通信,告知worker启动excutor

10.在worker类中查找上面发送的方法LaunchExecutor

在此方法中,按照master的资源分配要求,启动excutor,并且汇报给master
总结
1。excutor在集群中尽量分散,方便task在计算过程中数据存储。spreadOutApps为true的时候是均匀分布,否则,全都在一台work上使用资源,直到该worker上的资源用完。

2。如果,提交任务的时候没有设置–executor-cores,每一个Worker为当前的Application启动一个Executor,这个Executor会使用这个Worker的所有的cores和1G内存

3。默认情况下没有设置–total-executor-cores,一个Application会使用Spark集群中所有的cores