数据分析真题日刷 | 网易2018校招数据分析师笔试卷
- 今日真题
网易2018校招数据分析师笔试卷(来源:牛客网) - 题型
客观题:单选20道
主观题:问答1道,编程2道 - 完成时间
120分钟 - 牛客网评估难度系数
3颗星
❤️ 「更多数据分析真题」
《数据分析真题日刷 | 目录索引》
1. 已知存在以下表
S 表保存着学生关系,有两列,其中SNO 为学号,SNAME 为姓名
C 表保存着课程关系,有三列,其中CNO 为课程号,CNAME 为课程名,CTEACHER 为老师
SC表保存着选课关系,有三列,其中SNO为学号,CNO为课程号,SCORE 为成绩
找出没有选“小易”老师课程的所有学生姓名
列出有三门(包括三门)以上课程分数>90的学生姓名及其平均成绩
「参考答案」
- 找出没有选“小易”老师课程的所有学生姓名
SELECT Sname
FROM S
WHERE S.Sno NOT IN
( SELECT DISTINCT(S.Sno)
FROM S, SC, C
WHERE S.Sno = SC.Sno AND C.Cno = SC.Cno AND C.Cteacher = '小易');
- 列出有三门(包括三门)以上课程分数>90的学生姓名及其平均成绩
-- 方法1
SELECT S.SNAME,AVG(SC.SCORE)
FROM S INNER JOIN SC ON S.SNO=SC.SNO
GROUP BY S.SNAME
HAVING SUM(CASE WHEN SC.SCORE > 90 THEN 1 ELSE 0 END) >= 3;
-- 方法2
SELECT SNAME, AVG(SCORE) AS avg_score
FROM S INNER JOIN SC ON S.SNO = SC.SNO
GROUP BY S.SNAME
HAVING COUNT(SC.SCORE>90 or NULL) >= 3;
感谢评论指出我原本答案的错漏之处,方法2是对原本错误代码的修正版本。
为了便于大家更仔细的了解COUNT()的用法,以下是原错误代码进行对比:
-- 原本的错误代码
SELECT SNAME, AVG(SCORE) AS avg_score
FROM S, C, SC
WHERE S.SNO = SC.SNO AND C.CNO = SC.CNO
GROUP BY S.SNAME
HAVING COUNT(SC.SCORE>90) >=3 -- 错误之处就在于COUNT()内的条件判断
COUNT()对所有非NULL进行计数。SC.Score>90时,为True,不再执行or之后的语句,True不为NULL,则计数。SC.Score<90>90 or NULL) ,SC.Score<90时,为False,则会继续执行or之后的语句,此时整个括号里的结果为NULL,此时不会被计数了。详细参考:https://blog.csdn.net/qq_32719287/article/details/79513164 。
2. 有2堆宝石,A和B一起玩游戏,假设俩人足够聪明,规则是每个人只能从一堆选走1个或2个或3个宝石,最后全部取玩的人获胜,假设2堆宝石的数目为12和13,请问A怎么可以必胜?
A. 让A先取
B. 让B先取
C. 没有策略能够让A必胜
D. 说法都不正确
正确答案:A
「题目解析」
「每个人只能从一堆选走1个或2个或3个宝石」,所以无论对方怎么拿,另一个人总能拿出4的倍数个。比如,对方拿1个,则我拿3;对方2,我拿2;对方3,我拿1。我总是可以保证,我是最后全部去完4的倍数个的人。当宝石数目为4的倍数,这种情况下,后拿的获胜。
现在有12+13=25个宝石。因此A先拿走1个,剩下24个宝石。对于剩下的24个宝石,B是先拿者,A是后拿者。所以可以保证A获胜。
- 举一反三
本题是《网易2018校园招聘数据分析工程师笔试卷》第14题的变形。
3. 从数字集合{1,2,3,4,… ,20}中选出4个数字的子集,如果不允许两个相连的数字出现在同一集合中,那么能够形成多少个这种子集?
A. 2380
B. 816
C. 330
D. 1220
正确答案:A
「题目解析」
可以转化题目为,将4个数字插入到16个数字的17个空格中,有多少种插入方法?
C(17,4) = 2380
4. 将4个不一样的球随机放入5个杯子中,则杯子中球的最大个数为3的概率是?
A. 9/16
B. 16/125
C. 16/25
D. 9/25
正确答案:B
「题目解析」
分母 : 4个不一样的球随即放入5个被子总共有 5 * 5 * 5 * 5 中放法
分子 : 「杯子中球的最大个数为3」,则C(4,1)选出一个球,单独放在5个杯子中任意一个,剩下3个球作为整体,放在剩下的4个杯子中的一个。即,C(4,1) * 5 * 4
5. 下面程序的功能是输出数组的全排列,选择正确的选项,完成其功能。
void perm(int list[], int k, int m)
{
if ( )
{
copy(list,list+m,ostream_iterator(cout," "));
cout< A. k!=m 和 perm(list,k+1,m)
B. k==m 和 perm(list,k+1,m)
C. k!=m 和 perm(list,k,m)
D. k==m 和 perm(list,k,m)
正确答案:B
「民间解析」
if是递归的终止判断条件,刚开始输入的时候k应该为0,m应该为数组中的元素个数;所以当k==m时,表示全排列的全部情况都已经找出。
第一个swap是依次将第k个元素和k~m个元素交换,交换完后进入递归,再全排列其子数组。
递归调用,之所以从k+1开始,是因为如果传入的是k的话,递归传进去的参数不变,递归将永无止境的递归下去,因为k永远不会等于m
第二个swap是将该层交换完后的数组再还原,目的是为了使递归返回后不改变上一层的数组元素顺序,方便下一次交换。
来源:http://s3.nowcoder.com/questionTerminal/af099970cfcc44cfa8e43348f600a017
作者:chinawjb
6.若有33个长度不等的初始归并段,做7路平衡归并排序,为组织最佳归并树,应增加长度为0的初始归并段的个数是________。
A. 0
B. 2
C. 4
D. 6
正确答案:D
?附加“虚段”的归并树
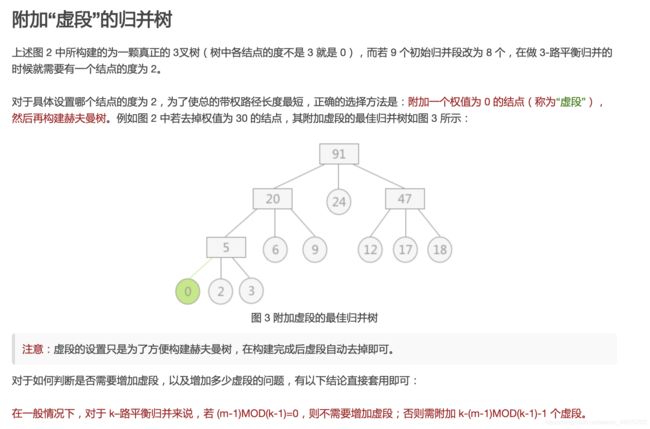
(来源:http://data.biancheng.net/view/79.html)
「题目解析」
已知 m = 33, k = 7,根据公式
k - (m-1) MOD (k-1) -1 = 7 - (32)MOD(6) -1 = 7- 2 -1 = 4。
7. 将一个整数序列整理为升序,两趟处理后序列变为10,12,21,9,7,3,4,25,则采用的排序算法可能是________。
A. 插入排序
B. 选择排序
C. 快速排序
D. 堆排序
正确答案:A
「民间解析」
- 插入排序:第一趟前两个有序,第二趟前三个有序。
- 快速排序:每经过一趟快排,轴点元素都必然就位,也就是说,一趟下来至少有1个元素在其最终位置,2趟就有两个位置元素就位。
来源:https://www.nowcoder.com/test/question/done?tid=24933835&qid=167735#summary
作者:阿蔡蔡
8. 在数理统计中, 一般通过增加抽样次数取平均来使得预估误差减小, 在机器学习中也有类似的模型处理, 如随机森林, 通过引入随机样本并且增加决策树的数据,对于随机森林主要降低预估的哪个方面值
A. 预估偏差
B. 预估方差
C. 噪音
D. 全部
正确答案:B
「民间解析」
增加数据是降低由数据的不稳定性所带来的方差,增加模型复杂度是降低偏差,另外噪音是无法避免的
来源:https://www.nowcoder.com/test/question/done?tid=24933835&qid=167736#summary
作者:全面发展的程序员
9. 以下不属于非监督学习的为
A. 关联规则
B. Kmeans
C. Word2vec
D. Knn
正确答案:D
「题目解析」
Knn是分类算法,是有监督的。
- 强烈参考
《通俗理解word2vec》 https://www.jianshu.com/p/471d9bfbd72f
10. 将当前命令sh test.sh任务在后台执行,下列最优雅的的做法是
A. sh test.sh &
B. nohup sh test.sh
C. nohup sh test.sh &
D. nohup sh test.sh &&
正确答案:C
「民间解析」
nohup (no hang up)命令
用途:不挂断地运行命令。
语法:nohup Command [ Arg … ] [ & ]
例子: nohup sh example.sh &
描述:nohup 命令运行由 Command 参数和任何相关的 Arg 参数指定的命令,忽略所有挂断(SIGHUP)信号。在注销后使用 nohup 命令运行后台中的程序。要运行后台中的 nohup 命令,添加 & ( 表示”and”的符号)到命令的尾部。
来源:https://www.nowcoder.com/test/question/done?tid=24933835&qid=167738#summary
作者:我佛慈悲
(欢迎评论,补充解析~)
11. 截取logfile文件中含有suc的行,并且只输出最后一列,下列操作正确的是:
A. grep -o 'suc' logfile | awk '{print $0}'
B. grep 'suc' logfile | awk '{print $0}'
C. grep 'suc' logfile | awk '{print $NF}'
D. grep -o 'suc' logfile | awk '{print $NF}'
正确答案:C
(欢迎评论,补充解析~)
12. 哪个不是DDL(数据库定义语言)语句?
A. ALTER
B. CREATE
C. RENAME
D. GRANT
正确答案:D
?数据库的四种语言
SQL语言共分为四大类:数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。
1. 数据查询语言DQL
数据查询语言DQL基本结构是由SELECT子句,FROM子句,WHERE
子句组成的查询块:
SELECT <字段名表>
FROM <表或视图名>
WHERE <查询条件>2. 数据操纵语言DML
1)插入:INSERT
2)更新:UPDATE
3)删除:DELETE
3. 数据定义语言DDL
数据定义语言DDL用来创建数据库中的各种对象—–表、视图、索引、同义词、聚簇等如:
CREATE TABLE/VIEW/INDEX/SYN/CLUSTER(表 视图 索引 同义词 簇)
4. 数据控制语言DCL
数据控制语言DCL用来授予或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。如:
1) GRANT:授权。
2) REVOKE:撤销授权。
3) ROLLBACK [WORK] TO [SAVEPOINT]:回退到某一点。
4) COMMIT [WORK]:提交。
来源:https://blog.csdn.net/sunhuaqiang1/article/details/52880780
- 强烈推荐
《SQL语言四大类》https://blog.csdn.net/sunhuaqiang1/article/details/52880780
13. 对于SQL语句select * from t where a=100 and b=200,哪个索引可以使用到?
A. 索引idx_b(b)
B. 索引idx_b_a(b,a)
C. 索引idx_a_b(a,b)
D. 都可以
正确答案:D
?索引的「最左原则」
- 举一反三
《京东2019校招数据分析工程师笔试题》第33题。
14. 若要在员工信息表EMP中增加一列WANGYI_NO(网易id),可用( )。
A. ADD TABLE EMP(WANGYI_NO CHAR(10))
B. ADD TABLE EMP ALTER(WANGYI_NO CHAR(10))
C. ALTER TABLE EMP ADD(WANGYI_NO CHAR(10))
D. ALTER TABLE EMP (ADD WANGYI_NO CHAR(10))
正确答案:C
15. 在机器学习任务中经常假设矩阵为n×n的对称矩阵A, 则以下说法正确的是
A. 对称矩阵为满秩矩阵
B. 对称矩阵的列向量之间正交
C. 对应于A的不同特征值的特征向量之间正交
D. 对应于A的相同特征值得特征向量之间正交
正确答案:C
「民间解析」
对称矩阵不一定满秩;不同特征值之间的特征向量一定正交,而同一特征值的特征向量需要借助公式得正交向量
来源:https://www.nowcoder.com/test/question/done?tid=24933835&qid=167743#summary
作者:阿蔡蔡
16. 以下关于python数据结构说法正确的是
A. python中list可以动态的更新, 但是不容许嵌套
B. python中tuple可以动态更新, 但是不容许嵌套
C. python中dict保存键值对, 并且键值对是有序的
D. python中list的元素可以是tuple
正确答案:D
「题目解析」
A.list可以动态更新,也可以进行嵌套;
B.tuple不可以更新,更不可以动态更新,可以嵌套;
C.待解析,欢迎评论~
D.正确。
17. 一个快递公司对同一年龄段的员工,进行汽车,三轮车,二轮车平均送件量的比较,结果给出sig.=0.034,说明
A. 三类交通工具送件量有差别的可能性是0.034
B. 三类交通工具送件量没有差别的可能性是0.034
C. 交通工具对送件量没影响。
D. 按照0.05显著性水平,拒绝H0,说明三类交通工具送件量有显著差异。
正确答案:D
18. 小明在一次班干部二人竞选中,支持率为百分之五十五,而置信水平0.95以上的置信区间为百分之五十到百分之六十,请问小明未当选的可能性有可能是
A. 40%
B. 50%
C. 5%
D. 3%
正确答案:D
「民间解析」
如果不能当选,意味着在置信区间外,但置信区间外也有可能支持率大于60%(仍当选),
所以不当选(支持率小于50%)的可能性只能是0%-5%以下,不包括5%,否则支持率大于60%的可能性为0。
来源:https://www.nowcoder.com/test/question/done?tid=24933835&qid=167746#summary
作者:cjn201805071412837
19. 以下关于最小二乘法正确的是
A. 最小二乘估计是线性有偏估计中方差最小的
B. 最小二乘估计是线性无偏估计中方差最小的
C. 最小二乘估计是线性有偏估计中方差最大的
D. 最小二乘估计是线性无偏估计中方差最大的
正确答案:B
20. 小易有一些彩色的砖块。每种颜色由一个大写字母表示。各个颜色砖块看起来都完全一样。现在有一个给定的字符串s,s中每个字符代表小易的某个砖块的颜色。小易想把他所有的砖块排成一行。如果最多存在一对不同颜色的相邻砖块,那么这行砖块就很漂亮的。请你帮助小易计算有多少种方式将他所有砖块排成漂亮的一行。(如果两种方式所对应的砖块颜色序列是相同的,那么认为这两种方式是一样的。)
例如: s = “ABAB”,那么小易有六种排列的结果:
“AABB”,“ABAB”,“ABBA”,“BAAB”,“BABA”,“BBAA”
其中只有"AABB"和"BBAA"满足最多只有一对不同颜色的相邻砖块。
「思路」
如果有三个不同字符则不满足上述情况,如果有两个字符,则结果只有两种,若只有一个字符,则结果只有一种。所以本题本意为求不同字符的个数。
「我的答案」
def fun(s):
l = len(set(s))
if l == 2:
return 2
elif l == 1:
return 1
else :
return 0
s = input()
print(fun(s))
21. 小易为了向他的父母表现他已经长大独立了,他决定搬出去自己居住一段时间。一个人生活增加了许多花费: 小易每天必须吃一个水果并且需要每天支付x元的房屋租金。当前小易手中已经有f个水果和d元钱,小易也能去商店购买一些水果,商店每个水果售卖p元。小易为了表现他独立生活的能力,希望能独立生活的时间越长越好,小易希望你来帮他计算一下他最多能独立生活多少天。
「我的答案」
def fun(x, f, d, p):
if d//x <= f:
return d//x
else:
l = f+(d-x*f)//(x+p)
return l
x, f, d, p = map(int,input().split())
print(fun(x, f, d, p))
22. 设{xn}服从独立同分布,E[xn] = 0, Var[xn]=1,, 则当n趋向于无穷大时,下式值为:![]()
A. 无穷大
B. 0
C. 1
D. 2
正确答案:C
「题目解析」
step 1. 独立同分布,则 E[Xi X(i+1)] = E[Xi] * E[X(i+1)] = 0
step 2. E(Xi ^2) = (EX) ^ 2 + Var(X) = 0 + 1 = 1
step 3. E(原式) = n / n = 1
23. 通常可以通过关联规则挖掘来发现啤酒和尿布的关系, 那么如果对于一条规则A →B, 如果同时购买A和B的顾客比例是4/7, 而购买A的顾客当中也购买了B的顾客比例是1/2, 而购买B的顾客当中也购买了A的顾客比例是1/3,则以下对于规则A →B的支持度(support)和置信度(confidence)分别是多少?
A. 4/7,1/3
B. 3/7,1/2
C. 4/7,1/2
D. 4/7,2/3
正确答案:C
?支持度、置信度
对于关联规则 A -> B
支持度 = P(AB)
置信度 = P(B | A)