spark调优总结
1.sparkseaming
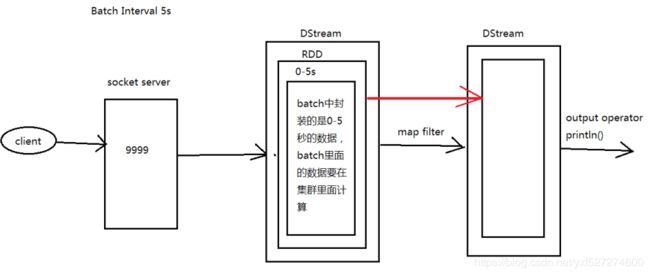
从图上可以看到,Batch Interval的间隔是5s,也就是说每经过5s,SparkStreaming会将这5s内的信息封装成一个DStream,然后提交到Spark集群进行计算
1.1执行流程
第一个 DStream 里面是 0-5s 的数据,在第6s的时候会触发 DStream 的job执行,这时会另启动一个线程执行这个job(假设这个job只需要3s),同时在6-10s期间继续接受数据,在第11s的时候会触发 DStream 的job的执行,这时会另启动一个线程执行这个job(假设这个job只需要3s),同时在11-15s期间继续接受数据...
*注意!
如果这个job执行的时间大于5s会有什么问题?
数据在5s内处理不完,又启动一个job,导致数据越积越多,从而导致 SparkStreaming down
1.2为什么需要有窗口操作?
比如别人要求能够实时看到此刻之前一段时间的数据情况,如果使用批处理的话,那么我们只能固定一个整段时间然后对这个整段时间进行spark core的计算,但是别人的要求是每一个时刻都需要有结果,那么就需要窗口操作?但是窗口操作肯定会有很多的重复计算,这里有一个优化的地方(这个优化也不是必须的,视具体情况而定,比如说我们要查看最近30分钟最热门的头条,我们在设计的时候不可能每隔30分钟计算一次,这里定义了滑动窗口时间是1分钟,然而计算量是30分钟内的数据,那么肯定会有29分钟重复的数据计算);但是优化的话就会有一个前提,必须要checkpoint
1.3 UpdateStateByKey
updateStateByKey的使用需要checkpoint,隔几次记录一次到磁盘中
UpdateStateByKey的主要功能
1、Spark Streaming中为每一个Key维护一份state状态,这个state类型可以是任意类型的的, 可以是一个自定义的对象,那么更新函数也可以是任意类型的。
2、通过更新函数对该key的状态不断更新,对于每个新的batch而言,Spark Streaming会在使用updateStateByKey的时候为已经存在的key进行state的状态更新(对于每个新出现的key,会同样的执行state的更新函数操作)
3、如果要不断的更新每个key的state,就涉及到了状态的保存和容错,这个时候就需要开启checkpoint机制和功能 ( one.checkpoint(Durations.seconds(10)) //容错更好就需要牺牲性能,容错不需要太高,时间可以设置的长一些,(比如这里将checkpoint设置为10s,也就是每隔10s会将标记有checkpoint的RDD计算的结果持久化到磁盘,如果我们设置的Batch Interval = 5s, 在第15s时触发job进行计算, 但是在第17s时down, 这时候只能恢复到10s的数据,那么10s至17s的数据就丢失了,具体设置多少,视具体情况而定))
以上时从此处参考整理 http://www.cnblogs.com/haozhengfei/p/e353daff460b01a5be13688fe1f8c952.html
- sparkStreaming监控
Spark UI中的以下两个指标尤为重要:
1.Processing Time 处理时间 - 处理每批数据的时间。
2.Scheduling Delay 计划延迟 - 批处理在队列中等待处理先前批处理完成的时间。
*注意:若Processing Time的值一直大于Scheduling Delay,或者Scheduling Delay的值持续增长,代表系统已经无法处理这样大的数据输入量了,这时就需要考虑各种优化方法来增强系统的负载或者减少批处理的时间
Spark UI中提供一些数据监控,包括实时输入数据、Scheduling Delay、处理时间以及总延迟的相关监控数据的趋势展现。另外除了提供上述数据监控外,Spark UI还提供了Active Batches以及Completed Batches相关信息。Active Batches包含当前正在处理的batch信息以及堆积的batch相关信息,而Completed Batches刚提供每个batch处理的明细数据,具体包括batch time、input size、scheduling delay、processing Time、Total Delay等
Spark Streaming能够提供如此优雅的数据监控,是因在对监听器设计模式的使用。如若Spark UI无法满足你所需的监控需要,用户可以定制个性化监控信息。Spark Streaming提供了StreamingListener特质,通过继承此方法,就可以定制所需的监控
3.SparkStreaming 支持的业务场景
目前而言SparkStreaming 主要支持以下三种业务场景
a.无状态操作:只关注当前的DStream中的实时数据,例如 只对当前DStream中的数据做正确性校验
无状态模型只关注当前新生成的DStream数据,所以的计算逻辑均基于该批次的数据进行处理。无状态模型能够很好地适应一些应用场景,比如网站点击实时排行榜、指定batch时间段的用户访问以及点击情况等。该模型由于没有状态,并不需要考虑有状态的情况,只需要根据业务场景保证数据不丢就行。此种情况一般采用Direct方式读取Kafka数据,并采用监听器方式持久化Offsets即可。
*注意:受网络、集群等一些因素的影响,实时程序出现长时失败,导致数据出现堆积。此种情况下是丢掉堆积的数据从Kafka largest处消费还是从之前的Kafka offsets处消费,这个取决具体的业务场景。
b.有状态操作:对有状态的DStream进行操作时,需要依赖之前的数据 例如 统计网站各个模块总的访问量。有状态模型是指DStreams在指定的时间范围内有依赖关系,具体的时间范围由业务场景来指定,可以是2个及以上的多个batch time RDD组成。Spark Streaming提供了updateStateByKey方法来满足此类的业务场景。因涉及状态的问题,所以在实际的计算过程中需要保存计算的状态,Spark Streaming中通过checkpoint来保存计算的元数据以及计算的进度。该状态模型的应用场景有网站具体模块的累计访问统计、最近N batch time 的网站访问情况以及app新增累计统计等等.
c.窗口操作:对指定时间段范围内的DStream数据进行操作,例如 需要统计一天之内网站各个模块的访问数量
4.spark优化
4.1算子优化
1在使用join的地方看是否可以使用map算子和广播变量的方式替代;
2使用高效的算子, 例如:使用reduceByKey/aggregateByKey来代替groupByKey,因为前者可以进行combiner操作,减少网络IO;
当进行联合规约操作时,避免使用 groupByKey。举个例子,rdd.groupByKey().mapValues(_ .sum) 与 rdd.reduceByKey(_ + _) 执行的结果是一样的,但是前者需要把全部的数据通过网络传递一遍,
3.使用MapPartition来代替Map操作, 尤其是在需要网络连接的地方;
4.使用foreachPartition代替foreach操作,可以对数据进行批量处理;
5.在filter操作后,可以使用colease操作,可以减少任务数;
6.序列化尽量使用Kyro方式, 其性能更好;
7.减少对复杂数据结构的使用,可以有效减少序列化时间;
8.对应简单的函数,最好使用闭合结构,可以有效减少网络IO;
9.使用Repartition操作可以有效增加任务的处理并行度;
4.2参数调整优化部分
设置合理的资源;
Java垃圾回收器;
清理不必要的空间;
1.根据资源情况,可以添加Executor的个数来有效,参数为 spark.executor.instances
2.调整每个Executor的使用内核数, 参数为 spark.executor.cores
3.调整每个Executor的内存, 参数为 spark.executor.memory
4.shuffle write task的buffer大小, 参数为 spark.shuffle.file.buffer
5.shuffle read task的buffer大小, 参数为 spark.reducer.maxSizeInFlight
6.每一个stage的task的默认并行度, 默认为200, 建议修改为1000左右, 参数 spark.default.parallelism
7.用于RDD的持久化使用的内存比例,默认0.6, 参数 spark.storage.memoryFraction
8.用户shuffle使用的内存比例, 默认为0.2, 参数 spark.shuffle.memoryFraction
4.3其它优化
1.增加数据读取的并行度,比如读取Kafka的数据,可以增加topic的partition数量和executor的个数;
2.限制读取Kafka数据的速率,参数 spark.streaming.kafka.maxRatePerPartition
3.对于存在数据倾斜问题,有两类情况:
4.进行join操作,产生skew问题, 可以使用map+广播变量类进行处理;
5.对redece/aggregate等聚合操作,参数skew问题, 可以进行两次聚合的思想来解决,
* 核心是先进行key进行随机数操作, 是数据分布均匀,并进行聚合,最后是剔除随机数据,用实际数据来进行聚合操作。
6.并行度调优设置:
a.在数据进行混洗的时候,使用参数的方式为混洗后的RDD指定并行度
b.对于已经存在的RDD可以进行重新分区来获取更多或更少的分区数。重新分区操作通过repartiton()实现,这个操作会把 RDD随机打乱并分成设定的分区数目。如果要减少RDD分区,可以使用coalesce()操作。由于没有打乱数据这个 操作比 repartition()更为高效。
eg:从S3上读取大量数据,进行filter()操作。filter()返回的RDD的分区数和父节点的一样,这样会造成很多空的 分区或只有很少数据的分区。这样的情况下可以通过合并得到分区更少的RDD来提高性能。

7.序列化:
a.spark通过网络传输数据,或者把数据溢写到磁盘上时,需要把数据序列化成二进制格式。序列化会在数据进行混洗的时 候发生。此时需要大量网络传输。默认情况下,spark使用java内部得序列化库。spark也支持第三方得序列化库, 可提供比java序列化工具更短得序列化时间和更高得压缩比例得二进制表示。
b.要使用kryo序列化工具,需要设置spark.serializer为org.apache.spark.serializer.kryoserializer。还可 以像kryo注册你想要得序列化得类,这样可以让kryo把每个对象完整得类名写下来。要注册就得把 org.apache.spark.serializer.kryoserializer设置为true
eg:
val conf = new sparkConf()
conf.set("spark.serializer","org.apache.spark.serializer.kryoserializer")
//注册类
conf.set("spark.kryo.registrationReauired","true")
conf.registerKryoClasses(Array(classOf[MyClass],classOf[MyOtherClass]))
8.内存调优
a.spark会用60%得空间来存储RDD,20%存储数据混洗产生得数据,20%留给用户程序。用户可以自定义调节这些选项 来追求更好得性能。如果用户代码中分配了大量的对象,那么降低RDD存储和数据混洗存储所占得空间可以有效避 免内存不足得情况。
spark默认得cache()以memory_only的存储等级持久化数据。这意味着缓存新的RDD分区时空间不够,旧得分 区会被删除。等用到这些分区得时候在进行计算。 所以有时运用momory_and_disk存储级别调用 persist()方法会获得更好得效果
b.对于默认的缓存策略的另一个改进是缓存序列化后的对象而非直接缓存。可以通过memory_only_ser或者 memory_and_disk_ser得存储级别来实现。虽然缓存得时间边长了,但是可以显著减少jvm得垃圾回收时间。这 种场景 是你需要以对象的形式缓存大量的数据,或者注意到长时间的垃圾回收暂停。
4.4 sparkSQL 优化
- 广播JOIN表
spark.sql.autoBroadcastJoinThreshold,默认10485760(10M),在内存够用的情况下,提高其大小,可以将join中 的较小 的表广播出去,而不用进行网络数据传输
- 合理配置spark.sql.shuffle.partition;
3. 缓存表
对于一条SQL语句中可能多次使用到的表,可以对其进行缓存,使用SQLContext.cacheTable(tableName)或者DataFr ame.cache即可。Spark SQL会用内存 列存储的格式进行表的缓存。然后SparkSQL就可以仅仅扫描需要使用的列,并 且自动优化压缩,来最小化内存使用和GC开销。可以通过spark.sql.inMemoryColumnarStorage.batchSize这个参数, 默认10000,配置列存储单位
- sparkSql参数调优
A. Spark.sql.codegen 默认false 若设置为true,Spark SQL会将每个查询都编译为Java字节码。当查询量较大时, 这样的设置能够改进查询性能,但不适用于查询量小的情形
B. spark.sql.inMemoryColumnarStorage.compressed 默认true置为true时,会根据统计信息自动为每列选择压缩存储
c.spark.sql.inMemoryColumnarStorage.batchSize 默认10000 需要视存储数据量而定,若此值设置过大,可能导 致内存溢出。
D .spark.sql.shuffle.partitions 默认200 配置连接或聚合数据移动数据时要使用的分区数。
D. spark.sql.parquet.compression.codec 默认snappy 可以设置多种编码方式,除了snappy外,还可以设置为 uncompressed,gzip和lzo
*注意 D 想是我之前给你们说过的数据的压缩方式,你们可以说gzip。sparkSql默认是snappy的方式。
这些选项可以放在配置文件中,也可以以编程方式设置SQLContext。例如:
val sqlContext = new SQLContext(sc)
sqlContext.setConf("spark.sql.codegen", true) sqlContext.setConf("spark.sql.inMemoryColumnarStorage.batchSize", "10000")
当把spark.sql.codegen设置为true时,由于需要初始化编译器,在第一次执行查询时,可能会影响查询性能。
5.基于SparlSql提供的优化器cataLyst进行优化。这是基于Scala的函数式编程元素。它提供的语法解析功能通过创建表达式树对 语法进行解析,每种数据类型和操作都可以视为表达式树的一种节点。这些节点皆继承自TreeNode抽象类。
6.spark.scheduler.mode 为 FAIR 模式,首先 spark.scheduler.mode 有 FIFO, FAIR 两种模式,FIFO 是说提交的job,都是 顺序执行的,后提交的 job 一定要等之前提交的 job 完全执行结束后才可以执行;FAIR 是说,如果之前提交的 job 没有 用完集群资源的话,后提交的job可以即刻开始运行。