基于Xgboost的移动业务室内室外预测
比赛背景
利用大数据中心整理的一份包括基站、通话时间、通话时长,标签为室内、室外可公开的数据集(数量达12000条),运用机器学习方法预测用户分布是处于室内或者室外,帮助移动业务相关参数配置分析和优化。
问题定位
特征字段含义解释
| 字段 | 含义 |
|---|---|
| reportcellkey | 小区cellID,基站编号和小区编号的组合 |
| strongestnbpci | 小区PCI,范围0~503 |
| aoa | angle of arrival入射角度 |
| ta_calc | 时延 |
| rsrp | 测试功率值 |
| rsrq | 测量质量值 |
| ta | 时延 |
| tadltvalue | 下行时延 |
| mrtime | MR上报时间 |
| imsi | IMSI用户,做了脱敏 |
| ndskey | NDS数据服务器的归属key |
| uerecordid | 用户记录ID |
| starttime | 业务开始时间 |
| endtime | 业务结束时间 |
| positionmark_real | 室内室外,1:室内,2:室外 |
Import Libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
# from scipy.stats import mode导入数据
data_train = pd.read_csv("IndoorOutdoorPredict.csv",header=0)
data_test = pd.read_csv("test_data.csv",header=0)
data_train.head()| reportcellkey | strongestnbpci | aoa | ta_calc | rsrp | rsrq | ta | tadltvalue | mrtime | imsi | ndskey | uerecordid | starttime | endtime | positionmark_real | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 240877_2 | 226 | 235 | 3.1250 | -97 | -6.5 | 3 | 34 | 2017/2/23 20:41 | 4.600000e+14 | null | 003ACED20452DA84 | 2017/2/23 20:35 | 2017/2/23 20:56 | 0 |
| 1 | 240877_2 | 225 | 242 | 1.7500 | -101 | -7 | 2 | 28 | 2017/2/23 21:10 | 4.600000e+14 | null | 003ACEDE02959A4A | 2017/2/23 21:00 | 2017/2/23 21:11 | 0 |
| 2 | 64638_1 | 330 | 88 | 1.5625 | -93 | -6 | 2 | 25 | 2017/2/21 15:22 | 4.600000e+14 | null | 000FC7E0F5E63D49 | 2017/2/21 15:09 | 2017/2/21 15:25 | 0 |
| 3 | 240877_2 | null | 248 | 3.1875 | -95 | -6.5 | 3 | 35 | 2017/2/23 21:08 | 4.600000e+14 | null | 003ACEDBC3068F92 | 2017/2/23 20:58 | 2017/2/23 21:17 | 0 |
| 4 | 254892_2 | null | 220 | 22.6250 | null | null | 22 | 42 | 2017/2/22 11:05 | 4.600000e+14 | null | 003E3AC0CDAC941A | 2017/2/22 10:47 | 2017/2/22 11:08 | 0 |
数据规模 10000+ 特征 14 ,可见原始数据的规模并不大,可以通过单机来完成分析工作。目标字段positionmark_real是预测用户位于室内还是室外,是一个二分类问题。
数据预处理
检查数据类型
data_train.dtypesreportcellkey object
strongestnbpci object
aoa object
ta_calc float64
rsrp object
rsrq object
ta int64
tadltvalue int64
mrtime object
imsi float64
ndskey object
uerecordid object
starttime object
endtime object
positionmark_real int64
dtype: object
检查缺失值
import numpy as np
data_train.replace('null', np.nan, inplace=True)
data_test.replace('null', np.nan, inplace=True)
data_train.apply(lambda x: sum(x.isnull())),data_test.apply(lambda x: sum(x.isnull()))(reportcellkey 0
strongestnbpci 2657
aoa 116
ta_calc 0
rsrp 225
rsrq 225
ta 0
tadltvalue 0
mrtime 0
imsi 0
ndskey 10698
uerecordid 0
starttime 0
endtime 0
positionmark_real 0
dtype: int64, reportcellkey 0
strongestnbpci 508
aoa 26
ta_calc 0
rsrp 40
rsrq 40
ta 0
tadltvalue 0
mrtime 0
imsi 0
ndskey 2062
starttime 0
endtime 0
positionmark_real 2062
dtype: int64)
data_train.shape,data_test.shape((10698, 15), (2062, 14))
drop掉uerecordid列
通过观察,测试集没有该列,所以这列特征不能用。
data_train.drop('uerecordid',axis=1,inplace=True)处理ndskey列
该列全部为null 直接drop掉
data_train.drop('ndskey',axis=1,inplace=True)
data_test.drop('ndskey',axis=1,inplace=True)处理 aoa列
该列缺失值不是很多,尝试用均值填充
data_train[['aoa']]=data_train[['aoa']].astype('float32')
data_test[['aoa']]=data_test[['aoa']].astype('float32')
data_train['aoa'].describe(),data_test['aoa'].describe()(count 10582.000000
mean 177.791718
std 96.962294
min 0.000000
25% 103.000000
50% 206.000000
75% 248.000000
max 359.000000
Name: aoa, dtype: float64, count 2036.000000
mean 178.873276
std 97.544271
min 0.000000
25% 105.000000
50% 209.000000
75% 248.000000
max 359.000000
Name: aoa, dtype: float64)
data_train['aoa'].replace(np.nan,177.791718,inplace=True)
data_test['aoa'].replace(np.nan,178.873276,inplace=True)处理rsrq rsrp
转换类型为float32 并用均值填充缺失值
data_train[['rsrp']] = data_train[['rsrp']].astype('float32')
data_train[['rsrq']] = data_train[['rsrq']].astype('float32')
data_test[['rsrp']] = data_test[['rsrp']].astype('float32')
data_test[['rsrq']] = data_test[['rsrq']].astype('float32')
data_train['rsrp'].describe(),data_train['rsrq'].describe(),data_test['rsrp'].describe(),data_test['rsrq'].describe()(count 10473.000000
mean -92.272797
std 12.115891
min -131.000000
25% -102.000000
50% -94.000000
75% -84.000000
max -48.000000
Name: rsrp, dtype: float64, count 10473.000000
mean -8.449012
std 2.264931
min -20.000000
25% -10.000000
50% -8.500000
75% -6.500000
max -3.000000
Name: rsrq, dtype: float64, count 2022.000000
mean -92.339760
std 12.019746
min -126.000000
25% -101.000000
50% -94.000000
75% -83.000000
max -56.000000
Name: rsrp, dtype: float64, count 2022.000000
mean -8.559594
std 2.271767
min -20.000000
25% -10.000000
50% -8.500000
75% -7.000000
max -4.000000
Name: rsrq, dtype: float64)
data_train['rsrp'].replace(np.nan,-92.272797,inplace=True)
data_train['rsrq'].replace(np.nan,-8.449012,inplace=True)
data_test['rsrp'].replace(np.nan,-92.339760,inplace=True)
data_test['rsrq'].replace(np.nan,-8.559594,inplace=True)处理strongestnbpci列
小区PCI当做类别处理 缺失值尝试填充众数
pd.value_counts(data_train['strongestnbpci']),pd.value_counts(data_test['strongestnbpci'])(226 684
216 457
88 352
274 285
271 282
268 275
5 263
37 255
227 204
419 198
9 196
59 183
225 148
228 141
132 134
2 133
211 124
417 122
367 121
402 117
0 113
20 110
404 109
38 103
330 100
35 95
391 94
11 75
273 74
4 74
...
277 1
179 1
279 1
454 1
361 1
416 1
128 1
385 1
60 1
205 1
431 1
430 1
14 1
373 1
13 1
257 1
439 1
236 1
500 1
465 1
30 1
39 1
144 1
107 1
143 1
178 1
351 1
289 1
319 1
405 1
Name: strongestnbpci, Length: 322, dtype: int64, 226 137
216 72
88 71
271 56
268 56
37 54
274 52
227 46
9 45
5 40
59 35
402 35
419 31
228 30
225 29
2 28
211 24
132 24
367 23
417 22
20 21
0 19
35 16
273 15
38 15
404 14
330 14
3 14
391 12
33 11
...
384 1
199 1
368 1
247 1
245 1
362 1
305 1
447 1
303 1
333 1
62 1
487 1
99 1
255 1
220 1
392 1
471 1
13 1
96 1
166 1
188 1
69 1
185 1
299 1
297 1
337 1
418 1
173 1
288 1
101 1
Name: strongestnbpci, Length: 216, dtype: int64)
data_train['strongestnbpci'].replace(np.nan,'226',inplace=True)
data_test['strongestnbpci'].replace(np.nan,'216',inplace=True)处理IMSI列
该列取值差异大,没有相同取值,对构建模型无用,drop
pd.value_counts(data_train['imsi']),pd.value_counts(data_test['imsi'])(4.600000e+14 10698
Name: imsi, dtype: int64, 4.600000e+14 2062
Name: imsi, dtype: int64)
data_train.drop('imsi',axis=1,inplace=True)
data_test.drop('imsi',axis=1,inplace=True)处理starttime,endtime,mrtime列
转换为时间类型,读入时会默认为字符串类型。
data_train["starttime_"]=pd.to_datetime(data_train["starttime"])
data_train["endtime_"]=pd.to_datetime(data_train["endtime"])
data_train["mrtime_"]=pd.to_datetime(data_train["mrtime"])
data_test["starttime_"]=pd.to_datetime(data_test["starttime"])
data_test["endtime_"]=pd.to_datetime(data_test["endtime"])
data_test["mrtime_"]=pd.to_datetime(data_test["mrtime"])观察reportcellkey特征
pd.value_counts(data_train['reportcellkey']) # 可作为类别特征240768_4 1046
240877_2 996
260284_2 665
263135_128 618
254892_2 600
240770_2 391
254892_0 306
240772_1 295
240688_3 280
240795_2 239
240792_6 239
240877_1 226
254850_1 221
64648_1 213
254823_2 201
254850_2 198
756794_128 174
64638_1 153
254792_1 149
240770_5 149
240792_5 146
254890_2 115
240831_4 115
254823_0 110
240771_2 95
240768_0 85
920496_130 81
254831_1 75
254850_4 65
240818_2 55
...
240825_1 1
240768_2 1
5274_129 1
240803_2 1
240846_2 1
254791_8 1
240643_5 1
240643_7 1
240643_0 1
240643_2 1
254791_2 1
263115_129 1
263115_128 1
5275_129 1
240642_2 1
240695_3 1
5318_144 1
240697_1 1
240847_4 1
264004_128 1
240878_2 1
263139_128 1
756794_130 1
240687_2 1
254791_11 1
240644_10 1
64648_2 1
240694_3 1
240694_5 1
240847_1 1
Name: reportcellkey, Length: 298, dtype: int64
data_train.dtypesreportcellkey object
strongestnbpci object
aoa float32
ta_calc float64
rsrp float32
rsrq float32
ta int64
tadltvalue int64
mrtime object
starttime object
endtime object
positionmark_real int64
starttime_ datetime64[ns]
endtime_ datetime64[ns]
mrtime_ datetime64[ns]
dtype: object
data = pd.concat([data_train,data_test])
data.shape将datetime类型的feature转换为更有物理含义的特征
data['start_minute']=data['starttime_'].apply(lambda x:x.minute)
data['start_day']=data['starttime_'].apply(lambda x:x.day)
data['start_hour']=data['starttime_'].apply(lambda x:x.hour)
data['end_hour']=data['endtime_'].apply(lambda x:x.hour)
data['end_minute']=data['endtime_'].apply(lambda x:x.minute)
data['end_day']=data['endtime_'].apply(lambda x:x.day)
data['mrtime_hour']=data['mrtime_'].apply(lambda x:x.hour)
data['mrtime_minute']=data['mrtime_'].apply(lambda x:x.minute)
data['mrtime_day']=data['mrtime_'].apply(lambda x:x.day)
data['time_delta']=data['endtime_'] - data_train['starttime_']
data['time_delta_in_seconds']= data['time_delta'].apply(lambda x: x.seconds)Drop 掉无用特征
# data = data.drop(['starttime','endtime','starttime_','endtime_','mrtime','mrtime_','time_delta'],axis=1)
data = data.drop(['starttime','endtime','starttime_','endtime_','mrtime','mrtime_'],axis=1)Numerical Coding:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
var_to_encode = ['reportcellkey']
for col in var_to_encode:
data[col] = le.fit_transform(data[col])One-Hot Coding
对于不好处理的类别型列 reportcellkey 进行One-Hot编码
data = pd.get_dummies(data, columns=var_to_encode)
data.columnsIndex([u'strongestnbpci', u'aoa', u'ta_calc', u'rsrp', u'rsrq', u'ta',
u'tadltvalue', u'positionmark_real', u'start_minute', u'start_day',
...
u'reportcellkey_292', u'reportcellkey_293', u'reportcellkey_294',
u'reportcellkey_295', u'reportcellkey_296', u'reportcellkey_297',
u'reportcellkey_298', u'reportcellkey_299', u'reportcellkey_300',
u'reportcellkey_301'],
dtype='object', length=319)
Generate final dataset
data.to_csv('data_is_ready_formal_version_full.csv',index=False)
data_train.to_csv('data_is_ready_formal_version_train.csv',index=False)
data_test.to_csv('data_is_ready_formal_version_test.csv',index=False)data.head()| strongestnbpci | aoa | ta_calc | rsrp | rsrq | ta | tadltvalue | positionmark_real | start_minute | start_day | … | reportcellkey_292 | reportcellkey_293 | reportcellkey_294 | reportcellkey_295 | reportcellkey_296 | reportcellkey_297 | reportcellkey_298 | reportcellkey_299 | reportcellkey_300 | reportcellkey_301 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 226 | 235.0 | 3.1250 | -97.000000 | -6.500000 | 3 | 34 | 0.0 | 35 | 23 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 225 | 242.0 | 1.7500 | -101.000000 | -7.000000 | 2 | 28 | 0.0 | 0 | 23 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 330 | 88.0 | 1.5625 | -93.000000 | -6.000000 | 2 | 25 | 0.0 | 9 | 21 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 226 | 248.0 | 3.1875 | -95.000000 | -6.500000 | 3 | 35 | 0.0 | 58 | 23 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 226 | 220.0 | 22.6250 | -92.272797 | -8.449012 | 22 | 42 | 0.0 | 47 | 22 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 319 columns
模型训练与预测
Import Libraries
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost.sklearn import XGBClassifier
from xgboost import plot_tree
from sklearn import cross_validation, metrics
from sklearn.grid_search import GridSearchCV
import matplotlib.pylab as plt
%matplotlib inline
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 20,10Load Data:
The data has gone through following pre-processing:
data = pd.read_csv('data_is_ready_formal_version_full.csv')
data.head()| strongestnbpci | aoa | ta_calc | rsrp | rsrq | ta | tadltvalue | positionmark_real | start_minute | start_day | … | reportcellkey_292 | reportcellkey_293 | reportcellkey_294 | reportcellkey_295 | reportcellkey_296 | reportcellkey_297 | reportcellkey_298 | reportcellkey_299 | reportcellkey_300 | reportcellkey_301 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 226 | 235.0 | 3.1250 | -97.000000 | -6.500000 | 3 | 34 | 0.0 | 35 | 23 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 225 | 242.0 | 1.7500 | -101.000000 | -7.000000 | 2 | 28 | 0.0 | 0 | 23 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 330 | 88.0 | 1.5625 | -93.000000 | -6.000000 | 2 | 25 | 0.0 | 9 | 21 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 226 | 248.0 | 3.1875 | -95.000000 | -6.500000 | 3 | 35 | 0.0 | 58 | 23 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 226 | 220.0 | 22.6250 | -92.272797 | -8.449012 | 22 | 42 | 0.0 | 47 | 22 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5 rows × 319 columns
data.shape(12760, 319)
data.columnsIndex([u'strongestnbpci', u'aoa', u'ta_calc', u'rsrp', u'rsrq', u'ta',
u'tadltvalue', u'positionmark_real', u'start_minute', u'start_day',
...
u'reportcellkey_292', u'reportcellkey_293', u'reportcellkey_294',
u'reportcellkey_295', u'reportcellkey_296', u'reportcellkey_297',
u'reportcellkey_298', u'reportcellkey_299', u'reportcellkey_300',
u'reportcellkey_301'],
dtype='object', length=319)
target = 'positionmark_real'
data['positionmark_real'].value_counts()0.0 7740
1.0 2958
Name: positionmark_real, dtype: int64
data_train = data[:10698]
data_test = data[10698:]# 初始化为0 后续替换为真实预测值
data_test['positionmark_real']=0/root/anaconda2/lib/python2.7/site-packages/ipykernel/__main__.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
from ipykernel import kernelapp as app
定义函数用来训练模型和交叉验证
函数包含以下功能:
1. 训练模型
2. 计算训练精度
3. 计算训练AUC值
4. 通过xgboost包的交叉验证,更新弱分类器个数n_estimators为最佳。
5. 绘制feature importance图
def modelfit(alg,dtrain,dtest, predictors, cv_folds=5, early_stopping_rounds=50):
xgb_param = alg.get_xgb_params()
xgtrain = xgb.DMatrix(dtrain[predictors].values, label=dtrain[target].values)
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=alg.get_params()['n_estimators'], nfold=cv_folds,metrics=['auc'],
early_stopping_rounds=early_stopping_rounds)
print cvresult.shape[0]
alg.set_params(n_estimators=cvresult.shape[0])
#Fit the algorithm on the data
alg.fit(dtrain[predictors], dtrain['positionmark_real'],eval_metric='auc')
#Predict training set:
dtrain_predictions = alg.predict(dtrain[predictors])
dtrain_predprob = alg.predict_proba(dtrain[predictors])[:,1]
dtest_predictions = alg.predict(dtest[predictors])
#Print model report:
print "\nModel Report"
print "Accuracy : %.4g" % metrics.accuracy_score(dtrain['positionmark_real'].values, dtrain_predictions)
print "AUC Score (Train): %f" % metrics.roc_auc_score(dtrain['positionmark_real'], dtrain_predprob)
feat_imp = pd.Series(alg.booster().get_fscore()).sort_values(ascending=False)
feat_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')
return dtest_predictions,algFind the number of estimators for a high learning rate
predictors = [x for x in data.columns if x != target]
xgb1 = XGBClassifier(
learning_rate =0.1,
n_estimators=1000,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
seed=27)
data_test[target],model = modelfit(xgb1, data_train, data_test, predictors)Will train until cv error hasn't decreased in 50 rounds.
Stopping. Best iteration: 87
88
Model Report
Accuracy : 1
AUC Score (Train): 1.000000
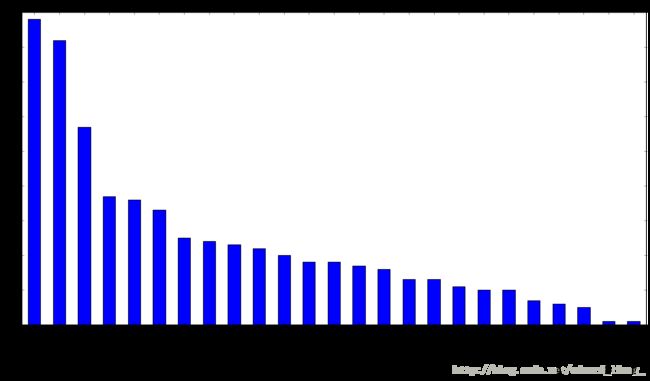
经验与不足
1.特征工程中缺少更加精确的特征选择步骤,导致代码执行的效率不够高。一个比较完整的特征工程如下图所示,特别应该引起注意的是特征选择步骤。 
2.使用xgboost调参前,应该尽可能的缩小特征规模(也就是做好特征选择),并且考虑用后台执行(notebook经常会出现页面假死)
3.xgboost调参的基本流程总结如下:
- 初始化学习率 得到estimator的数量
- 对 max_depth和min_weight进行grid search,他们对最终结果会有很大影响。
- 调整gamma参数
- 调整subsample和colsample_bytree参数
- 正则化参数调优:alpha和lambda
- 进一步降低学习率,增加树的数量,得到最佳参数。