Pandas引言(二)
DataFrame的基本操作
读取数据集
import pandas as pd
import numpy as np
titanic_survival = pd.read_csv('titanic_train.csv')
titanic_survival.head()

查看 Age 列的缺失值情况
age = titanic_survival['Age']
pd.isnull(age).loc[:6]
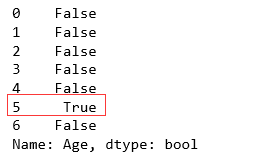
使用布尔型Series过滤缺失值
age_not_null = age[age.isnull() == False]
age_not_null.loc[:6]

使用布尔型Series选取DataFrame
titanic_survival[age.isnull() == False].tail()

使用 dropna 方法过滤缺失值
titanic_survival.dropna(subset=['Age']).tail()

计算年龄的均值
通过 isnull 方法我们已确定 Age 列存在缺失值,需要注意的是,NAN和任何值做计算时,结果都为NAN:

所以在对某一列做求和,求均值等操作时,需先过滤掉缺失值:
# 计算年龄平均值
age_null = titanic_survival["Age"].isnull()
age = titanic_survival["Age"][age_null == False]
mean_age = sum(age) / len(age)
mean_age
![]()
使用 mean 方法可以很方便地计算均值:

重复值过滤
使用 duplicated 方法查看重复项(True为已经出现过的重复记录):
titanic_survival.duplicated(subset=['Sex']).head()

除了指定 subset 参数,还可以使用如下的方式:
titanic_survival['Sex'].duplicated().head()
此外,还可以指定多个列,用于判定重复。下面我们过滤Sex和Age列重复的项:
titanic_survival[titanic_survival.duplicated(subset=['Sex', 'Age']) == False].shape
等价于:
titanic_survival.drop_duplicates(subset=['Sex', 'Age']).shape

分组与聚合操作
使用纯 python 计算每类 Pclass 的平均 Fare 值:
# 分组与聚合:计算每类旅客的平均票价,分组即:按旅客类型分组;聚合即:求每组的平均值
passenger_classes = set(titanic_survival["Pclass"])
ava_fares = {}
for _class in passenger_classes:
pclass_rows = titanic_survival[titanic_survival['Pclass'] == _class]
pclass_fares = pclass_rows['Fare']
ava_fare = pclass_fares.mean()
ava_fares[_class] = ava_fare
ava_fares
![]()
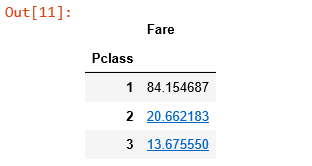
使用 pandas 的数据透视表 pivot_table ,根据 Pclass 分组,对 Fare 列使用 np.mean 进行聚合:
titanic_survival.pivot_table(index='Pclass', values='Fare', aggfunc=np.mean)
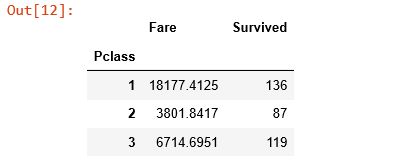
此外,还可以对多个列进行聚合:
titanic_survival.pivot_table(index='Pclass', values=['Fare', 'Survived'], aggfunc=np.sum)
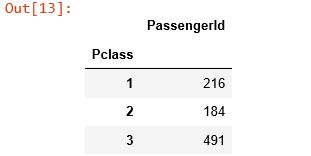
aggfunc 除了指定为 numpy 中的聚合函数外,还可以其它符合条件的函数,可以应用到Series,返回单个值:
titanic_survival.pivot_table(index='Pclass', values='PassengerId', aggfunc=len)
df.apply() 方法的参数和 aggfunc 指定的函数是同类函数,只不过df.apply()会将此函数应用到所有的列:
def no_100_row(column):
no_100 = column.iloc[99]
return no_100
# 对DataFrame的每一列应用上述函数
titanic_survival.apply(no_100_row)
方法总结
| 方法 | 说明 |
|---|---|
| pandas.isnull() / series.isnull() | 返回是否为空的 bool 型的 Series 对象(备注:DataFrame 和 Series 都可以通过 bool 型的Series取值,bool型的 Series 和 True/False 进行比较,可用于数据过滤) |
| series.mean() | 自动过滤缺失值,再求平均值 |
| df.pivot_table(index=“列名1”, values=“列名2”/[“列名2”,“列名3”,…], aggfunc=聚合函数) | 实现分组、聚合处理;index指定分组依据的列;values指定对哪几个列做聚合统计运算;aggfunc指定用于series的聚合函数。 |
| df.dropna(axis=1) / df.dropna(axis=‘column’) | 删除存在缺失值的列 |
| df.dropna(axis=0, subset=[‘columns1’, ‘columns2’, …]) | 删除指定列存在缺失值的记录 |
| df.duplicated(subset=None, keep=‘first’) | 返回一个表示记录是否重复的 bool 型 Series。subset 指定比较的列,keep默认为 first ,表示将首次出现的重复记录标记为 False ,其它位置则为 True;keep = last,则表示只将重复值最后出现的位置标记为 False;keep=False,则表示将所有重复的记录均标记为 True。 |
| df.drop_duplicates(subset=None, keep=‘first’, inplace=False) | 返回去重的dataframe,subset指定去重的列,keep可以为’first’、‘last’、False,分别代表保留重复项首次出现的记录、最后一次出现的记录,False则表示删除任何重复记录 |
| df.sortvalues(‘列名’, inplace=False, ascending=True) | 返回一个新的升序dataframe |
| reset_index(drop=True) | 用于排序后重置索引 |
| .loc[行索引,列索引] | 获取指定值 |