面试题-05:ConcurrentHashMap & HashMap & Collections.synchronizedMap
文章目录
- 1. 线程安全集合类
- 1. HashTab与Vector
- 2. Collections.synchronizedMap
- 3. ConcurrentHashMap
- 2. ConcurrentHashMap原理
- 1. JDK 7 HashMap 并发死链
- 2. JDK 8 ConcurrentHashMap
1. 线程安全集合类

1. HashTab与Vector
通过这里的部分源码可以看出:HashTable中几乎所有的方法都使用synchronized修饰的,并发性能较低,不推荐使用
public synchronized int size() {
return count;
}
public synchronized boolean isEmpty() {
return count == 0;
}
public synchronized Enumeration<K> keys() {
return this.<K>getEnumeration(KEYS);
}
public synchronized Enumeration<V> elements() {
return this.<V>getEnumeration(VALUES);
}
public synchronized boolean contains(Object value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<?,?> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
public boolean containsValue(Object value) {
return contains(value);
}
2. Collections.synchronizedMap
将原本线程不安全的线程集合类变成线程安全的,看源码:
synchronizedMap(Map中传入一个线程不安全的Map,然后对其进行包装,如何进行包装?
synchronizedMap实现了Map接口,将里面所有的方法重写了一遍,但是这些方法里直接调用的是传入的线程不安全的集合类中的方法,自己本身并没有实现,只是调用的传入的线程集合类中的方法,只不过多加了synchronized修饰。(装饰器模式),因此并发性能较低。
//传入的是一个线程不安全的集合Map,将其进行包装变成线程安全的
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
//如何进行包装的?
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
public void putAll(Map<? extends K, ? extends V> map) {
synchronized (mutex) {m.putAll(map);}
}
public void clear() {
synchronized (mutex) {m.clear();}
}
}
3. ConcurrentHashMap

2. ConcurrentHashMap原理
1. JDK 7 HashMap 并发死链
1、HashMap的数据结构为数组加链表,当一个元素放入集合时,会计算key的Hash值,即hash(key),然后对数组的大小进行按位与运算计算一个桶下标(索引)。然后将key放入数组对应的桶下标索引处,将key尽可能的分散在不同的桶下标下面,可以让查找更加快速,时间复杂度为O(1)
2、但是不同的key也有可能计算出相同的桶下标(索引),此时需要通过equals()方法来查找key,虽然查找性能会有损失,但是可以解决桶下标冲突。
3、JDK7中后加入的元素会放在链表的头部,这也是死链差生的原因。

4、死链的并发问题会发在扩容的时候,随着数组内元素越来越多,必然导致链表的长度也越来越长,查找性能就会受到影响,jdk7和jdk8都是在数组长度超过一个阈值时就会发生扩容,这个阈值就是数组的长度的四分之三(12)发生扩容,扩容的方式会重新计算桶下标,让容量翻倍:
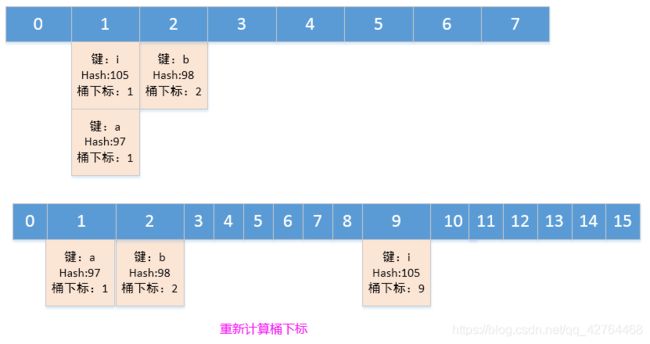
5、但是在多线程下面,会因为数组的扩容导致并发死链的问题:
究其原因,是因为在多线程环境下使用了非线程安全的 map 集合
JDK 8 虽然将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序),但仍不意味着能够在多线程环境下能够安全扩容,还会出现其它问题(如扩容丢数据)
2. JDK 8 ConcurrentHashMap
1、重要属性和内部类:
// 默认为 0
// 当初始化时, 为 -1
// 当扩容时, 为 -(1 + 扩容线程数)
// 当初始化或扩容完成后,为 下一次的扩容的阈值大小
private transient volatile int sizeCtl;
// 整个 ConcurrentHashMap 就是一个 Node[]
static class Node<K,V> implements Map.Entry<K,V> {}
Node节点中的四个属性:

// hash 表
transient volatile Node<K,V>[] table;
// 扩容时的新 hash 表
private transient volatile Node<K,V>[] nextTable;
// 扩容时如果某个 bin 迁移完毕, 用 ForwardingNode 作为旧 table bin 的头结点
static final class ForwardingNode<K,V> extends Node<K,V> {}

如果链表过长,查找的速率是比较低的,时间复杂度就会从o(1)退化成O(n),为了提升查找效率可以使用红黑树的数据结构替换掉链表结构。红黑树除了能提升查找效率外还能防止DOS的攻击。如何做?
链表的长度阈值为8,当链表的长度超过8时,就会从链表装换为红黑树,在转换之前如果链表的长度还没到达64会先进行扩容,因为扩容也可以减少链表的长度,当扩容到64并且链表的长度大于8时就会从链表转换为红黑树,如果红黑树的节点数小于6时,又会从红黑树转换为链表。
// 作为 treebin 的头节点, 存储 root 和 first
static final class TreeBin<K,V> extends Node<K,V> {}
// 作为 treebin 的节点, 存储 parent, left, right
static final class TreeNode<K,V> extends Node<K,V> {}
2、重要方法:
// 获取 Node[] 中第 i 个 Node
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i)
// cas 修改 Node[] 中第 i 个 Node 的值, c 为旧值, v 为新值
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v)
// 直接修改 Node[] 中第 i 个 Node 的值, v 为新值
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v)
3、构造器分析:
可以看到实现了懒惰初始化,在构造方法中仅仅计算了 table 的大小,以后在第一次使用时才会真正创建

4、get方法:

5、put方法:








