【论文笔记】端到端文本检测与识别——FOTS
常见的深度学习OCR过程中,会把文本检测与文本识别拆分成两个部分,通过先检测后识别的方法对图片中的文本进行OCR识别。在商汤的paper中,一种新的端到端快速检测识别模型给了我们一个很大的惊喜。
【论文题目】FOTS: Fast Oriented Text Spotting with a Unified Network
【摘要】偶然的场景文本定位被认为是文档分析社区中最困难和最有价值的挑战之一。大多数现有方法将文本检测和识别视为单独的任务。在这项工作中,我们提出了一个统一的端到端可训练的快速定向文本定位(FOTS)网络,用于在两个互补任务之间同时检测和识别,共享计算和视觉信息。特别地,引入RoIRotate以在检测和识别之间共享卷积特征。受益于卷积分析策略,与基线文本检测网络相比,我们的FOTS具有很少的计算开销,并且联合训练方法学习更多通用特征以使我们的方法比这两个阶段方法表现更好。 ICDAR 2015,ICDAR 2017 MLT和ICDAR 2013数据集上的实验证明,所提出的方法显着优于最先进的方法,这进一步使我们能够开发出第一个面向实时的文本定位系统在保持22.6 fps的同时,ICDAR 2015文本定位任务超过了所有先前的最新成果超过5%。
【亮点】端到端快速文本检测识别、提出了RoIRotate
FOTS是一个快速的端到端的集成检测+识别的框架,和其他two-stage的方法相比,FOTS具有更快的速度。FOTS通过共享训练特征,互补监督,从而压缩了特征提取所占用的时间。

上图,蓝色框为FOTS,红色框为其他two-stage方法,可以看出FOTS消耗的时间是two-stage时间的一半。
1 模型整体结构
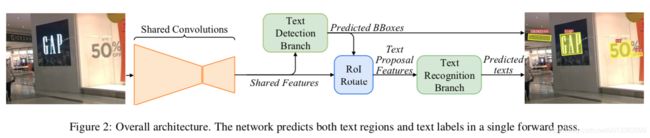
FOTS的整体结构由四部分组成。分别是:卷积共享特征(shared convolutions),文本检测分支(the text detection branch), RoIRotate操作(RoIRotate operation),文本识别分支(the text recognition branch)。
2 四部分结构及实现细节
2.1 卷积共享(shared convolutions)
共享网络的主干是 ResNet-50。 受FPN的启发,我们连接了低级特征映射和高级语义特征映射。 共享卷积产生的特征图的分辨率是输入图像的1/4。

FOTS的基础网络结构为ResNet-50,共享卷积层采用了类似U-net的卷积的共享方法,将底层和高层的特征进行了融合。这部分和EAST中的特征共享方式一样。最终输出的特征图大小为原图的1/4。
2.2 文本检测分支(the text detection branch)
受EAST与DDRN的启发,我们采用完全卷积网络作为文本检测器。 由于自然场景图像中有许多小文本框,我们将共享卷积中原始输入图像的1/32到1/4大小的特征映射放大。 在提取共享特征之后,应用一个转换来输出密集的每像素的单词预测。 第一个通道计算每个像素为正样本的概率。 与EAST类似,原始文本区域的缩小版本中的像素被认为是正的。 对于每个正样本,以下4个通道预测其到包含此像素的边界框的顶部,底部,左侧,右侧的距离,最后一个通道预测相关边界框的方向。 通过对这些正样本应用阈值和NMS产生最终检测结果。
这一部分与EAST相同。损失函数包括了分类的loss(Cross Entropy Loss)和坐标的回归的loss(IOU Loss)。实验中的平衡因子,λreg =1。
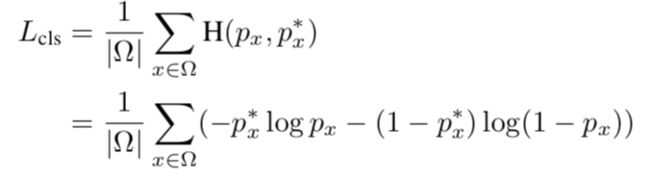
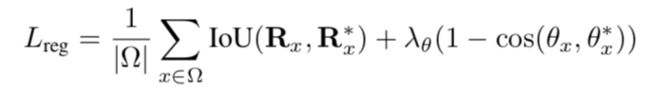
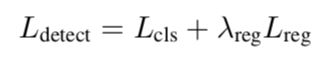
2.3 RoIRotate操作(RoIRotate operation)
这一部分的主要功能,将有角度的文本块,经过仿射变换,转化为正常的轴对齐的文本块。
在这项工作中,我们修正输出高度并保持纵横比不变以处理文本长度的变化。对比RRoI,其通过最大池化将旋转的区域转换为固定大小的区域,而本文使用双线性插值来计算输出的值。避免了RoI与提取特征不对准,使得输出特征的长度可变,更加适用于文本识别。这个过程分为两个步骤:①通过文本提议的预测或ground truth坐标计算仿射变换参数。②将仿射变换分别应用于每个区域的共享特征映射,并获得文本区域的正常情况下水平的特征映射。
第①步中的计算:
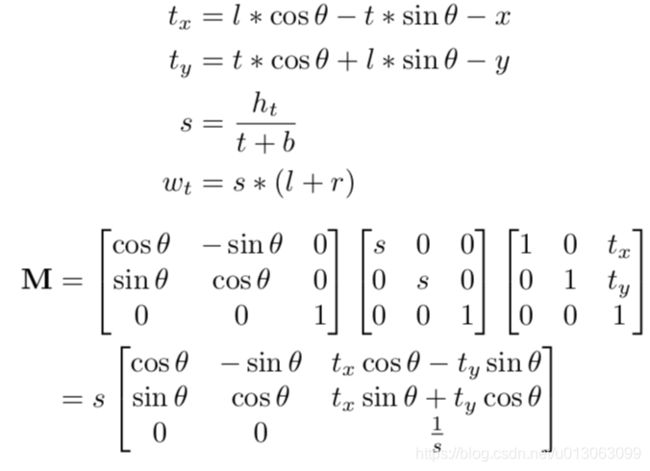
M:仿射变换矩阵,包含旋转,缩放,平移
Ht:仿射变换后的特征图的高度,实验中为8
wt:仿射变换后的特征图的宽度
(x,y):特征图中的点的位置
(t; b; l; r) :特征图中的点距离旋转的框的上下左右的距离
θ:检测框的角度
第②步中的计算:
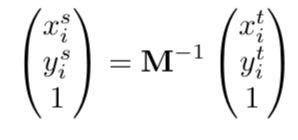

Vcij:在位置(i,j),通道c处的输出值。
Ucnm:在位置(i,j),通道c处的输入值。
hs:输入的高度
ws:输入的宽度
Φx, Φy :双线性插值的核的参数
2.4 文本识别分支(the text recognition branch)
文本识别分支旨在使用由共享卷积提取并由RoIRotate转换的区域特征来预测文本标签。 考虑到文本区域中标签序列的长度,LSTM的输入特征沿着宽度轴通过原始图像的共享卷积仅减少两次。 否则,将消除紧凑文本区域中的可辨别特征,尤其是窄形字符的特征。 我们的文本识别分支包括类似VGG的顺序卷积,仅沿高度轴减少的汇集,一个双向LSTM,一个完全连接和最终的CTC解码器。
这一部分主要是与CRNN类似,结构如下图所示。

FOTS最终的损失函数是检测+识别的loss,λrecog=1。
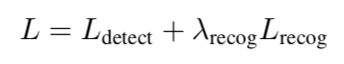
2.5 实现细节
我们使用ImageNet数据集训练的模型作为我们预先训练的模型。 训练过程包括两个步骤:首先我们使用Synth800k数据集训练网络10个epoch,然后采用实际数据对模型进行微调直到收敛。 不同的任务采用不同的训练数据集。 ICDAR 2015和ICDAR 2017 MLT数据集中的一些模糊文本区域被标记为“DO NOT CARE”,我们在训练中忽略它们。
数据增强对于深度神经网络的鲁棒性很重要,特别是当真实数据的数量有限时。 首先,图像的较长边从640像素调整为2560像素。 接下来,图像随机旋转[-10°,10°]范围。 然后,图像的高度以0.8到1.2的比例重新缩放,同时它们的宽度保持不变。 最后,从变换的图像中裁剪640×640个随机样本。
3 实验效果
3.1 ICDAR2015结果

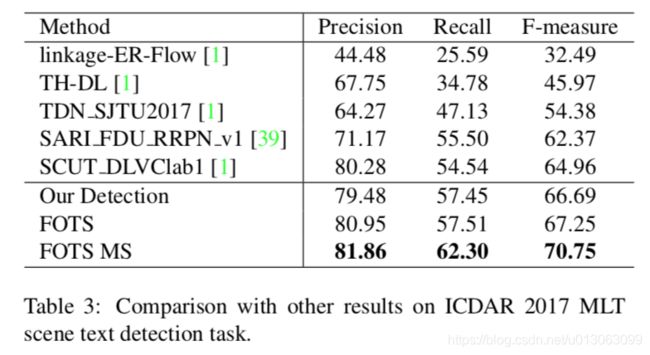
3.2 ICDAR2017 MLT结果
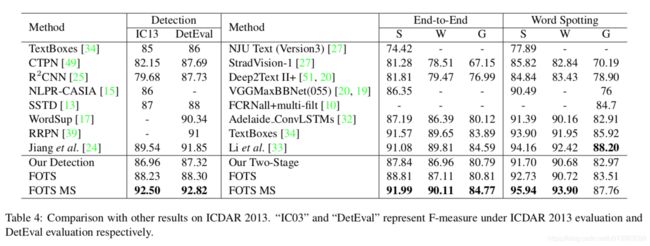
3.3 ICDAR2013结果
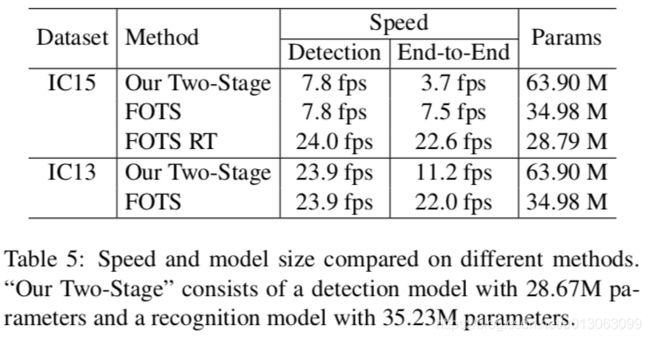
3.4 速度和模型大小
4 总结
FOTS一个检测+识别一体化的框架,具有模型小,速度快,精度高,支持多角度等特点。大大减少了这四种类型的错误(Miss:遗漏了一些文本区域;False:将一些非文本区域错误地视为文本区域;Split:错误地将整个文本区域拆分为多个单独的部分;Merge :错误地将几个独立的文本区域合并在一起)。
参考文献
[1]论文原文:https://arxiv.org/pdf/1801.01671.pdf
[2]文字检测+识别之FOTS:https://blog.csdn.net/qq_14845119/article/details/84635847
[3]PyTorch实现:https://github.com/jiangxiluning/FOTS.PyTorch