在《第二篇|Spark Core编程指南》一文中,对Spark的核心模块进行了讲解。本文将讨论Spark的另外一个重要模块--Spark SQL,Spark SQL是在Shark的基础之上构建的,于2014年5月发布。从名称上可以看出,该模块是Spark提供的关系型操作API,实现了SQL-on-Spark的功能。对于一些熟悉SQL的用户,可以直接使用SQL在Spark上进行复杂的数据处理。通过本文,你可以了解到:
- Spark SQL简介
- DataFrame API&DataSet API
- Catalyst Optimizer优化器
- Spark SQL基本操作
- Spark SQL的数据源
- RDD与DataFrame相互转换
- Thrift server与Spark SQL CLI
Spark SQL简介
Spark SQL是Spark的其中一个模块,用于结构化数据处理。与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据结构和正在执行的计算的更多信息,Spark SQL会使用这些额外的信息来执行额外的优化。使用SparkSQL的方式有很多种,包括SQL、DataFrame API以及Dataset API。值得注意的是,无论使用何种方式何种语言,其执行引擎都是相同的。实现这种统一,意味着开发人员可以轻松地在不同的API之间来回切换,从而使数据处理更加地灵活。
DataFrame API&DataSet API
DataFrame API
DataFrame代表一个不可变的分布式数据集合,其核心目的是让开发者面对数据处理时,只关心要做什么,而不用关心怎么去做,将一些优化的工作交由Spark框架本身去处理。DataFrame是具有Schema信息的,也就是说可以被看做具有字段名称和类型的数据,类似于关系型数据库中的表,但是底层做了很多的优化。创建了DataFrame之后,就可以使用SQL进行数据处理。
用户可以从多种数据源中构造DataFrame,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD。DataFrame API支持Scala,Java,Python和R,在Scala和Java中,row类型的DataSet代表DataFrame,即Dataset[Row]等同于DataFrame。
DataSet API
DataSet是Spark 1.6中添加的新接口,是DataFrame的扩展,它具有RDD的优点(强类型输入,支持强大的lambda函数)以及Spark SQL的优化执行引擎的优点。可以通过JVM对象构建DataSet,然后使用函数转换(map,flatMap,filter)。值得注意的是,Dataset API在Scala和 Java中可用,Python不支持Dataset API。
另外,DataSet API可以减少内存的使用,由于Spark框架知道DataSet的数据结构,因此在持久化DataSet时可以节省很多的内存空间。
Catalyst Optimizer优化器
在Catalyst中,存在两种类型的计划:
- 逻辑计划(Logical Plan):定义数据集上的计算,尚未定义如何去执行计算。每个逻辑计划定义了一系列的用户代码所需要的属性(查询字段)和约束(where条件),但是不定义该如何执行。具体如下图所示:
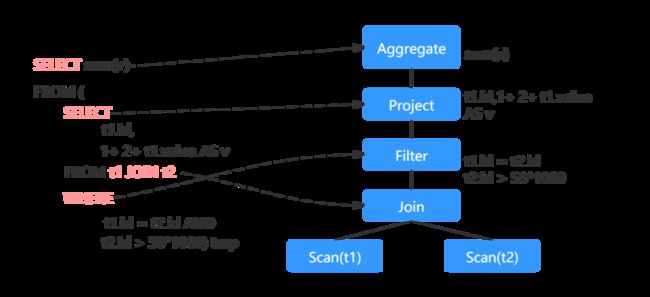
- 物理计划(Physical Plan):物理计划是从逻辑计划生成的,定义了如何执行计算,是可执行的。举个栗子:逻辑计划中的JOIN会被转换为物理计划中的sort merge JOIN。需要注意,Spark会生成多个物理计划,然后选择成本最低的物理计划。具体如下图所示:
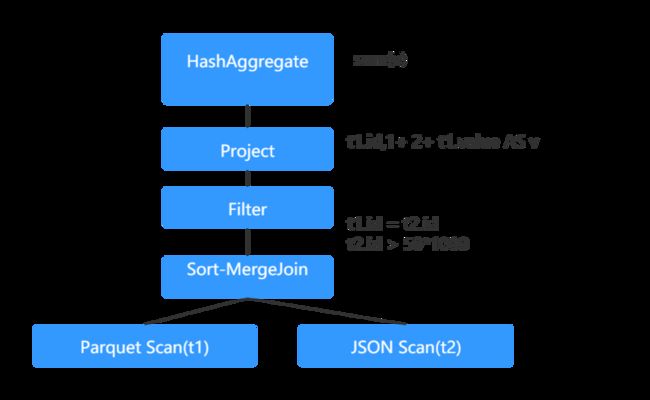
在Spark SQL中,所有的算子操作会被转换成AST(abstract syntax tree,抽象语法树),然后将其传递给Catalyst优化器。该优化器是在Scala的函数式编程基础会上构建的,Catalyst支持基于规则的(rule-based)和基于成本的(cost-based)优化策略。
Spark SQL的查询计划包括4个阶段(见下图):
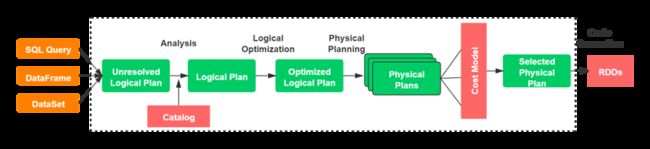
- 1.分析
- 2.逻辑优化
- 3.物理计划
- 4.生成代码,将查询部分编译成Java字节码
注意:在物理计划阶段,Catalyst会生成多个计划,并且会计算每个计划的成本,然后比较这些计划的成本的大小,即基于成本的策略。在其他阶段,都是基于规则的的优化策略。
分析
Unresolved Logical plan --> Logical plan。Spark SQL的查询计划首先起始于由SQL解析器返回的AST,或者是由API构建的DataFrame对象。在这两种情况下,都会存在未处理的属性引用(某个查询字段可能不存在,或者数据类型错误),比如查询语句:SELECT col FROM sales,关于字段col的类型,或者该字段是否是一个有效的字段,只有等到查看该sales表时才会清楚。当不能确定一个属性字段的类型或者没能够与输入表进行匹配时,称之为未处理的。Spark SQL使用Catalyst的规则以及Catalog对象(能够访问数据源的表信息)来处理这些属性。首先会构建一个Unresolved Logical Plan树,然后作用一系列的规则,最后生成Logical Plan。
逻辑优化
Logical plan --> Optimized Logical Plan。逻辑优化阶段使用基于规则的优化策略,比如谓词下推、投影裁剪等。经过一些列优化过后,生成优化的逻辑计划Optimized Logical Plan。
物理计划
Optimized Logical Plan -->physical Plan。在物理计划阶段,Spark SQL会将优化的逻辑计划生成多个物理执行计划,然后使用Cost Model计算每个物理计划的成本,最终选择一个物理计划。在这个阶段,如果确定一张表很小(可以持久化到内存),Spark SQL会使用broadcast join。
需要注意的是,物理计划器也会使用基于规则的优化策略,比如将投影、过滤操作管道化一个Spark的map算子。此外,还会将逻辑计划阶段的操作推到数据源端(支持谓词下推、投影下推)。
代码生成
查询优化的最终阶段是生成Java字节码,使用Quasi quotes来完成这项工作的。
经过上面的分析,对Catalyst Optimizer有了初步的了解。关于Spark的其他组件是如何与Catalyst Optimizer交互的呢?具体如下图所示:
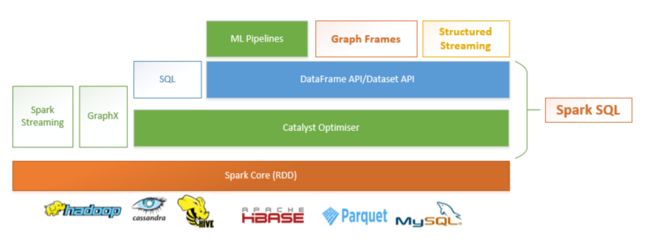
如上图所示:ML Pipelines, Structured streaming以及 GraphFrames都使用了DataFrame/Dataset
APIs,并且都得益于 Catalyst optimiser。
Quick Start
创建SparkSession
SparkSession是Dataset与DataFrame API的编程入口,从Spark2.0开始支持。用于统一原来的HiveContext和SQLContext,为了兼容两者,仍然保留这两个入口。通过一个SparkSession入口,提高了Spark的易用性。下面的代码展示了如何创建一个SparkSession:
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
//导入隐式转换,比如将RDD转为DataFrame
import spark.implicits._创建DataFrame
创建完SparkSession之后,可以使用SparkSession从已经存在的RDD、Hive表或者其他数据源中创建DataFrame。下面的示例使用的是从一个JSON文件数据源中创建DataFrame:
/**
* {"name":"Michael"}
* {"name":"Andy", "age":30}
* {"name":"Justin", "age":19}
*/
val df = spark.read.json("E://people.json")
//输出DataFrame的内容
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+DataFrame基本操作
创建完DataFrame之后,可以对其进行一些列的操作,具体如下面代码所示:
// 打印该DataFrame的信息
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// 查询name字段
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// 将每个人的age + 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// 查找age大于21的人员信息
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// 按照age分组,统计每种age的个数
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+在程序中使用SQL查询
上面的操作使用的是DSL(domain-specific language)方式,还可以直接使用SQL对DataFrame进行操作,具体如下所示:
// 将DataFrame注册为SQL的临时视图
// 该方法创建的是一个本地的临时视图,生命周期与其绑定的SparkSession会话相关
// 即如果创建该view的session结束了,该view也就消失了
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+Global Temporary View
上面使用的是Temporary views的方式,该方式是Spark Session范围的。如果将创建的view可以在所有session之间共享,可以使用Global Temporary View的方式创建view,具体如下:
// 将DataFrame注册为全局临时视图(global temporary view)
// 该方法创建的是一个全局的临时视图,生命周期与其绑定的Spark应用程序相关,
// 即如果应用程序结束,会自动被删除
// 全局临时视图是可以跨Spark Session的,系统保留的数据库名为`global_temp`
// 当查询时,必须要加上全限定名,如`SELECT * FROM global_temp.view1`
df.createGlobalTempView("people")
// 全局临时视图默认的保留数据库为:`global_temp`
spark.sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// 全局临时视图支持跨Spark Session会话
spark.newSession().sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+创建DataSet
DataSet与RDD很类似,但是,RDD使用的Java的序列化器或者Kyro序列化,而DataSet使用的是Encoder对在网络间传输的对象进行序列化的。创建DataSet的示例如下:
case class Person(name: String, age: Long)
// 创建DataSet
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// 通过导入Spark的隐式转换spark.implicits._
// 可以自动识别数据类型
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // 返回: Array(2, 3, 4)
// 通过调用as方法,DataFrame可以转为DataSet,
val path = "E://people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+RDD与DataFrame相互转换
Spark SQL支持两种不同的方式将RDD转换为DataFrame。第一种是使用反射来推断包含特定类型对象的RDD的模式,这种基于反射的方式可以提供更简洁的代码,如果在编写Spark应用程序时,已经明确了schema,可以使用这种方式。第二种方式是通过可编程接口来构建schema,然后将其应用于现有的RDD。此方式编写的代码更冗长,此种方式创建的DataFrame,直到运行时才知道该DataFrame的列及其类型。
下面案例的数据集如下people.txt:
Tom, 29
Bob, 30
Jack, 19通过反射的方式
Spark SQL的Scala接口支持自动将包含样例类的RDD转换为DataFrame。样例类定义表的schema。通过反射读取样例类的参数名称,并映射成column的名称。
object RDD2DF_m1 {
//创建样例类
case class Person(name: String, age: Int)
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("RDD2DF_m1")
.master("local")
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
runRDD2DF(spark)
}
private def runRDD2DF(spark: SparkSession) = {
//导入隐式转换,用于RDD转为DataFrame
import spark.implicits._
//从文本文件中创建RDD,并将其转换为DataFrame
val peopleDF = spark.sparkContext
.textFile("file:///E:/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
//将DataFrame注册成临时视图
peopleDF.createOrReplaceTempView("people")
// 运行SQL语句
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
// 使用字段索引访问列
teenagersDF.map(teenager => "Name: " + teenager(0)).show()
// +----------+
// | value|
// +----------+
// |Name: Jack|
// +----------+
// 通过字段名访问列
teenagersDF.map(teenager => "Name: " + teenager.getAs[String]("name")).show()
// +------------+
// | value|
// +------------+
// |Name: Jack|
// +------------+
}
}通过构建schema的方式
通过构建schema的方式创建DataFrame主要包括三步:
- 1.从原始RDD创建Row类型的RDD
- 2.使用StructType,创建schema
- 3.通过createDataFrame方法将schema应用于Row类型的RDD
object RDD2DF_m2 {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("RDD2DF_m1")
.master("local")
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
runRDD2DF(spark)
}
private def runRDD2DF(spark: SparkSession) = {
//导入隐式转换,用于RDD转为DataFrame
import spark.implicits._
//创建原始RDD
val peopleRDD = spark.sparkContext.textFile("E:/people.txt")
//step 1 将原始RDD转换为ROW类型的RDD
val rowRDD = peopleRDD
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim.toInt))
//step 2 创建schema
val schema = StructType(Array(
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
//step 3 创建DF
val peopleDF = spark.createDataFrame(rowRDD, schema)
// 将DataFrame注册成临时视图
peopleDF.createOrReplaceTempView("people")
// 运行SQL语句
val results = spark.sql("SELECT name FROM people")
// 使用字段索引访问列
results.map(attributes => "Name: " + attributes(0)).show()
// +----------+
// | value|
// +----------+
// | Name: Tom|
// | Name: Bob|
// | Name: Jack|
// +----------+
}
}
Spark SQL的数据源
Spark SQL支持通过DataFrame接口对各种数据源进行操作,可以使用关系转换以及临时视图对DataFrame进行操作。常见的数据源包括以下几种:
文件数据源
- Parquet文件
- JSON文件
- CSV文件
- ORC文件
private def runBasicDataSourceExample(spark: SparkSession): Unit = {
/**
* 读取parquet文件数据源,并将结果写入到parquet文件
*/
val usersDF = spark
.read
.load("E://users.parquet")
usersDF.show()
// 将DF保存到parquet文件
usersDF
.select("name", "favorite_color")
.write
.mode(SaveMode.Overwrite)
.save("E://namesAndFavColors.parquet")
/**
* 读取json文件数据源,并将结果写入到parquet文件
*/
val peopleDF = spark
.read
.format("json")
.load("E://people.json")
peopleDF.show()
// 将DF保存到parquet文件
peopleDF
.select("name", "age")
.write
.format("parquet")
.mode(SaveMode.Overwrite)
.save("E://namesAndAges.parquet")
/**
* 读取CSV文件数据源
*/
val peopleDFCsv = spark.read.format("csv")
.option("sep", ";")
.option("inferSchema", "true")
.option("header", "true")
.load("E://people.csv")
/**
* 将usersDF写入到ORC文件
*/
usersDF.write.format("orc")
.option("orc.bloom.filter.columns", "favorite_color")
.option("orc.dictionary.key.threshold", "1.0")
.option("orc.column.encoding.direct", "name")
.mode(SaveMode.Overwrite)
.save("E://users_with_options.orc")
/**
* 将peopleDF保存为持久化表,一般保存为Hive中
*/
peopleDF
.write
.option("path","E://warehouse/people_bucketed") // 保存路径
.bucketBy(42, "name") // 按照name字段分桶
.sortBy("age") // 按照age字段排序
.saveAsTable("people_bucketed")
/**
* 将userDF保存为分区文件,类似于Hive分区表
*/
usersDF
.write
.partitionBy("favorite_color") // 分区字段
.format("parquet") // 文件格式
.mode(SaveMode.Overwrite) // 保存模式
.save("E://namesPartByColor.parquet")
/**
*
*/
usersDF
.write
.option("path","E://warehouse/users_partitioned_bucketed") // 保存路径
.partitionBy("favorite_color") // 分区
.bucketBy(42, "name") // 分桶
.saveAsTable("users_partitioned_bucketed")
spark.sql("DROP TABLE IF EXISTS people_bucketed")
spark.sql("DROP TABLE IF EXISTS users_partitioned_bucketed")
}
保存模式
| Scala/Java | Meaning |
|---|---|
SaveMode.ErrorIfExists(default) |
如果目标文件已经存在,则报异常 |
SaveMode.Append |
如果目标文件或表已经存在,则将结果追加进去 |
SaveMode.Overwrite |
如果目标文件或表已经存在,则覆盖原有的内容 |
SaveMode.Ignore |
类似于SQL中的CREATE TABLE IF NOT EXISTS,如果目标文件或表已经存在,则不做任何操作 |
保存为持久化表
DataFrame可以被保存为Hive的持久化表,值得注意的是,这种方式并不依赖与Hive的部署,也就是说Spark会使用Derby创建一个默认的本地Hive metastore,与createOrReplaceTempView不同,该方式会直接将结果物化。
对于基于文件的数据源( text, parquet, json等),在保存的时候可以指定一个具体的路径,比如 df.write.option("path", "/some/path").saveAsTable("t")(存储在指定路径下的文件格式为parquet)。当表被删除时,自定义的表的路径和表数据不会被移除。如果没有指定具体的路径,spark默认的是warehouse的目录(/user/hive/warehouse),当表被删除时,默认的表路径也会被删除。
Hive数据源
见下面小节:Spark SQL集成Hive
JDBC数据源
Spark SQL还包括一个可以使用JDBC从其他数据库读取数据的数据源。与使用JdbcRDD相比,应优先使用此功能。这是因为结果作为DataFrame返回,它们可以在Spark SQL中轻松处理或与其他数据源连接。JDBC数据源也更易于使用Java或Python,因为它不需要用户提供ClassTag。
可以使用Data Sources API将远程数据库中的表加载为DataFrame或Spark SQL临时视图。用户可以在数据源选项中指定JDBC连接属性。 user并且password通常作为用于登录数据源的连接属性提供。除连接属性外,Spark还支持以下不区分大小写的选项:
| 属性名称 | 解释 |
|---|---|
url |
要连接的JDBC URL |
dbtable |
读取或写入的JDBC表 |
query |
指定查询语句 |
driver |
用于连接到该URL的JDBC驱动类名 |
partitionColumn, lowerBound, upperBound |
如果指定了这些选项,则必须全部指定。另外, numPartitions必须指定 |
numPartitions |
表读写中可用于并行处理的最大分区数。这也确定了并发JDBC连接的最大数量。如果要写入的分区数超过此限制,我们可以通过coalesce(numPartitions)在写入之前进行调用将其降低到此限制 |
queryTimeout |
默认为0,查询超时时间 |
fetchsize |
JDBC的获取大小,它确定每次要获取多少行。这可以帮助提高JDBC驱动程序的性能 |
batchsize |
默认为1000,JDBC批处理大小,这可以帮助提高JDBC驱动程序的性能。 |
isolationLevel |
事务隔离级别,适用于当前连接。它可以是一个NONE,READ_COMMITTED,READ_UNCOMMITTED,REPEATABLE_READ,或SERIALIZABLE,对应于由JDBC的连接对象定义,缺省值为标准事务隔离级别READ_UNCOMMITTED。此选项仅适用于写作。 |
sessionInitStatement |
在向远程数据库打开每个数据库会话之后,在开始读取数据之前,此选项将执行自定义SQL语句,使用它来实现会话初始化代码。 |
truncate |
这是与JDBC writer相关的选项。当SaveMode.Overwrite启用时,就会清空目标表的内容,而不是删除和重建其现有的表。默认为false |
pushDownPredicate |
用于启用或禁用谓词下推到JDBC数据源的选项。默认值为true,在这种情况下,Spark将尽可能将过滤器下推到JDBC数据源。 |
object JdbcDatasetExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("JdbcDatasetExample")
.master("local") //设置为本地运行
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
runJdbcDatasetExample(spark)
}
private def runJdbcDatasetExample(spark: SparkSession): Unit = {
//注意:从JDBC源加载数据
val jdbcPersonDF = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://localhost/mydb")
.option("dbtable", "person")
.option("user", "root")
.option("password", "123qwe")
.load()
//打印jdbcDF的schema
jdbcPersonDF.printSchema()
//打印数据
jdbcPersonDF.show()
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "123qwe")
//通过.jdbc的方式加载数据
val jdbcStudentDF = spark
.read
.jdbc("jdbc:mysql://localhost/mydb", "student", connectionProperties)
//打印jdbcDF的schema
jdbcStudentDF.printSchema()
//打印数据
jdbcStudentDF.show()
// 保存数据到JDBC源
jdbcStudentDF.write
.format("jdbc")
.option("url", "jdbc:mysql://localhost/mydb")
.option("dbtable", "student2")
.option("user", "root")
.option("password", "123qwe")
.mode(SaveMode.Append)
.save()
jdbcStudentDF
.write
.mode(SaveMode.Append)
.jdbc("jdbc:mysql://localhost/mydb", "student2", connectionProperties)
}
}
Spark SQL集成Hive
Spark SQL还支持读取和写入存储在Apache Hive中的数据。但是,由于Hive具有大量依赖项,因此这些依赖项不包含在默认的Spark发布包中。如果可以在类路径上找到Hive依赖项,Spark将自动加载它们。请注意,这些Hive依赖项也必须存在于所有工作节点(worker nodes)上,因为它们需要访问Hive序列化和反序列化库(SerDes)才能访问存储在Hive中的数据。
将hive-site.xml,core-site.xml以及hdfs-site.xml文件放在conf/下。
在使用Hive时,必须实例化一个支持Hive的SparkSession,包括连接到持久性Hive Metastore,支持Hive 的序列化、反序列化(serdes)和Hive用户定义函数。没有部署Hive的用户仍可以启用Hive支持。如果未配置hive-site.xml,则上下文(context)会在当前目录中自动创建metastore_db,并且会创建一个由spark.sql.warehouse.dir配置的目录,其默认目录为spark-warehouse,位于启动Spark应用程序的当前目录中。请注意,自Spark 2.0.0以来,该在hive-site.xml中的hive.metastore.warehouse.dir属性已被标记过时(deprecated)。使用spark.sql.warehouse.dir用于指定warehouse中的默认位置。可能需要向启动Spark应用程序的用户授予写入的权限。
下面的案例为在本地运行(为了方便查看打印的结果),运行结束之后会发现在项目的目录下E:IdeaProjectsmyspark创建了spark-warehouse和metastore_db的文件夹。可以看出没有部署Hive的用户仍可以启用Hive支持,同时也可以将代码打包,放在集群上运行。
object SparkHiveExample {
case class Record(key: Int, value: String)
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", "e://warehouseLocation")
.master("local")//设置为本地运行
.enableHiveSupport()
.getOrCreate()
Logger.getLogger("org.apache.spark").setLevel(Level.OFF)
Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF)
import spark.implicits._
import spark.sql
//使用Spark SQL 的语法创建Hive中的表
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
sql("LOAD DATA LOCAL INPATH 'file:///e:/kv1.txt' INTO TABLE src")
// 使用HiveQL查询
sql("SELECT * FROM src").show()
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ...
// 支持使用聚合函数
sql("SELECT COUNT(*) FROM src").show()
// +--------+
// |count(1)|
// +--------+
// | 500 |
// +--------+
// SQL查询的结果是一个DataFrame,支持使用所有的常规的函数
val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 AND key > 0 ORDER BY key")
// DataFrames是Row类型的, 允许你按顺序访问列.
val stringsDS = sqlDF.map {
case Row(key: Int, value: String) => s"Key: $key, Value: $value"
}
stringsDS.show()
// +--------------------+
// | value|
// +--------------------+
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// ...
//可以通过SparkSession使用DataFrame创建一个临时视图
val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i")))
recordsDF.createOrReplaceTempView("records")
//可以用DataFrame与Hive中的表进行join查询
sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
// +---+------+---+------+
// |key| value|key| value|
// +---+------+---+------+
// | 2| val_2| 2| val_2|
// | 4| val_4| 4| val_4|
// | 5| val_5| 5| val_5|
// ...
//创建一个Parquet格式的hive托管表,使用的是HQL语法,没有使用Spark SQL的语法("USING hive")
sql("CREATE TABLE IF NOT EXISTS hive_records(key int, value string) STORED AS PARQUET")
//读取Hive中的表,转换成了DataFrame
val df = spark.table("src")
//将该DataFrame保存为Hive中的表,使用的模式(mode)为复写模式(Overwrite)
//即如果保存的表已经存在,则会覆盖掉原来表中的内容
df.write.mode(SaveMode.Overwrite).saveAsTable("hive_records")
// 查询表中的数据
sql("SELECT * FROM hive_records").show()
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ...
// 设置Parquet数据文件路径
val dataDir = "/tmp/parquet_data"
//spark.range(10)返回的是DataSet[Long]
//将该DataSet直接写入parquet文件
spark.range(10).write.parquet(dataDir)
// 在Hive中创建一个Parquet格式的外部表
sql(s"CREATE EXTERNAL TABLE IF NOT EXISTS hive_ints(key int) STORED AS PARQUET LOCATION '$dataDir'")
// 查询上面创建的表
sql("SELECT * FROM hive_ints").show()
// +---+
// |key|
// +---+
// | 0|
// | 1|
// | 2|
// ...
// 开启Hive动态分区
spark.sqlContext.setConf("hive.exec.dynamic.partition", "true")
spark.sqlContext.setConf("hive.exec.dynamic.partition.mode", "nonstrict")
// 使用DataFrame API创建Hive的分区表
df.write.partitionBy("key").format("hive").saveAsTable("hive_part_tbl")
//分区键‘key’将会在最终的schema中被移除
sql("SELECT * FROM hive_part_tbl").show()
// +-------+---+
// | value|key|
// +-------+---+
// |val_238|238|
// | val_86| 86|
// |val_311|311|
// ...
spark.stop()
}
}
Thrift server与Spark SQL CLI
可以使用JDBC/ODBC或者命令行访问Spark SQL,通过这种方式,用户可以直接使用SQL运行查询,而不用编写代码。
Thrift JDBC/ODBC server
Thrift JDBC/ODBC server与Hive的HiveServer2向对应,可以使用Beeline访问JDBC服务器。在Spark的sbin目录下存在start-thriftserver.sh脚本,使用此脚本启动JDBC/ODBC服务器:
./sbin/start-thriftserver.sh
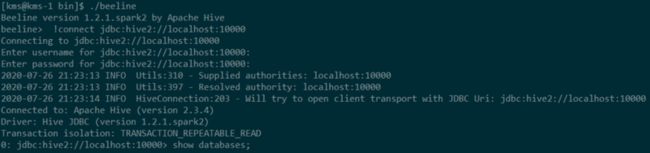
使用beeline访问JDBC/ODBC服务器,Beeline会要求提供用户名和密码,在非安全模式下,只需输入用户名和空白密码即可
beeline> !connect jdbc:hive2://localhost:10000
Spark SQL CLI
Spark SQL CLI是在本地模式下运行Hive Metastore服务并执行从命令行输入的查询的便捷工具。请注意,Spark SQL CLI无法与Thrift JDBC服务器通信。
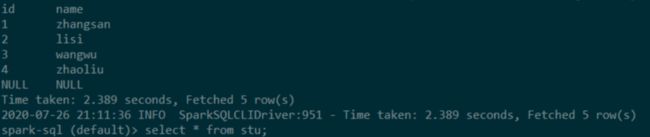
要启动Spark SQL CLI,只需要在Spark的bin目录中运行以下命令:
./spark-sql
总结
本文主要对Spark SQL进行了阐述,主要包括Spark SQL的介绍、DataFrame&DataSet API基本使用、Catalyst Optimizer优化器的基本原理、Spark SQL编程、Spark SQL数据源以及与Hive集成、Thrift server与Spark SQL CLI。下一篇将分享Spark Streaming编程指南。
公众号『大数据技术与数仓』,回复『资料』领取大数据资料包