Android性能工具——Systrace使用
一、屏幕刷新机制
基础概念
在一个典型的显示系统中,一般包括CPU、GPU、display三个部分, CPU负责计算数据,把计算好数据交给GPU,GPU会对图形数据进行渲染,渲染好后放到buffer里存起来,然后display(有的文章也叫屏幕或者显示器)负责把buffer里的数据呈现到屏幕上。
显示过程,简单的说就是CPU/GPU准备好数据,存入buffer,display每隔一段时间去buffer里取数据,然后显示出来。display读取的频率是固定的,比如每个16ms读一次,但是CPU/GPU写数据是完全无规律的。
简单的说,屏幕的刷新包括三个步骤:CPU 计算屏幕数据、GPU 进一步处理和缓存、最后 display 再将缓存中(buffer)的屏幕数据显示出来。
Screen Tearing(撕裂)
由于display处理的频率是固定的,而CPU/GPU处理数据的时间是不确定的,因此在早期的设备上,由于是单缓冲的模式,则会有屏幕撕裂的情况发生。

例如显示周期为0.01秒,则在0.01秒时显示正确,而在0.01秒-0.02秒时,CPU/GPU仅完成了部分工作,则在0.02秒时,屏幕显示的是上部分为2,下部分为1的撕裂画面。
Double-Buffer
双缓冲技术,基本原理就是采用两块buffer。一块back buffer用于CPU/GPU后台绘制,另一块framebuffer则用于显示,当back buffer准备就绪后,它们才进行交换。
为了避免Tearing情况发生,当扫描完一个屏幕后,设备需要重新回到第一行以进入下一次的循环,此时有一段时间空隙,这个时间点就是我们进行缓冲区交换的最佳时间,VSync信号也是在这个时间点产生的。
VSync
在android4.1之前,没有采用Vsync信号时,CPU/GPU往Buffer里面写数据是比较随意的,CPU/GPU开始工作的时间不是固定的,而Display处理的频率是固定的,因此,会造成丢帧(Jank)的情况发生,如下图所示。
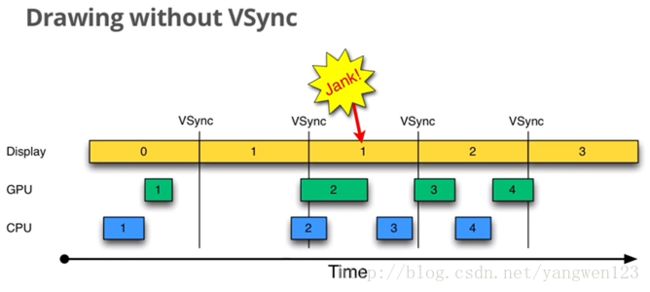
在android4.1之后,对Android Display系统进行了重构,实现了Project Butter,引入了三个核心元素,即VSYNC、Triple Buffer和Choreographer。
Project Butter规定系统一旦收到vsync通知(16ms触发一次),CPU和GPU就立刻开始工作把显示数据写入buffer。

系统规定收到Vsync信号后,CPU就开始处理屏幕绘制数据,CPU/GPU根据VSYNC信号同步处理数据,可以让CPU/GPU有完整的16ms时间来处理数据,减少了jank。
Triple Buffer
双缓存的机制并不是完美的,比如当CPU/GPU工作时间较长时,会发生如下情况:

当CPU/GPU的处理时间超过16ms时,第一个VSync到来时,缓冲区B中的数据还没有准备好,于是只能继续显示之前A缓冲区中的内容。而B完成后,又因为缺乏VSync信号,它只能等待下一个信号的来临。于是在这一过程中,有一大段时间是被浪费的。
当下一个VSync出现时,CPU/GPU马上执行操作,此时它可操作的buffer是A,相应的显示屏对应的就是B。这时看起来就是正常的。只不过由于执行时间仍然超过16ms,导致下一次应该执行的缓冲区交换又被推迟了——如此循环反复,便出现了越来越多的Jank。

三缓存不能解决双缓冲带来的第一次Jank丢失问题,但是当第一次VSync发生后,CPU不用再等待了,它会使用第三个buffer C来进行下一帧数据的准备工作。虽然对缓冲区C的处理所需时间同样超过了16ms,但这并不影响显示屏——第2次VSync到来后,它选择buffer B进行显示;而第3次VSync时,它会接着采用C,而不是像double buffering中所看到的情况一样只能再显示一遍B了。这样子就有效地降低了jank。
二、App相关的屏幕绘制
App刷新屏幕流程
- 界面上任何一个 View 的刷新请求最终都会走到 ViewRootImpl 中的
scheduleTraversals()里来安排一次遍历绘制 View 树的任务; scheduleTraversals()会先过滤掉同一帧内的重复调用,在同一帧内只需要安排一次遍历绘制 View 树的任务即可,这个任务会在下一个屏幕刷新信号到来时调用performTraversals()遍历 View 树,遍历过程中会将所有需要刷新的 View 进行重绘;- 接着
scheduleTraversals()会往主线程的消息队列中发送一个同步屏障,拦截这个时刻之后所有的同步消息的执行,但不会拦截异步消息,以此来尽可能的保证当接收到屏幕刷新信号时可以尽可能第一时间处理遍历绘制 View 树的工作; - 发完同步屏障后
scheduleTraversals()才会开始安排一个遍历绘制 View 树的操作,作法是把performTraversals()封装到 Runnable 里面,然后调用 Choreographer 的postCallback()方法; postCallback()方法会先将这个 Runnable 任务以当前时间戳放进一个待执行的队列里,然后如果当前是在主线程就会直接调用一个native 层方法,如果不是在主线程,会发一个最高优先级的 message 到主线程,让主线程第一时间调用这个 native 层的方法;- native 层的这个方法是用来向底层注册监听下一个屏幕刷新信号,当下一个屏幕刷新信号发出时,底层就会回调 Choreographer 的
onVsync()方法来通知上层 app; onVsync()方法被回调时,会往主线程的消息队列中发送一个执行doFrame()方法的消息,这个消息是异步消息,所以不会被同步屏障拦截住;doFrame()方法会去取出之前放进待执行队列里的任务来执行,取出来的这个任务实际上是 ViewRootImpl 的doTraversal()操作;- 上述第4步到第8步涉及到的消息都手动设置成了异步消息,所以不会受到同步屏障的拦截;
doTraversal()方法会先移除主线程的同步屏障,然后调用performTraversals()开始根据当前状态判断是否需要执行performMeasure()测量、perfromLayout()布局、performDraw()绘制流程,在这几个流程中都会去遍历 View 树来刷新需要更新的View;
总结来说,当有屏幕刷新操作时,系统会将View树的测量、布局和绘制等封装到一个Runnable,然后监听VSync信号,等Vsync信号来时,再触发此Runnable。
三、卡顿分析利器——Systrace工具
简介
Systrace是分析Android性能问题的神器,Google IO 2017上更是对其各种强推. 是分析卡顿掉帧问题核心工具,只要能提供卡顿现场,systrace就能很好定位问题。
原理
在介绍使用之前,先简单说明一下Systrace的原理:它的思想很朴素,在系统的一些关键链路(比如System Service,虚拟机,Binder驱动)插入一些信息(我这里称之为Label),通过Label的开始和结束来确定某个核心过程的执行时间,然后把这些Label信息收集起来得到系统关键路径的运行时间信息,进而得到整个系统的运行性能信息。Android Framework里面一些重要的模块都插入了Label信息(Java层的通过android.os.Trace类完成,native层通过ATrace宏完成),用户App中可以添加自定义的Label,这样就组成了一个完成的性能分析系统。另外说明的是:Systrace对系统版本有一个要求,就是需要Android 4.1以上。系统版本越高,Android Framework中添加的系统可用Label就越多,能够支持和分析的系统模块也就越多;因此,在可能的情况下,尽可能使用高版本的Android系统来进行分析。
获取systrace文件
要想分析卡顿现场,必须先获取到卡顿现场的Systrace文件,获取Systrace文件的方式有两种,一种是通过AndroidSDK/tools目录下,通过monitor.bat用Android Device Monitor可视化工具得到,一种是通过python脚本获取,我本人更喜欢通过脚本获取,因为更方便一点。
1. 通过Android Device Monitor获取
-
点击绿色按钮启动Systrace
-
选择抓取Systrace的配置文件

这里,我们仅仅抓取5秒钟的系统数据,没有选择特别的应用进程,抓取的内容为基础内容。 -
点击OK开始抓取
2. 通过python脚本抓取(推荐)
-
装python2.X版本,Systrace脚本不支持3.X版本。
-
通过python脚本执行
AndroidSDK\platform-tools\systrace\目录下的systrace.py文件 -
可以配置一些参数,类似于通过Android Device Monitor抓取时步骤2配置的显示信息,若不选择则默认全部抓取。
-
配置一些其他实用参数:
-o: 指定文件输出位置和文件名-t: 抓取systrace的时间长度-a: 指定特殊进程包名(自己加Label时必须加上)
-
抓取脚本示例:

Systrace文件说明
准备工具
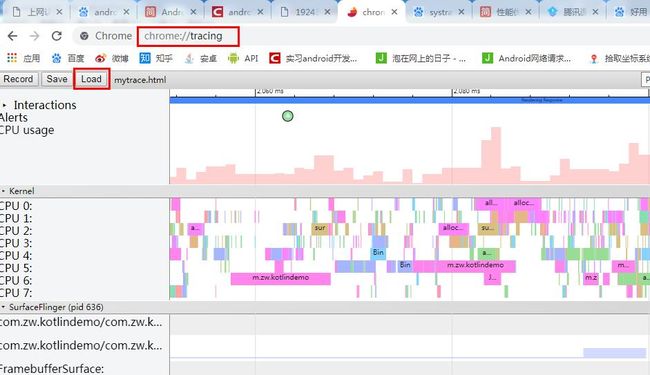
- Chrome浏览器(必须)。
在地址栏输入chrome://tracing命令,然后将生成的trace.html文件拖进来,或者通过load按钮导入。
常用快捷键说明:
W: 放大横轴,用于查看耗时方法细节;S: 缩小横轴,用于查看整体情况;A: 将面板左移;D: 将面板右移;M: 高亮某一段耗时内容。
文件结构
Systrace的文件结构从上到下一般是:
-
内核信息(CPU片信息);
-
SurfaceFlinger(底层绘制信号等信息);
-
system_server等其他进程信息。
性能问题分析
一般用Systrace用来分析卡顿、启动时间慢等问题,还可以用来分析方法耗时等。
1. 卡顿问题分析
首先分析一下正常的无卡顿时的表现:
[外链图片转存失败(img-cN2yB054-1567387228383)(https://i.postimg.cc/43LnJ6hY/6.jpg)]
当按W并且按M放大高亮每一帧细节的时候,可以看到每一帧的绘制开始都是在16ms以内完成的:
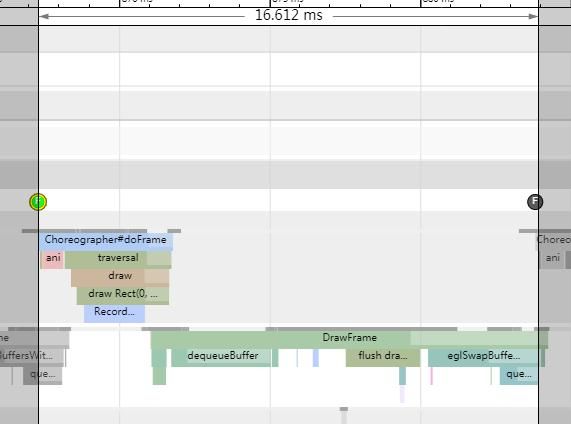
从某一帧的刷新,我们也可以知道,刷新是从Choreographer的doFrame()开始的,一直到GPU线程绘制完毕结束。
现在,我们修改代码,在 ListView 的getView()方法延迟100ms,然后抓取systrace,查看一下耗时情况。
代码:
@Override
public View getView(int i, View view, ViewGroup viewGroup) {
SystemClock.sleep(100);
if(view != null) {
((TextView)view).setText(list.get(i));
return view;
}
TextView tv = new TextView(viewGroup.getContext());
tv.setText(list.get(i));
return tv;
}
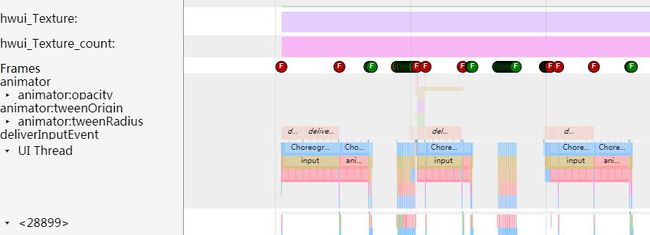
从图上,我们可以看见用来标识每一帧耗时的F标志变成了红色,这说明这一帧是耗时特别严重的。
高亮某一个带红色F的帧:
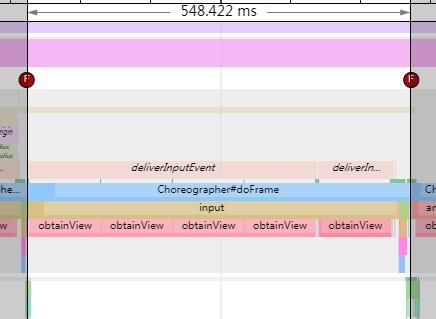
从图上,可以看出这一帧耗时达到548ms,其中耗时很大的部分为input,这个input和上面的deliverInputEvent相对应,说明是触摸事件耗时过长(其实是因为我们在主线程sleep了100ms导致的)。
为什么这一帧耗时是500ms呢?明明我们只sleep了100ms呀。原因是我们是在每一个ListView的getView()方法sleep了100ms,而这次触摸事件刷新出了5个item,每一个item的getView()方法都耗时了100ms(obtainView()会调用getView()),因此耗时达到了500多ms。
分析卡顿的步骤就是:
-
找到卡顿的场景,并抓取卡顿发生时的systrace文件;
-
找到发生问题的应用进程的主线程,并通过标红的F图标,找到发生问题的问题帧;
-
通过放大和高亮去判断具体是哪一个细节点发生了耗时情况。
若从systrace文件中看不出来具体是哪一个方法耗时,我们可以自己在代码中加入Label,去查看方法具体耗时(替代TraceView),后面会讲到。
2. 启动时间分析
很多时候,我们对App的冷启动时间都有一定的要求,我们当然可以通过adb命令去启动我们的MainActivity,然后查看启动时间,但是那并不是真正意义上应用完全打开的启动时间,而通过Systrace则可以很方便的统计启动时间,并找出耗时的地方。
这里,我们统计耗时是从用户点击Launcher上的应用图标,到界面完全显示的时间, 那么界面完全显示的时间是哪里?有两个方法,一个是在onWindowFocusChange()方法中打印Label,或者通过MessageQueue.IdelHandler来进行,这里,简单起见我们就用onWindowFocusChange()方法中加Label吧。
自己加Label主要是通过API:Trace.beginSection("名称")和Trace.endSection()来进行,自己的Label有以下需要注意:
begin和end必须成对出现;- Label支持嵌套;
begin和end必须在同一个线程中;- 抓取systrace时,必须指定包名
代码示例:
private boolean flag = true;
private static Handler mHandler = new Handler();
@Override
public void onWindowFocusChanged(boolean hasFocus) {
super.onWindowFocusChanged(hasFocus);
if(hasFocus && flag) {
flag = false;
mHandler.post(new Runnable() {
@Override
public void run() {
Trace.beginSection("endTime");
SystemClock.sleep(500);
Trace.endSection();
}
});
}
}
systrace文件:
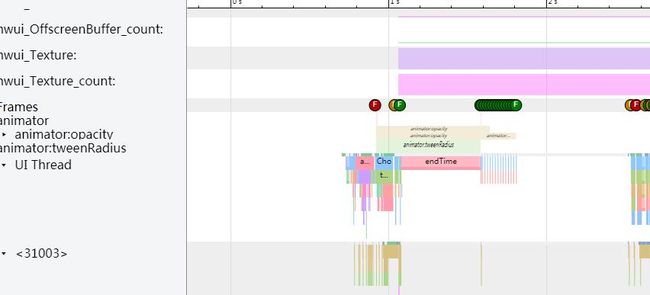
启动时间计算:
1、找到Launcher进程中最后一次手指按下的时间点 deliverInputEvent的标示,这里是起点:

2、终点就是上图中endTime()打印时开始的地方,用图中标示的工具,将两段时间相连,就能得到本次应用的冷启动时间为434ms。

总结
-
屏幕绘制的流程为 CPU计算数据 -> GPU绘制界面 -> 数据放入Buffer -> Display从Buffer中取数据呈现;
-
Display刷新的时间是固定的(Android中可以理解为16.6ms),而CPU/GPU计算数据的时间不固定,因此会有很多显示问题(撕裂、丢帧);
-
Systrace可以查看丢帧现场的具体问题点(哪些方法耗时过长导致丢帧);
-
Systrace可以通过添加Label代替TraceView的作用,用来统计方法耗时详情和应用启动时间。