2019独角兽企业重金招聘Python工程师标准>>> 
问题描述
HDFS在机器断电或意外崩溃的情况下,有可能出现正在写的数据(例如保存在DataNode内存的数据等)丢失的问题。再次重启HDFS后,发现hdfs无法启动,查看日志后发现,一直处于安全模式。
原因分析
出现前面提到的问题主要原因是客户端写入的数据没有及时保存到磁盘中,从而导致数据丢失;又因为数据块丢失达到一定的比率,导致hdfs启动进入安全模式。
为了弄清楚导致安全模式的原因,下面主要对hdfs安全模式和如何退出安全模式进行分析。
安全模式
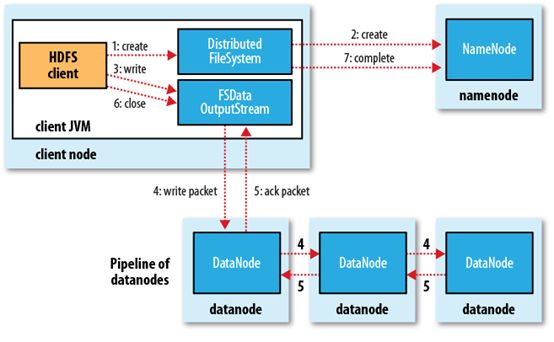
当 hdfs的NameNode节点启动时,会进入安全模式阶段。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。
在此阶段,NameNode加载fsimage(Filesystem image:文件meta信息的持久化的检查点)文件到内存中,然后在editlog中执行相应的操作。加载fsimage文件包含文件metadata信息,但是不包含文件块位置的信息。
DataNode启动的时候扫描本地磁盘,保存的block信息,然后将这些信息汇报给NameNode,让 NameNode得到块的位置信息,并对每个文件对应的数据块副本进行统计。
如果hdfs数据量很大时,进入至退出安全模式时间较长。
安全模式退出条件
当最小副本条件满足时,即一定比例(dfs.safemode.threshold.pct缺省值0.999f)的数据块都达到最小副本数,系统就会退出安全模式。当最小副本条件未达到要求时,就会对副本数不足的数据块安排DataNode进行复制,直至达到最小副本数。如果datanode丢失的block达到一定的比例(1-dfs.safemode.threshold.pct),则系统会一直处于安全模式状态即只读状态。而在安全模式下,系统会处于只读状态,NameNode不会处理任何块的复制和删除命令。
dfs.safemode.threshold.pct(缺省值0.999f)表示HDFS启动的时候,如果DataNode上报的block个数达到了元 数据 记录的block个数的0.999倍才可以离开安全模式,否则一直是这种只读模式。如果设为1则HDFS永远是处于SafeMode。
下面这行摘录自NameNode启动时的日志:
| 异常情况: |
| The ratio of reported blocks 0.8544 has not reached the threshold0.9990. Safe mode will be turned off automatically. org.apache.hadoop.hdfs.server.namenode.SafeModeException: Checkpoint not created. Name node is in safe mode. |
| 正常情况: |
| The ratio of reported blocks 1.0000 has reached the threshold0.9990. Safe mode will be turned off automatically in 18 seconds. |
解决方法
机器断电或意外崩溃是客观存在的事实,为了减少其带来的问题,从丢数据和不丢数据两个方面讨论解决方法
丢失少量数据
因为机器断电或意外崩溃,在内存中未写入的数据块已经丢失或损坏,无法复原,只有让hdfs离开安全模式,才可以让hdfs启动成功,这样无可避免的会导致数据丢失。
通过原因分析可知,有两个方法离开这种安全模式:
1. 修改dfs.safemode.threshold.pct为一个比较小的值,缺省是0.999;
该方法虽然可以是HDFS正常启动,但是threshold.pct的值不好把握,设置低了会导致集群可靠性下降,不推荐使用。
2. 退出安全模式后,删除损坏的块文件,然后重启hdfs服务。
注: 不论hdfs是否采用journal ha模式。hdfs进入安全模式后,hbase无法启动,会一直打印等待dfs退出安全模式(“Waiting for dfs to exit safe mode...”),此时也不可以使用hbck工具修复hbase,否则会打印获取不到Master错误(
client.HConnectionManager$HConnectionImplementation: getMaster attempt 8 of 35 failed)。
退出安全模式具体方法如下:
1. 首先启动hdfs所有服务,包括NameNode | DataNode | JournalNode | DFSZKFailoverController等;
[hadoop@172-25-8-121 hadoop]$ ./sbin/start-dfs.sh
2. 判断hdfs是否处于安全模式
[hadoop@172-25-8-121 bin]$ hdfs dfsadmin -safemode get
| Safe mode is ON |
注:两种模式,ON / OFF
3. 使用fsck命令查看是否有损坏的块
[hadoop@172-25-8-121 hadoop]$ ./bin/hdfs fsck /
(以下红色标记的为缺失或损坏的块)
| [hadoop@172-25-8-121 sbin]$ hadoop fsck / …………… /hbase/data/default/DSA_RESULT_SUMMARY/3432986e5109695221484de73f26cecd/attribute/08fa05898ff34fe9b0cdfef5dc30e9e6:CORRUPT blockpool BP-2061322962-172.25.8.121-1440560168099 block blk_1073742016 /hbase/data/default/DSA_RESULT_SUMMARY/3432986e5109695221484de73f26cecd/attribute/08fa05898ff34fe9b0cdfef5dc30e9e6:MISSING 1 blocks of total size 78969 B.. /hbase/data/default/DSA_RESULT_SUMMARY/3432986e5109695221484de73f26cecd/image/1ca82fc944a14a05aebac92b8de46d11:CORRUPT blockpool BP-2061322962-172.25.8.121-1440560168099 block blk_1073742018 /hbase/data/default/DSA_RESULT_SUMMARY/3432986e5109695221484de73f26cecd/image/1ca82fc944a14a05aebac92b8de46d11:MISSING 1 blocks of total size 72545 B... /hbase/data/default/DSA_RESULT_SUMMARY/3432986e5109695221484de73f26cecd/sequence/9ddd08a485164eabbdd16d66d96b19b3:CORRUPT blockpool BP-2061322962-172.25.8.121-1440560168099 block blk_1073742020 /hbase/data/default/DSA_RESULT_SUMMARY/3432986e5109695221484de73f26cecd/sequence/9ddd08a485164eabbdd16d66d96b19b3:MISSING 1 blocks of total size 77363 B......... /hbase/data/default/DSA_RESULT_SUMMARY/939bafb7709b004c8a81796b6af05733/attribute/a50e9e114db548508328bee892139800:CORRUPT blockpool BP-2061322962-172.25.8.121-1440560168099 block blk_1073742015 /hbase/data/default/DSA_RESULT_SUMMARY/939bafb7709b004c8a81796b6af05733/attribute/a50e9e114db548508328bee892139800:MISSING 1 blocks of total size 138179 B.. /hbase/data/default/DSA_RESULT_SUMMARY/939bafb7709b004c8a81796b6af05733/image/9965fb45404b46278d2d4738bbff8051:CORRUPT blockpool BP-2061322962-172.25.8.121-1440560168099 block blk_1073742017 /hbase/data/default/DSA_RESULT_SUMMARY/939bafb7709b004c8a81796b6af05733/image/9965fb45404b46278d2d4738bbff8051:MISSING 1 blocks of total size 126927 B.... /hbase/data/default/DSA_RESULT_SUMMARY/939bafb7709b004c8a81796b6af05733/sequence/441a9d027c944d78931d0d18a39454bd:CORRUPT blockpool BP-2061322962-172.25.8.121-1440560168099 block blk_1073742019 /hbase/data/default/DSA_RESULT_SUMMARY/939bafb7709b004c8a81796b6af05733/sequence/441a9d027c944d78931d0d18a39454bd: MISSING 1 blocks of total size 135366 B........................Status: CORRUPT Total size: 1624639056 B (Total open files size: 45 B) Total dirs: 85 Total files: 75 Total symlinks: 0 (Files currently being written: 5) Total blocks (validated): 83 (avg. block size 19573964 B) (Total open file blocks (not validated): 5) ******************************** CORRUPT FILES: 6 MISSING BLOCKS: 6 MISSING SIZE: 629349 B CORRUPT BLOCKS: 6 ******************************** Minimally replicated blocks: 77 (92.77109 %) Over-replicated blocks: 0 (0.0 %) Under-replicated blocks: 0 (0.0 %) Mis-replicated blocks: 0 (0.0 %) Default replication factor: 2 Average block replication: 1.8554217 Corrupt blocks: 6 Missing replicas: 0 (0.0 %) Number of data-nodes: 4 Number of racks: 1 FSCK ended at Wed Aug 26 17:17:22 CST 2015 in 44 milliseconds The filesystem under path '/' is CORRUPT |
4. 在NameNode节点上使用dfsadmin命令离开安全模式
[hadoop@172-25-8-121 hadoop]$ ./bin/hdfs dfsadmin -safemode leave
| Instead use the hdfs command for it. Safe mode is OFF |
5. 使用fsck命令将丢失的块删除
[hadoop@172-25-8-121 hadoop]$ ./bin/hdfs fsck -delete
6. 重启hdfs相关服务
[hadoop@172-23-9-20 hadoop]# ./sbin/dfs-start.sh
7. 重启hbase
[hadoop@172-23-9-20 hbase]# ./bin/start-hbase.sh
8. 如果hbase启动失败,则使用hbck命令修复
[hadoop @172-23-9-20 hbase]# ./bin/hbase hbck -repair
HBase提供了hbck命令来检查各种不一致问题,包括meta数据不一致。检查数据在Master及RegionServer的内存中状态与数据在HDFS中的状态之间的一致性。
HBase的hbck不仅能够检查不一致问题,而且还能够修复不一致问题。
在生产环境中,应当经常运行hbck,以便及早发现不一致问题并更容易地解决问题。
不丢数据
使用hsync()方法实现意外断电情况下HDFS数据的完整性。hdfs在Client端提供了hsync()的方法调用,从而保证在机器崩溃或意外断电的情况下,数据不会丢失。
在hdfs中,调用hflush()会将Client端buffer中的存放数据更新到Datanode端,直到收到所有Datanode的ack响应时结束调用。这样可保证在hflush()调用结束时,所有的Client端都可以读到一致的数据。hdfs中的sync()本质也是调用hflush()。
hsync()则是除了确保会将Client端buffer中的存放数据更新到Datanode端外,还会确保Datanode端的数据更新到物理磁盘上,这样在hsync()调用结束后,即使Datanode所在的机器意外断电,数据并不会因此丢失。而hflush()在机器意外断电的情况下却有可能丢失数据,因为Client端传给Datanode的数据可能存在于Datanode的cache中,并未持久化到磁盘上。
hdfs虽然提供了hsync()方法,但是若我们对每次写操作都执行hsync(),会严重加剧磁盘的写延迟。通过一些策略,比方说定期执行hsync()或当存在于Cache中的数据达到一定数目时,执行hsync()会是更可行的方案,从而尽量减少机器意外断电所带来的影响。