flask,MySQL实现简单小搜索引擎
断断续续学习了些python的网课,涉及python基础,scrapy框架,django框架,flask框架,elasticsearch,mysql,课程都不尽人意,两个课程相互借鉴了一下,有点小收获。
琢磨着也做点小玩意。
1、scrapy框架爬取网络数据
2、flask搭建简单搜索引擎
3、一些错误处理
scrapy爬取数据
爬过一些网站,目前觉得知乎改版后的爬取有点难。
这里我选择爬取jobbole伯乐在线。
首先看一下scrapy的框架图!(官方标配)
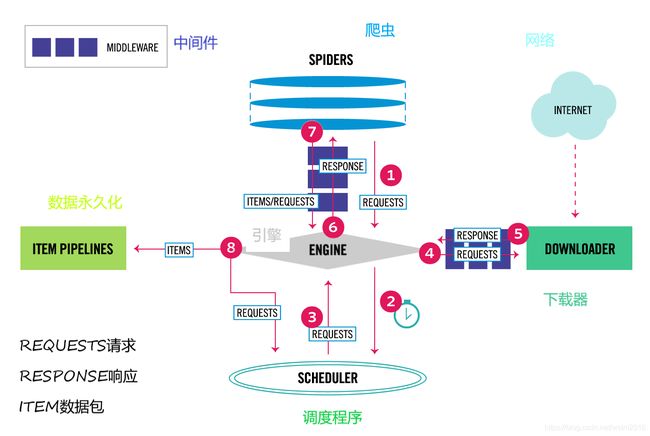
通俗来说就是spider发出请求爬取的url送到scheduler(调度程序:所有的url都会汇总到这里进行迭代),调度程序scheduler将要请求的url经过中间件middleware(可以在此处设置IP池,user-agent池等)发送到下载器downloader下载,结果response返回给spider(在这里可以对数据做操作,但不建议,因为看起来很乱),而item和item pipeline则是对数据进行处理的,其中item.py中定义数据类型以及处理数据函数,管道pipeline.py中做保存操作,比如存入数据库。(切记要在setting文件中给自定义的pipeline注册好)
一、scrapy爬取伯乐在线的文章
# 利用scrapy框架创建爬虫,cmd下
pip install scrapy # 安装包
# 然后cd 到想创建的目录下,创建
scrapy startproject
your spider project name
可以用pychame打开该工程文件,在spiders下创建爬虫逻辑,比如我创建的是jobbole.py
# -*- coding: utf-8 -*-
import scrapy
import datetime
from scrapy.http import Request
from urllib import parse
from ArticleSpider.items import jobboleArticleSpiderItem,JoboleMySqlItem # 自己目录下的文件
import hashlib # 将哈希package引进
# 继承scrapy.Spider
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
# 允许的域名
allowed_domains = ['blog.jobbole.com']
#开始页面
start_urls = ['http://blog.jobbole.com/all-posts/']
#这里我设置一个数值控制爬取的页面数
crawlpage=0
# 必须重载的函数,对数据做处理
def parse(self, response):
# xpath选择器找到自己要选择的元素,据说这样的比beautifulsoup处理速度快
# 取页面下文章节点,后对节点处理
all_post_node = response.xpath("//div[@class = 'post floated-thumb']//div[@class = 'post-thumb']")
# 取下一页地址
next_parse_url = response.xpath('//a[@class = "next page-numbers"]/@href').extract()[0]
# 遍历节点,获取文章url和照片的url
for post_node in all_post_node:
post_url = post_node.xpath('./a/@href').extract_first("")
post_url = parse.urljoin(response.url, post_url) #添上域名,防止只带部分域名的链接
image_url = post_node.xpath('.//a/img/@src').extract_first("")
image_url = parse.urljoin(response.url, image_url) # 添上域名,防止只带部分域名的链接
# yield出去,这是一个迭代器
yield Request(post_url, meta={"front_image_url": image_url}, callback=self.parse_content) #请求到页面后作为参数,callback到函数prase_content
# 下一页url
if next_parse_url:
self.crawlpage=self.crawlpage+1
# 这里只爬取四个3个下一页
if self.crawlpage< 3:
next_parse_url=parse.urljoin(response.url,next_parse_url)
# 这里是把下一页reaponse作为参数,回调给自己处理,再取各url
yield Request(next_parse_url, callback=self.parse)
def parse_content(self,response):
front_image_url = response.meta.get("front_image_url","") #封面图
tags = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/a/text()").extract()[0] #标签
title = response.xpath("//div[@class = 'entry-header']/h1/text()").extract()[0] #标题
create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").re(".*?(\d+/\d+/\d+)")[0] #创建日期
try:
create_date = datetime.datetime.strptime(create_date, "%y/%m/%d").date()
except Exception as e:
create_date = datetime.datetime.now().date()
content =''.join( response.xpath("//div[@class = 'entry']/p/text()").extract()) #部分内容
# 点赞数
praise_number = response.xpath('//span[@class = " btn-bluet-bigger href-style vote-post-up register-user-only "]/h10/text()').extract()
if praise_number:
praise_number = int(praise_number[0])
else:
praise_number = 0
# 评论数
comment_num = response.xpath('//span[@class = "btn-bluet-bigger href-style hide-on-480"]').re(".*(\d+).*")
if comment_num:
comment_num = int(comment_num[0])
else:
comment_num = 0
# 实例化自己写的item 对象,填充数据
article_item = JoboleMySqlItem()
article_item["front_image_url"] = [front_image_url]
article_item["front_image_path"]= "path/image"
article_item["url"] = response.url
article_item["url_object_id"] = self.get_md5(response.url)
article_item["tags"] = tags
article_item["title"] = title
article_item["create_date"] = create_date
article_item["content"] = content
article_item["praise_number"] = praise_number
article_item["comment_num"] = comment_num
# 将item抛出去,给其他需要的调用
yield article_item
def get_md5(url):
# 在PY3中默认字符集是unicode编码, 要转换为utf-8
if isinstance(url, str):
url = url.encode("utf-8")
m = hashlib.md5()
m.update(url)
return m.hexdigest() # 返回哈希摘要
2、同时因该在item中吧表格做出来,item可以理解为一个暂存数据的容器
到item.py文件下
class JoboleMySqlItem(scrapy.Item):
front_image_url = scrapy.Field() # 封面图
front_image_path = scrapy.Field() # 封面图本地存放路径
url = scrapy.Field() # 内容url
url_object_id = scrapy.Field() # 什么md5,限定什么url长度
tags = scrapy.Field() # 标签
title = scrapy.Field() # 标题
create_date = scrapy.Field() # 创建日期
content = scrapy.Field() # 部分内容
praise_number = scrapy.Field() # 点赞数
comment_num = scrapy.Field() # 评论数
# 这里把数据库的语句准备好,这样pipeline就可以直接调用而不用理会item写了什么
def get_insert_sql(self):
sql_insert="""insert into article_jobbole(front_image_path, front_image_url,
url,url_object_id, tag, title, create_date, content, praise_number, comment_num)
values(%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)"""
params=(self['front_image_path'], self['front_image_url'], self['url'],
self['url_object_id'], self['tags'], self['title'],
self['create_date'], self['content'], self['praise_number'],
self['comment_num'])
return sql_insert, params3、管道pipeline.py保存数据到数据库,这里采用异步存储,毕竟爬取速度是比较快的
# scrapy基于是twisted框架的,提供的异步机制adbapi
from twisted.enterprise import adbapi
# 写一个异步存储数据库的class
class MyTwistedMysqlPipline(object):
# connect mysql use dict to post the info
def __init__(self):
conn_param= {
"host":"localhost",
"user":"root",
"passwd":"12345",
"db":"spider_article",
"cursorclass": MySQLdb.cursors.DictCursor,
"charset": "utf8mb4"
}
self.dbpool= adbapi.ConnectionPool("MySQLdb",**conn_param)
def process_item(self, item, spider):
# 开始异步,对自定义函数do_insert,可对返回值做异常处理
return_info = self.dbpool.runInteraction(self.do_insert, item)
return_info.addErrback(self.error_info)
def do_insert(self, cursor, item):
sql_insert,params= item.get_insert_sql()
cursor.execute(sql_insert, params)
def error_info(self, failure):
print(failure)pipeline的存储类必须在setting中注册,
ITEM_PIPELINES = {
#'ArticleSpider.pipelines.ArticlespiderPipeline': 300,
'ArticleSpider.pipelines.MyTwistedMysqlPipline': 2,
}
# 后面的数字是管道处理的优先级至此数据的爬取基本可以了。
当然人家肯定会反爬虫的,很多网站其实设置个user-agent池 就可以了。request的时候携带上就可以,之前讲过可以在中间件middleware.py中设置
# middlewares时scrapy框架中可以对请求信息或者返回信息做处理的模块
# 此处方法是先在setting 中设置好一个user-agent的list ,然后在此处对request做处理
class Random_UserAgent_Middleware(object):
# 可以定义请求时附加头信息
# def __init__(self, crawler):
# super(Random_UserAgent_Middleware, self).__init__() # 首先找到test的父类(比如是类A),然后把类test的对象self转换为类A的对象,然后“被转换”的类A对象调用自己的__init__函数
# self.user_agent_list= crawler.settings.get("USER_AGENT_LIST", [])
# self.ua= self.random_ua(self.user_agent_list)
#
# @classmethod
# def from_crawler(cls, crawler):
# return cls(crawler)
def __init__(self):
self.ua_list= settings.USER_AGENT_LIST
self.ua= self.random_ua(self.ua_list)
def process_request(self, request, spider):
request.headers.setdefault("User-Agent",self.ua)
#request.headers.setdefault("Cookies",settings.MyCookies)
#request.cookies=('Cookies',settings.MyCookies)
# get_ip= GetRandomIp()
# request.meta["proxy"]= get_ip.get_random_ip()
def random_ua(self, user_angent_list):
# 取的随机user_agent
random_index= random.randint(0, len(user_angent_list)-1)
return user_angent_list[random_index]这里只是我采用的一种方法,还有更简单的方法是在github上有专门处理user-agent的:https://github.com/hellysmile/fake-useragent
而我是从这里获取user-agent的:https://fake-useragent.herokuapp.com/browsers/0.1.7
# 当然,在这里也可以设置ip池(上面我注释的部分),我爬取的是西刺ip代理的代理ip,可以参考我令一篇博客
至此爬取完成。
二、flask构建超级简单的搜索引擎
1、pycharm创建flask工程。
简单说一下flask工程,app.py是处理的逻辑,static文件下放css, js,templates下放html文件
app.py 下:
@app.route('/')
def hello_world():
return render_template('search.html')当运行后相当于启动了一个小服务器,进入网站(比如是:http://localhost:5000)时,直接返回search.html页面。
2、我的search.html页面是:
WstmSearch
(好简陋啊!)创建一个form点击搜索则以post的形式将搜索的keyword发送到搜索的处理逻辑处“/wstmsearch”
app.py下:
@app.route('/wstmsearch', methods=['GET', 'POST'])
def wstm_search():
#搜索结果list,用来给result.html传数据
search_result=[]
#当接受到post请求时
if request.method== 'POST':
#取出待搜索keyword
keyword= request.form['keyword']
#对keyword分词
cut_keywords= jieba.cut_for_search(keyword)
# 遍历所有切分出来的词,搜索数据库,这里不想做去重了
for cut_keyword in cut_keywords:
search_result.extend(sql_query(cut_keyword))
#记录搜到了多少数据
search_nums= len(search_result)
return render_template('search_result.html',search_result=search_result, search_nums=search_nums, keyword=keyword)
return render_template('search.html')
# 数据库查询操作
def sql_query(keyword):
# 我把数据库的连接放在了新建的config.py下
with db.cursor() as cursor:
sql= "select url, title, content, create_date from article_jobbole where title like '%{keyword}%' or content like '%{keyword}%'".format(keyword=keyword)
cursor.execute(sql)
result=cursor.fetchall()
return result
数据库连接:
db= pymysql.connect(host='localhost',
user='root',
password='12345',
db='spider_article',
charset='utf8',
cursorclass=pymysql.cursors.DictCursor)这里我的result.html:
WstmSearchResult
找到约 {{ search_nums }} 条结果
{% for search in search_result %}
{% autoescape off %}{{ search.content[:100] }}{% endautoescape %}
{{search.create_data}}
{% endfor %}
(同样简陋的操作。。。。)
这里主要学习点其实是jianja2的应用,比如模板,挖坑填坑,还有一些逻辑语句。官方文档:http://jinja.pocoo.org/docs/2.10/
3、一些错误处理
~~> 爬取过程中报错:(1366, "Incorrect string value: '\\xF0\\x9F\\x8C\\xB0\\xE3\\x80...' for column )一番度娘后,,
因为存储的数据中有 emoji 表情到 MySQL 实例,需要应用客户端、到 MySQL 实例的连接、MySQL 实例内部 3 个方面统一使用或者支持 utf8mb4 字符集。
mysql> show character set;
发现我的截至2019/3/31的MySQL版本默认的就是utf8mb4,所以我只在连接时的charset="utf8"改成“utf8mb4”就解决了。
~~> mysql的修改属性列:
mysql>alter table yourtablename alter column column_name varchar(20); #不可用,不知道原因
mysql>alter table yourtablename change old_column_name new_column_name varchar(20); # 可用
这个小项目到此结束。
大家多多指教!!!