MySQL - 分页查询优化的两个案例解析
文章目录
- Table
- 日常场景
- Case1 根据自增且连续的主键排序的分页查询
- 优化
- 数据可删除的场景
- 适用条件
- Case2 根据非主键字段排序的分页查询

Table
还是我们那个老表
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
有个主键索引和二级联合索引 idx_name_age_position
日常场景
任何一个系统,分页查询都是必不可少的吧 ,MySQL中的分页查询 就是 limit呗 ,你有没有感觉到 越往后翻页越慢 ,常见的SQL如下
mysql> select * from employees limit 10000,10;
就是从 employees 中取出从 10001 行开始的 10 行记录。
MySQL是怎么处理这个SQL的呢?
先读取 10010 条记录,然后抛弃前 10000 条记录,仅保留10 条想要的数据 。 可想而知,如果要查询一张大表比较靠后的数据,这效率是非常低的。
那有没有优化的办法呢?
Case1 根据自增且连续的主键排序的分页查询
我们先来看一个 【根据自增且连续主键排序的分页查询】的优化案例
select * from employees limit 10000, 10
从第1万条数据开始,获取10条数据

我们来看下执行计划
mysql> explain select * from employees limit 10000, 10 ;
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 100175 | 100 | NULL |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+-------+
1 row in set
mysql>
因为没有添加单独 order by字段,所以表示通过主键排序 。 执行计划显示全表扫描
优化
如何优化下呢?
既然是按照id排序,结合B+Tree 的特性 ,如果能从 10000这个数据位置往后扫描,是不是就会比扫描全部理论上更快一些呢?
改造如下
select * from employees where id> 10000 limit 10;
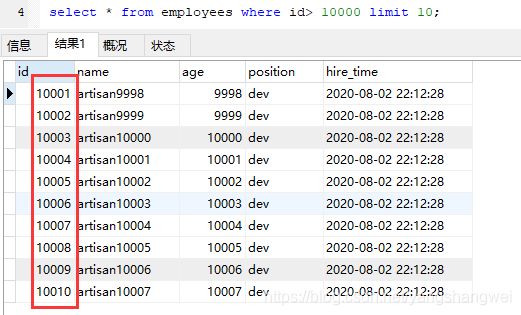
来看下执行计划
mysql> explain select * from employees where id> 10000 limit 10;
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
| 1 | SIMPLE | employees | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 50087 | 100 | Using where |
+----+-------------+-----------+------------+-------+---------------+---------+---------+------+-------+----------+-------------+
1 row in set
比一比这两个,是不是下面那个更快一些

数据可删除的场景
还有个问题,我们知道我们业务系统有些数据是可以被删除的,如果有些数据被删除了,还是按照id来排序,上面这种优化方式,会存在问题吗?
假设8888 这条业务数据被删除了
delete from employees where id = 8888 ;
那我们来看下


如果允许删除,那这种优化方式是不是就不正确了?
-
limit 10000, 10 : 就是全部数据排好序后 取第10000个开始后的10个,我们刚才删除了8888, 所以 第一条数据就变成了 10002
-
id> 10000 limit 10 : 这个就很好理解了,删除了8888 ,不影响 id>10000的排序 ,所以第一条数据还是 10001
适用条件
如果主键不连续,不能使用上面描述的优化方法。
如果原 SQL 是 order by 非主键的字段,按照上的方法改写会导致两条 SQL 的结果不一致。
所以这种优化方式必须同时满足以下两个条件:
- 主键自增且连续
- 结果是按照主键排序的
Case2 根据非主键字段排序的分页查询
来看第二个案例,实际工作中可能比第一种用的比较多
select * from employees ORDER BY name limit 10000, 10 ;

来看下执行计划
mysql> explain select * from employees ORDER BY name limit 10000, 10 ;
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 100175 | 100 | Using filesort |
+----+-------------+-----------+------------+------+---------------+------+---------+------+--------+----------+----------------+
1 row in set
mysql>
按照B+Tree的结构,应该会走name字段索引,wtf , 操作的结果集太多,又要回表等等原因 , MySQL可能不选name 字段的索引 , key 字段对应的值为 null ,从而走了全表扫描 。。。。
还有 Using filesort
这部分就属于MySQL内部的优化了,可以使用Trace来追踪下MySQL是如何选择的 ,
MySQL - 使用trace工具来窥探MySQL是如何选择执行计划的
MySQL认为扫描整个索引并查找到没索引的行(可能要遍历多个索引树)的成本比扫描全表的成本更高,所以优化器放弃使用索引。
那既然知道不走索引的原因,那么怎么优化呢?
关键是让排序时返回的字段尽可能少,所以可以让排序和分页操作先查出主键,然后根据主键查到对应的记录.
让排序时返回的字段尽可能少–》 只返回id , 然后用返回的特定范围的id ,再和原表关联,只取特定范围内的数据 ,肯定比全表扫描要快。
改造如下
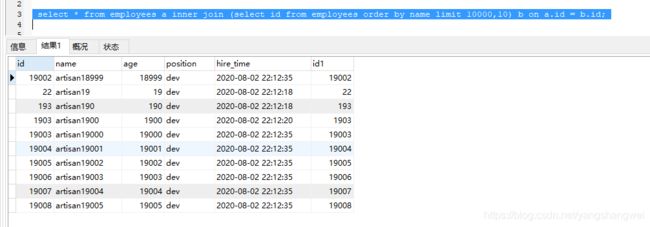
select * from employees a inner join (select id from employees order by name limit 10000,10) b on a.id = b.id;
先找到id (select id 使用覆盖索引),然后用这个结果集 (这个案例中就只有10条结果)去和 employees 关联
看看执行计划

原 SQL 使用的是 filesort 排序,优化后的 SQL 使用的是索引排序。
当然了,结果集也是和优化前是一致的