一、状态编程
Flink 内置的很多算子,数据源 source,数据存储 sink 都是有状态的,流中的数据都是 buffer records,会保存一定的元素或者元数据。例如 : ProcessWindowFunction会缓存输入流的数据,ProcessFunction 会保存设置的定时器信息等等。
1,算子状态(operator state)
算子状态的作用范围限定为算子任务。这意味着由同一并行任务所处理的所有数据都可以访问到相同的状态,状态对于同一任务而言是共享的。Flink为算子状态提供三种基本数据结构:
列表状态(List state):将状态表示为一组数据的列表。
联合列表状态(Union list state):也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
广播状态(Broadcast state):如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
2,键控状态(keyed state)
键控状态是根据输入数据流中定义的键(key)来维护和访问的。具有相同 key 的所有数据都会访问相同的状态。Flink 的 Keyed State 支持以下数据类型:
ValueState[T]保存单个的值,值的类型为 T。 get 操作: ValueState.value() set 操作: ValueState.update(value: T) ListState[T]保存一个列表,列表里的元素的数据类型为 T。基本操作如下: ListState.add(value: T) ListState.addAll(values: java.util.List[T]) ListState.get()返回 Iterable[T] ListState.update(values: java.util.List[T]) MapState[K, V]保存 Key-Value 对。 MapState.get(key: K) MapState.put(key: K, value: V) MapState.contains(key: K) MapState.remove(key: K) ReducingState[T] AggregatingState[I, O] State.clear()是清空操作。
案例:判断两个相邻的评分之间差值,如果大于10就输出当前key对应的这两次评分。
自定义继承RichFlatMapFunction
val resultDStream:DataStream[(String,Double,Double)] = stream.keyBy(_.id) .flatMap(new MyKeyedState(10.0)) //keyby之后再进行自定义的聚合
//输入为id,输入为(id,lastRate,currentRate) class MyKeyedState(diff:Double) extends RichFlatMapFunction[Item,(String,Double,Double)]{ //记录上次的评分 var lastRateState:ValueState[Double] = _ override def open(parameters: Configuration): Unit = { //初始化上次的评分 lastRateState = getRuntimeContext.getState[Double](new ValueStateDescriptor[Double]("rate",Types.of[Double])) } override def flatMap(value: Item, out: Collector[(String, Double, Double)]): Unit = { val currentRate = value.rate val lastRate = lastRateState.value() if (lastRate != 0 && (lastRate - currentRate).abs > diff) { //不是第一次进入并且差值大于10 out.collect((value.id,lastRate,currentRate)) } lastRateState.update(currentRate) } }
使用flatMapWithState
val resultDStream:DataStream[(String,Double,Double)] = stream.keyBy(_.id) .flatMapWithState[(String,Double,Double),Double]{ case (item:Item,None)=> //如果state为None表示是第一次,此时给定初始值即可 (List.empty,Some(item.rate)) case (item:Item,last:Some[Double])=> //如果有值的情况下就是判定和输出 val lastRate = last.getOrElse(0) val currentRate = item.rate if (lastRate != 0 && (lastRate - currentRate).abs > 10.0) { //不是第一次进入并且差值大于10 (List((item.id,lastRate,currentRate)),Some(currentRate)) }else{ (List.empty,Some(currentRate)) } }
二、状态一致性
1,一致性级别
在流处理中,一致性可以分为3个级别:
at-most-once: 这其实是没有正确性保障的委婉说法 ——故障发生之后,计数结果可能丢失。 同样的还有 udp。 at-least-once: 这表示计数结果可能大于正确值,但绝不会小于正确值。 也就是说,计数程序在发生故障后可能多算,但是绝不会少算。 exactly-once: 这指的是系统保证在发生故障后得到的计数结果与正确值一致。
Flink 的一个重大价值在于,它既保证了 exactly-once,也具有低延迟和高吞吐的处理能力。
2,端到端(end-to-end)状态一致性
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件。具体可以划分如下:
内部保证 — — 依赖 checkpoint
source端 — — 需要外部源可重设数据的读取位置
sink端 — — 需要保证从故障恢复时,数据不会重复写入外部系统
而对于sink端,又有两种具体的实现方式:幂等( Idempotent)写入和事务性( Transactional)写入。
幂等:所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了
事务性:需要构建事务来写入外部系统,构建的事务对应着checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入sink 系统中。
对于事务性写入,具体又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)。DataStream API 提供了 GenericWriteAheadSink 模板类和TwoPhaseCommitSinkFunction 接口。

三、检查点(checkpoint)
1,检查点算法(图解)
简介:有两个source:source1和source2,这两个source均接收到(1,2,3,4,5,6,7,8,9...)等数据
第一步,jobmanager接收到checkpoint编号为2的数据,如下图:
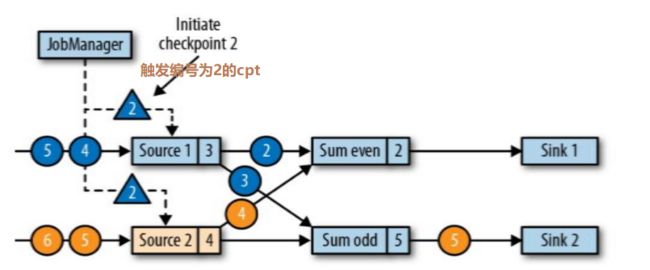
第二步,source停止接收checkpoint编号为2之后的数据,产生对应的barrier屏障。直到状态后端(state backends)存入对应的检查点之后,返回给source任务,待JobManager通知确认检查点完成。如图:
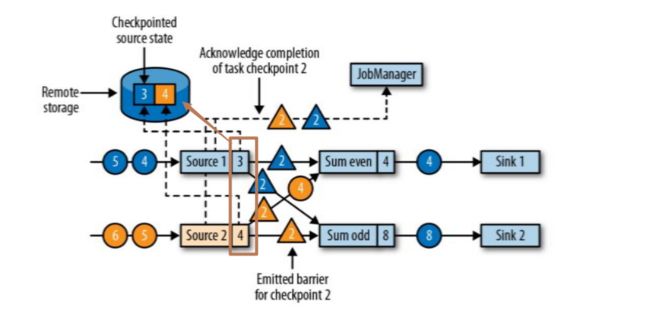
第三步,barrier对齐:等待所有source分区中标记相同检查点编号的数据到达处理完成之后再进行当前barrier(例如当前蓝色4数据是source1中cpt2之后的数据,故而先不做计算,会存入缓存直到当前黄色标记的cpt2之前的数据全部处理完毕)。如图:
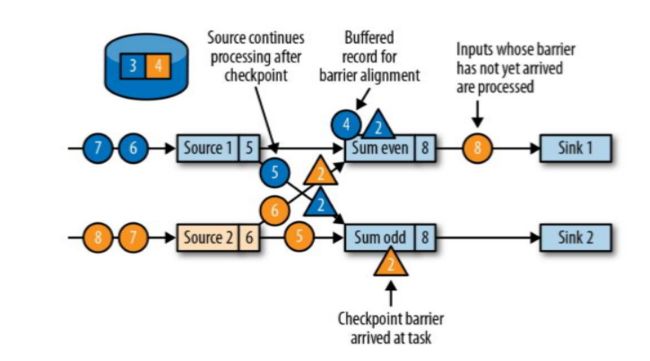
当收到所有输入分区的 barrier 时,任务就将其状态保存到状态后端的检查点中,然后将 barrier 继续向下游转发。如图:
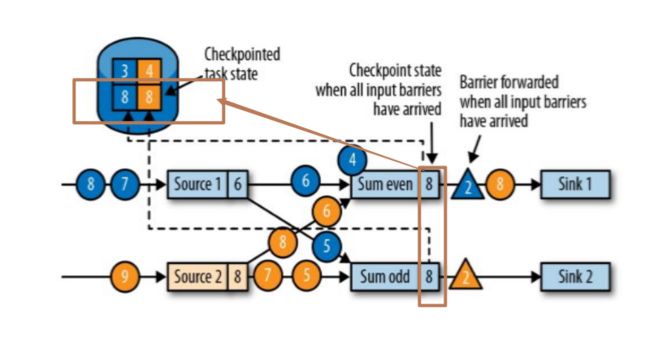
第四步:Sink 任务向 JobManager 确认状态保存到 checkpoint 完毕,当所有任务都确认已成功将状态保存到检查点时,检查点就真正完成了。如图:

Flink 检查点算法的正式名称是异步分界线快照(asynchronous barrier snapshotting)。该算法大致基于Chandy-Lamport 分布式快照算法。
检查点是 Flink 最有价值的创新之一,因为它使 Flink 可以保证 exactly-once,并且不需要牺牲性能。
2,Flink+Kafka实现exactly-once
端到端的状态一致性的实现,需要每一个组件都实现,对于 Flink + Kafka 的数据管道系统(Kafka 进、Kafka 出)而言,各组件怎样保证 exactly-once 语义呢?
内部 — — 利用 checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性。
source — — kafka consumer 作为 source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
sink — — kafka producer 作为 sink,采用两阶段提交 sink,需要实现一个 TwoPhaseCommitSinkFunction
执行过程实际上是一个两段式提交,每个算子执行完成,会进行“预提交”,直到执行完sink 操作,会发起“确认提交”,如果执行失败,预提交会放弃掉。
具体的两阶段提交步骤总结如下:
第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”
jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
外部 kafka 关闭事务,提交的数据可以正常消费了。
3,状态后端(state backend)
env.setStateBackend(new MemoryStateBackend()) env.setStateBackend(new FsStateBackend("checkpointDataUri")) env.setStateBackend(new RocksDBStateBackend("checkpointDataUri"))
a)MemoryStateBackend
内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在 TaskManager 的 JVM 堆上;而将checkpoint 存储在 JobManager 的内存中。
b)FsStateBackend
将checkpoint 存到远程的持久化文件系统(FileSystem)上。 而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上。
c)RocksDBStateBackend
将所有状态序列化后,存入本地的 RocksDB 中存储。
使用RocksDB需要添加依赖:
org.apache.flink flink-statebackend-rocksdb_2.11 1.7.2