Content Provider之间互相通信的源码浅析
写在前面:本文是根据大神的博客http://blog.csdn.net/luoshengyang/article/details/6967204,对android5.0系统进行了分析
一、个人理解
分析之前先说一下,自己对Content Provider进程间通信的基本理解。个人认为,Android中进程间通信的套路都是基本一致。基本和AIDL差不多。其实AIDL本身就是用来在进程之间通信的。这里先说一下进程间通信的大体套路。假设client进程要向server进程传递数据或访问数据,首先,两个进程要拥有相同的接口(假设为A),因为我们我们要使他们的对象相同,做到面向对象编程,即调用client进程的A对象,就像调用server进程的A对象一样。第二,进程间的通信是用代理模式来实现的,所以在server进程要有一个真正用于提供服务的类AA(实现了A),在client进程会有一个AProxy类,用来代表AA,这样我们在client做的操作就可以有Aproxy传到server的AA中了。第三,既然是进程间通信,那么Binder也是必不可少的。它会将在client端所做的操作传递到server端。这里我们附一张图来说明一下: 现在我们以content provider,来看一下进程间通信的实现机制:
现在我们以content provider,来看一下进程间通信的实现机制: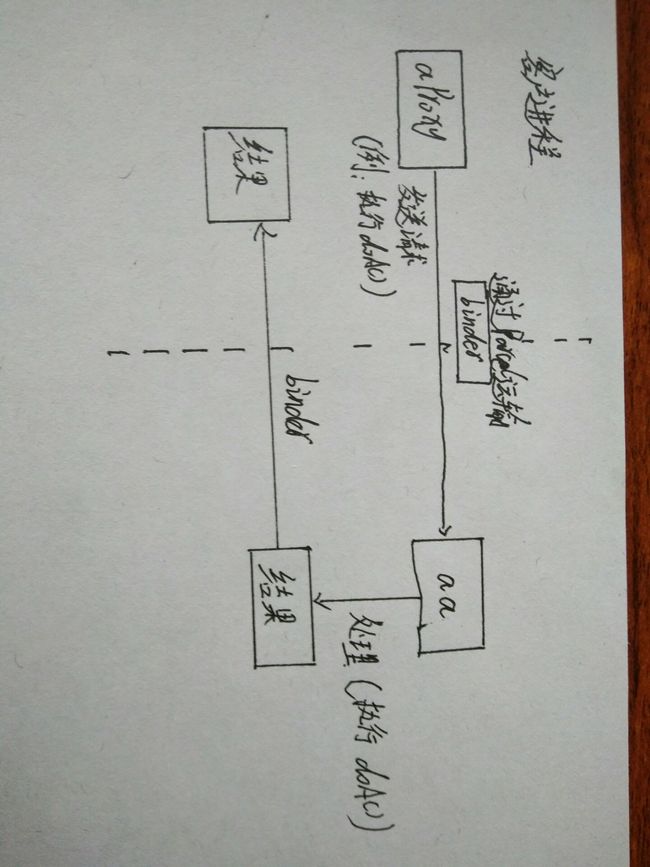 。
。
好了,回到正题,说一下content provider的通信。它的通信和进程间的通信是基本一致的,但是,它也有些不同,在Content Provider的通信中会有一个CursorWindow类,它的作用是用来储存查询到的数据,client端和server端会共享这个CursorWindow类型的对象,从而实现数据的交流。
二、content provider通信分析
1、client端provider的获得
在上一节我们说过content provider的启动。content provider启动的最后阶段,会调用AMS的getContentProvider()方法来返回一个ContentProviderHolder型的holder对象,它里面包含了已经加载好的provider对象,但是这里的provider对象并不是真正的服务端的provider对象,而是一个ContentProviderProxy对象,它里面包含了用于进程间通信的binder。下面让我们来看一下这个ContentProviderProxy对象是如何获得的:
1.1获得holder:
holder = ActivityManagerNative.getDefault().getContentProvider(
getApplicationThread(), auth, userId, stable);1.2ActivityManagerProxy的getContentProvider()
public ContentProviderHolder getContentProvider(IApplicationThread caller,
String name, int userId, boolean stable) throws RemoteException {
......
mRemote.transact(GET_CONTENT_PROVIDER_TRANSACTION, data, reply, 0);
......
ContentProviderHolder cph = null;
if (res != 0) {
cph = ContentProviderHolder.CREATOR.createFromParcel(reply);
}
data.recycle();
reply.recycle();
return cph;
}1.3这里的mBinder是AMS进程发过来的binder对象,用来和真正的AMS通信,从上面的代码可以看出,它会向真正的AMS请求provider对象,具体实现如下:
case GET_CONTENT_PROVIDER_TRANSACTION: {
data.enforceInterface(IActivityManager.descriptor);
IBinder b = data.readStrongBinder();
IApplicationThread app = ApplicationThreadNative.asInterface(b);
......
ContentProviderHolder cph = getContentProvider(app, name, userId, stable);
reply.writeNoException();
if (cph != null) {
reply.writeInt(1);
cph.writeToParcel(reply, 0);
} else {
reply.writeInt(0);
}
return true;
}public void writeToParcel(Parcel dest, int flags) {
info.writeToParcel(dest, 0);
if (provider != null) {
dest.writeStrongBinder(provider.asBinder());
} else {
dest.writeStrongBinder(null);
}
dest.writeStrongBinder(connection);
dest.writeInt(noReleaseNeeded ? 1 : 0);
}写入完毕之后,把reply返回给client进程。这样client进程就可以在reply中获得已经加载好的provider。这样和AMS进程间的通信就已经完成了。下一步就是把它转化成client端的provider,即ContentProviderProxy对象。
1.4我们来看一下ContentProviderHolder.CREATOR.createFromParcel(reply)是如何实现的:
public static final Parcelable.Creator CREATOR
= new Parcelable.Creator() {
@Override
public ContentProviderHolder createFromParcel(Parcel source) {
return new ContentProviderHolder(source);
}
@Override
public ContentProviderHolder[] newArray(int size) {
return new ContentProviderHolder[size];
}
}; private ContentProviderHolder(Parcel source) {
info = ProviderInfo.CREATOR.createFromParcel(source);
provider = ContentProviderNative.asInterface(
source.readStrongBinder());
connection = source.readStrongBinder();
noReleaseNeeded = source.readInt() != 0;
}2、使用provider进行数据的查询
2.1ContentProviderProxy的query()
public Cursor query(String callingPkg, Uri url, String[] projection, String selection,
String[] selectionArgs, String sortOrder, ICancellationSignal cancellationSignal)
throws RemoteException {
BulkCursorToCursorAdaptor adaptor = new BulkCursorToCursorAdaptor();
Parcel data = Parcel.obtain();
Parcel reply = Parcel.obtain();
try {
data.writeInterfaceToken(IContentProvider.descriptor);
//省略查询参数的封装
......
data.writeStrongBinder(adaptor.getObserver().asBinder());
data.writeStrongBinder(cancellationSignal != null ? cancellationSignal.asBinder() : null);
mRemote.transact(IContentProvider.QUERY_TRANSACTION, data, reply, 0);
DatabaseUtils.readExceptionFromParcel(reply);
if (reply.readInt() != 0) {
BulkCursorDescriptor d = BulkCursorDescriptor.CREATOR.createFromParcel(reply);
adaptor.initialize(d);
} else {
adaptor.close();
adaptor = null;
}
return adaptor;
}
......
}2.2ContentProviderNative的onTransact
case QUERY_TRANSACTION:
{
data.enforceInterface(IContentProvider.descriptor);
//参数获得
......
Cursor cursor = query(callingPkg, url, projection, selection, selectionArgs,
sortOrder, cancellationSignal);
if (cursor != null) {
CursorToBulkCursorAdaptor adaptor = null;
try {
adaptor = new CursorToBulkCursorAdaptor(cursor, observer,
getProviderName());
cursor = null;
BulkCursorDescriptor d = adaptor.getBulkCursorDescriptor();
adaptor = null;
reply.writeNoException();
reply.writeInt(1);
d.writeToParcel(reply, Parcelable.PARCELABLE_WRITE_RETURN_VALUE);
} finally {
// Close cursor if an exception was thrown while constructing the adaptor.
if (adaptor != null) {
adaptor.close();
}
if (cursor != null) {
cursor.close();
}
}
} else {
reply.writeNoException();
reply.writeInt(0);
}
return true;
}2.3SQLiteDataBase的queryWithFactory()
public Cursor queryWithFactory(CursorFactory cursorFactory,
boolean distinct, String table, String[] columns,
String selection, String[] selectionArgs, String groupBy,
String having, String orderBy, String limit, CancellationSignal cancellationSignal) {
acquireReference();
try {
String sql = SQLiteQueryBuilder.buildQueryString(
distinct, table, columns, selection, groupBy, having, orderBy, limit);
return rawQueryWithFactory(cursorFactory, sql, selectionArgs,
findEditTable(table), cancellationSignal);
} finally {
releaseReference();
}
}2.4SQLiteDataBase的awQueryWithFactory()
public Cursor rawQueryWithFactory(
CursorFactory cursorFactory, String sql, String[] selectionArgs,
String editTable, CancellationSignal cancellationSignal) {
acquireReference();
try {
SQLiteCursorDriver driver = new SQLiteDirectCursorDriver(this, sql, editTable,
cancellationSignal);
return driver.query(cursorFactory != null ? cursorFactory : mCursorFactory,
selectionArgs);
} finally {
releaseReference();
}
}在这里会生成一个driver对象,然后用此driver进行数据查询
2.5SQLiteCursorDriver的query()
public Cursor query(CursorFactory factory, String[] selectionArgs) {
final SQLiteQuery query = new SQLiteQuery(mDatabase, mSql, mCancellationSignal);
final Cursor cursor;
try {
query.bindAllArgsAsStrings(selectionArgs);
if (factory == null) {
cursor = new SQLiteCursor(this, mEditTable, query);
} else {
cursor = factory.newCursor(mDatabase, this, mEditTable, query);
}
} catch (RuntimeException ex) {
query.close();
throw ex;
}
mQuery = query;
return cursor;
}得到cursor后,就可以用此cursor来生成一个server端的CursorToBulkCursorAdaptor类型的adaptor对象了,然后用此adaptor,生成一个BulkCursorDescriptor 类型的对象。
2.6CursorToBulkCursorAdaptor的getBulkCursorDescriptor()
public BulkCursorDescriptor getBulkCursorDescriptor() {
synchronized (mLock) {
throwIfCursorIsClosed();
BulkCursorDescriptor d = new BulkCursorDescriptor();
d.cursor = this;
d.columnNames = mCursor.getColumnNames();
d.wantsAllOnMoveCalls = mCursor.getWantsAllOnMoveCalls();
d.count = mCursor.getCount();
d.window = mCursor.getWindow();
if (d.window != null) {
// Acquire a reference to the window because its reference count will be
// decremented when it is returned as part of the binder call reply parcel.
d.window.acquireReference();
}
return d;
}
}2.7SQLiteCursor的getCount()
public int getCount() {
if (mCount == NO_COUNT) {
fillWindow(0);
}
return mCount;
}2.8SQLiteCursor的fillWindow()
private void fillWindow(int requiredPos) {
clearOrCreateWindow(getDatabase().getPath());
try {
if (mCount == NO_COUNT) {
int startPos = DatabaseUtils.cursorPickFillWindowStartPosition(requiredPos, 0);
mCount = mQuery.fillWindow(mWindow, startPos, requiredPos, true);
mCursorWindowCapacity = mWindow.getNumRows();
if (Log.isLoggable(TAG, Log.DEBUG)) {
Log.d(TAG, "received count(*) from native_fill_window: " + mCount);
}
} else {
int startPos = DatabaseUtils.cursorPickFillWindowStartPosition(requiredPos,
mCursorWindowCapacity);
mQuery.fillWindow(mWindow, startPos, requiredPos, false);
}
}
......
}2.9AbstractWindowedCursor的clearOrCreateWindow()
protected void clearOrCreateWindow(String name) {
if (mWindow == null) {
mWindow = new CursorWindow(name);
} else {
mWindow.clear();
}
}2.10SQLiteQuery的fillWindow()
int fillWindow(CursorWindow window, int startPos, int requiredPos, boolean countAllRows) {
acquireReference();
try {
window.acquireReference();
try {
int numRows = getSession().executeForCursorWindow(getSql(), getBindArgs(),
window, startPos, requiredPos, countAllRows, getConnectionFlags(),
mCancellationSignal);
return numRows;
}
.......
}requiredPos:可以用来指示出mWindow的最大容量
在此代码块中,会去调用SQLiteSession的executeForCursorWindow(),这里简单说一下SQLiteSession这个类,它是一个会话,被用来查询数据库的数据,保存了与数据库的连接,有一个连接池;并且,在每个线程中,对应一个数据库,都有一个session。它由SQLiteDataBase提供。
2.11SQLiteSession的executeForCursorWindow()
public int executeForCursorWindow(String sql, Object[] bindArgs,
CursorWindow window, int startPos, int requiredPos, boolean countAllRows,
int connectionFlags, CancellationSignal cancellationSignal) {
......
acquireConnection(sql, connectionFlags, cancellationSignal); // might throw
try {
return mConnection.executeForCursorWindow(sql, bindArgs,
window, startPos, requiredPos, countAllRows,
cancellationSignal); // might throw
} finally {
releaseConnection(); // might throw
}
}
最后,我们终于得到了填满数据的mWindow,这样就可将其封装到BulkCursorDescriptor类型的对象d中,然后将其放到要发送的Parcel中。
2.12BulkCursorDescriptor的writeToParcel()
public void writeToParcel(Parcel out, int flags) {
out.writeStrongBinder(cursor.asBinder());
out.writeStringArray(columnNames);
out.writeInt(wantsAllOnMoveCalls ? 1 : 0);
out.writeInt(count);
if (window != null) {
out.writeInt(1);
window.writeToParcel(out, flags);
} else {
out.writeInt(0);
}
}3client端对数据的接收
BulkCursorDescriptor d = BulkCursorDescriptor.CREATOR.createFromParcel(reply);
adaptor.initialize(d);client端会将发过来的数据整合成一个BulkCursorDescriptor类型的对象,然后用其实例化一个BulkCursorToCursorAdaptor类型的对象adaptor,并将其作为Cursor类型的对象返回,这样,我们在client端就可以进行数据的增删该查了