图模型+Bert香不香?完全基于注意力机制的图表征学习模型Graph-Bert

作者 | Jiawei Zhang、Haopeng Zhang、Congying Xia、Li Sun
译者 | 凯隐
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
【导读】本文提出了一种全新的图神经网络 Graph-Bert,仅仅基于 Attention 机制而不依赖任何类卷积或聚合操作即可学习图的表示,并且完全不考虑节点之间的连接信息。通过将原始图分解为以每个节点为中心的多个子图来学习每个节点的表征信息,这不仅能解决图模型的预训练问题,还能通过并行处理还提高效率。

论文地址:
https://arxiv.org/abs/2001.05140
简介
传统的图神经网络存在许多严重影响模型性能的问题,例如模型假死和过于平滑问题。模型假死和过于平滑都可以归结于传统 GNN 的类卷积特征学习方式以及基于聚合操作(mean,max,sum)的信息更新方式,这会导致随着模型层数加深,模型会逐渐丧失对输入的响应,因此一般GNN都是只堆叠不超过两层。同时,模型学习到的不同节点的表征信息也会愈发相似,从而变得无法区分。此外,由于传统GNN都考虑图中的固有内在连接(即边),因此无法对图数据进行并行化处理。
为了解决以上问题,本文提出了Graph-Bert,Bert 是一个用于NLP的模型,其核心在于 attention 机制,将这种机制拓展到图结构数据上,便是 Graph-Bert。Graph-Bert 将原始图采样为多个子图,并且只利用attention机制在子图上进行表征学习,而不考虑子图中的边信息。因此Graph-Bert可以解决上面提到的传统GNN具有的性能问题和效率问题。
此外,传统 GNN 受限于图结构的多样性,无法进行跨任务的预训练,而 Graph-Bert 由于不考虑图中的边信息,因此并不受限于图结构,可以很好地进行预训练和迁移学习。
模型结构介绍
Graph-Bert 主要由四部分组成:
1、将原始图分解为无边子图(不考虑子图中的边信息)
2、节点输入特征的嵌入表示
3、基于图transformer的节点表征学习编码器,编码器的输出作为学习到的节点特征表示。
4、基于图transformer的解码器

(一)无边子图分解
这部分对应上图中的step1,主要将原始输入图分解为多个子图,每个子图都包含一个中心节点和固定数量的邻居节点,邻居节点就代表了中心节点的上下文信息,因此如何为中心节点选取邻居节点是这一步的关键。方法有很多种,本文采用的是top-K关系值方法,类似于KNN算法,计算每个节点与其他所有节点的关联(intimacy)程度,然后选取关系值最大的前K个点作为邻接节点。关系矩阵的计算方法采用pagerank算法:
![]()
![]() 表示列归一化(随机游走归一化)的邻接矩阵A,即
表示列归一化(随机游走归一化)的邻接矩阵A,即 ![]() ,D 是度矩阵,注意A和D都是相对于输入图而言的。给定图G以及该图的关系矩阵S,那么就可以得到图中任意节点vi的上下文信息:
,D 是度矩阵,注意A和D都是相对于输入图而言的。给定图G以及该图的关系矩阵S,那么就可以得到图中任意节点vi的上下文信息:
![]()
这里节点vi的邻居节点vj既可以是距离较近的,也可以是距离较远的,并不局限于边连接。
(二)节点输入特征嵌入表示
节点的排序
不同于图片像素和句子中的词,图的节点并没有明确的顺序,理论上我们在表示节点特征时,交换任何两个节点在矩阵中的顺序都不应该影响最终结果(置换不变性),然而在用矩阵表示节点特征信息时,矩阵的行/列必须和权重矩阵(例如FC层)列/行进行对应,否则即便是同一特征矩阵,在不同的行排列下也会得到不同的计算结果,这显然是不合理的。因此还是需要按照一定的顺序来对每个子图的输入节点特征向量(矩阵)进行排序,从而得到特征矩阵(张量)。这里按照前面计算得到的关联值由大到小进行排序。
特征向量嵌入表示
通过四种方法来逐步得到每个节点特征向量的嵌入表示:
1、原始特征向量嵌入
![]()
这一步主要将原始特征嵌入到一个新的特征空间,对于不同类型的输入数据可以使用不同的Embed函数,例如对于图片可以使用CNN,对于序列信息则可以使用LSTM。
2、Weisfeiler-Lehman 绝对角色嵌入
这一步学习每个节点在全局图(即输入图)中的唯一表示,通过WL算法完成。WL算法根据节点在图中的结构位置来标记节点,结构位置相同的节点会得到相同的标记,这里的结构位置是指节点在完整图(而不是子图)中的位置,因此与子图无关。节点的WL绝对角色嵌入向量计算方法为:
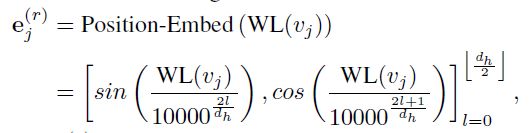
这一步主要是获取节点全局位置的信息,详细细节可以参考原文。
3、基于关联值的相对位置嵌入
相较于上一步基于WL的全局位置嵌入,这一步主要是获取节点在子图中的局部信息:
![]()
P是一个位置函数,对于中心节点vi,P(vi)=1,对于其他的周围节点vj,和vi关联值越大,P(vj)越小。
4、基于节点距离的相对距离嵌入
这一步主要是平衡上面两步的嵌入值,通过计算两个节点在原始图(考虑边)中的相隔的边距离来计算嵌入值:
![]()
由于这一步是基于全局图的,因此不同子图中的相同节点之间得到的H值是相同的。
(三)基于编码-解码器的图Transformer
谷歌提出的Transformer模型是一种基于全attention的sequence to sequence模型,在NLP任务上取得了比LSTM更好的成绩。这里将Transformer方法推广到了图结构数据。首先将上面计算到的四种嵌入表示聚合,以作为编码器的输入:
![]()
聚合方法可以有多种,例如max, sum, mean等。之后通过多层attention操作来逐步更新节点的表示:
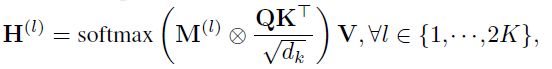
QKV都是输入特征矩阵H(l-1)的复制,这里额外添加了一个mask矩阵M,可以学习到子图的上下文信息。
整个Transoformer包含2K层,前K层是编码器,后K层是解码器,通过自回归来监督训练,最终编码器的输出即为学习到的节点特征表示zi。此外还在编码器输入和输入之间添加了res连接。
Graph-Bert预训练与微调
主要介绍 Graph-Bert 在图表征学习任务中的预训练和微调,对于预训练,主要考虑节点属性重建以及图结构恢复任务,对于表征学习相关应用,主要考虑节点分类和图聚类任务。
(一)模型预训练
1、节点原始特征重建
如何从学习到的节点特征表示中还原原始输入特征是采用预训练模型时需要关注的点:
![]()
在监督时自然采用和编码-解码器相同的监督方式:
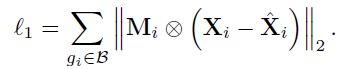
考虑到节点的特征可能非常稀疏,这里额外加入了一个Mask矩阵:
![]()
![]()
2、图结构重建
通过图结构重建来保证模型能学习到图的结构信息,该任务依然是作为预训练任务。图的结构可以用一个标签向量y来表示,yij表示节点i和j之间的连接关系,包含两个值(i->j, j->i),因此我们需要预测的是:
![]()
损失函数采用多类交叉熵损失函数即可:
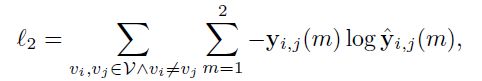
考虑到图比较稀疏时,大部分节点之间都没有连接(例如对于一个总节点数为100,平均1阶邻居节点数为5的图,其邻接矩阵就有95%的地方为0),需要对负例(即无连接的节点对)进行采样来保证正负例平衡。
通过将上述两种不同的学习任务与变量正则化项结合,我们可以定义正式训练前的目标函数。通过优化该目标函数将有助于对Graph-Bert进行有效的预训练。
(二)模型迁移与微调
在将Graph-Bert应用在新任务中时,既可以直接使用模型学习到的图特征表示,也可以根据实际情况做一些必要的调整。这里主要考虑节点分类和图聚类任务,其中图聚类任务可以直接使用学习到的特征表示,而节点分类还需要做一些调整。
1、节点分类
通过额外添加FC层和softmax来进行节点分类:
![]()
相应的损失函数为:

因此额外需要训练的就是FC层,通过将FC层和原来的Graph-Bert结合,并重新训练,就可以完成节点分类的任务。
2、图聚类
图聚类主要是将图中的节点分为多类,由于聚类属于非监督的无参算法,因此不需要额外添加权重,直接在学习到的节点特征上进行聚类即可,使用诸如K-means的算法就可以完成,需要优化的目标函数为:

该函数中仍然包含了一些变量,可以用EM算法来高效地学习,而不是反向传播。
总结
本文提出的Graph-Bert模型属于Bert模型在图结构数据上的拓展,在一定程度上降低了对节点间固有连接的依赖,使得模型可以更好的进行预训练和并行计算。笔者个人认为这种思想和点云很相似,具体区别还有待探究。
(*本文为AI科技大本营翻译文章,转载请微信联系 1092722531)
◆
精彩推荐
◆
1、评选进行中,参与投票即有机会参与抽奖,60+公开课免费学习

2、【Python Day——北京站】现已正式启动,「新春早鸟票」火热开抢!2020年,我们还将在全国多个城市举办巡回活动,敬请期待!活动咨询,可扫描下方二维码加入官方交流群~
CSDN「Python Day」咨询群 ????
来~一起聊聊Python

如果群满100人,无法自动进入,可添加会议小助手微信:婷婷,151 0101 4297(电话同微信)
推荐阅读
疫情严重,潜伏期也有传染性?科技公司在行动
召唤超参调优开源新神器:集XGBoost、TensorFlow、PyTorch、MXNet等十大模块于一身
5个可以帮助你提高工作效率的新AI工具
亚马逊机器学习服务:深入研究AWS SageMaker
从4个月到7天,Netflix开源Python框架Metaflow有何提升性能的魔法?
管理7k+工作流,月运行超10000万次,Lyft开源的Flyte平台意味着什么?
伯克利新无监督强化学习方法:减少混沌所产生的突现行为
机器推理文本+视觉,跨模态预训练新进展

你点的每个“在看”,我都认真当成了AI