MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文阅读心得
本文提出了一种称为MobileNets的模型,该模型适用于移动和嵌入式视觉应用。MobileNets使用深度可分离的卷积来构建轻型深度神经网络,并引入两个简单的全局超参数,有效地在延迟和精度之间权衡,这些超参数允许模型构建者根据问题的约束条件来为他们的应用选择合适大小的模型。
卷积神经网络总的发展趋势是创造更深更复杂的网络,以达到更高的精度,但精度的进步不一定会使网络在大小和速度方面提高效率,但是在很多现实的应用中,识别任务需要在一个计算有限的平台上及时进行。本文描述了一种高效的网络架构和两个超参数,以建立非常小的,低延迟的模型,可以很容易地匹配移动和嵌入式视觉应用的设计要求,允许开发者为他们的应用专门选择与资源限制(延迟、大小)相匹配的小型网络。
MobileNets的核心层是可深度分离的滤波器,两个全局超参数 width multiplier(宽度乘法器) 和 resolution multiplier(分辨率乘法器)。
深度可分离卷积
深度可分离卷机是一种因子话卷积形式,将标准卷积因子化为深度卷积和1×1卷积,对于MobileNets来说,深度卷积对每个输入通道都应用一个滤波器。然后,点向卷积应用1×1卷积来组合深度卷积的输出。
标准卷积既能对输入进行过滤,又能在一步内将输入合并成一组新的输出。深度可分离卷积将其分成两层,一层用于过滤,另一层用于合并。这种因子化的效果是大幅减少计算量和模型大小。
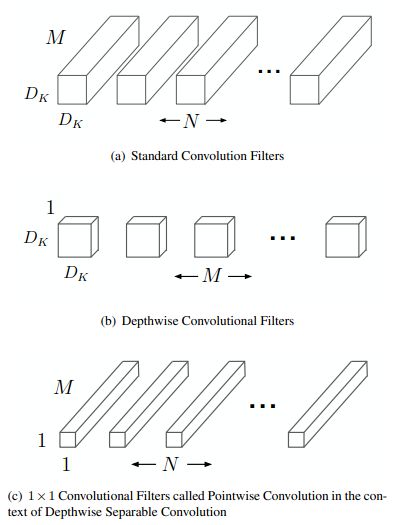
假设,标准卷积层以D_F×D_F×M特征图F为输入,生成D_F×D_F×N特征图G,卷积核K的参数量为 D_K × D_K x M x N
则标准卷积的计算量为:
D_K × D_K × M× N× D_F × D_F
深度可分卷积的计算量为(深度卷积 + 1×1卷积):
D_K × D_K × M × D_F × D_F+ M× N× D_F × D_F
MobileNet使用3×3的深度可分离卷积,比标准卷积减少了8到9倍的计算量,但精度却只降低了一小部分
网络结构和训练
下图中左边是标准卷积,右边是深度可分离卷积,MobileNet第一层采用标准卷积,其它层均采用深度可分解卷积。

MobileNet结构图:

宽度参数
虽然基本的MobileNet架构已经是小型和低延迟的,但很多时候,特定的用例或应用可能会要求模型更小和更快.为了构建这些更小和计算成本更低的模型,我们引入了一个非常简单的参数α。
宽度倍增器α的作用是使网络在每层均匀地变薄。对于给定的层数和宽度乘数α,输入通道数M变为αM,输出通道数N变为αN。其中α∈(0,1],典型的设置为1,0.75,0.5和0.25.α=1为基线MobileNet,α<1为缩小MobileNets,α的作用是降低计算成本和参数数量,大约减少α^2其计算量为:
D_K × D_K × αM × D_F × D_F x αM+ αM x αN × D_F × D_F
分辨率参数
分辨率乘数用来改变输入数据层的分辨率,将其应用到输入图像上,随后每一层的内部表示都会被同样的乘数所减少,其中ρ∈(0,1],通常隐式设置,使网络的输入分辨率为224、192、160或128.ρ=1为基线MobileNet,ρ<1为减少计算的MobileNets。分辨率乘法器的作用是将计算成本降低ρ^2,计算量为:
D_K × D_K × αM × ρD_F × ρD_F x αM+ αM x αN × ρD_F × ρD_F
代码训练
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''Depthwise conv + Pointwise conv'''
def __init__(self, in_planes, out_planes, stride=1):
super(Block, self).__init__()
# Depthwise 卷积,3*3 的卷积核,分为 in_planes,即各层单独进行卷积
self.conv1 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=in_planes, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
# Pointwise 卷积,1*1 的卷积核
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(out_planes)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
return out
创建DataLoader
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
100%
169934848/170498071 [00:03<00:00, 51474007.21it/s]
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
创建MobileNetV1网络
32×32×3 ==>
32×32×32 ==> 32×32×64 ==> 16×16×128 ==> 16×16×128 ==>
8×8×256 ==> 8×8×256 ==> 4×4×512 ==> 4×4×512 ==>
2×2×1024 ==> 2×2×1024
接下来为均值 pooling ==> 1×1×1024
最后全连接到 10个输出节点
class MobileNetV1(nn.Module):
# (128,2) means conv planes=128, stride=2
cfg = [(64,1), (128,2), (128,1), (256,2), (256,1), (512,2), (512,1),
(1024,2), (1024,1)]
def __init__(self, num_classes=10):
super(MobileNetV1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.linear = nn.Linear(1024, num_classes)
def _make_layers(self, in_planes):
layers = []
for x in self.cfg:
out_planes = x[0]
stride = x[1]
layers.append(Block(in_planes, out_planes, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.avg_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
实例化网络
# 网络放到GPU上
net = MobileNetV1().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
模型训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.324
Epoch: 1 Minibatch: 101 loss: 1.727
Epoch: 1 Minibatch: 201 loss: 1.507
Epoch: 1 Minibatch: 301 loss: 1.473
Epoch: 2 Minibatch: 1 loss: 1.689
Epoch: 2 Minibatch: 101 loss: 1.173
Epoch: 2 Minibatch: 201 loss: 1.355
Epoch: 2 Minibatch: 301 loss: 1.168
Epoch: 3 Minibatch: 1 loss: 1.298
Epoch: 3 Minibatch: 101 loss: 1.010
Epoch: 3 Minibatch: 201 loss: 1.028
Epoch: 3 Minibatch: 301 loss: 1.044
Epoch: 4 Minibatch: 1 loss: 0.807
Epoch: 4 Minibatch: 101 loss: 0.886
Epoch: 4 Minibatch: 201 loss: 1.164
Epoch: 4 Minibatch: 301 loss: 0.976
Epoch: 5 Minibatch: 1 loss: 0.786
Epoch: 5 Minibatch: 101 loss: 0.709
Epoch: 5 Minibatch: 201 loss: 0.893
Epoch: 5 Minibatch: 301 loss: 0.838
Epoch: 6 Minibatch: 1 loss: 0.733
Epoch: 6 Minibatch: 101 loss: 1.085
Epoch: 6 Minibatch: 201 loss: 0.775
Epoch: 6 Minibatch: 301 loss: 0.524
Epoch: 7 Minibatch: 1 loss: 0.901
Epoch: 7 Minibatch: 101 loss: 0.693
Epoch: 7 Minibatch: 201 loss: 0.622
Epoch: 7 Minibatch: 301 loss: 0.698
Epoch: 8 Minibatch: 1 loss: 0.624
Epoch: 8 Minibatch: 101 loss: 0.703
Epoch: 8 Minibatch: 201 loss: 0.849
Epoch: 8 Minibatch: 301 loss: 0.711
Epoch: 9 Minibatch: 1 loss: 0.447
Epoch: 9 Minibatch: 101 loss: 0.621
Epoch: 9 Minibatch: 201 loss: 0.509
Epoch: 9 Minibatch: 301 loss: 0.749
Epoch: 10 Minibatch: 1 loss: 0.449
Epoch: 10 Minibatch: 101 loss: 0.622
Epoch: 10 Minibatch: 201 loss: 0.480
Epoch: 10 Minibatch: 301 loss: 0.335
Finished Training
模型测试
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 77.88 %
MobileNetV2: Inverted Residuals and Linear Bottlenecks
本文介绍了一种新的移动端架构MobileNetV2,它进一步提高了移动模型在多个任务和基准上以及在不同模型大小的范围内的最佳性能,除此之外还介绍了如何通过全新框架 SSDLite 将这些模型高效应用于目标检测。展示了通过简化版 DeepLabv3( Mobile DeepLabv3)构建移动端的语义分割方法。
现代最先进的网络需要高计算资源,超出了许多移动和嵌入式应用的能力。本文介绍了一种新的神经网络架构,它是专门为移动和资源受限的环境量身定做的。该网络推动了移动定制计算机视觉模型的发展,在保持相同精度的前提下,大大减少了操作次数和所需内存。主要贡献是一个新颖的层模块:线性瓶颈的反残差。该模块将一个低维压缩表示作为输入,首先将其扩展到高维,并用轻量级深度卷积进行过滤。随后,特征将被投射回一个线性卷积的低维表示。
MobileNet V1 的主要问题:结构非常简单,但是没有使用RestNet里的residual learning;另一方面,Depthwise Conv确实是大大降低了计算量,但实际中,发现不少训练出来的kernel是空的。
V2的改进点:
-
Linear Bottlenecks:去掉了小维度输出层后面的非线性激活层,目的是为了保证模型的表达能力。 好处:通过去掉Eltwise+ 的特征去掉ReLU, 减少ReLU对特征的破坏
v1中使用width multiplier参数来做模型通道的缩减,使特征信息集中在缩减后的通道中,其后使用非线性激活ReLU,会产生较大的信息丢失。为了减少信息损失,v2使用linear bottleneck,在bottleneck的输出后接线性激活。
-
Inverted Residual block:和residual block中维度先缩减再扩增正好相反,因此shotcut也就变成了连接的是维度缩减后的feature map。好处:1.复用特征,2.旁支block内先通过1x1升维, 再接depthwise conv以及ReLU, 通过增加ReLU的InputDim, 来缓解特征的退化情况

ResNet中的bottleneck,先用1x1卷积把通道数由256降到64,然后进行3x3卷积,不然中间3x3卷积计算量太大。所以bottleneck是两边宽中间窄(也是名字的由来)。
现在我们中间的3x3卷积可以变成Depthwise,计算量很少了,所以通道可以多一些。所以MobileNet V2 先用1x1卷积提升通道数,然后用Depthwise 3x3的卷积,再使用1x1的卷积降维。作者称之为Inverted residual block,中间宽两边窄。
代码练习
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
class Block(nn.Module):
'''expand + depthwise + pointwise'''
def __init__(self, in_planes, out_planes, expansion, stride):
super(Block, self).__init__()
self.stride = stride
# 通过 expansion 增大 feature map 的数量
planes = expansion * in_planes
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, groups=planes, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes)
# 步长为 1 时,如果 in 和 out 的 feature map 通道不同,用一个卷积改变通道数
if stride == 1 and in_planes != out_planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_planes))
# 步长为 1 时,如果 in 和 out 的 feature map 通道相同,直接返回输入
if stride == 1 and in_planes == out_planes:
self.shortcut = nn.Sequential()
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
# 步长为1,加 shortcut 操作
if self.stride == 1:
return out + self.shortcut(x)
# 步长为2,直接输出
else:
return out
创建MobileNetV2网络
因为CIFAR10 是 32*32,因此,网络有一定修改
class MobileNetV2(nn.Module):
# (expansion, out_planes, num_blocks, stride)
cfg = [(1, 16, 1, 1),
(6, 24, 2, 1),
(6, 32, 3, 2),
(6, 64, 4, 2),
(6, 96, 3, 1),
(6, 160, 3, 2),
(6, 320, 1, 1)]
def __init__(self, num_classes=10):
super(MobileNetV2, self).__init__()
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.layers = self._make_layers(in_planes=32)
self.conv2 = nn.Conv2d(320, 1280, kernel_size=1, stride=1, padding=0, bias=False)
self.bn2 = nn.BatchNorm2d(1280)
self.linear = nn.Linear(1280, num_classes)
def _make_layers(self, in_planes):
layers = []
for expansion, out_planes, num_blocks, stride in self.cfg:
strides = [stride] + [1]*(num_blocks-1)
for stride in strides:
layers.append(Block(in_planes, out_planes, expansion, stride))
in_planes = out_planes
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layers(out)
out = F.relu(self.bn2(self.conv2(out)))
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
创建Dataloader
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
98%
167813120/170498071 [00:11<00:00, 13980137.46it/s]
Extracting ./data/cifar-10-python.tar.gz to ./data
Files already downloaded and verified
实例化网络
# 网络放到GPU上
net = MobileNetV2().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
模型训练
for epoch in range(10): # 重复多轮训练
for i, (inputs, labels) in enumerate(trainloader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 输出统计信息
if i % 100 == 0:
print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item()))
print('Finished Training')
Epoch: 1 Minibatch: 1 loss: 2.319
Epoch: 1 Minibatch: 101 loss: 1.569
Epoch: 1 Minibatch: 201 loss: 1.369
Epoch: 1 Minibatch: 301 loss: 1.352
Epoch: 2 Minibatch: 1 loss: 1.168
Epoch: 2 Minibatch: 101 loss: 1.140
Epoch: 2 Minibatch: 201 loss: 1.066
Epoch: 2 Minibatch: 301 loss: 0.997
Epoch: 3 Minibatch: 1 loss: 0.835
Epoch: 3 Minibatch: 101 loss: 0.887
Epoch: 3 Minibatch: 201 loss: 1.112
Epoch: 3 Minibatch: 301 loss: 0.971
Epoch: 4 Minibatch: 1 loss: 0.896
Epoch: 4 Minibatch: 101 loss: 0.813
Epoch: 4 Minibatch: 201 loss: 0.705
Epoch: 4 Minibatch: 301 loss: 0.861
Epoch: 5 Minibatch: 1 loss: 0.658
Epoch: 5 Minibatch: 101 loss: 0.595
Epoch: 5 Minibatch: 201 loss: 0.788
Epoch: 5 Minibatch: 301 loss: 0.565
Epoch: 6 Minibatch: 1 loss: 0.735
Epoch: 6 Minibatch: 101 loss: 0.505
Epoch: 6 Minibatch: 201 loss: 0.531
Epoch: 6 Minibatch: 301 loss: 0.617
Epoch: 7 Minibatch: 1 loss: 0.566
Epoch: 7 Minibatch: 101 loss: 0.567
Epoch: 7 Minibatch: 201 loss: 0.653
Epoch: 7 Minibatch: 301 loss: 0.539
Epoch: 8 Minibatch: 1 loss: 0.568
Epoch: 8 Minibatch: 101 loss: 0.477
Epoch: 8 Minibatch: 201 loss: 0.559
Epoch: 8 Minibatch: 301 loss: 0.575
Epoch: 9 Minibatch: 1 loss: 0.522
Epoch: 9 Minibatch: 101 loss: 0.534
Epoch: 9 Minibatch: 201 loss: 0.416
Epoch: 9 Minibatch: 301 loss: 0.416
Epoch: 10 Minibatch: 1 loss: 0.555
Epoch: 10 Minibatch: 101 loss: 0.429
Epoch: 10 Minibatch: 201 loss: 0.428
Epoch: 10 Minibatch: 301 loss: 0.390
Finished Training
模型测试
correct = 0
total = 0
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %.2f %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 80.62 %
HybridSN: Exploring 3D-2D CNN Feature Hierarchy for Hyperspectral Image Classification
本文提出了一种混合光谱卷积神经网络(Hybrid Spectral Convolutional Neural Network,HybridSN)用于HSI分类。3D-CNN有利于从光谱波段的堆叠中联合进行空间-光谱特征表示。在3D-CNN基础上的2D-CNN进一步学习更多抽象层次的空间表示。此外,与单独使用3D-CNN相比,混合CNN的使用降低了模型的复杂性。
仅仅使用2D-CNN或3D-CNN分别存在一些缺点,如通道关系信息缺失或模型非常复杂。这也使得这些方法在高光谱图像上无法达到较好的精度。主要原因是由于高光谱图像是体积数据,也有光谱维度。单纯的2D-CNN并不能从光谱维度中提取出良好的判别特征图。同样,深层的3D-CNN在计算上也比较复杂,单独使用3D-CNN对于在许多光谱波段上具有相似纹理的类似乎表现更差。这就是我们提出一种混合CNN模型的动机,它克服了之前模型的这些缺点。3D-CNN和2D-CNN层为所提出的模型进行了组装,使它们充分地利用了频谱以及空间特征图,以达到最大可能的精度。
网络模型

2D-CNN
在2D-CNN中,输入数据与2D卷积核进行卷积,卷积是通过计算输入数据与卷积核之间的点积之和实现的,卷积核在输入数据上进行跨越处理以覆盖整个空间维度,同时通过激活函数来引入模型中的非线性
生成公式:

方程左边为在二维卷积中,第i层第j个特征图中空间位置(x,y)的激活值
右边ϕ 为激活函数, bi,j为偏差参数,dl−1 为l-1层的特征图数目和第i层第j个特征图的卷积核 wi,j 是深度,2γ+12γ+1 是卷积核的宽度, 2δ+12δ+1 是卷积核的高度,wi,j 是第i层第j个特征图的权重参数值
3D-CNN
3D-CNN是通过对三维数据和三维卷积核进行卷积实现的,在所提出的HSI数据模型中,卷积层的特征图是利用三维卷积核在输入层的多个连续波段上生成的
生成公式:

该公式是在二维卷积基础上得到的,其中2η+12η+1是 沿光谱维度的卷积核深度
HybridSN
CNN的参数,如偏置b和内核权重w,通常采用监督方法,借助梯度下降优化技术进行训练。在传统的二维CNN中,只在空间维度上应用卷积,覆盖上一层的所有特征图,计算二维判别特征图。而对于恒生指数分类问题,则需要捕捉光谱信息,在空间信息的同时,还需要对多个波段进行编码。2D-CNNs无法处理频谱信息。另一方面,3D-CNN内核可以同时从HSI数据中提取光谱和空间特征表示,但代价是增加了计算复杂性。为了发挥二维CNN和三维CNN的自动特征学习能力的优势,提出了一个混合特征学习框架——HybridSN,它由三个3D卷积(方程2),一个2D卷积(方程1)和三个完全连接的层组成。
代码练习
! wget http://www.ehu.eus/ccwintco/uploads/6/67/Indian_pines_corrected.mat
! wget http://www.ehu.eus/ccwintco/uploads/c/c4/Indian_pines_gt.mat
! pip install spectral
import numpy as np
import matplotlib.pyplot as plt
import scipy.io as sio
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, accuracy_score, classification_report, cohen_kappa_score
import spectral
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
定义HybridSN类
三维卷积部分:
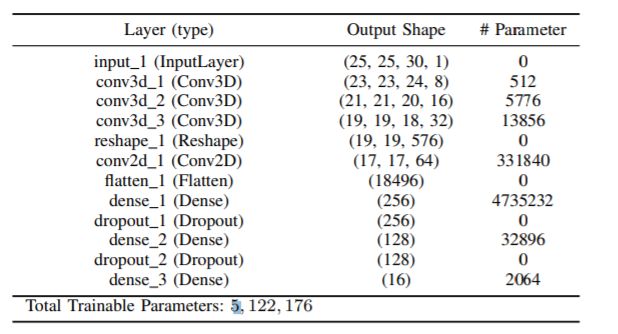
conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==> (8, 24, 23, 23)
conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)
二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
接下来是一个 flatten 操作,变为 18496 维的向量,
接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout,
最后输出为 16 个节点,是最终的分类类别数。
下面是 HybridSN 类的代码:
class_num = 16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
# 3个三维卷积
# conv1:(1, 30, 25, 25), 8个 7x3x3 的卷积核 ==> (8, 24, 23, 23)
self.conv1_3d = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0)
self.relu1 = nn.ReLU()
# conv2:(8, 24, 23, 23), 16个 5x3x3 的卷积核 ==>(16, 20, 21, 21)
self.conv2_3d = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0)
self.relu2 = nn.ReLU()
# conv3:(16, 20, 21, 21),32个 3x3x3 的卷积核 ==>(32, 18, 19, 19)
self.conv3_3d = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0)
self.relu3 = nn.ReLU()
# 二维卷积:(576, 19, 19) 64个 3x3 的卷积核,得到 (64, 17, 17)
self.conv4_2d = nn.Conv2d(576,64,(3,3))
self.relu4 = nn.ReLU()
# 接下来依次为256,128节点的全连接层,都使用比例为0.4的 Dropout
self.fn1 = nn.Linear(18496,256)
self.fn2 = nn.Linear(256,128)
self.fn3 = nn.Linear(128,16)
self.drop = nn.Dropout(p = 0.4)
def forward(self, x):
out = self.conv1_3d(x)
out = self.relu1(out)
out = self.conv2_3d(out)
out = self.relu2(out)
out = self.conv3_3d(out)
out = self.relu3(out)
# 接下来要进行二维卷积,因此把前面的 32*18 reshape 一下,得到 (576, 19, 19)b为batchsize x*y=32*16 m,n=19
b,x,y,m,n = out.size()
out = out.view(b,x*y,m,n)
out = self.conv4_2d(out)
out = self.relu4(out)
# 接下来是一个 flatten 操作,变为 18496 维的向量
# 进行重组,以b行,d列的形式存放(d自动计算)
out = out.reshape(b,-1)
out = self.fn1(out)
out = self.drop(out)
out = self.fn2(out)
out = self.drop(out)
out = self.fn3(out)
return out
# 随机输入,测试网络结构是否通
x = torch.randn(1, 1, 30, 25, 25)
net = HybridSN()
y = net(x)
print(y.shape)
print(y)
torch.Size([1, 16])
tensor([[-0.0237, -0.0012, 0.0278, -0.0022, -0.0091, 0.0228, 0.0856, 0.0145,
0.0022, 0.1151, -0.0260, -0.0542, -0.0494, 0.0858, 0.0233, -0.0473]],
grad_fn=)
创建数据集
首先对高光谱数据实施PCA降维;然后创建 keras 方便处理的数据格式;然后随机抽取 10% 数据做为训练集,剩余的做为测试集。
首先定义基本函数:
# 对高光谱数据 X 应用 PCA 变换
def applyPCA(X, numComponents):
newX = np.reshape(X, (-1, X.shape[2]))
pca = PCA(n_components=numComponents, whiten=True)
newX = pca.fit_transform(newX)
newX = np.reshape(newX, (X.shape[0], X.shape[1], numComponents))
return newX
# 对单个像素周围提取 patch 时,边缘像素就无法取了,因此,给这部分像素进行 padding 操作
def padWithZeros(X, margin=2):
newX = np.zeros((X.shape[0] + 2 * margin, X.shape[1] + 2* margin, X.shape[2]))
x_offset = margin
y_offset = margin
newX[x_offset:X.shape[0] + x_offset, y_offset:X.shape[1] + y_offset, :] = X
return newX
# 在每个像素周围提取 patch ,然后创建成符合 keras 处理的格式
def createImageCubes(X, y, windowSize=5, removeZeroLabels = True):
# 给 X 做 padding
margin = int((windowSize - 1) / 2)
zeroPaddedX = padWithZeros(X, margin=margin)
# split patches
patchesData = np.zeros((X.shape[0] * X.shape[1], windowSize, windowSize, X.shape[2]))
patchesLabels = np.zeros((X.shape[0] * X.shape[1]))
patchIndex = 0
for r in range(margin, zeroPaddedX.shape[0] - margin):
for c in range(margin, zeroPaddedX.shape[1] - margin):
patch = zeroPaddedX[r - margin:r + margin + 1, c - margin:c + margin + 1]
patchesData[patchIndex, :, :, :] = patch
patchesLabels[patchIndex] = y[r-margin, c-margin]
patchIndex = patchIndex + 1
if removeZeroLabels:
patchesData = patchesData[patchesLabels>0,:,:,:]
patchesLabels = patchesLabels[patchesLabels>0]
patchesLabels -= 1
return patchesData, patchesLabels
def splitTrainTestSet(X, y, testRatio, randomState=345):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=testRatio, random_state=randomState, stratify=y)
return X_train, X_test, y_train, y_test
下面读取并创建数据集:
# 地物类别
class_num = 16
X = sio.loadmat('Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('Indian_pines_gt.mat')['indian_pines_gt']
# 用于测试样本的比例
test_ratio = 0.90
# 每个像素周围提取 patch 的尺寸
patch_size = 25
# 使用 PCA 降维,得到主成分的数量
pca_components = 30
print('Hyperspectral data shape: ', X.shape)
print('Label shape: ', y.shape)
print('\n... ... PCA tranformation ... ...')
X_pca = applyPCA(X, numComponents=pca_components)
print('Data shape after PCA: ', X_pca.shape)
print('\n... ... create data cubes ... ...')
X_pca, y = createImageCubes(X_pca, y, windowSize=patch_size)
print('Data cube X shape: ', X_pca.shape)
print('Data cube y shape: ', y.shape)
print('\n... ... create train & test data ... ...')
Xtrain, Xtest, ytrain, ytest = splitTrainTestSet(X_pca, y, test_ratio)
print('Xtrain shape: ', Xtrain.shape)
print('Xtest shape: ', Xtest.shape)
# 改变 Xtrain, Ytrain 的形状,以符合 keras 的要求
Xtrain = Xtrain.reshape(-1, patch_size, patch_size, pca_components, 1)
Xtest = Xtest.reshape(-1, patch_size, patch_size, pca_components, 1)
print('before transpose: Xtrain shape: ', Xtrain.shape)
print('before transpose: Xtest shape: ', Xtest.shape)
# 为了适应 pytorch 结构,数据要做 transpose
Xtrain = Xtrain.transpose(0, 4, 3, 1, 2)
Xtest = Xtest.transpose(0, 4, 3, 1, 2)
print('after transpose: Xtrain shape: ', Xtrain.shape)
print('after transpose: Xtest shape: ', Xtest.shape)
""" Training dataset"""
class TrainDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtrain.shape[0]
self.x_data = torch.FloatTensor(Xtrain)
self.y_data = torch.LongTensor(ytrain)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
""" Testing dataset"""
class TestDS(torch.utils.data.Dataset):
def __init__(self):
self.len = Xtest.shape[0]
self.x_data = torch.FloatTensor(Xtest)
self.y_data = torch.LongTensor(ytest)
def __getitem__(self, index):
# 根据索引返回数据和对应的标签
return self.x_data[index], self.y_data[index]
def __len__(self):
# 返回文件数据的数目
return self.len
# 创建 trainloader 和 testloader
trainset = TrainDS()
testset = TestDS()
train_loader = torch.utils.data.DataLoader(dataset=trainset, batch_size=128, shuffle=True, num_workers=2)
test_loader = torch.utils.data.DataLoader(dataset=testset, batch_size=128, shuffle=False, num_workers=2)
Hyperspectral data shape: (145, 145, 200)
Label shape: (145, 145)
... ... PCA tranformation ... ...
Data shape after PCA: (145, 145, 30)
... ... create data cubes ... ...
Data cube X shape: (10249, 25, 25, 30)
Data cube y shape: (10249,)
... ... create train & test data ... ...
Xtrain shape: (1024, 25, 25, 30)
Xtest shape: (9225, 25, 25, 30)
before transpose: Xtrain shape: (1024, 25, 25, 30, 1)
before transpose: Xtest shape: (9225, 25, 25, 30, 1)
after transpose: Xtrain shape: (1024, 1, 30, 25, 25)
after transpose: Xtest shape: (9225, 1, 30, 25, 25)
开始训练
# 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 网络放到GPU上
net = HybridSN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
# 开始训练
total_loss = 0
for epoch in range(100):
for i, (inputs, labels) in enumerate(train_loader):
inputs = inputs.to(device)
labels = labels.to(device)
# 优化器梯度归零
optimizer.zero_grad()
# 正向传播 + 反向传播 + 优化
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print('[Epoch: %d] [loss avg: %.4f] [current loss: %.4f]' %(epoch + 1, total_loss/(epoch+1), loss.item()))
print('Finished Training')
[Epoch: 1] [loss avg: 22.5323] [current loss: 2.7441]
[Epoch: 2] [loss avg: 22.1352] [current loss: 2.6902]
[Epoch: 3] [loss avg: 21.6159] [current loss: 2.5321]
[Epoch: 4] [loss avg: 21.0273] [current loss: 2.3835]
[Epoch: 5] [loss avg: 20.5831] [current loss: 2.2506]
[Epoch: 6] [loss avg: 20.2141] [current loss: 2.2283]
[Epoch: 7] [loss avg: 19.8481] [current loss: 2.2072]
[Epoch: 8] [loss avg: 19.4836] [current loss: 2.0824]
[Epoch: 9] [loss avg: 19.1653] [current loss: 1.9948]
[Epoch: 10] [loss avg: 18.8324] [current loss: 1.9228]
[Epoch: 11] [loss avg: 18.5302] [current loss: 1.9472]
[Epoch: 12] [loss avg: 18.1838] [current loss: 1.6163]
[Epoch: 13] [loss avg: 17.7052] [current loss: 1.2744]
[Epoch: 14] [loss avg: 17.0751] [current loss: 1.0495]
[Epoch: 15] [loss avg: 16.3665] [current loss: 0.7357]
[Epoch: 16] [loss avg: 15.6642] [current loss: 0.5940]
[Epoch: 17] [loss avg: 14.9263] [current loss: 0.3441]
[Epoch: 18] [loss avg: 14.2067] [current loss: 0.3294]
[Epoch: 19] [loss avg: 13.5468] [current loss: 0.1627]
[Epoch: 20] [loss avg: 12.9278] [current loss: 0.1172]
[Epoch: 21] [loss avg: 12.3564] [current loss: 0.0536]
[Epoch: 22] [loss avg: 11.8348] [current loss: 0.2059]
[Epoch: 23] [loss avg: 11.3465] [current loss: 0.0330]
[Epoch: 24] [loss avg: 10.8945] [current loss: 0.0679]
[Epoch: 25] [loss avg: 10.4769] [current loss: 0.0372]
[Epoch: 26] [loss avg: 10.0960] [current loss: 0.1070]
[Epoch: 27] [loss avg: 9.7392] [current loss: 0.0660]
[Epoch: 28] [loss avg: 9.4051] [current loss: 0.0305]
[Epoch: 29] [loss avg: 9.0999] [current loss: 0.0233]
[Epoch: 30] [loss avg: 8.8171] [current loss: 0.0112]
[Epoch: 31] [loss avg: 8.5483] [current loss: 0.0505]
[Epoch: 32] [loss avg: 8.2920] [current loss: 0.0287]
[Epoch: 33] [loss avg: 8.0493] [current loss: 0.0699]
[Epoch: 34] [loss avg: 7.8239] [current loss: 0.0116]
[Epoch: 35] [loss avg: 7.6111] [current loss: 0.0059]
[Epoch: 36] [loss avg: 7.4038] [current loss: 0.0089]
[Epoch: 37] [loss avg: 7.2086] [current loss: 0.0140]
[Epoch: 38] [loss avg: 7.0260] [current loss: 0.0315]
[Epoch: 39] [loss avg: 6.8525] [current loss: 0.0066]
[Epoch: 40] [loss avg: 6.6910] [current loss: 0.0068]
[Epoch: 41] [loss avg: 6.5313] [current loss: 0.0243]
[Epoch: 42] [loss avg: 6.3790] [current loss: 0.0037]
[Epoch: 43] [loss avg: 6.2328] [current loss: 0.0020]
[Epoch: 44] [loss avg: 6.0923] [current loss: 0.0043]
[Epoch: 45] [loss avg: 5.9595] [current loss: 0.0005]
[Epoch: 46] [loss avg: 5.8330] [current loss: 0.0061]
[Epoch: 47] [loss avg: 5.7100] [current loss: 0.0003]
[Epoch: 48] [loss avg: 5.5929] [current loss: 0.0068]
[Epoch: 49] [loss avg: 5.4805] [current loss: 0.0110]
[Epoch: 50] [loss avg: 5.3761] [current loss: 0.0319]
[Epoch: 51] [loss avg: 5.2724] [current loss: 0.0163]
[Epoch: 52] [loss avg: 5.1746] [current loss: 0.0146]
[Epoch: 53] [loss avg: 5.0795] [current loss: 0.0007]
[Epoch: 54] [loss avg: 4.9892] [current loss: 0.0180]
[Epoch: 55] [loss avg: 4.9014] [current loss: 0.0407]
[Epoch: 56] [loss avg: 4.8194] [current loss: 0.0325]
[Epoch: 57] [loss avg: 4.7389] [current loss: 0.0414]
[Epoch: 58] [loss avg: 4.6588] [current loss: 0.0026]
[Epoch: 59] [loss avg: 4.5844] [current loss: 0.0426]
[Epoch: 60] [loss avg: 4.5092] [current loss: 0.0075]
[Epoch: 61] [loss avg: 4.4375] [current loss: 0.0033]
[Epoch: 62] [loss avg: 4.3676] [current loss: 0.0061]
[Epoch: 63] [loss avg: 4.2990] [current loss: 0.0057]
[Epoch: 64] [loss avg: 4.2325] [current loss: 0.0040]
[Epoch: 65] [loss avg: 4.1691] [current loss: 0.0005]
[Epoch: 66] [loss avg: 4.1086] [current loss: 0.0117]
[Epoch: 67] [loss avg: 4.0524] [current loss: 0.0090]
[Epoch: 68] [loss avg: 3.9993] [current loss: 0.0265]
[Epoch: 69] [loss avg: 3.9426] [current loss: 0.0019]
[Epoch: 70] [loss avg: 3.8877] [current loss: 0.0082]
[Epoch: 71] [loss avg: 3.8350] [current loss: 0.0552]
[Epoch: 72] [loss avg: 3.7836] [current loss: 0.0730]
[Epoch: 73] [loss avg: 3.7334] [current loss: 0.0006]
[Epoch: 74] [loss avg: 3.6859] [current loss: 0.0073]
[Epoch: 75] [loss avg: 3.6389] [current loss: 0.0161]
[Epoch: 76] [loss avg: 3.5935] [current loss: 0.0386]
[Epoch: 77] [loss avg: 3.5497] [current loss: 0.0677]
[Epoch: 78] [loss avg: 3.5067] [current loss: 0.0080]
[Epoch: 79] [loss avg: 3.4645] [current loss: 0.0006]
[Epoch: 80] [loss avg: 3.4220] [current loss: 0.0081]
[Epoch: 81] [loss avg: 3.3804] [current loss: 0.0035]
[Epoch: 82] [loss avg: 3.3399] [current loss: 0.0006]
[Epoch: 83] [loss avg: 3.3007] [current loss: 0.0016]
[Epoch: 84] [loss avg: 3.2624] [current loss: 0.0287]
[Epoch: 85] [loss avg: 3.2248] [current loss: 0.0154]
[Epoch: 86] [loss avg: 3.1879] [current loss: 0.0013]
[Epoch: 87] [loss avg: 3.1516] [current loss: 0.0010]
[Epoch: 88] [loss avg: 3.1163] [current loss: 0.0237]
[Epoch: 89] [loss avg: 3.0835] [current loss: 0.0358]
[Epoch: 90] [loss avg: 3.0516] [current loss: 0.0279]
[Epoch: 91] [loss avg: 3.0193] [current loss: 0.0032]
[Epoch: 92] [loss avg: 2.9876] [current loss: 0.0018]
[Epoch: 93] [loss avg: 2.9567] [current loss: 0.0163]
[Epoch: 94] [loss avg: 2.9279] [current loss: 0.1293]
[Epoch: 95] [loss avg: 2.8986] [current loss: 0.0108]
[Epoch: 96] [loss avg: 2.8731] [current loss: 0.0305]
[Epoch: 97] [loss avg: 2.8465] [current loss: 0.0031]
[Epoch: 98] [loss avg: 2.8197] [current loss: 0.0118]
[Epoch: 99] [loss avg: 2.7923] [current loss: 0.0266]
[Epoch: 100] [loss avg: 2.7655] [current loss: 0.0414]
Finished Training
模型测试
count = 0
# 模型测试
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred_test = outputs
count = 1
else:
y_pred_test = np.concatenate( (y_pred_test, outputs) )
# 生成分类报告
classification = classification_report(ytest, y_pred_test, digits=4)
print(classification)
precision recall f1-score support
0.0 1.0000 0.7561 0.8611 41
1.0 0.9745 0.9214 0.9472 1285
2.0 0.9570 0.8635 0.9078 747
3.0 0.9638 1.0000 0.9816 213
4.0 0.9746 0.9701 0.9724 435
5.0 0.9738 0.9619 0.9678 657
6.0 0.8333 1.0000 0.9091 25
7.0 0.9884 0.9930 0.9907 430
8.0 0.7059 0.6667 0.6857 18
9.0 0.8722 0.9749 0.9207 875
10.0 0.9751 0.9733 0.9742 2210
11.0 0.9228 0.9176 0.9202 534
12.0 0.9672 0.9568 0.9620 185
13.0 0.9381 0.9974 0.9668 1139
14.0 0.9477 0.8876 0.9167 347
15.0 0.7640 0.8095 0.7861 84
accuracy 0.9511 9225
macro avg 0.9224 0.9156 0.9169 9225
weighted avg 0.9525 0.9511 0.9510 9225
备用函数
下面是用于计算各个类准确率,显示结果的备用函数,以供参考
from operator import truediv
def AA_andEachClassAccuracy(confusion_matrix):
counter = confusion_matrix.shape[0]
list_diag = np.diag(confusion_matrix)
list_raw_sum = np.sum(confusion_matrix, axis=1)
each_acc = np.nan_to_num(truediv(list_diag, list_raw_sum))
average_acc = np.mean(each_acc)
return each_acc, average_acc
def reports (test_loader, y_test, name):
count = 0
# 模型测试
for inputs, _ in test_loader:
inputs = inputs.to(device)
outputs = net(inputs)
outputs = np.argmax(outputs.detach().cpu().numpy(), axis=1)
if count == 0:
y_pred = outputs
count = 1
else:
y_pred = np.concatenate( (y_pred, outputs) )
if name == 'IP':
target_names = ['Alfalfa', 'Corn-notill', 'Corn-mintill', 'Corn'
,'Grass-pasture', 'Grass-trees', 'Grass-pasture-mowed',
'Hay-windrowed', 'Oats', 'Soybean-notill', 'Soybean-mintill',
'Soybean-clean', 'Wheat', 'Woods', 'Buildings-Grass-Trees-Drives',
'Stone-Steel-Towers']
elif name == 'SA':
target_names = ['Brocoli_green_weeds_1','Brocoli_green_weeds_2','Fallow','Fallow_rough_plow','Fallow_smooth',
'Stubble','Celery','Grapes_untrained','Soil_vinyard_develop','Corn_senesced_green_weeds',
'Lettuce_romaine_4wk','Lettuce_romaine_5wk','Lettuce_romaine_6wk','Lettuce_romaine_7wk',
'Vinyard_untrained','Vinyard_vertical_trellis']
elif name == 'PU':
target_names = ['Asphalt','Meadows','Gravel','Trees', 'Painted metal sheets','Bare Soil','Bitumen',
'Self-Blocking Bricks','Shadows']
classification = classification_report(y_test, y_pred, target_names=target_names)
oa = accuracy_score(y_test, y_pred)
confusion = confusion_matrix(y_test, y_pred)
each_acc, aa = AA_andEachClassAccuracy(confusion)
kappa = cohen_kappa_score(y_test, y_pred)
return classification, confusion, oa*100, each_acc*100, aa*100, kappa*100
检测结果写在文件里:
classification, confusion, oa, each_acc, aa, kappa = reports(test_loader, ytest, 'IP')
classification = str(classification)
confusion = str(confusion)
file_name = "classification_report.txt"
with open(file_name, 'w') as x_file:
x_file.write('\n')
x_file.write('{} Kappa accuracy (%)'.format(kappa))
x_file.write('\n')
x_file.write('{} Overall accuracy (%)'.format(oa))
x_file.write('\n')
x_file.write('{} Average accuracy (%)'.format(aa))
x_file.write('\n')
x_file.write('\n')
x_file.write('{}'.format(classification))
x_file.write('\n')
x_file.write('{}'.format(confusion))
下面代码用于显示分类结果:
# load the original image
X = sio.loadmat('Indian_pines_corrected.mat')['indian_pines_corrected']
y = sio.loadmat('Indian_pines_gt.mat')['indian_pines_gt']
height = y.shape[0]
width = y.shape[1]
X = applyPCA(X, numComponents= pca_components)
X = padWithZeros(X, patch_size//2)
# 逐像素预测类别
outputs = np.zeros((height,width))
for i in range(height):
for j in range(width):
if int(y[i,j]) == 0:
continue
else :
image_patch = X[i:i+patch_size, j:j+patch_size, :]
image_patch = image_patch.reshape(1,image_patch.shape[0],image_patch.shape[1], image_patch.shape[2], 1)
X_test_image = torch.FloatTensor(image_patch.transpose(0, 4, 3, 1, 2)).to(device)
prediction = net(X_test_image)
prediction = np.argmax(prediction.detach().cpu().numpy(), axis=1)
outputs[i][j] = prediction+1
if i % 20 == 0:
print('... ... row ', i, ' handling ... ...')
... ... row 0 handling ... ...
... ... row 20 handling ... ...
... ... row 40 handling ... ...
... ... row 60 handling ... ...
... ... row 80 handling ... ...
... ... row 100 handling ... ...
... ... row 120 handling ... ...
... ... row 140 handling ... ...
predict_image = spectral.imshow(classes = outputs.astype(int),figsize =(5,5))
