NLU意图识别的流程说明
基于智能问答的业务流程,所谓的NLU意图识别就是针对已知的训练语料(如语料格式为\((x,y)\)格式的元组列表,其中\(x\)为训练语料,\(y\)为期望输出类别或者称为意图)采用选定的算法构建一个模型,而后基于构建的模型对未知的文本进行分类。流程梳理如下:
- 准备训练数据,按照固定的格式进行;
- 抽取所需要的特征,形成特征向量;
- 抽取的特征向量与对应的期望输出(也就是目标label)一起输入到机器学习算法中,训练出一个预测模型;
- 对新到的数据采取同样的特征抽取,得到用于预测的特征向量;
- 使用训练好的预测模型,对处特征处理后的新数据进行预测,并返回结果。
从流程梳理看,NLU的意图识别从根本上看是有监督的机器学习,即基于给定的人工筛选数据进行特征处理,构建模型用于预测。处理流程图如下所示:
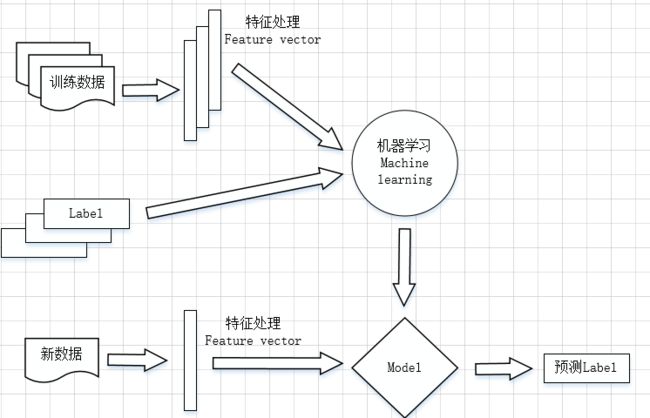
针对NLU意图识别原理的例子说明
基于上述说明的流程,用一个例子来进行原理说明。
场景
小明需要订购一张从上海到北京的机票(意图:订机票),在订票的过程中想要了解下北京的天气情况(意图:查天气),看是否需要准备一把雨伞;同时考虑初到北京对地方不熟悉,希望协助订餐(意图:订餐)。
准备数据
根据第一部分介绍的流程,需要先准备上述场景涉及意图的训练数据,以备模型构建使用,我们准备如下的几条数据(此处为了描述方便,每个意图我们仅提供一条数据进行说明,在实际处理中每个意图至少需要2条语料):
- 帮我查询明天到北京的机票。---------> 订机票
- 北京明天是否有雨?---------> 查天气
- 帮我定个烤鸭送到酒店。---------> 订餐
在第一条的语料“帮我查询明天到北京的机票。”中,我们可以通过实体抽取提取出“时间:明天、目的地:北京”,通过隐含条件可以推算出出发地为上海(基于用户当前的定位数据等),这部分信息可以作为对话过程中的关键信息收集起来,作为后续的订票主要信息。因此处我们主要介绍意图识别,对于实体提取的一些处理流程不做具体的介绍。
特征提取
特征的提取是为了方便后续的计算,在中文文本处理中,常用的特征处理有词袋模型(bag of word)、Tf-idf、SVD奇异值分解等,这里为了方便说明,我们采用词袋模型(bag of word)。特征权重的计算方法采用简单的\(1/n\)进行,其中\(n\)为所有语料中该词出现的个数。
针对上文的数据,首先构造词典,利用jieba分词,对上述语料进行分词,而后统计各个词的权重,结果如下所示:
"帮我查询明天到北京的机票。"分词结果如下:
['帮', '我', '查询', '明天', '到', '北京', '的', '机票', '。']
"北京明天是否有雨?"分词结果如下:
['北京', '明天', '是否', '有雨', '?']
"帮我定个烤鸭送到酒店。"分词结果如下:
['帮', '我定', '个', '烤鸭', '送到', '酒店', '。']
整合后的词典及词权重如下所示:
['帮':0.5, '我':1.0, '查询':1.0, '明天':0.5, '到':1.0, '北京':0.5, '的':1.0, '机票':1.0, '。':0.5, '是否':1.0, '有雨':1.0, '?':1.0, '我定':1.0, '个':1.0, '烤鸭':1.0, '送到':1.0, '酒店':1.0]
模型训练
基于上步构造的词典,对样本数据进行特征权重构造(也就是模型构建的过程,如果是使用神经网络等深度学习技术的话,就是通过样本数据学习各个特征的权重及偏置),如下所示:
"帮我查询明天到北京的机票。"特征如下:
['帮':0.5, '我':1.0, '查询':1.0, '明天':0.5, '到':1.0, '北京':0.5, '的':1.0, '机票':1.0, '。':0.5]
"北京明天是否有雨?"特征如下:
['北京':0.5, '明天':1.0, '是否':1.0, '有雨':1.0, '?':1.0]
"帮我定个烤鸭送到酒店。"特征如下:
['帮':0.5, '我定':1.0, '个':1.0, '烤鸭':1.0, '送到':1.0, '酒店':1.0, '。':0.5]
新数据特征提取
在上述几步流程中,我们已经通过准备的训练数据构建好了预测模型,针对新的数据,需要经过同样的特征提取流程获取新数据的特征向量。
比如新数据为:查询机票。
结巴分词结果如下:
['查询', '机票', '。']
基于构造的词典,获得各个特征的权重如下:
['查询':1.0, '机票':1.0, '。':0.5]
模型预测
通过模型计算新数据与各个类别(意图)的得分(为了方便说明,这里直接比对新数据与各个类别数据特征匹配上的个数,而后计算相关的权重得分),如下所示:
订机票意图特征命中:查询、机票、。
得分:1.0(查询)+1.0(机票)+0.5(。)=2.5
查天气意图特征命中:
得分:0.0(查询)+0.0(机票)+0.0(。)=0.0
订餐意图特征命中:。
得分:0.0(查询)+0.0(机票)+0.5(。)=0.5
采用得分最高作为最终意图,则新数据意图为“订机票”。
备注:在上述的处理过程中,出现了很多的得分为0项,在实际的处理过程中会做平滑处理,常用的平滑处理有\(add-k smoothing、Good-turning\)等平滑方法。
NLU识别引擎中使用的pipline分析
上面是简单的描述了文本分类模型的构建及模型使用的介绍,在实际的场景处理中会比较复杂,本节针对我们在使用RASA框架的NLU模块的一个文本处理pipline进行流程分析说明。
pipline如下所示:
language: "zh"
pipeline:
- name: JiebaTokenizer
- name: CRFEntityExtractor
- name: EntitySynonymMapper
- name: CountVectorsFeaturizer
- name: EmbeddingIntentClassifier
意图识别的三个流程涉及JiebaTokenizer(分词)、CountVectorsFeaturizer(特征向量表示)、EmbeddingIntentClassifier(分类)三个过程,我们主要对上述三个进行说明。
JiebaTokenizer 分词
分词组件这里主要是使用的一个开源分词jieba分词,通过结巴分词将我们的训练语料或者是传入的用户语句进行分词处理,获取分词后的结果。
关注下,语料经过jieba分词后会得到一个词在该条语料中的开始start、结束end位置信息,在最终返回给其他算法处理时仅返回词条在训练语料的开始start位置,结束end信息后续会通过开始start+len(word)的方式获得。
分词的示例:
import jieba
text = "帮我查询明天到北京的机票。"
tokenized = jieba.tokenize(text)
# tokens = [Token(word, start) for (word, start, end) in tokenized]
print(list(tokenized))
[('帮', 0, 1), ('我', 1, 2), ('查询', 2, 4), ('明天', 4, 6), ('到', 6, 7), ('北京', 7, 9), ('的', 9, 10), ('机票', 10, 12), ('。', 12, 13)]
CountVectorsFeaturizer 特征向量表示
CountVectorsFeaturizer 是一种基于特征的tf表示的向量标识方法,其核心思想与上述示例中的基本一致,也是通过对训练集数据经过分词后构建词典,而后针对每一条训练文本统计其特征的相关tf,形成特征向量表示(或者认为是词频矩阵)。这里需要注意下,CountVectorsFeaturizer 中有一些默认参数,会对分词后的数据进行一些处理,比如针对英文的一些大小写转换、针对中文的单字过滤、停用词过滤等操作。
我们仍然使用上文示例中出现的3条语料进行CountVectorsFeaturizer 的表示,示例代码采用sklearn中的CountVectorizer,如下所示:
from sklearn.feature_extraction.text import CountVectorizer
# "帮 我 查询 明天 到 北京 的 机票" 为输入列表元素,即代表一个文章的经过分词后的词,这里为了便于说明去除了其他一些信息,每个语料为一条信息
texts = ["帮 我 查询 明天 到 北京 的 机票", "北京 明天 是否 有雨", "帮 我定 个 烤鸭 送到 酒店"]
# 创建词袋模型
cv = CountVectorizer()
# 词袋模型构建
cv_fit = cv.fit_transform(texts)
# 打印所有的训练语料形成的词典中的词
print(cv.get_feature_names())
结果: ['北京', '我定', '明天', '是否', '有雨', '机票', '查询', '烤鸭', '送到', '酒店']
# 打印所有的训练语料形成的词典及该词在词典中的标号
print(cv.vocabulary_)
结果: {'查询': 6, '明天': 2, '北京': 0, '机票': 5, '是否': 3, '有雨': 4, '我定': 1, '烤鸭': 7, '送到': 8, '酒店': 9}
# 打印出特征的词频标识
print(cv_fit)
结果: (0, 5) 1 0:texts中的第0个元素; 5:词典中顺序为5的词,即“机票”; 1:词频
(0, 0) 1
(0, 2) 1
# 结果转化为稀疏举证标识
print(cv_fit.toarray())
结果: [[1 0 1 0 0 1 1 0 0 0]
[1 0 1 1 1 0 0 0 0 0]
[0 1 0 0 0 0 0 1 1 1]]
上述示例中单条语料中没有出现重复的词,我们对第一条语料增加一个“北京”对比看下,结果如下所示:
from sklearn.feature_extraction.text import CountVectorizer
# "帮 我 查询 明天 到 北京 的 机票" 为输入列表元素,即代表一个文章的字符串
texts = ["帮 我 查询 明天 到 北京 的 机票 北京", "北京 明天 是否 有雨", "帮 我定 个 烤鸭 送到 酒店"]
# 创建词袋模型
cv = CountVectorizer()
cv_fit = cv.fit_transform(texts)
# print(cv.get_feature_names())
# print(cv.vocabulary_)
# print(cv_fit)
print(cv_fit.toarray())
结果:[[2 0 1 0 0 1 1 0 0 0]
[1 0 1 1 1 0 0 0 0 0]
[0 1 0 0 0 0 0 1 1 1]]
经过处理后就将我们所提供的训练文本转换成了特征的向量表示形式,这些特征向量在传入到EmbeddingIntentClassifier中与各条语料的类别标识一同进行训练成模型。
EmbeddingIntentClassifier 分类(模型构建)
rasa框架是通过集成TensorFlow来进行模型构建的,一些细节进行了封装,为了说明清晰,这里撇开TensorFlow框架进行分析。
同样使用上文处理好的稀疏向量为例:
三条语料:帮我查询明天到北京的机票。 北京明天是否有雨? 帮我定个烤鸭送到酒店。 其对应的特征向量如下所示:
[[1 0 1 0 0 1 1 0 0 0]
[1 0 1 1 1 0 0 0 0 0]
[0 1 0 0 0 0 0 1 1 1]]
三条语料的意图分别为:订机票、查天气、订餐
基于上述的特征数据,我们构建一个4层的神经网络,其中第一层为输入层,其接收我们处理后的特征向量数据,根据上述示例,每个语料有10个向量值,则我们的第一层输入层对应有10个神经元;最后一层为输出层,也就是结构层,我们这里有三个意图分类,则我们的输出神经元对应有3个;中间两层时隐藏层,我们可以根据需要进行设计。
备注:神经网络的主要思想可以看做是通过大量的训练样本,自动学习一个模拟函数,进而对未知数据进行预测。或者说神经网络使用样本数据自动推断出每一类的的特征规则,然后应用的新的位置数据上,进而达到分类的目的。
经过上述说明后,设计如下的神经网络结构:

输入层较多,我们仅画出部分表示,层与层之间采用全连接的方式,激活函数我们选择使用sigmoid函数。
针对上述的神经网络结构,每一个神经元的结构如下所示:

其中\(x_1,x_2,...,x_{10}\)就是我们上文处理后的特征向量,我们上文示例是10维度的,一般的情况下输出的维度都比较大,\(z=w_1x_1+w_2x_2+...+w_{10}x_{10}+b\)为加权输入,输出则为激活函数作用在加权输入\(z\)上,即\(y=\sigma(z)\).
上述我们已经构建了一个4层的神经网络,那该神经网络如何与我们的分类结合在一起呢?在数学上,我们一般将这类问题归纳为优化问题,也就是有了训练数据与相关的数据标识,则可以通过设计相关的优化函数进行。比如我们在上文已经将语料 “帮我查询明天到北京的机票。” 标识成一个1X10的向量表示 [1 0 1 0 0 1 1 0 0 0],我们设计了一个模拟函数\(y=y(x)\)标识对应的期望输出,根据上文示例,这个输出是一个3维的向量,对于语料 “帮我查询明天到北京的机票。” 我们期望的输出应该是\(y(x)=(1,0,0)^T\),如何求出这个模拟函数(一般情况下则是求相关的权重和偏置)则是我们模型构建的过程,即上面说的最优化问题。
针对我们上面是设计的神经网络,我们选择二次代价函数(也称为均方误差代价函数):
模型的构建过程就是基于训练语料对上述代价函数进行最优化的过程,最终得到\(y(x)\)函数的权重及偏置,则在新的用户数据请求到来后,直接进行计算则可以得到相应的分类结果。
注:上述最优化过程在深度学习中最常用的是反向传播算法,这块内容因为涉及的细节后数学公式推导较多,可以参考我整理的笔记 神经网络的几点记录 、反向传播的四个基本方程
上述流程即是使用RASA的NLU进行模型构建及模型预测的流程,其思想与上述中的例子所讲基本上类似。