Redis中核心数据结构源码分析-redisObject结构体
序言:
了解Redis中核心的数据结构有助于我们了解Redis的底层存储,快速写入,快速寻址原因。以及通过源码可快速的明白各种核心功能(RDB,AOF,LazyFree,内存回收策略,过期键回收策略等)的实现。
注意:以下源码都基于redis最新版本(redis5.0系列描述),想要了解redis源码需要对c语言有一定的了解,建议先了解下c的语法以及核心——指针的使用。
1:redisObject(类比于Java中Object类的作用)
c中本身是没有继承的概念的,redis使用redisObject结构体来实现继承的概率,提取出type,encoding,lru,refcount公共属性,并通过*ptr指针指向实际的各实际的底层实际结构。
redisObject结构体被定义在server.h中
typedef struct redisObject {
unsigned type:4; //4bit=0.5字节
unsigned encoding:4; //4bit=0.5字节
unsigned lru:LRU_BITS; //24bit =3字节 /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
int refcount; //4字节
void *ptr; //8字节
} robj;属性解释:
1.1:type
4位的type表示具体的数据类型。在Redis5.0共有7基础种数据类型(4.0之后新增加了module 新的数据类型,5.0中新增加了Stream、数据类型)。2^4 = 8足以表示这些类型
//源码在server.c中
/*-----------------------------------------------------------------------------
* Data types
*----------------------------------------------------------------------------*/
/* A redis object, that is a type able to hold a string / list / set */
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
/* The "module" object type is a special one that signals that the object
* is one directly managed by a Redis module. In this case the value points
* to a moduleValue struct, which contains the object value (which is only
* handled by the module itself) and the RedisModuleType struct which lists
* function pointers in order to serialize, deserialize, AOF-rewrite and
* free the object.
*
* Inside the RDB file, module types are encoded as OBJ_MODULE followed
* by a 64 bit module type ID, which has a 54 bits module-specific signature
* in order to dispatch the loading to the right module, plus a 10 bits
* encoding version. */
#define OBJ_MODULE 5 /* Module object. */
#define OBJ_STREAM 6 /* Stream object. */1.2:encoding
4位encoding表示该类型的物理编码方式,同一种数据类型可能有不同的编码方式。目前Redis中主要有8种编码方式:
/**
*对象编码类型,某些类型的对象(如字符串和散列)可以用多种方式在内部表示。用redisObject的encoding来设置
*/
#define OBJ_ENCODING_RAW 0 //字符串
#define OBJ_ENCODING_INT 1 //整数
#define OBJ_ENCODING_HT 2 //哈希表
#define OBJ_ENCODING_ZIPMAP 3 //不再使用
#define OBJ_ENCODING_LINKEDLIST 4 //不再使用了 双向链表——5.0中不再使用它构建list
#define OBJ_ENCODING_ZIPLIST 5 //压缩列表
#define OBJ_ENCODING_INTSET 6 //整数集合
#define OBJ_ENCODING_SKIPLIST 7 //跳跃列表
#define OBJ_ENCODING_EMBSTR 8 //embstr编码的简单动态字符串 embstr编码是通过调用一次内存分配函数来分配一块连续的空间,而raw需要调用两次。
#define OBJ_ENCODING_QUICKLIST 9 //由压缩列表构成的双端链表——快速列表
#define OBJ_ENCODING_STREAM 10 //服务于5.0 提供的新数据结构stream可以使用 OBJECT ENCODING key 查看该key底层的物理编码方式
1.3:lru
24位当使用redis.conf设置的回收策略为lru或lfu相关的策略时,用于存储相对应时间,例如若设置回收策略为lru则24位存储的是以秒为单位的该对象最近被访问的时间,若设置为lfu则高16为存储是以分为单位的该对象被访问的时间,低8位保存着按照某种规则(具体规则可以参考evict.c中LFULogIncr()函数,在回收策略的时候会进行描述)实现的某段时间内的使用频次
1.3:refcount
记录当前对象被引用的次数,redis中使用引用计数法来回收对象内存空间,当一个对象refcount为0时,代表此对象可以被进行销毁回收了。
1.4:*ptr
定义指针ptr,指向了该对象底层实现的数据结构。这个数据结构由 type 属性和 encoding 属性决定 (存在)
举个例子, 如果一个 redisObject 的 type 属性为 REDIS_STRING, encoding 属性为 OBJ_ENCODING_EMBSTR, 那么这个对象就是一个 Redis String, 它的值保存在一个SDS中, 而 ptr 指针就指向这个sds。
以下详细介绍redis5.0的7大基础数据类型如何由type与encoding组合而成:
1.4.1:String
字符串底层使用SDS(在C语言中字符串可以用'\0'结尾char数组来表示,这种方式在大多数情况可以满足需求,但是不能高效的计算length和append数据,并且如果我们序列化一个图片为字符串时内部可能会存在'\0',使用C语言在操作该字符串时因为遇到'\0'时就会终止,那么后续的字符不会读取,就会出现丢失数据情况。所以Redis自己实现了SDS(简单动态字符串)的抽象类型,后续详细介绍)这种数据结构存储数据,提供OBJ_ENCODING_INT,OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR三种编码方式。底层具体使用哪一种编码方式与所存储的大小有一定的关系。如下图所示

- int:8字节的数字类型
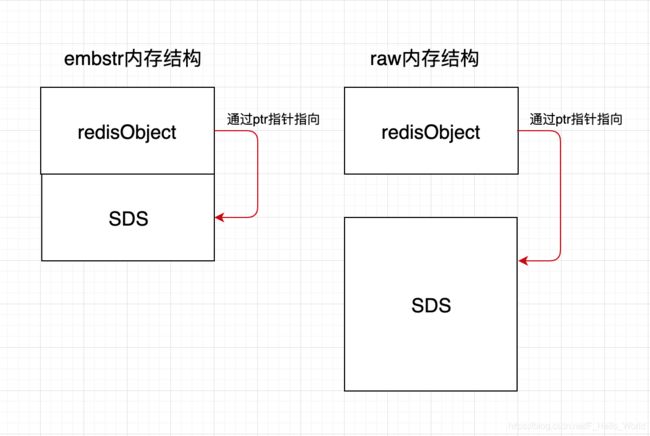
- embstr:不同版本有着不同的范围(3.0版本之前是小于等于39字节的字符串类型,3.2版本之后,则变成了44字节为分界,后面详细介绍此块),embster分配内存时只存在一次,只需要为redisObject分配内存
- raw:超过44字节字符串类型,raw创建是会分配两次内存(一次为sds分配,另一次为redisObject对象分配)。
SDS(简单动态字符串,源码存在与sds.h与sds.c 中基于redis5.0系列):
typedef char *sds;
//定义SDS结构体源码:
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; //8bit=1字节
uint8_t alloc;//8bit=1字节 /* excluding the header and null terminator */
unsigned char flags;//默认为1字节 /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; //16bit=1字节/* used */
uint16_t alloc; //16bit=2字节/* excluding the header and null terminator */
unsigned char flags; //默认为1字节/* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; //32bit=4字节/* used */
uint32_t alloc; //32bit=4字节/* excluding the header and null terminator */
unsigned char flags; //默认为1字节 /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; //64bit=8字节 /* used */
uint64_t alloc; //64bit=8字节 /* excluding the header and null terminator */
unsigned char flags; //默认为1字节 /* 3 lsb of type, 5 unused bits */
char buf[];
};
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4从上述源码会我存在几个疑问:
- 上述源码中sdshdr的作用是什么?为何存在5种不同的sdshdr,除了sdshdr5(上面的源码注解表明该方式从不被使用),里面都包含类似的属性,这几个属性的作用是什么?
- __attrubte__ ((packed)) 的作用是干嘛?
- 上述的sdshdr和SDS_TYPE_的命名的规则为啥都跟着5,8,16,32,64这些数字,那么这么数字代表着什么?
1:redis中的SDS的本质还是char ,这些从上述源码中typedef char *sds也可以看出,为了能弥补c中字符串的的不足,redis构建了表头的概念,每个字符串在写入的同时在开始的位置记录:写入的字符串的长度(len);记录了当前字节数组总共分配的内存大小,也可以理解为这个字节数组可存储最大字符长度(alloc的大小其实与redis使用内存分配器有关,后续会结合jmalloc来描述,但大小是不包含最后多余的那个字节'\0');以及使用一个字节中的低3位(另外高5位不使用)来标明此head类型(flags)。有了上述结构在对于字符串进行操作时,就可以避免C中出现的问题。而buf实际就是用于存储真正的数据了(在真正的字符串数据之后,还有一个NULL结束符,即ASCII码为0的’\0’字符。这是为了和传统C字符串兼容。之所以字符数组的长度比最大容量多1个字节,就是为了在字符串长度达到最大容量时仍然有1个字节存放NULL结束符)。这也就是上述的各sdshdr(sds-header)结构了。
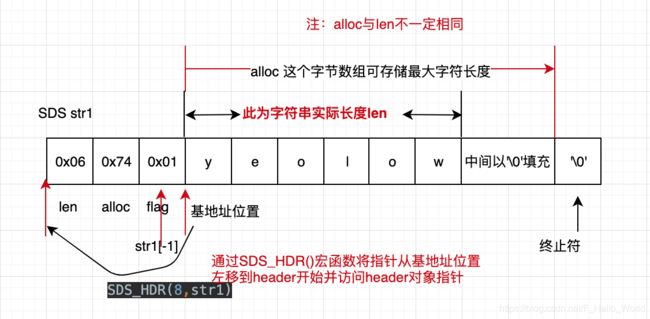
因为整个SDS字符串在内存空间是整体紧凑的,所以以指针从基位(模式是从基础位置开始)左移一位指向flag(flag本身指定为一个字节非动态内存分配),也就可以获取到了flag数据,取其中低3位就可以获取到对应的SDS_TYPE,即从str1[-1]=0x01,str2[-1]=0x02可以获取两个SDS字符串的类型为SDS_TYPE_6与SDS_TYPE_8。通过SDS_HDR()函数宏从sds字符串获得header在起始位置的指针对象,详细源码可以参考下述:
//这个是c中宏函数的写法(c中宏函数的作用可以简单描述为,先通过书写符合编译原则的代码,)
/**
*struct sdshdr 可能有这样几种类型, struct sdshdr8,struct sdshdr16... T传入宏函数用##
*方式拼接成对应字节长度的类型,s是一个指针类型,它的第一个对象类型是struct sdshdr(n),
* s-...就是在s的基地址上向左回退指定长度
*sizeof(struct sdshdr##T) 计算不同类型的sdshdr的字节长度
*它返回了该header的对象指针,在对象指针可以使用上"->"就跟栈对象上"."一样来访问sdshdr中具体属性
*例如如果为SDS_HDR(8,s),下面的宏函数在编译之后 会被替换成
*((struct sdshdr8 *)((s)-(sizeof(struct sdshdr8))))
*上述代码的含义在于指针s从基位左移到sds header头位置
*/
#define SDS_HDR(T,s) ((struct sdshdr##T *)((s)-(sizeof(struct sdshdr##T))))
//作用和SDS_HDR宏函数作用形同,不同在于生成的内存地址直接赋予类型为指定的sdshdr_的结构体 sh
//例如SDS_HDR_VAR(8,s)下面的宏函数在编译之后 会被替换成
//struct sdshdr8 *sh = (void*)((s)-(sizeof(struct sdshdr8)));
//上述代码的含义在于指针s从基位左移到sds header头位置 再赋予指针sh
#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));
当我们获取到了SDS中header的对象指针,那么就可以很简单的操作各sdshdr中len,alloc,flag等属性了从下述源码中可以看出:
//该函数用于获取sds中len的值
static inline size_t sdslen(const sds s) {
//这里s代表是sds指针对象默认是在sds的基位
//将指针向左移动一位,此时指向的是sdshdr中flag位置
unsigned char flags = s[-1];
switch(flags&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return SDS_TYPE_5_LEN(flags);
case SDS_TYPE_8:
//从这里可以看出通过SDS_HDR(8,s)获取了sdshdr对象指针并且访问len属性
return SDS_HDR(8,s)->len;
case SDS_TYPE_16:
return SDS_HDR(16,s)->len;
case SDS_TYPE_32:
return SDS_HDR(32,s)->len;
case SDS_TYPE_64:
return SDS_HDR(64,s)->len;
}
return 0;
}2:它的作用就是告诉编译器取消结构在编译过程中的优化对齐,按照实际占用字节数进行分配。这样的作用是保证整个sdshdr结构在内存空间中是整体紧凑,我们可以很方便的计算内存地址以获取指向sdshdr头部的起始地址的指针[sds-头部的大小]
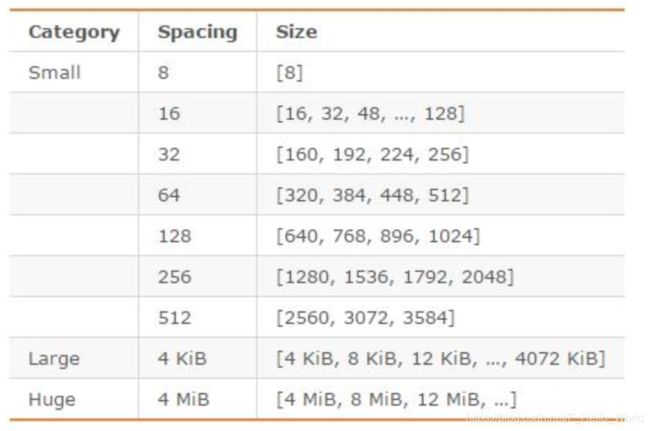
3:上述源码中5,8,16,32,64与位运行(i< 其实从源码sds.c中sdsReqType函数也可以看的出来,该函数通过写入的字符的大小判定使用SDS类型 这里通过源码sdsnewlen(const void *init, size_t initlen)函数来验证下上述: 说到这里我们对于sds的作用心里有了大致的了解了,redis通过sds.h与sds.c提供的API实现了string底层数据结构的构建(增删改查)。详细可以参考:Redis中sds—API详细介绍,这里不会深入描述。 写到这里内心不由的产生了存在一个疑问,redisObject中的encoding:embstr,raw与sds有着什么关系: 在描述这个问题之前,先描述下redis的内存分配器:jemalloc(它是默认的,也是高效的)、tcmalloc、glib 对于redis的所有对象内存的分配都是内存分配器干的,jemalloc分配器将内存分为:Small class(存放小对象区域)、Large class(存放大对象区域)、Huge class(存放巨大对象区域)。如下图所示是jemalloc分配器详细情况: jemalloc会根据数据的大小进行分配内存空间,例如现redis需要保存一个25字节大小的字符串,因为25在16-32之间,所以jemalloc这对于该数据实际会分配32字节的内存空间供该字符串存放(这也是为sds中len<=allcoc的值的原因)。对于redis来说浪费内存空间是一种罪过——(redis的高效也是来源于开发者对于每一个内存字节的不浪费)。raw与embstr两种encoding被提出实际上就是上述一种体现。 不论raw,embstr这两种encoding底层内部实现都是sds。不同在于具体的内存实现:embstr的内存结构连续的而raw是非连续的,这也是上面说embstr这种类型只会分配一次,而raw需要分配2次的原因(使用raw会比embstr产生更多的内存碎片,造成数据浪费)。如下图所示: 上述还说到embstr的最大数据存储字节数为44字节,此阀值的的来源在于:SDS中最小内存使用的类型为SDS_TYPE_5,SDS_TYPE_5大小为3字节+SDS尾部会默认添加一个字节的‘\0’结尾符,而redisObject中的内存大小为16字节,而embstr类型被jemalloc分配的最大内存空间为64字节,超过64字节redis认为它是一个大字符串使用embstr这种方式并不合适来则就使用raw类型模式。那么最终embstr类型能存储最大数据为:64-16-3-1=44字节。 redis中string是对外部类型的体现,SDS是redis中字符串的底层存储结构,是一个数据载体,而embstr与raw为redis中内部类型,结合redisObject结构体构成 list作为redis最开始就有5大类型之一,它的使用频率非常高,它可以保证数据的写入输出顺序,通常使用它来构建FIFO(First In First Out )先进先出队列,FILO(First In Last Out)先进后出队列。 1:redis3.2之前使用LINKEDLIST(双向链表linkedlist)+OBJ_ENCODING_ZIPLIST(ziplist)来真正实现 redis3.2之前针对上述linkedlist和ziplist的特点,redis会根据list中元素的长度来决定使用哪一种存储形式,当列表对象中元素的长度比较小或者数量比较少的时候使用ziplist这种结构,随着数据的增加redis会将ziplist这种结构转变为linkedlist。这里就会涉及到数据的copy以及内存的重分配。 2 :redis3.2之后redis引入了OBJ_ENCODING_QUICKLIST(快速链表-本质是通过ziplist与linkedlist的两种概念的结合,整体的数据结构仍然是linkedlist,但是每一个节点都是一个ziplist)这一数据结构。如下图所示 从上图可以看出,quicklist存储数据量的大小=(LinkedNode节点数*ziplist节点个数),这里会存在一个问题,LinkedNode节点数与ziplist节点个数如何控制,例如现在存在12元素需要存储,那么是使用2个LinkedNode*6个ziplist节点还是6个LinkedNode*2个ziplist节点。这个redis都要进行平衡,如果Linkedlist过大内存碎片的问题无法有效解决,如果ziplist过大,那么此为ziplist分配大的连续内存空间的难度也就越大。 redis提供了一个配置属性(redis.conf中list-max-ziplist-size ,list-compress-depth),让我们可以结合自己的应用场景由自己进行控制。 源码分析(redis3.2之前参考adlist.h与adlist.c,redis3.2之后参考quicklist.h与quicklist.c。对于ziplist可以参考ziplist.c于ziplist.h ): 注:这里以redis5.0为例子 redis中ziplist的情况比较特殊,它并不像qulistlist那样定义了结构体。它的数据结构非常紧凑,为了保证内存空间的不浪费,避免在结构体中使用指针,同时减少执行该指针的内存空间使用量(叹服redis设计者对于内存使用的的'抠'),而是直接使用一块连续的内存来存储整个ziplist(这也是命名为ziplist压缩列表的原因)。ziplist的数据结构如下所示: 该结构的定义从源码ziplistNew函数中可以看出: ziplist中entity是一个特殊的数据结构,redis对其进行了结构体的逻辑定义,但在物理内存实现又对其进行编码,对数据空间进一步压缩。 redis中定义来zlentry(未被编码后的实际结构体)逻辑结构源码: redis中实际的物理内存结构(即被编码后的zpentry结构): 整个解压缩的过程可以参考源码中zipEntry()函数: 从上述解压缩代码可以分析出,redis将zlentry中prevrawlensize,prevrawlen属性数据encoding到entry内存区域中的prev_entry_length区域,将encoding,lensize,len属性数据encoding到entry内存区域中的entry_encoding区域。value实际保存到就是需要写入的数据值。 这里从客户端写入list来总体分析: 实际的写入的quicklist中的操作代码由 quicklistPush()(此处源码在quicklist.c)完成: 结合push流程图来描述说明: 字典是一种用于保存键值对(key-value pair)的抽象数据结构。在字典中,一个键(key)可以和一个值(value)进行关联(或者说将键映射为值),这些关联的键和值就称为键值对。因此Redis 构建了自己的字典实现。redis中字典这种数据结构不仅在我们实际的工作经历中实际使用占比要高于其它数据结构,而在redis的内部也大量使用来实现各大功能(例如索引体系)。之前我对于java中hashmap有过一定的描述(可参考此篇博客),其实redis中字典理论与之非常相似(使用hashtable,链地址等来构建),只不过内部实现细节存在一定的差异。redis在结构体robj中使用type=OBJ_HASH,encoding=OBJ_ENCODING_ZIPLIST或OBJ_ENCODING_HT来实现字典结构。 与上述两种结构描述的不同,我们直接先通过源码来查看下redis中hash的具体实现以及底层结构,然后再结合图的方式对于hash结构的一定的了解,最后结合写入hput命令让我们加深对于redis中hash结构自我掌握。 redis中hash结构在源码在dict.h与dict.c中: redis中hash字典的存储结构: 字典中其实并不是只存在上述这一种数据结构,如果说一个字典本身所存储的数据很少,如果使用上述这么庞大的结构来存储相对于大炮轰蚊子——多此一举,其实在redis.conf中就可以看出这一现象,在ADVANCED CONFIG只一块中存在这么一段描述: 这种高效的编码方式为ziplist。使用ziplist数据结构将字典中的数据保存使得数据整体变得更加紧凑:例如字典中每一对key和value,在ziplist中以连续的entry来保存,只有当字典中所存储的value值大于指定的阀值的时候,才会有ziplist转换为hashtable这一复杂的结构,这个从下述写入的代码也可以看出: 字典中写入操作(源码在t_hash.c的hsetCommand()函数) 结合hset使用流程图说明: 上述流程图有些 细节并没有描述到位,需要我们参照源码再细致分析。 redis中字典的rehash 在之前的对于java中hashmap数据结构描述的时,当map中元素的值达到一定阀值的时候(默认为当前位桶数组长度*0.75的时候)就会触发一次扩容操作,redis中字典也有如此的操作,于hashmap类似的时阀值也与字典中现有元素的大小有关,不同在于扩容的实现过程不一样。redis中字典的rehash不仅仅包括扩容过程(字典中元素过多,增大hashtable数组长度,有效减少hash&sizmask冲突,增加查询效率)也包括收缩(字典中元素过少,减少hashtable数组长度,有效减少内存浪费)的过程。 redis中rehash是如何做到的呢?之前描述过dict结构体的整体结构,里面包含了两个hashtable数组ht[0],ht[1],在非rehash期间ht[0]存在值而ht[1]为空,当确定该字典需要进行rehash操作,而真正的rehash操作是发生在每一次对字典各种操作中(增删改查都会触发)(下述描述的是rehash的整体过程): set是redis在结构体robj中使用type=OBJ_SET,encoding=OBJ_ENCODING_INTSET或OBJ_ENCODING_HT来实现set的结构。 和上述描述中字典结构类似,redis为了保证应对不同需求下set集合都可以保证其强大的性能,所以对于不同的写入value,实现了不同两种编码方式。OBJ_ENCODING_INTSET和OBJ_ENCODING_HT,在上述hash中以及描述了OBJ_ENCODING_HT这种编码方式以及对应的结构,那么OBJ_ENCODING_INTSET这种编码方式对应的结构又是如何呢?哪些情况下使用OBJ_ENCODING_INTSET编码方式,哪些情况使用OBJ_ENCODING_HT方式?什么时候数据结构从inset转变为ht结构?我们直接结合下sadd执行的源码来查看下。 sadd命令对应的服务端代码在t_set.c中 inset*类型数据结构: hashtable与上述字典中的结构是一致的,不同在与dicttype不同,以及set中value为null不存储任何数据。 结合zadd使用流程图说明: SortedSet是redis在结构体robj中使用type=OBJ_SET,encoding=OBJ_ENCODING_ZIPLIST或OBJ_ENCODING_SKIPLIST来实现set的结构。 和上述描述中set结构类似,redis为了保证应对不同需求下SortedSet集合都可以保证其强大的性能,所以对于不同的写入value,实现了不同两种编码方式。OBJ_ENCODING_ZIPLIST和OBJ_ENCODING_SKIPLIST,在上述list中以及描述了OBJ_ENCODING_ZIPLIST这种编码方式以及对应的结构,那么OBJ_ENCODING_SKIPLIST这种编码方式对应的结构又是如何呢?哪些情况下使用OBJ_ENCODING_ZIPLIST编码方式,哪些情况使用OBJ_ENCODING_SKIPLIST方式?什么时候数据结构从ziplist转变为skiplist结构?我们直接结合下zadd的源码来查看下。 在描述zadd源码之前,先描述下OBJ_ENCODING_SKIPLIST这种编码方式对应的数据底层(跳跃表)的实现。 跳跃表 跳跃表本身也是一种链表,与单链表或双端链表不同,跳跃表通过节点跳跃查询的使得查询时间复杂度都为O(log(n))(其实跳跃表的增删改查的时间复杂度都为O(log(n))),而不是O(n),那么跳跃表是如何做到的呢? 下图一个普通的有序单链表结构,如果我们需要查询一个元素(例如25时),那么需要从header节点开始向后遍历,直到找到25为止,那么该查询对应的的时间复杂度为O(n) 这时候我们想能不能对该结构进行一些优化(很多时候对于查询效率的优化,我们可以通过拿空间换时间来做到,索引也是上述理念的实现),所以这里我们看能否通过冗余多份数据来达到此种效果。我们在每两个节点之间,单独使用另外一种节点,该节点不仅连接前后节点,而且该指针也指向下下个节点如下图所示: 这样新的节点类型也变成了一个链表,改链表的长度为原链表的一半(上图中5,20,28,32节点),若此时想查询元素30,则我们可以通过遍历新的链表,知道发现节点大于被查询的元素时终止,此时再回到原来的链表中进行查找就很快就寻找到30元素,第一次访问的为5这个节点而跳过了2节点,相对于单链表需要7步而上述结构只需要6次。在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了。需要比较的节点数大概只有原来的一半。利用同样的方式,可以在新产生的链表上,继续为每相邻的两个节点增加一个指针,从而产生第三层链表。如此下去所产生的链表层数越多,在长链表(在短链表中层数越多反而效率提升并不高,这里也是为何redis对于zset设置了阀值-默认为128个节点使用ziplist而非跳跃表)下查询效率越高,因为跳过的节点的数量越多。 如下图所示是redis针对于不同情况对于sorted set这种数据结构的具体底层实现: 参考zadd命令来加深对上述结构的理解。 zset,skiplist数据底层结构源码在server.h zadd命令对应的服务端代码在t_zset.c中 这里通过查看zrange源码来看下skiplist中查询(zset.c中zrangeCommand函数 ) 作为redis5.0版本新出来的数据结构,它支持多播的消息可持久化的消息队列,作者参考了大量kafka的设计(例如Consumer Group概念-消费者组最早是由名为Kafka(TM)的流行消息系统引入的。Redis用完全不同的术语重新实现了一个相似的概念,但目标是相同的:允许一组客户端相互配合来消费同一个Stream的不同部分的消息,messgeid等后续详细介绍)。与之前redis中发布订阅的不同,对于stream中的数据redis中消息会缓存到磁盘中,redis重启后该数据仍然存在。 和上述描述zset结构不同,stream目前就提供了一种编码方式:OBJ_STREM,我们直接结合下xadd的源码来查看下。 等待更新。。。 streams中使用到的底层数据结构源码在stream.h中 xadd中使用到的底层数据结构源码在t_stream.h中 如下图所示包含对redisObject对象的增删改查的所有操作: SDS_TYPE_5:32Byte
SDS_TYPE_8:256Byte
SDS_TYPE_16:16kb
SDS_TYPE_32:4G
SDS_TYPE_64:这个太大有兴趣可以自己算下static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<5)
return SDS_TYPE_5;
if (string_size < 1<<8)
return SDS_TYPE_8;
if (string_size < 1<<16)
return SDS_TYPE_16;
#if (LONG_MAX == LLONG_MAX)
if (string_size < 1ll<<32)
return SDS_TYPE_32;
return SDS_TYPE_64;
#else
return SDS_TYPE_32;
#endif
}**
* 使用“init”指针和“initlen”指定的内容来创建新的sds字符串。
* 如果“init”为NULL,则字符串初始化为零字节。
* 字符串是二进制安全的,中间可以包含0个字符,因为长度存储在sds头中
* @param init 指针对象 指向需要写入的字符串
* @param initlen 被写入的字符串的实际长度
* @return
*/
sds sdsnewlen(const void *init, size_t initlen) {
//定义通用类型指针sh
void *sh;
sds s;
//根据字符串大小判断当前字符串所属sds类型
char type = sdsReqType(initlen);
//对于创建一个空sds来说不使用SDS_TYPE_5类型而直接使用SDS_TYPE_8
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type);
unsigned char *fp; //申明无符号char——一个字节 fp指针作用存在该sds的类型
//指针sh将指向新创建的内存地址 内存的大小包括sdshdr+字符串本体大小+1(以'\0'结尾包容C中字符串的操作)
sh = s_malloc(hdrlen+initlen+1);
//如果使用SDS-NOINIT,则缓冲区保持未初始化状态;字符串始终为空(所有SDS字符串始终为空)则等同于init=NULL
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
//初始值处理 清空指定内存地址 避免内存分配分配垃圾内存(c中特性)
memset(sh, 0, hdrlen+initlen+1);
//NULL 是一个宏定义 实际指的是0——>这段内存是无法被访问
if (sh == NULL) return NULL;
//将通用类型sh指针强转为char类型指针 从初始位置开始向右移动(hdrlen*(指针类型字节大小))的位数
//这里代表向右移动hdrlen位(因为指针类型是char实际就移动了一位)
//此时s指针实际的位置在 此时s的指针定位基位
s = (char*)sh+hdrlen;
//将s目前指针的位置左移一位 赋于fp指针
fp = ((unsigned char*)s)-1;
//根据不同sds类型填充数据
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
//将要写入的init数据从新的sds的基位的内存开始开始copy数据
if (initlen && init)
memcpy(s, init, initlen);
//这里在init数据的尾部添加 '\0' ,为了兼容C语言中的字符串的功能,可以使用C提供的字符串功能
s[initlen] = '\0';
return s;
}
1.4.2:List
redis通过redisObject中type=OBJ_LIST,encoding存在3种类型OBJ_ENCODING_ZIPLIST,OBJ_ENCODING_LINKEDLIST,OBJ_ENCODING_QUICKLIST来指定。

-5: max size: 64 Kb <-- 最大内存数为64k
-4: max size: 32 Kb <-- 最大内存数为32kb
-3: max size: 16 Kb <-- 最大内存数为16kb
-2: max size: 8 Kb <-- 最大内存数为8kb(为默认值)
-1: max size: 4 Kb <--最大内存数为4kb
从redis的配置文件中我们也可以看出,redis官网建议我们设置为-1或-2,此时redis中性能最优(这是针对于大多数情况下的,如果你的应用需求使得要单个ziplist节点保存的数据过大,那么就可以考虑修改该值——如果你对于你的程序有一点要求的话,那么自己要明白一句话,网上copy来的大多数配置可能有用,但却不是你自己程序最优的选择。我们对于不同需求就应该使用不同的配置属性,没什么配置是万能的)。/**
* 定义quicklist中节点结构体 该结构体数据大小为32字节 针对于64位操作系统
*/
typedef struct quicklistNode {
//记录上一个节点指针 占8字节
struct quicklistNode *prev;
//记录下一个节点指针 占8字节
struct quicklistNode *next;
//数据指针 占用8字节 如果当前list没被压缩指向一个ziplist 否则它指向的是一个quicklistLZF结构
unsigned char *zl;
//zl指针指向ziplist的数据总大小 以byte数为单位
//如果该ziplist是一个被压缩的结构 那么该值为未被压缩前数据总量 占4字节
unsigned int sz;
//记录当前节点中部ziplist节点的个数 占16bit
unsigned int count : 16; /* count of items in ziplist */
// 占2bit 表示该ziplist是否压缩了 目前只有两种取值:1表示没有压缩2表示被压缩了(而且用的是LZF压缩算法),
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
//占2bit 从字面意思上来看 该字段表明容器类型 实际上代表该quicklistNode中保存的实际的类型 1代表无 2代表ZIPLIST
//该字段是一个预留字段 为了设计是用来表明一个quicklist节点下面是直接存数据,还是使用ziplist存数据,或者用其它的结构来存数据
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
//占1bit 是否压缩标志 若客户端发送命令(例如index命令)导致已被压缩的数据会被进行解压缩 这个时候就会将该标志位变为1
//使得redis有机会将数据重写进行压缩
unsigned int recompress : 1; /* was this node previous compressed? */
//占用1bit
unsigned int attempted_compress : 1; /* node can't compress; too small */
//预留扩展字段目前无使用 占10bit
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/**
* 由ziplist 定义ziplist变更后的结构体
* 当前结构体所占字节大小 4+N
*/
typedef struct quicklistLZF {
//被压缩后的数据大小单位byte 4字节
unsigned int sz; /* LZF size in bytes*/
//存放压缩后的ziplist字节数组
char compressed[];
} quicklistLZF;
/**
* quicklist占40字节大小
* 定义双端列表
*/
typedef struct quicklist {
//quicklistNode 指针类型 记录双端列表头部节点 8字节
quicklistNode *head;
//quicklistNode 指针类型 记录双端列表尾部节点 8字节
quicklistNode *tail;
//记录双端列表中ziplist节点数 即实际保存的元素数 占8字节
unsigned long count; /* total count of all entries in all ziplists */
//记录quicklist中quicklistNode数 占8字节
unsigned long len; /* number of quicklistNodes */
//占16bit 存放redis.conf中对于ziplist大小设置
//即list-max-ziplist-size参数的值(默认为-2即每个quicklistNode中ziplist大小不超过8kb)
int fill : 16; /* fill factor for individual nodes */
//占16字节 存放redis.conf中对于 即list-compress-depth参数的值默认为(0不压缩)
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
/**
* 定义quicklist 迭代器结构体
*
*/
typedef struct quicklistIter {
const quicklist *quicklist;
quicklistNode *current;
unsigned char *zi;
long offset; /* offset in current ziplist */
int direction;
} quicklistIter;
/**
* 定义
*
*/
typedef struct quicklistEntry {
const quicklist *quicklist;
quicklistNode *node;
unsigned char *zi;
unsigned char *value;
long long longval;
unsigned int sz;
int offset;
} quicklistEntry;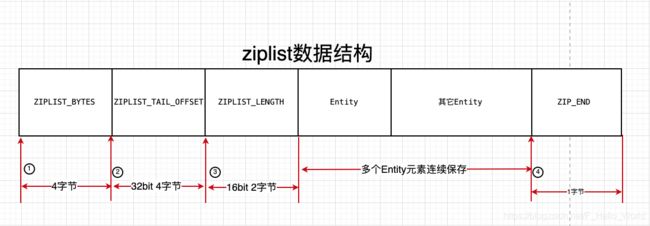
//创建一个空的ziplist 一个空的ziplist占用11字节的内存空间
//ziplist是一个连续的数据结构 每一个元素紧密相连 通过定义头部数据来管理这些元素
unsigned char *ziplistNew(void) {
//获取一个ziplist依赖的header所需要的字节数大小 +1是因为最后需要一个结尾符占1字节
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
//通过分配器分配指定大小内存空间 返回该内存地址指针 指针位置为该段内存起始位置
unsigned char *zl = zmalloc(bytes);
//1:初始化ziplist所占内存字节数ZIPLIST_BYTES
//ZIPLIST_BYTES该宏的意思指针向右移动uint32_t——32bit实际为4字节大小
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
//2:记录ziplist中方最后一个尾节点的偏移量(此偏移量指的是指针从开始到最后一个节点尾部需要移动字节数)
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
//3:ZIPLIST_LENGTH 记录ziplist中entity长度
ZIPLIST_LENGTH(zl) = 0;
//4:结尾占位符 使用0xff=255来表示结尾
zl[bytes-1] = ZIP_END;
return zl;
}
//定义宏 用于操作ziplist中header
//指针指向zlbytes字段
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
//指针右移4字节指向zltail字段
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
//指针右移ZIPLIST_TAIL_OFFSET指向尾元素首地址;intrev32ifbe使得数据存取统一按照小端法
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
//指针右移8字节指向zllen字段
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
//压缩列表最后一个字节即为zlend字段
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
//定义ziplist中entry
//这是一个逻辑结构 并不是数据的实际编码方式 实际存储的时候redis数据进行编码
typedef struct zlentry {
//前一个元素编码后的内存空间大小
unsigned int prevrawlensize;
//前一个元素的内存空间大小
unsigned int prevrawlen;
//当前元素中value编码后的内存空间大小
unsigned int lensize;
//当前元素value内存大小
unsigned int len;
//当前元素的header长度 实际为 prevrawlensize + lensize
unsigned int headersize;
//当前元素编码规则 可设置为ZIP_STR_u*或ZIP_INT_u*
unsigned char encoding;
//char指针 指向的是当前元素内存地址
unsigned char *p;
} zlentry;
/**
* 该函数将内存中数据进行解码 从而返回一个包含所有信息的结构——zlentry
* @param p 指向的是内存中实际保存的entry
* @param e zlentry 用以装载内存中entry的解压缩后的数据
*/
void zipEntry(unsigned char *p, zlentry *e) {
//ZIP_DECODE_PREVLEN是一个宏定义
//作用将内存中entry中记录的上一个entry的信息(获取prev_entry_length区域)赋值于当前zlentry中的prevrawlensize,prevrawlen
ZIP_DECODE_PREVLEN(p, e->prevrawlensize, e->prevrawlen);
//ZIP_DECODE_LENGTH是一个宏定义
//作用将内存中entry中记录的当前entry的信息数据赋值于zlentry中的encoding,lensize,len
//p + e->prevrawlensize 代表将内存指针向右移动到到entry_encoding区域
ZIP_DECODE_LENGTH(p + e->prevrawlensize, e->encoding, e->lensize, e->len);
//计算headersize 并赋值
e->headersize = e->prevrawlensize + e->lensize;
//将当前entry指针赋值
e->p = p;
//上述宏定义较为复杂 有兴趣可自行研究
}
//list写入命令
void pushGenericCommand(client *c, int where) {
int j, pushed = 0;
//通过key寻找当前db中是否存在 若该key是否存在 返回该对象指针 否则返回NULL
robj *lobj = lookupKeyWrite(c->db,c->argv[1]);
//如果能查到键 但是类型却不为list 直接报错 (error) WRONGTYPE Operation against a key holding the wrong kind of value
if (lobj && lobj->type != OBJ_LIST) {
addReply(c,shared.wrongtypeerr);
return;
}
//这里存在一个命令中包含 一个key写入多个value的情况
for (j = 2; j < c->argc; j++) {
if (!lobj) {
//创建一个新的robj 包含新的quicklist数据结构
lobj = createQuicklistObject();
//初始化quicklist中fill与compress属性
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
//将键与quicklist指针写入指定db(每个字典)中 若key存在则忽略
// 此处的作用为每个键在db中添加索引 索引的结构为字典这里可参考dict数据结构(其它的数据类型都是这样做的)
//这样再下次访问的时候就能快速寻找到quicklist 这样就可以操作各节点数据
dbAdd(c->db,c->argv[1],lobj);
}
//将实际的value写入到quicklist中
listTypePush(lobj,c->argv[j],where);
//吸入成功 pushed计数器+1
pushed++;
}
addReplyLongLong(c, (lobj ? listTypeLength(lobj) : 0));
//如果写入成功
if (pushed) {
//判断此处类型
char *event = (where == LIST_HEAD) ? "lpush" : "rpush";
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);
}
//记录全局变量dirty
server.dirty += pushed;
}
/**
* 创建类型为quicklist的robj
* @return
*/
robj *createQuicklistObject(void) {
//创建quicklist结构
quicklist *l = quicklistCreate();
robj *o = createObject(OBJ_LIST,l);
//设置robj中编码方式
o->encoding = OBJ_ENCODING_QUICKLIST;
return o;
}
/**
* 该函数用以在指定db中寻找key是否存在(源码在db.c中)
* 在寻找之前会触发一次惰性删除键操作 将键进行移除
* 若选找到键并且根据设置淘汰策略更新该robj中lru属性值
* @param db
* @param key
* @return
*/
robj *lookupKeyWrite(redisDb *db, robj *key) {
//进行惰性删除处理
expireIfNeeded(db,key);
//寻找键
return lookupKey(db,key,LOOKUP_NONE);
}
/**
* 判断配置的compress 最大不能超过2^16 最小不能小于0
*/
#define COMPRESS_MAX (1 << 16)
void quicklistSetCompressDepth(quicklist *quicklist, int compress) {
if (compress > COMPRESS_MAX) {
compress = COMPRESS_MAX;
} else if (compress < 0) {
compress = 0;
}
quicklist->compress = compress;
}
/**
* 判断配置的fill 最小不能超过-5 最大不能超过2^15数
*/
#define FILL_MAX (1 << 15)
void quicklistSetFill(quicklist *quicklist, int fill) {
if (fill > FILL_MAX) {
fill = FILL_MAX;
} else if (fill < -5) {
fill = -5;
}
quicklist->fill = fill;
}
/**
* 获取redis.conf 设置基础属性
* @param quicklist
* @param fill 定义每个quicknode中ziplist的深度
* @param depth 定义ziplist压缩深度
*/
void quicklistSetOptions(quicklist *quicklist, int fill, int depth) {
quicklistSetFill(quicklist, fill);
quicklistSetCompressDepth(quicklist, depth);
}
//创建一个新的quicklist结构 只在redis中key为空的时候调用
quicklist *quicklistCreate(void) {
struct quicklist *quicklist;
//分配指定大小内存数据
quicklist = zmalloc(sizeof(*quicklist));
//初始化各基础属性
quicklist->head = quicklist->tail = NULL;
quicklist->len = 0;
quicklist->count = 0;
quicklist->compress = 0;
quicklist->fill = -2;
return quicklist;
}
/**
*
* 根据where类型来判断此处类型是向双端列表左侧还是右侧添加
* @param subject 被写入的quicklist
* @param value 需要写入的value
* @param where LIST_HEAD=0 LIST_TAIL=1
*
*/
void listTypePush(robj *subject, robj *value, int where) {
//必须保证encoding类型为OBJ_ENCODING_QUICKLIST时才会写入
if (subject->encoding == OBJ_ENCODING_QUICKLIST) {
//将外部LIST_HEAD=0 转换为内部QUICKLIST_HEAD=0
//将外部LIST_TAIL=1 转换为内部QUICKLIST_HEAD=-1
int pos = (where == LIST_HEAD) ? QUICKLIST_HEAD : QUICKLIST_TAIL;
//对数据进行解码 从客户端传输来的数据都进行了编码 所以这里需要进行解码处理
//获取value的解码版本(作为新对象返回)。
//如果对象已经被原始编码,只需增加ref计数
value = getDecodedObject(value);
//获取整个sds中所保存的数据长度
size_t len = sdslen(value->ptr);
//push数据到quicklist节点中
quicklistPush(subject->ptr, value->ptr, len, pos);
//value 引用计数器-1 使得 value内存可以被回收
decrRefCount(value);
} else {
serverPanic("Unknown list encoding");
}
}/**
* push到数据到双端列表头部或者尾部
* @param quicklist
* @param value vlaue
* @param sz value数据大小 byte
* @param where 追加的方向 可为head 可为tail
*/
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) {
//追加双端列表头部
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) {
//追加双端列表尾部
quicklistPushTail(quicklist, value, sz);
}
}
/**
* 将新的value数据写入双端列表head
* @param quicklist
* @param value
* @param sz value size大小
* @return 返回0代表失败 返回1代表新的head已经被创建
*/
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
//获取双端列表中当前head头
quicklistNode *orig_head = quicklist->head;
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
//当前head quicklistNode不为null并且ziplist大小未超过阀值
//将当前value已entry追加写入到ziplist中
quicklist->head->zl =
//push数据并返回ziplist
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
//修改node中基础属性sz
quicklistNodeUpdateSz(quicklist->head);
} else {
//新建一个新的quicklistNode结构体
quicklistNode *node = quicklistCreateNode();
//push数据并返回ziplist 写入到quicklistnode中
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
//修改node中基础属性sz
quicklistNodeUpdateSz(node);
//新建的节点变更为nodelist中head节点
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
//变更quicklist中各种count属性
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
/**
* 将新的value数据写入双端列表尾部
* @param quicklist
* @param value
* @param sz value size大小
* @return 返回0代表失败 返回1代表新的tail已经被创建
*/
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail;
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
//当前tail quicklistNode不为null并且ziplist大小未超过阀值
//将当前value已entry追加写入到ziplist中
quicklist->tail->zl =
//push数据并返回ziplist
ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL);
//修改node中基础属性sz
quicklistNodeUpdateSz(quicklist->tail);
} else {
//新建一个新的quicklistNode结构体
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
//修改node中基础属性sz
quicklistNodeUpdateSz(node);
//新建的节点变更为nodelist中tail节点
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);
}
//变更quicklist中各种count属性
quicklist->count++;
quicklist->tail->count++;
return (orig_tail != quicklist->tail);
}
/**
* 新建一个quicklistNode 在内存中创建 并返回该node的指针
* @return
*/
REDIS_STATIC quicklistNode *quicklistCreateNode(void) {
quicklistNode *node;
//分配内存
node = zmalloc(sizeof(*node));
//初始化
node->zl = NULL;
node->count = 0;
node->sz = 0;
node->next = node->prev = NULL;
//默认指定ziplist为未压缩
node->encoding = QUICKLIST_NODE_ENCODING_RAW;
//当前node中容器中保存的结构为ziplist
node->container = QUICKLIST_NODE_CONTAINER_ZIPLIST;
//当前node的ziplist是否需要被重新压缩 默认0不需要
node->recompress = 0;
return node;
}
/**
*判断当前sz是否超过阀值——此函数针对fill为负值的情况
* @param sz value的大小
* @param fill 设置阀值
* @return
*/
REDIS_STATIC int
_quicklistNodeSizeMeetsOptimizationRequirement(const size_t sz,
const int fill) {
//如果为正值不做任何处理 这里只处理负值
if (fill >= 0)
return 0;
//计算当前fill在阀值区域数组[4096=4Kb, 8192=8Kb, 16384=16kb, 32768=32kb, 65536=64kb]的位置
size_t offset = (-fill) - 1;
if (offset < (sizeof(optimization_level) / sizeof(*optimization_level))) {
//计算出offset必须要小于<5
if (sz <= optimization_level[offset]) {
//计算最新ziplist的大小sz是否超过设置的阀值
return 1;
} else {
return 0;
}
} else {
return 0;
}
}
#define sizeMeetsSafetyLimit(sz) ((sz) <= SIZE_SAFETY_LIMIT)
/**
* 判断当前quicklistNode节点能否被造正常插入
*
* @param node 被操作的节点
* @param fill 阀值
* @param sz value的大小
* @return 1可插入 当前节点不为null 并且node中sz的大小+value的大小不能超过设置阀值(fill控制) 0不可插入
*/
REDIS_STATIC int _quicklistNodeAllowInsert(const quicklistNode *node,
const int fill, const size_t sz) {
//当前node是否存在
if (unlikely(!node))
return 0;
//计算将value写入后ziplist维护所消耗的字节数
// (每一个value的写入都会创建一个新的entry,redis需要维护entry所要花费的额外字节数)
int ziplist_overhead;
/* size of previous offset */
if (sz < 254)
ziplist_overhead = 1;
else
ziplist_overhead = 5;
/* size of forward offset */
if (sz < 64)
ziplist_overhead += 1;
else if (likely(sz < 16384))
ziplist_overhead += 2;
else
ziplist_overhead += 5;
//计算
/* new_sz overestimates if 'sz' encodes to an integer type */
//new_sz=原node中zipist字节数+当前value所需要字节数+维护value的ziplist数据结果字节数
unsigned int new_sz = node->sz + sz + ziplist_overhead;
//判断当前sz是否超过阀值——针对fill为负值的情况
if (likely(_quicklistNodeSizeMeetsOptimizationRequirement(new_sz, fill)))
return 1;
else if (!sizeMeetsSafetyLimit(new_sz))
return 0;
//针对与fill为正 并且保证当前node中ziplist的长度不能超过阀值
else if ((int)node->count < fill)
return 1;
else
return 0;
}
//ziplistPush该函数源码在ziplist.c中
/**
* 公共方法:将value写入到ziplist 中
* @param zl quicklistnode中ziplist指针
* @param s 需要写入数据的指针
* @param slen value在sds中的实际长度len
* @param where 是head
* @return
*/
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {
unsigned char *p;
//根据条件指定写入ziplist地点——头或者尾
//ZIPLIST_ENTRY_HEAD 与ZIPLIST_ENTRY_END是一个宏定义 作用是返回从ziplist结构中指针从开始向右移动指定大小后位置
//使得后续数据可以从该位置进行插入
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
//__ziplistInsert 涉及到c中各种指针处理 有兴趣的可以自行研究 这里不细致介绍
return __ziplistInsert(zl,p,s,slen);
}
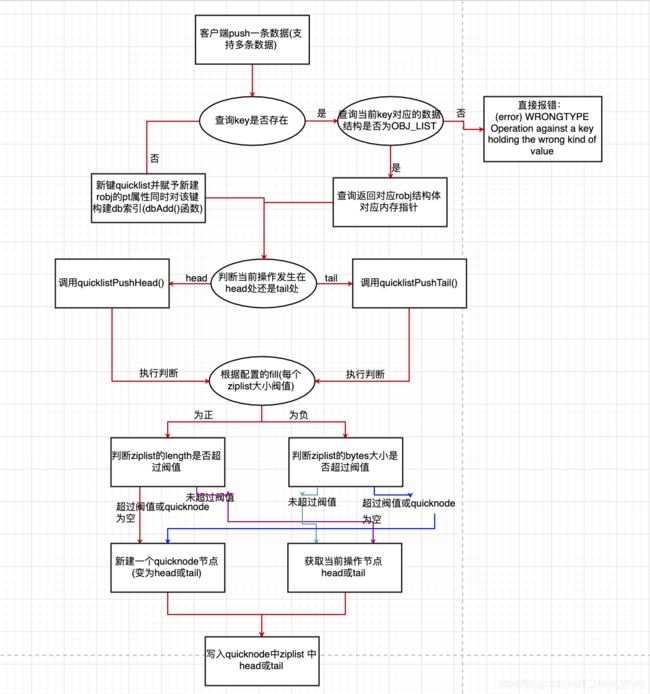
1.4.3:字典
//下述为dict中所用到结构体源码
/**
* 每个 dictEntry 结构存储着一个键值对
* 且存有一个 next 指针来保持链表结构
*/
typedef struct dictEntry {
//指针类型 8字节 hash中key
void *key;
//v它是一个联合类型,方便存储各种结构 并记录一些基础属性
union {
//指针类型 8字节 实际用于存储value数据
void *val;
//
uint64_t u64;
//
int64_t s64;
double d;
} v;
//记录下一个字典实体
//实际上dictEntry本身是一个链表结构
//和hashmap中概念value链表的作用一样当存在相同的key的hash值一样时,使用链地址法来解决key相同冲突
struct dictEntry *next;
} dictEntry;
/**
* dictType结构中包含自定义的函数,这些函数使得key和value能够存储任何类型的数据。
* 因为hashtable这种数据结构不仅仅在字典上作为底层数据结构来使用 还可以作为其它类型(例如set或zset)的底层数据结构 每个对基础数据类型对dictType都有自己的具体实现详细可参考server.c源码中setDictType,zsetDictType,dbDictType(此结构为各个db中的索引结构,key为键,value为robj)
shaScriptObjectDictType 等等
* 在结构体中每个函数中都看到一个参数privdata(这个是每个dict中的privdata属性)
*/
typedef struct dictType {
//用于计算dict中key的hash值
uint64_t (*hashFunction)(const void *key);
//该函数用于复制dict中key
void *(*keyDup)(void *privdata, const void *key);
//该函数用于复制dict中value
void *(*valDup)(void *privdata, const void *obj);
//该函数用于比较dict中两个key是否相同
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
//销毁dict中的key
void (*keyDestructor)(void *privdata, void *key);
//销毁dict中的value
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/**
* redis中hashtable结构体定义
* 当我们实现从旧表到新表的增量重新灰化时,每个字典都有存在两个这样的值。进行数据交换
*/
typedef struct dictht {
//二级指针类型 hash表数组 数组中的每一个元素都是dictEntry结构的指针
//其实redis字典并不是只使用hashtable这一种数据结构 在元素少量的情况模式使用ziplist用于替换hashtable的作用 可参考后续写入代码
dictEntry **table;
//整个hash表数组大小 初始化大小为4
unsigned long size;
//用于映射位置的掩码
//作用对于键进行映射 索引到hashtable数组对应下标所以值永远等于(size-1)
//对于一个键的hash映射的过程实际为改键的hash值与该sizemask位运算
unsigned long sizemask;
//代表当前hash表数组中已有的节点数量即已包含的dictEntry的多少 包含链接的dictEntry 所以该值可能会比size要大
unsigned long used;
} dictht;
/**
* 定义字典结构体
*/
typedef struct dict {
//指针类型 类型特定函数
dictType *type;
//私有数据,保存着dictType结构中函数的参数。
//type 属性和privdata 属性是针对不同类型的键值对,为创建多态字典而设置的:
void *privdata;
/*定义两个hashtable 其中ht[0]为原生哈希表,ht[1]为 rehash 哈希表
*作用在dict 扩容缩容时,需要分配新的hashtable,redis使用渐进式搬迁或者说是分布进行的,当此
*字典处于扩容状态时,对字典的每一个查询或者新增修改操作,都会把旧表的一个bucket移到新的
*表中。当所有数据迁移完成后,新表变成旧表,旧表变成新表(所以通常情况下该hashtable数组中只有
*一个 hashtable 是有值的)。这样在扩容的过程就变成了分步进行,减少了因为扩容导致的其它命令的
*长时间等待
*/
dictht ht[2];
//记录rehash过程中最新访问的hashtablde的下标 如果rehashidx=-1代表 则代表rehash动作不在进行中(或rehash动作以完成)
long rehashidx;
//当前运行的迭代器数量
unsigned long iterators;
} dict;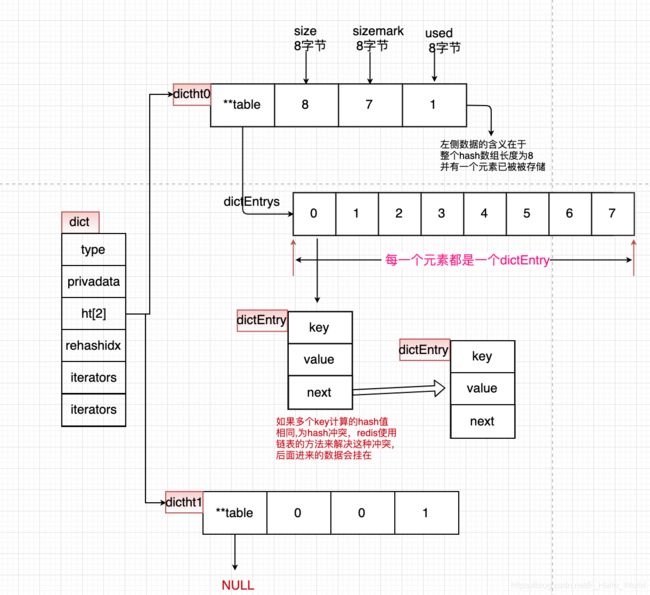
############################### ADVANCED CONFIG ###############################
# Hashes are encoded using a memory efficient data structure when they have a
# small number of entries, and the biggest entry does not exceed a given
# threshold. These thresholds can be configured using the following directives.
#当哈希有少量的条目,并且最大的条目不超过给定的阈值时,使用内存高效的数据结构对其进行编码。
#可以使用以下指令配置这些阈值
#此处代表ziplist中最大保存的元素为256个 每个元素(k,v型)占2个entry
hash-max-ziplist-entries 512
##每个entry存储的最大字节数为64字节
hash-max-ziplist-value 64
/**
* 真正执行写入数据操作
* 命令格式为hset 键 key1 value1 key2 value2
* @param c
*/
void hsetCommand(client *c) {
//定义 created创建成功计数器
int i, created = 0;
robj *o;
//校验当前接受的命令是否符合格式 默认来说命令的个数为2的倍数
if ((c->argc % 2) == 1) {
addReplyError(c,"wrong number of arguments for HMSET");
return;
}
//判断当前键对应字典是否存在若不存在直接创建
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
//是否对字典中底层数据结构进行转换(由ziplist->hashtable)
hashTypeTryConversion(o,c->argv,2,c->argc-1);
//真正执行写入数据操作 i+=2是因为key和value是
for (i = 2; i < c->argc; i += 2)
//没成功一次 计数器+1 hashTypeSet函数新写入为0 插入为1
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/**
* 这里根据不同的命令(HMSET,HSET)发送到到客户端不同的值
*/
//获取执行命令名称
char *cmdname = c->argv[0]->ptr;
//addReplyLongLong与addReply都是在networking.c中函数作用发送消息到指定客户端 后续描述
if (cmdname[1] == 's' || cmdname[1] == 'S') {
//如果命令明第二个字符为s 则为HSET命令
addReplyLongLong(c, created);
} else {
//HMSET
addReply(c, shared.ok);
}
//用于键空间更改的挂钩
signalModifiedKey(c->db,c->argv[1]);
//用于键事件通知 可以让客户端通过订阅给定的频道或者模式,来获知数据库中键的变化,以及数据库中命令的执行情况后续描述
notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);
//dirty 距离上次RDB操作变化的键的计数器+1=》为RDB进行服务
server.dirty++;
}
/**
*
* 查询键 不存在创建一个新的
* @param c
* @param key 被
* @return
*/
robj *hashTypeLookupWriteOrCreate(client *c, robj *key) {
//查询获取指定键在db中数据
robj *o = lookupKeyWrite(c->db,key);
if (o == NULL) {
//当前键为null 重新创建dict
o = createHashObject();
//在当前db添加为该键添加索引结构
dbAdd(c->db,key,o);
} else {
//如果当前获取键已存在但不是指定的OBJ_HASH类型 直接返回null记录错误类型
if (o->type != OBJ_HASH) {
addReply(c,shared.wrongtypeerr);
return NULL;
}
}
return o;
}
/**
* 创建一个新的字典类型的robj 源码在object.c中
* 这里默认是创建一个ziplist而不是hashtable
* 只有当字典中元素达到一定阀值时才会触发变更
* @return
*/
robj *createHashObject(void) {
//创建一个新的ziplist 用于存放dict
unsigned char *zl = ziplistNew();
//创建一个新的robj type为OBJ_HASH
robj *o = createObject(OBJ_HASH, zl);
//设置编码类型为OBJ_ENCODING_ZIPLIST
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
/**
* 该函数检查写入字典中简直对数据字节大小是否超过设定的阀值redis.conf中hash-max-ziplist-value =64 该值默认为64
* 若超过需要将默认的ziplist结构变更为hashtable结构
* 源码在t_hash.c中
* @param o 需要被处理的robj对象
* @param argv 二级指针 需要被写入的多个键值对 实际上为客户端传输的命令 为hset 键 k1 v1 k2 v2
* @param start argv中开始位置
* @param end argv中结束位置
*/
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
//只处理键中数据为ziplist的字典
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
//对写入的数据都进行校验
for (i = start; i <= end; i++) {
/**当前需要写入的数据encoding是否为string中编码RAW或者EMBSTR
*因为字符串长度可以在恒定时间内查询(多亏于sds结构中包含len可以快速获取) 所以这里只检查key/value为字符串类型的)
*并且写入的数据大小是否超过指定的阀值
*/
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
//当上述条件满足时 将字典中ziplist结构变更为哈希表
hashTypeConvert(o, OBJ_ENCODING_HT);
break;
}
}
}
/**
* 公共函数根据需要处理的robj的不同编码类型进行不同处理 源码在t_hash.c中
* @param o 需要转换的
* @param enc 编码类型
*/
void hashTypeConvert(robj *o, int enc) {
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
hashTypeConvertZiplist(o, enc);
} else if (o->encoding == OBJ_ENCODING_HT) {
serverPanic("Not implemented");
} else {
serverPanic("Unknown hash encoding");
}
}
/**
*字典中底层数据变更由ziplist变更为ht
* @param o 需要处理的字典
* @param enc 编码类型
*/
void dhashTypeConvertZiplist(robj *o, int enc) {
//只处理编码类型为ziplist的字典
serverAssert(o->encoding == OBJ_ENCODING_ZIPLIST);
if (enc == OBJ_ENCODING_ZIPLIST) {
/* Nothing to do... */
} else if (enc == OBJ_ENCODING_HT) {
//由压缩列表变更为哈希表的详细过程
//定义一个hash类型迭代器 作用于迭代遍历字典中数据
hashTypeIterator *hi;
//定义字典指针
dict *dict;
int ret;
//初始化创建一个hash类型迭代器
hi = hashTypeInitIterator(o);
//创建一个新的dict结构体 hashDictType为全局变量 内部包含该字典所需要的一些函数
dict = dictCreate(&hashDictType, NULL);
//开始进行整个迭代ziplist中数据
while (hashTypeNext(hi) != C_ERR) {
sds key, value;
//从迭代器中获取当前需要遍历的key和value
key = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_KEY);
value = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_VALUE);
//将数据添加到新的数据结构中——dict的hashtabl中
ret = dictAdd(dict, key, value);
//判断写入是否成功 若非成功记录失败理由
if (ret != DICT_OK) {
serverLogHexDump(LL_WARNING,"ziplist with dup elements dump",
o->ptr,ziplistBlobLen(o->ptr));
serverPanic("Ziplist corruption detected");
}
}
//当前迭代器作用完成 对其进行重新初始化
hashTypeReleaseIterator(hi);
//释放之前的内存空间(即之前ziplist占用的内存空间)
zfree(o->ptr);
//将新的数据对字典重新赋值
o->encoding = OBJ_ENCODING_HT;
o->ptr = dict;
} else {
serverPanic("Unknown hash encoding");
}
}
/**
* 向字典中新添加一个元素,如果当前key已经存在,则用新的value覆盖旧的。
* 源码在dict.c中
* @param o 被操作字典robj
* @param field 元素中的key
* @param value 元素中的value
* @param flags 用于调用方能操作key 目前只针对于ht类型,value对于sds的权限的标志位(实际上该标志位决定操作key,value是否需要进行copy一份的动作)
* 有3种类型不同类型有着不同的处理
* HASH_SET_TAKE_FIELD=(1<<0) =1 key对应的sds所有权限传递给函数中 避免进行数据复制动作
* HASH_SET_TAKE_VALUE=(1<<1)=2 对应的sds所有权限传递给函数 避免进行数据复制动作(在HINCRBY命令中使用到 因为该命令会依赖到旧value值 所以不需要进行复制直接使用旧内存地址即可)
* HASH_SET_COPY=0 对应于没有传递任何标志,并且表示在需要时复制值的默认语义 即操作key和value时都要重新复制一份新的避免对原值存在影响
* @return 插入时返回0,更新时返回1
*/
int hashTypeSet(robj *o, sds field, sds value, int flags) {
//是否进行更新的标志位
int update = 0;
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
//字典中数据结构为ziplist时写入元素
unsigned char *zl, *fptr, *vptr;
//获取ziplist
zl = o->ptr;
//获取整个ziplist中去除ziplisthead之后最开始的entry
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
//在ziplist中从第一个entry开始寻找向后寻找直到找到值与key相同的entry
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
//如果已存在key 说明此次操作时一次更新操作
if (fptr != NULL) {
//抓取指向值的指针 获取旧value 实际上获取key指针的下一个指针即可
vptr = ziplistNext(zl, fptr);
serverAssert(vptr != NULL);
//修改update标志位
update = 1;
//删除旧值
zl = ziplistDelete(zl, &vptr);
//在旧的位置上插入一个新值
zl = ziplistInsert(zl, vptr, (unsigned char*)value,
sdslen(value));
}
}
//若非更新即为一个新写入动作
if (!update) {
//将key,value写入到ziplist队尾中
zl = ziplistPush(zl, (unsigned char*)field, sdslen(field),
ZIPLIST_TAIL);
zl = ziplistPush(zl, (unsigned char*)value, sdslen(value),
ZIPLIST_TAIL);
}
//将最新的ziplist的指针写入到字典中
o->ptr = zl;
//在写入之后 需要再次来判定是否需要将ziplist转换为ht
//当ziplist中entry过长就会导致后续查询修改的时间变长导致效率降低 所以需要转换为ht结构
//此次的阀值由redis.conf中hash-max-ziplist-entries(默认等于512 即字典最大保存256个元素)来控制,该属性控制ziplist中entry的个数
if (hashTypeLength(o) > server.hash_max_ziplist_entries)
hashTypeConvert(o, OBJ_ENCODING_HT);
} else if (o->encoding == OBJ_ENCODING_HT) {
//字典中数据结构为ht时写入元素
//通过key获取ht中对应实体对象
dictEntry *de = dictFind(o->ptr,field);
if (de) {
//如果存在说明是一个更新的操作 释放之前的内存空间
sdsfree(dictGetVal(de));
if (flags & HASH_SET_TAKE_VALUE) {
//直接将value赋值不进复制动作
dictGetVal(de) = value;
value = NULL;
} else {
//将传入的参数value构建为一个新的sds写入到字典中 从而完成更新value操作
// (避免因为参数value在其它地方被释放而导致此指针无效)
dictGetVal(de) = sdsdup(value);
}
//变更修改状态
update = 1;
} else {
//不存在说明这是一个新的写入的操作
sds f,v;
//这里根据设置对value是否进行复制处理
if (flags & HASH_SET_TAKE_FIELD) {
f = field;
field = NULL;
} else {
f = sdsdup(field);
}
if (flags & HASH_SET_TAKE_VALUE) {
v = value;
value = NULL;
} else {
v = sdsdup(value);
}
//将k,v写入到字典中
dictAdd(o->ptr,f,v);
}
} else {
serverPanic("Unknown hash encoding");
}
//释放field与value占用内存空间 清除垃圾
//避免在flags>0并且字典中数据结构为ziplist时写入成功后 无法释放传入的参数field与value造成内存垃圾
if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field);
if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value);
//返回标志位
return update;
}
/**
* 从字典中查询key对应dictEntry
* @param d 字典
* @param key 查询的key
* @return
*/
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
uint64_t h, idx, table;
//数据一般都在ht[0] ht[1]中若 未发生rehash操作一般在ht[0]中 若发生rehash操作 ht[0]和ht[1]都存在
if (d->ht[0].used + d->ht[1].used == 0) return NULL;
//进行rehash操作 若该字典真正进行的话
if (dictIsRehashing(d)) _dictRehashStep(d);
//计算key对应hash值
h = dictHashKey(d, key);
//为避免rehash带来数据不一致 从ht[0] 和ht[1]中查询
for (table = 0; table <= 1; table++) {
//计算该hash在hash表对应位桶位置
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
//遍历位桶中的链表 知道找到key对应dictentry 或null
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
//该操作避免不在rehash操作的时候访问ht[1]
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}
/**
* 添加一个新的元素(k,v)到hashtable中
* 该函数源码在dict.c中
* @param d
* @param key
* @param val
* @return
*/
int dictAdd(dict *d, void *key, void *val)
{
//将创建一个新的dictEntry 将key写入
dictEntry *entry = dictAddRaw(d,key,NULL);
//创建失败返回错误
if (!entry) return DICT_ERR;
//写入value
dictSetVal(d, entry, val);
return DICT_OK;
}
/**
*
*新建一个dictEntry 如果
*/
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
long index;
dictEntry *entry;
dictht *ht;
//如果当前字典正在进行rehash动作 继续进行数据的rehash动作 后续在rehash中介绍
if (dictIsRehashing(d)) _dictRehashStep(d);
//_dictKeyIndex函数通过dictHashKey函数计算key的hash值来判断hashtable中是否存dictEntry如果存在返回-1
// 不然返回这个新元素在hashtable中索引
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
//如果已存在不做任何处理
return NULL;
/**
*创建一个新元素并从顶部插入元素,原有在于:在一个数据库中
*客户端更可能的频繁访问的是最近添加的条目
*/
//如果给字典在rehash过程则取新表进行数据写入
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
//内存分配器创建新的entry大小空间内存 并返回该地址对应指针
entry = zmalloc(sizeof(*entry));
/**
* 这里的操作是将hash表对应下标的位桶中dictEntry 作为尾部链接到新的dictEntry上(如果存在hash冲突该位桶肯定是一个单链表)
* 所以在字典中若出现hash冲突 最新被写入的数据被访问的数据最快
* 最终将新建的dictEntry的指针重新写到下标对应的位桶中
*/
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
//将key写入到entry中
dictSetKey(d, entry, key);
return entry;
}
/**
*获取key对应在字典中索引位置 源码在dict.c中
*/
static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing)
{
unsigned long idx, table;
dictEntry *he;
if (existing) *existing = NULL;
//判定当前字典是否需要进行扩容 获取rehash中描述
if (_dictExpandIfNeeded(d) == DICT_ERR)
return -1;
//处理字典中两个hashtable
for (table = 0; table <= 1; table++) {
//通过对key进行hash取值后再与sizemask进行&运行得到最终的索引位置
idx = hash & d->ht[table].sizemask;
//通过ht索引位置获取到dictEntry 若存在遍历整个链表 来验证是否存在相同key
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
if (existing) *existing = he;
return -1;
}
he = he->next;
}
//如果不进行rehash动作 说明ht[1]为null不需要进行判定 否则对ht[1]也要进行获取
// 若ht[0]和ht[1]皆获取到idx则以ht[1]结果为准
if (!dictIsRehashing(d)) break;
}
return idx;
}
/**用于源码在server.c中*/
/**
*用于创建一个新的dict(hashtable)结构体
* 该处源码在dict.c中
*/
//重置dictht中数据
static void _dictReset(dictht *ht)
{
ht->table = NULL;
ht->size = 0;
ht->sizemask = 0;
ht->used = 0;
}
//该函数用于创建一个hashtable
dict *dictCreate(dictType *type,
void *privDataPtr)
{
//在内存分配 并创建一个新的dict结构体
dict *d = zmalloc(sizeof(*d));
_dictInit(d,type,privDataPtr);
return d;
}
//初始化hash table dict
int _dictInit(dict *d, dictType *type,
void *privDataPtr)
{
_dictReset(&d->ht[0]);
_dictReset(&d->ht[1]);
d->type = type;
d->privdata = privDataPtr;
d->rehashidx = -1;
d->iterators = 0;
return DICT_OK;
}
/**全局变量hashDictType 为dict提供下述对应函数*/
//其中下列函数对应源码在server.c中 有兴趣可自行查看 代码很简单易读
dictType hashDictType = {
dictSdsHash, //用于计算dict中key的hash值
NULL, //该函数用于复制dict中key
NULL, //该函数用于复制dict中value
dictSdsKeyCompare, //该函数用于比较dict中两个key是否相同
dictSdsDestructor, //销毁dict中的key
dictSdsDestructor //销毁dict中的value
};
/**数据迭代器hashTypeIterator 源码在server.h dict.h t_hash.c中*/
/**
* hash类型数据遍历器 通过迭代器来遍历整个字典
* 里面包含两种数据结构的遍历方式:ziplist,hashtable
*/
typedef struct {
//指针类型指向当前迭代器所属字典对象
robj *subject;
// 字典对象的编码类型
int encoding;
// 用于指向当前的key和value节点的地址,在当前字典对象编码类型为ziplist时使用
unsigned char *fptr, *vptr;
//迭代HT类型的哈希对象时的字典迭代器 在当前字典对象编码类型为hashtable时使用
dictIterator *di;
//指向当前hashtable中dictEntry 包含key和value
dictEntry *de;
} hashTypeIterator;
/**
* 用于遍历字典中类型为hashtable的数据
*/
typedef struct dictIterator {
//指针类型 指向当前迭代器所属字典
dict *d;
//记录哈希数组中位置 即table中的下标,标记table[index]
long index;
//通过table字段来判断是表th[0] 还是th[1] safe代表此迭代器是否安全
int table, safe;
//指针类型 entry指向当前元素 nextEntry指向下一个元素
dictEntry *entry, *nextEntry;
//不安全的迭代器,即正在更新的中的表的迭代器,使用指纹来标记
long long fingerprint;
} dictIterator;
/**
* 根据当前字典创建一个新的迭代器(这里主要负责创建处理ziplist类型的迭代器)
*/
hashTypeIterator *hashTypeInitIterator(robj *subject) {
//内存分配一个迭代器并返回一个指针
hashTypeIterator *hi = zmalloc(sizeof(hashTypeIterator));
//进行初始化
hi->subject = subject;
hi->encoding = subject->encoding;
if (hi->encoding == OBJ_ENCODING_ZIPLIST) {
//如果字典编码类型为ziplist 进行初始化
hi->fptr = NULL;
hi->vptr = NULL;
} else if (hi->encoding == OBJ_ENCODING_HT) {
//如果字典编码类型为HT 新建一个dictIterator进行初始化
hi->di = dictGetIterator(subject->ptr);
} else {
serverPanic("Unknown hash encoding");
}
return hi;
}
//这里主要负责创建处理ht类型的迭代器 源码在ditc.c中
/**
* 初始化dictIterator
* @param d
* @return
*/
dictIterator *dictGetIterator(dict *d)
{
//内存分配器分配dictIterator 并返回对应指针
dictIterator *iter = zmalloc(sizeof(*iter));
iter->d = d;
//默认迭代的是ht[0]
iter->table = 0;
iter->index = -1;
iter->safe = 0;
//默认迭代器处理数据为null
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}
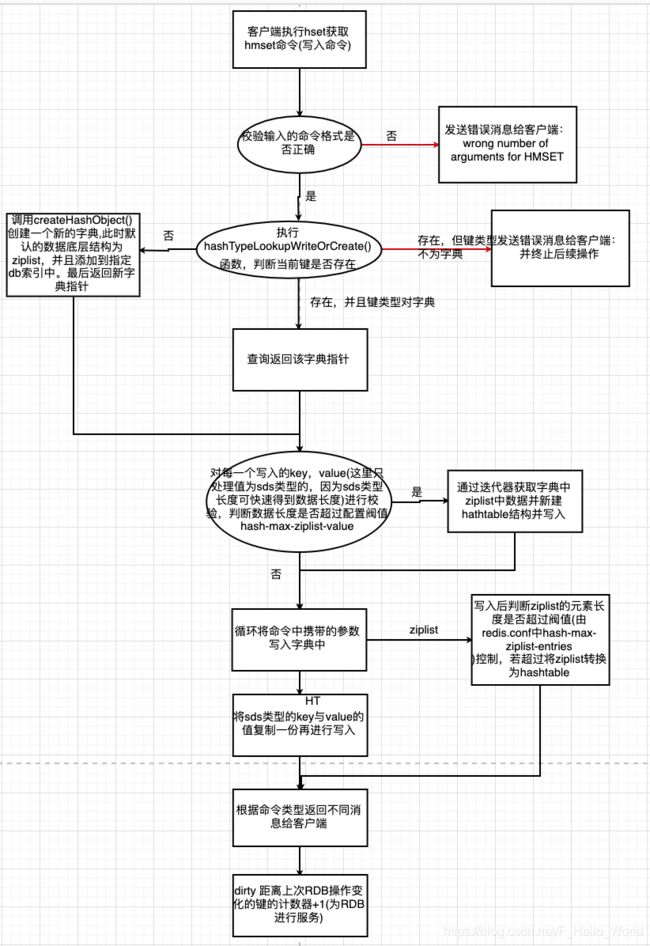
//rehash相关源码
/**第一步:校验hashtable是否触发rehash动作并进行初始化rehash前初始化动作*/
//hashtable是否需要进行扩容客户端对字典进行新增元素时
//dictAddRaw是字典添加一个新的元素时
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
。。。。。
//_dictKeyIndex函数中调用了_dictExpandIfNeeded函数用以判断字典是否需要进行扩容
if ((index = _dictKeyIndex(d, key, dictHashKey(d,key), existing)) == -1)
//如果已存在不做任何处理
return NULL;
。。。。。
}
/**
* 判断当前字典是否需要进行扩容动作
* 若需要扩容 修改dict中rehashidx为0
* @param d
* @return
*/
static int _dictExpandIfNeeded(dict *d)
{
//如果当前字典已在进行rehash 直接返回成功标示
if (dictIsRehashing(d)) return DICT_OK;
//如果当前哈希表为空,则将其扩展到初始大小 DICT_HT_INITIAL_SIZE
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/**
* 当满足以下条件时将触发rehash扩容动作:
* 1:当前字典中存在的元素个数大于等于hashtable数组的个数(这个时候肯定存在hash冲突,dictentry存在链表)
* 2:
* 2.1:当前全局配置设置可以调整哈希表的大小(默认开启),这个配置可以通过全局配置来继续开启关闭,如果开启则在1条件满足之后马上进行扩容
* 避免出现长链接的情况 但会占用一定内存资源 在内存紧张的情况下可以关闭由第2个选项主导
* 2.2:元素和位桶总大小之间的比值超过默认阀值dict_force_resize_ratio=5 即如果元素个数21个 当前位桶个数大小位4个此时触发扩容动作
* 一般能达到触发到此阀值,dict_can_resize被置于0(关闭),此时减少了内存空间的使用,但可能出现一批长链接对于查询效率有一定影响
*/
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
//默认来说字典每次扩容的长度要大于当前元素的2倍但却不是等于,后续介绍)
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
/**
* 创建一个新的hashtable并进行扩容
* @param d 字典
* @param size 扩容的长度
* @return
*/
int dictExpand(dict *d, unsigned long size)
{
//如果扩容的大小小于哈希表中已存在的元素数,则该大小无效
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
//定义一个新的哈希表
dictht n;
//计算新hash表的长度
unsigned long realsize = _dictNextPower(size);
//重新rehash到相同的表大小是没有用的。
if (realsize == d->ht[0].size) return DICT_ERR;
//新建一个新的哈希表(dict)并将所有指针初始化为空
n.size = realsize;
n.sizemask = realsize-1;
//初始化分配指定指定大小(元素个数*每一个dictEntry指针内存)的内存
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
//将新的hash表赋予dict中
d->ht[1] = n;
//初始化rehash过程中记录ht[0]位桶下标 rehashidx
d->rehashidx = 0;
return DICT_OK;
}
/**
*
* 计算扩容之后的hashtable位桶长度
* @param size
* @return 最终计算新ht的长度
*/
static unsigned long _dictNextPower(unsigned long size)
{
//默认大小
unsigned long i = DICT_HT_INITIAL_SIZE;
//整个hash表扩容有最大限度 最大为long类型的最大值
if (size >= LONG_MAX) return LONG_MAX + 1LU;
//实际上对于新hash表长度的取值只会是2的幂次方(即若size=60那么最终求出的长度为2^6=64)
while(1) {
if (i >= size)
return i;
i *= 2;
}
}
//hashtable是否需要进行收缩发生在客户端对字典进行删除元素时
//这里主要是依托于hdel命令源码进行分析
/**
* 从字典中删除元素
* @param o 被操作的字典
* @param field 需要被删除的key
* @return 返回1 key对应数据被删除 0没有key被找到
*/
int hashTypeDelete(robj *o, sds field) {
//定义返回状态
int deleted = 0;
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
//处理字典数据底层为ziplist结构
unsigned char *zl, *fptr;
zl = o->ptr;
//选在ziplist的第一个entry所定义指针位置
fptr = ziplistIndex(zl, ZIPLIST_HEAD);
if (fptr != NULL) {
//开始进行进行循环查找直到直到仙童key 并获取value
fptr = ziplistFind(fptr, (unsigned char*)field, sdslen(field), 1);
if (fptr != NULL) {
//删除ziplist的key和value
zl = ziplistDelete(zl,&fptr);
zl = ziplistDelete(zl,&fptr);
o->ptr = zl;
deleted = 1;
}
}
} else if (o->encoding == OBJ_ENCODING_HT) {
//处理字典数据底层为ht结构
//调用dict.c中dictDelete()函数进行删除元素返回C_OK 成功
if (dictDelete((dict*)o->ptr, field) == C_OK) {
deleted = 1;
//在每进行一次数据删除都进行判断该字典是否需要进行一次rehash收缩操作
if (htNeedsResize(o->ptr)) dictResize(o->ptr);
}
} else {
serverPanic("Unknown hash encoding");
}
return deleted;
}
/**
* 判断是否需要重新resize
* @param dict
* @return 1是 0否
*/
int htNeedsResize(dict *dict) {
long long size, used;
//获取字典hashtable位桶长度
size = dictSlots(dict);
//获取字典中所有元素个数
used = dictSize(dict);
/**满足下列条件
* 1:size>初始大小(小于初始大小其实没必要进行resize了)
* 2: 当前元素占整个位桶数组的长度要小于HASHTABLE_MIN_FILL(默认10%-可以对此进行修改重新编译打包)
* 若size=64 即若used<(64*10%=6.4)就会触发
*/
return (size > DICT_HT_INITIAL_SIZE &&
(used*100/size < HASHTABLE_MIN_FILL));
}
/**
* 收缩hashtable
* @param d 字典结构体对象
* @return
*/
int dictResize(dict *d)
{
//定义新ht中最小理想值大小
int minimal;
//如果设置了hash不能进行resize 或者当前字典正在进行rehash不进行任何处理
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR;
//新字典的大小为目前元素值 最小不能少于DICT_HT_INITIAL_SIZE=4
minimal = d->ht[0].used;
if (minimal < DICT_HT_INITIAL_SIZE)
minimal = DICT_HT_INITIAL_SIZE;
//dictExpand是一个公共方法在 参照扩容里描述
return dictExpand(d, minimal);
}
/**第二部:进行rehash动作 源码在dict.c中*/
//一般发生在增删改查中
//增加
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing)
{
。。。。。
if (dictIsRehashing(d)) _dictRehashStep(d);
。。。。。
}
//查询
dictEntry *dictFind(dict *d, const void *key)
{
。。。。。
if (dictIsRehashing(d)) _dictRehashStep(d);
。。。。。
}
//也属于查询的一种
//作用:为随机获取字典中键--为数据淘汰政策中的random算法提供随机获取key操作
dictEntry *dictGetRandomKey(dict *d)
{
。。。。。
if (dictIsRehashing(d)) _dictRehashStep(d);
。。。。。
}
//删除
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
。。。。。
if (dictIsRehashing(d)) _dictRehashStep(d);
。。。。。
}
//修改里面会涉及到查询的动作所以这里也算上
/**
* 在执行rehash的动作之前必须保证当前字典中无安全的迭代器进行绑定
* 因为如果当前字典存在迭代器,那么在rehash的过程中,会导致这两个哈希表进行错乱
* 最终可能导致某些元素会丢失或被复制
* @param d
*/
static void _dictRehashStep(dict *d) {
//若进行rehash操作 都只进行一次数据的迁移
if (d->iterators == 0) dictRehash(d,1);
}
/**
* 字典rehash过程
* 在整个rehash过程的其实就是将旧的hashtable中每一个bucket
* (这个bucket里面可能因为hash冲突的原因包含了多个key)
* 迁移到新的hashtable的过程 循环将旧ht中数据一一进行迁移(通过rehashidx记录当前操作下标)
*
* @param d 字典
* @param n 每次进行bucket迁移的个数
* @return 如果仍有键要从旧哈希表移动到新哈希表,则返回1,否则返回0
*/
int dictRehash(dict *d, int n) {
// 定义最多N*10个空bucket可以被访问
int empty_visits = n*10;
//再次验证当前字典是否在进行rehash操作
if (!dictIsRehashing(d)) return 0;
//每次rehash最多执行n次数据迁移 并且旧hashtable里存在数据
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
//保证rehashidx不能溢出(hashtable下标值不能超过哈希表长度)
assert(d->ht[0].size > (unsigned long)d->rehashidx);
/** 直到获取hashtable数组中不为空元素,但为了不影响原命令的响应时间 所以对于循环的次数有一定的限制
* (旧hashtable中可能存在一定连续的空的bucket,所以如果循环空的bucket过多也会导致此命令响应时间增加)
*/
while(d->ht[0].table[d->rehashidx] == NULL) {
//数组下标自增+1
d->rehashidx++;
//每次操作最大循环阀值-1 若已达到了最大阀值都没有
if (--empty_visits == 0) return 1;
}
//获取hashtable该位桶dictEntry对象
de = d->ht[0].table[d->rehashidx];
//该位桶中可能因为hash冲突存在一个链式结构 循环取出所有元素重新写入到新的hashtable中
//在迁移的过程中 链表写入的顺序是先进后出(即最新写入的元素在链表的头部)
while(de) {
//定义元素在新ht中的下标位置
uint64_t h;
//取出该链表下一个元素
nextde = de->next;
//根据元素的key计算出在新ht中的下标位置
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
//将元素放到位桶链表的首位
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
//旧ht中元素量-1
d->ht[0].used--;
//新ht元素量+1
d->ht[1].used++;
//执行下个链表节点的迁移
de = nextde;
}
//迁移成功将旧ht的对于位桶置空
d->ht[0].table[d->rehashidx] = NULL;
//旧ht需要迁移的下标+1
d->rehashidx++;
}
//如果rehash动作完成 需要将rehashidx置为-1 释放ht[0]内存空间 并将ht[1]赋值ht[0] 并重置ht[1] 为下一次rehash做准备
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
//能执行到这里说明rehash过程并没结束 还有剩余的bucket需要被迁移
return 1;
}1.4.4:Set
/**
* 朝set中新增元素(支持多条)
* @param c
*/
void saddCommand(client *c) {
robj *set;
int j, added = 0;
//在当前db查询key对应的robj指针
set = lookupKeyWrite(c->db,c->argv[1]);
if (set == NULL) {
//不存在创建一个新的set
set = setTypeCreate(c->argv[2]->ptr);
//将键写入到当前db的索引字典中
dbAdd(c->db,c->argv[1],set);
} else {
//若键已存在但类型不为set 则发送错误信息到客户端 并结束
if (set->type != OBJ_SET) {
addReply(c,shared.wrongtypeerr);
return;
}
}
//循环添加添加元素
for (j = 2; j < c->argc; j++) {
//添加数据进set
if (setTypeAdd(set,c->argv[j]->ptr)) added++;
}
//添加成功后操作
if (added) {
signalModifiedKey(c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_SET,"sadd",c->argv[1],c->db->id);
}
//dirty自增器+1 (为rbd做参考)
server.dirty += added;
//发送客户端成功信息包含 成功写入的次数
addReplyLongLong(c,added);
}
/**
* 新增一个元素到set中
* @param subject
* @param value
* @return 如果该元素已经是set的成员之一则不执行任何操作并返回0,否则将添加新元素并返回1
*/
int setTypeAdd(robj *subject, sds value) {
long long llval;
if (subject->encoding == OBJ_ENCODING_HT) {
//如果当前set的数据结构为类型为ht
dict *ht = subject->ptr;
//新建一个ht中dictEntry结构
// 详细可以参考之前对于字典中ht的描述
//因为是ht所以这里其实也存在rehash的过程 dictAddRaw若key已存在返回null
dictEntry *de = dictAddRaw(ht,value,NULL);
if (de) {
//新建dictEntry创建成功则进行最终数据的写入
//将实际的value转变为sds格式作为key写入到dictEntry 并且设置dictEntry的value为null
//所以set类型为ht实际上是将值保存到hashtabl中dictentry的key中,这也是为何set可以保证元素唯一性的原因(重复键不做任何操作)
dictSetKey(ht,de,sdsdup(value));
dictSetVal(ht,de,NULL);
return 1;
}
} else if (subject->encoding == OBJ_ENCODING_INTSET) {
//如果当前set的数据结构类型为intset
//需要判断最新写的的值是否为整数类型 若否还需要进行转换
if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) {
//写入的元素仍然是整数
//定义写入状态
uint8_t success = 0;
//写入到intset中
subject->ptr = intsetAdd(subject->ptr,llval,&success);
if (success) {
//如果写入成功 需要判定当前intset中元素的个数是否超过阀值(该值由redis.conf中set-max-intset-entries来设置默认为512)
if (intsetLen(subject->ptr) > server.set_max_intset_entries)
//将intset转换为ht诶下
setTypeConvert(subject,OBJ_ENCODING_HT);
return 1;
}
} else {
//写入的元素不为整数是
//转换set中intset数据结构为ht
setTypeConvert(subject,OBJ_ENCODING_HT);
//将数据写入到新的ht中 并验证释放成功
serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK);
return 1;
}
} else {
serverPanic("Unknown set encoding");
}
return 0;
}
/**
*根据写入的value是否为整数值来创建不同类型的底层结构
* Intset或HT
* 源码在t_set.c中
* @param value 需要写入的value
* @return
*/
robj *setTypeCreate(sds value) {
//isSdsRepresentableAsLongLong判断当前value是否为整数类型 C_OK是 C_ERROR为否
if (isSdsRepresentableAsLongLong(value,NULL) == C_OK)
//创建一个inset类型的数据结构
return createIntsetObject();
//创建一个ht类型数据结构
return createSetObject();
}
/**
* 创建一个数据结构为intset的robj
* 源码在objet.c中
* @return
*/
robj *createIntsetObject(void) {
//创建一个新的intset结构体
intset *is = intsetNew();
robj *o = createObject(OBJ_SET,is);
//设置该结构体类型为OBJ_ENCODING_INTSET
o->encoding = OBJ_ENCODING_INTSET;
return o;
}
/**
* 创建一个新的intset
* 源码在intset.c中
* @return intset结构体
*/
intset *intsetNew(void) {
//分配器分配一个大小为intset结构体大小内存区域 并返回该区域的内存指针
intset *is = zmalloc(sizeof(intset));
//初始化
is->encoding = intrev32ifbe(INTSET_ENC_INT16);
is->length = 0;
return is;
}
/**
* 定义intset类型数据结构
*/
typedef struct intset {
//32bit=4字节的encoding 保存intset中保存的数据的编码方式
uint32_t encoding;
//32bit=4字节的length 保存该intset中保存的元素长度大小
uint32_t length;
//用以保存数据的int数组
int8_t contents[];
} intset;
/**
*创建一个数据结构为ht的robj
* 源码在objet.c中
* @return
*/
robj *createSetObject(void) {
//创建一个dict 并且dictType为setDictType
// setDictType中包含ht在set的所需要的一些基础函数
dict *d = dictCreate(&setDictType,NULL);
robj *o = createObject(OBJ_SET,d);
//设置编码类型为OBJ_ENCODING_HT
o->encoding = OBJ_ENCODING_HT;
return o;
}
/**
*set中数据结构为ht时所需要依赖的函数
*/
dictType setDictType = {
dictSdsHash, //计算值对于hash
NULL,
NULL,
dictSdsKeyCompare, //该函数用于比较dict中两个key是否相同
dictSdsDestructor, //销毁key
NULL
};
/**
* 将set结构数据底层结构由intset转变为ht(这里与字典中由ziplist转换为ht很类似)
*
* @param setobj set结构体
* @param enc 编码方式 目前只支持OBJ_ENCODING_HT这一种 为何这么设计为了后续可能出现新的编码方式做准备
*/
void setTypeConvert(robj *setobj, int enc) {
//定义set类型迭代器
setTypeIterator *si;
//验证
serverAssertWithInfo(NULL,setobj,setobj->type == OBJ_SET &&
setobj->encoding == OBJ_ENCODING_INTSET);
if (enc == OBJ_ENCODING_HT) {
//目前只处理OBJ_ENCODING_HT
int64_t intele;
//新建并初始化dicttype类型为set的ht的数据结构
dict *d = dictCreate(&setDictType,NULL);
sds element;
//考虑到intset中可能已经存在一些元素所以先对ht进行扩容操作
dictExpand(d,intsetLen(setobj->ptr));
//初始化set迭代器
si = setTypeInitIterator(setobj);
//通过迭代器循环将intset中元素写入到set ht中
while (setTypeNext(si,&element,&intele) != -1) {
//获取intset中整数类型元素
element = sdsfromlonglong(intele);
//将元素写入ht中
serverAssert(dictAdd(d,element,NULL) == DICT_OK);
}
setTypeReleaseIterator(si);
setobj->encoding = OBJ_ENCODING_HT;
//释放intset数据结构内存空间
zfree(setobj->ptr);
//将新ht赋予ptr
setobj->ptr = d;
} else {
serverPanic("Unsupported set conversion");
}
}
/**
* 定义set类型数据迭代器结构体 源码定义在在server.c中
* 里面包含两种数据结构的的遍历方式:intset,hashtable
*/
typedef struct {
//当前迭代的set对象执行
robj *subject;
//set编码类型
int encoding;
//记录intset中数组下标 在当前set对象编码类型为intset时使用
int ii;
//迭代HT类型的哈希对象时的字典迭代器 在当前set对象编码类型为hashtable时使用
dictIterator *di;
} setTypeIterator;
/**
* 创建一个新的set类型的迭代器 源码在t_set.c中
* @param subject
* @return
*/
setTypeIterator *setTypeInitIterator(robj *subject) {
//内存分配一个迭代器并返回一个指针
setTypeIterator *si = zmalloc(sizeof(setTypeIterator));
//进行初始化
si->subject = subject;
//设置编码方式
si->encoding = subject->encoding;
if (si->encoding == OBJ_ENCODING_HT) {
//如果为ht类型 获取一个ht类型的迭代器 参考dict.c中源码
si->di = dictGetIterator(subject->ptr);
} else if (si->encoding == OBJ_ENCODING_INTSET) {
//因为intset中保存数据为数组 所以对该数组下标赋为0
si->ii = 0;
} else {
serverPanic("Unknown set encoding");
}
return si;
}

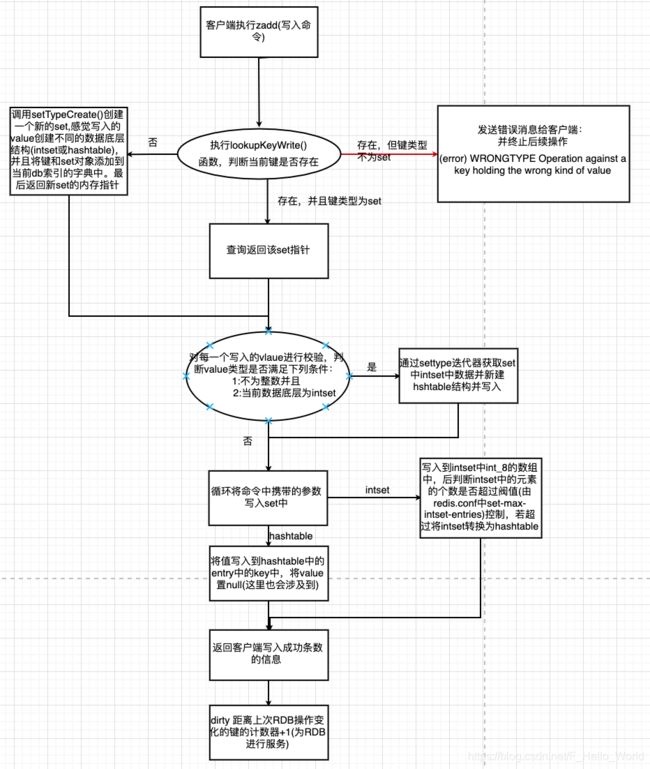
1.4.5:SortedSet


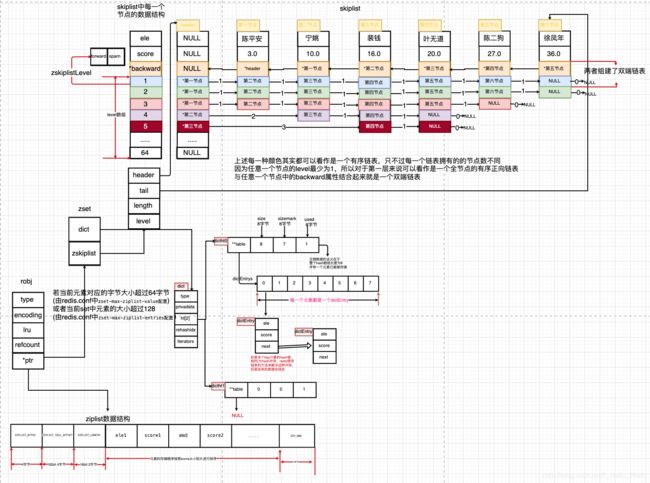
/**
* 定义跳跃表中各节点的结构体
* 所有节点都是通过backward进行相连 而每个节点中都有着属于自己的level(随机产生)
*/
typedef struct zskiplistNode {
//记录当前元素的string类型值
sds ele;
//记录当前元素对应score 用于在list中排序
double score;
//指针类型 后退指针(相当于双向链表中的prev指针,上一个节点),通个该指针,我们可以从表尾向表头遍历列表
struct zskiplistNode *backward;
//leavel 是一个动态数组 它的长度代表该节点在跳跃表中等级
//它可以包含多个元素,每个元素都包含一个层指针(level[i].forward),
//指向该结点在本层的后继结点。该指针用于从表头向表尾方向访问结点。可以通过这些层指针来加快访问结点的速度
struct zskiplistLevel {
//前进指针 对应等级下的链表中的下一个节点(相当于双向链表中的next指针 下一个节点)
struct zskiplistNode *forward;
//层跨度 span用于记录在当前层下该节点与下一节点之间的距离,便于后续快速查询(后续通过图解说明)
unsigned long span;
} level[];
} zskiplistNode;
/**
* 定义跳跃表结构体
* 跳跃表也是链表结构的一种只不过它在链表的基础上增加了跳跃功能(通过level数组来做到)
* 正是这个跳跃的功能,使得在查找元素时,跳表能够提供O(logN)的时间复杂度
* 跳跃表可以达到平衡树的插入、删除、查找时间复杂度,即O(logn)
* 却比平衡树实现简单,采用链表来实现可以方便依序遍历。
*/
typedef struct zskiplist {
/**
* 定义链表中表头和表尾 对于查询表头和表尾可以做到O(1)
* tail表示的是该链表中最后一个节点 但head确实一个伪节点 里面存储成员对象为NULL score为0
* 它的level层级固定为最大默认值ZSKIPLIST_MAXLEVEL=64 (后续通过图解说明)
* @return
*/
struct zskiplistNode *header, *tail;
//记录当前跳跃表中节点(元素)的个数
unsigned long length;
//记录当前跳跃表中节点的最高等级
int level;
} zskiplist;
/**
*
* 定义zset结构体(可参考java中的linkedhashmap数据结构或者Java实现LRU算法中的描述)
* 这里使用了字典和跳跃表结合构建zset原因在于
* 跳跃表优点是元素按照score进行排序,但是查询值对应的score需要遍历跳跃表所以对应复杂度为O(logn);
* 字典查询根据值来查询score复杂度为O(1) ,但是无序
* 所以结合两种结构来实现 可以保证zset的查询效率
*/
typedef struct zset {
//字典类型指针
dict *dict;
//zskiplist类型指针
zskiplist *zsl;
} zset;
/**zadd源码分析*/
/**
*
* 创建一个编码类型为SKIPLIST的robj
* @return
*/
robj *createZsetObject(void) {
//内存分配器分配内存用于初始化zset结构
zset *zs = zmalloc(sizeof(*zs));
robj *o;
//创建一个dicttype类型zsetDictType的字典
zs->dict = dictCreate(&zsetDictType,NULL);
//创建一个skiplist
zs->zsl = zslCreate();
//创建robj
o = createObject(OBJ_ZSET,zs);
//设置编码
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
/**
* 初始化一个新的跳跃表
* @return
*/
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
//内存分配器分配指定大小内存空间 并返回指向该内存空间的指针
zsl = zmalloc(sizeof(*zsl));
//初始化基础属性
zsl->level = 1;
zsl->length = 0;
//初始化head -伪节点 该节点的level为ZSKIPLIST_MAXLEVEL默认64
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
//初始化header节点中各层zskiplistLevel
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
/**
* 创建一个编码类型为ziplist的zset结构
* @return
*/
robj *createZsetZiplistObject(void) {
//创建一个新的ziplist
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_ZSET,zl);
//设置编码
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
/**
* 新增一个元素,score到ziplist
* @param zl 指针类型对应ziplist所在内存地址
* @param ele 原始值
* @param score score
* @return 指针类型 返回当前ziplist对应内存地址
*/
unsigned char *zzlInsert(unsigned char *zl, sds ele, double score) {
//定义eptr sptr指针 并且获取ziplist中第一个entry所在内存地址赋于eptr
unsigned char *eptr = ziplistIndex(zl,0), *sptr;
double s;
//从第一个entry节点开始循环遍历 知道无节点可找或者找到对应score位置
//ziplist使用两个entry来保存元素值和对应score
while (eptr != NULL) {
//获取当前entry相邻的下一个entry 因为ziplist是一个连续的内存空间 所以获取下一个entry实际上是指针向右的移动
sptr = ziplistNext(zl,eptr);
serverAssert(sptr != NULL);
s = zzlGetScore(sptr);
//决定被插入元素在有序的ziplist的位置
if (s > score) {
//将需要写入的元素插入到当前节点之前(整个ziplist中元素是升序排序的)
zl = zzlInsertAt(zl,eptr,ele,score);
break;
} else if (s == score) {
//如果score相同需要比较两个元素对应string的字节数大小
if (zzlCompareElements(eptr,(unsigned char*)ele,sdslen(ele)) > 0) {
//当前节点元素字节数大于插入元素的字节数大小
//将需要写入的元素插入到当前节点之前(整个ziplist中元素是升序排序的)
zl = zzlInsertAt(zl,eptr,ele,score);
break;
}
}
//指针移动到下一个节点 这个下一个节点是对应下一个元素所在entry
eptr = ziplistNext(zl,sptr);
}
//可能是一个空ziplist 或者当前元素score最大 所以将元素写到ziplist尾部
if (eptr == NULL)
zl = zzlInsertAt(zl,NULL,ele,score);
return zl;
}
/**
* 将元素和score写入到ziplist
* @param zl ziplist
* @param eptr 元素被插入位置对应的后一个entry节点
* @param ele 需要插入元素值
* @param score 元素值对应score
* @return 返回ziplist指针
*/
unsigned char *zzlInsertAt(unsigned char *zl, unsigned char *eptr, sds ele, double score) {
unsigned char *sptr;
char scorebuf[128];
int scorelen;
size_t offset;
//将double类型的score转换为string 并返回对应的length
scorelen = d2string(scorebuf,sizeof(scorebuf),score);
if (eptr == NULL) {
//直接将数据写入到ziplist 尾部
zl = ziplistPush(zl,(unsigned char*)ele,sdslen(ele),ZIPLIST_TAIL);
zl = ziplistPush(zl,(unsigned char*)scorebuf,scorelen,ZIPLIST_TAIL);
} else {
//计算ziplist头距离当前entry的offset(即指针偏移量) 后续需要此值
offset = eptr-zl;
//插入元素 ziplistInsert该方法将元素变更为entry插入指定entry上一个位置
zl = ziplistInsert(zl,eptr,(unsigned char*)ele,sdslen(ele));
//指针向右移动了offset 此时指针所在位置处于新插入的元素位置
eptr = zl+offset;
//指针继续向下一个entry移动为后续插入score做准备
serverAssert((sptr = ziplistNext(zl,eptr)) != NULL);
//将socore变更为entry插入到ziplist中指定位置(元素之后)
zl = ziplistInsert(zl,sptr,(unsigned char*)scorebuf,scorelen);
}
return zl;
}
/**
*添加新元素或更新已排序集合中现有元素的分数,而不考虑其编码
* 添加元素后会检验是否需要将ziplist转换为skiplist
* @param zobj zset结构体对象
* @param score 写入的元素对应的score
* @param ele 函数不拥有'ele'SDS字符串的所有权如果需要的话先进性复制
* @param flags 用整数指针传递的,不同值用以以指示不同的条件,包含以下类型
* ZADD_INCR=1<<0=1:按score递增当前元素分数,而不是更新当前元素分数。如果当前元素不存在,以0作为初始分数
* ZADD_NX=1<<1=2: 仅当元素不存在时才执行操作
* ZADD_XX=1<<2=4: 仅当元素已经存在时才执行操作用于更新操作
*
* @param newscore
* @return 成功返回1 失败返回0 当前仅当增量产生NAN条件时,或当“score”值自启动以来为NAN时
*/
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {
//将选项转换为简单的检查变量 若包含此命令则该值为1 否则为0
int incr = (*flags & ZADD_INCR) != 0;
int nx = (*flags & ZADD_NX) != 0;
int xx = (*flags & ZADD_XX) != 0;
//重置变量值 后续操作完用以返回不同结果
*flags = 0;
//定义score游标 用于记录访问set列表时的score5
double curscore;
//检查score是否为合法number
if (isnan(score)) {
//定义该元素此次操作为ZADD_NAN
*flags = ZADD_NAN;
return 0;
}
//根据当前zset其编码更新数据
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
//当前底层数据结构为zipist
//定义当前元素对应的指针类型
unsigned char *eptr;
//获取sorted set中值对应的entry 并赋值对应score于中间变量curscore
if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) {
//如果是NX操作因为元素在sortedset已经存在则无法进行修改直接返回
if (nx) {
*flags |= ZADD_NOP;
return 1;
}
//如果当前命令为incr
if (incr) {
//累加值对应的分值
score += curscore;
//如果score为非法number
if (isnan(score)) {
*flags |= ZADD_NAN;
return 0;
}
//针对于incr操作需要将最新score返回
if (newscore) *newscore = score;
}
//当socre发生变更时(不论是incr操作或zadd 中score的变更) 将新score重新写入
if (score != curscore) {
//将新值重写写入到ziplist中
zobj->ptr = zzlDelete(zobj->ptr,eptr);
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
//定义该元素此次操作为update
*flags |= ZADD_UPDATED;
}
return 1;
} else if (!xx) {
/**当前操作为新增操作*/
//将元素和对应score写入到ziplist中
zobj->ptr = zzlInsert(zobj->ptr,ele,score);
/**
* 当满足满足下列任意条件是,将当前ziplist变更为skiplist结构:
* 1:当前ziplist中元素的个数大于redis.conf中zset-max-ziplist-entries属性值(默认为128)
* 2:当前元素对应字节大小要大于redis.conf中zset-max-ziplist-value属性值(默认为64字节)
*/
if (zzlLength(zobj->ptr) > server.zset_max_ziplist_entries)
//将ziplist变更为skiplist
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
if (sdslen(ele) > server.zset_max_ziplist_value)
//将ziplist变更为skiplist
zsetConvert(zobj,OBJ_ENCODING_SKIPLIST);
//针对于incr操作需要将最新score返回
if (newscore) *newscore = score;
//返回当前操作类型为ZADD_ADDED
*flags |= ZADD_ADDED;
return 1;
} else {
//定义该元素此次操作为ZADD_NOP
*flags |= ZADD_NOP;
return 1;
}
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
//当前编码方式为skiplist
//获取zset结构体指针
zset *zs = zobj->ptr;
//定义dictEntry与zskiplistNode指针变量
zskiplistNode *znode;
dictEntry *de;
//从zset字典索引中获取该元素对应的dictentry
de = dictFind(zs->dict,ele);
if (de != NULL) {
//如果是NX操作因为元素在sortedset已经存在则无法进行修改直接返回
if (nx) {
//定义该元素此次操作为ZADD_NOP
*flags |= ZADD_NOP;
return 1;
}
//从索引字典中获取socre
curscore = *(double*)dictGetVal(de);
//如果当前命令为incr
if (incr) {
//累加值对应的分值
score += curscore;
//如果score为非法number
if (isnan(score)) {
//定义该元素此次操作为ZADD_NAN
*flags |= ZADD_NAN;
return 0;
}
//针对于incr操作需要将最新score返回
if (newscore) *newscore = score;
}
//当socre发生变更时(不论是incr操作或zadd 中score的变更) 将新score重新写入
if (score != curscore) {
//将新值重新写入到skiplist的node中
znode = zslUpdateScore(zs->zsl,curscore,ele,score);
//修改set索引中元素对应score
dictGetVal(de) = &znode->score;
//定义该元素操作为update
*flags |= ZADD_UPDATED;
}
return 1;
} else if (!xx) {
//如果当前命令不为xx 表情新写入元素值不存在
ele = sdsdup(ele);
//新创建一个skipnode 并写入对应score和元素值
znode = zslInsert(zs->zsl,score,ele);
//将新建的数据写入到set的索引字典中
serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
//定义该元素此次操作为add
*flags |= ZADD_ADDED;
if (newscore) *newscore = score;
return 1;
} else {
//定义该元素此次操作为ZADD_NOP
*flags |= ZADD_NOP;
return 1;
}
} else {
serverPanic("Unknown sorted set encoding");
}
return 0;
}
/**
* 该函数用于返回要创建的新skiplist节点的随机级别。
* 并且此函数的返回值(skiplist中level)会介于1和ZSKIPLIST_MAXLEVEL(64)(两者都包括在内)之间
* 一个具有k个后继指针的结点称为k层结点。假设k层结点的数量是k+1层结点的P倍,那么其实这个跳跃表可以看成是一棵平衡的P叉树
* 该算法的就是用来实现上述描述
* @return
*/
int zslRandomLevel(void) {
int level = 1;
/**
* random()&0xFFFF形成的数,会均匀分布在区间[0,0xFFFF]上 而ZSKIPLIST_P * 0xFFF(0.25*0xFFFF)
* 那么每次完成上述条件的概率都为0.25
* 那么level=1的概率 1-0.25=0.75=3/4 level=2的概率为 0.25*0.75 level=3的概率为0.25*0.25*0.75
* 依次向下推导 level=n的概率为0.25^(n-1)*0.75
* 所以如果假设level为k的概率为x,则返回level为k+1的概率为0.25*x 从另外一个角度来说
* 假设有第k层的节点数为x,则k+1层的节点数为0.25*x 这也就是幂次定律(powerlaw),越大的数出现的概率越小
* 也表明了为何这个跳跃表可以看成一颗平衡的p叉树
*
*/
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
//最大等级不会超过64
return (level/**
* zrang命令源码
* @param c
*/
void zrangeCommand(client *c) {
zrangeGenericCommand(c,0);
}
/**
* zrevrange命令源码
* @param c
*/
void zrevrangeCommand(client *c) {
zrangeGenericCommand(c,1);
}
/**
* ZREVRANGE与ZREVRANGE命令具体函数实现
* @param c 客户端类client ZRANGE|ZREVRANGE 键 start end withscores
* @param reverse 排列顺序0:升序 1:降序
*/
void zrangeGenericCommand(client *c, int reverse) {
//定义key
robj *key = c->argv[1];
robj *zobj;
//定义变量withscores 当前请求命令是否返回score
int withscores = 0;
//定义中间变量
long start;
long end;
//当前set中元素的个数
long llen;
//此次查询批次score对应的范围
long rangelen;
/**开始进行 */
//获取命令中所携带的参数并赋值中间变量 start end 若两参数不为long类型 结束函数运行 并报错
//(error) ERR value is not an integer or out of range
if ((getLongFromObjectOrReply(c, c->argv[2], &start, NULL) != C_OK) ||
(getLongFromObjectOrReply(c, c->argv[3], &end, NULL) != C_OK)) return;
//判断当前命令中是否包含withscores值
if (c->argc == 5 && !strcasecmp(c->argv[4]->ptr,"withscores")) {
withscores = 1;
} else if (c->argc >= 5) {
//命令参数个数超长处理 发生给客户端异常信息 (error) ERR syntax error
addReply(c,shared.syntaxerr);
return;
}
//从字典中查询到键对应数据结构 若存在并判断编码方式为OBJ_ZSET时继续执行
if ((zobj = lookupKeyReadOrReply(c,key,shared.emptymultibulk)) == NULL
|| checkType(c,zobj,OBJ_ZSET)) return;
/* 重新计算rang的start和end */
//获取当前zset中元素的个数
llen = zsetLength(zobj);
/**下标参数 start 和 stop 都以 0 为底
* 以 0 表示有序集第一个成员,以 1 表示有序集第二个成员,以此类推。
* 若以 -1 表示最后一个成员 则 -2 表示倒数第二个成员,以此类推。
*
*/
if (start < 0) start = llen+start;
if (end < 0) end = llen+end;
if (start < 0) start = 0;
//如果start>end 或者start>zset中元素总大小 直接返回(empty list or set)
if (start > end || start >= llen) {
addReply(c,shared.emptymultibulk);
return;
}
//计算
if (end >= llen) end = llen-1;
//获取此次批次查询的范围
rangelen = (end-start)+1;
//以多批回复的形式返回结果
addReplyMultiBulkLen(c, withscores ? (rangelen*2) : rangelen);
if (zobj->encoding == OBJ_ENCODING_ZIPLIST) {
//如果为数据底层类型为ziplist
//这里不细说了有兴趣可以自行看下,基本都是ziplist的基本操作
} else if (zobj->encoding == OBJ_ENCODING_SKIPLIST) {
//如果为数据底层类型为skiplist
zset *zs = zobj->ptr;
//获取skiplist
zskiplist *zsl = zs->zsl;
//定义中间变量
zskiplistNode *ln;
sds ele;
//在执行O(log(N))的查找之前 根据条件用以获取起点的位置
if (reverse) {
//如果是倒序(从大到小)i的话 起点从尾部开始
ln = zsl->tail;
if (start > 0)
//获取指定位置上的节点获取指定位置上的节点
ln = zslGetElementByRank(zsl,llen-start);
} else {
//如果是正序(从小到大)的话
ln = zsl->header->level[0].forward;
if (start > 0)
//获取指定位置上的节点获取指定位置上的节点
ln = zslGetElementByRank(zsl,start+1);
}
//遍历skiplist链表
while(rangelen--) {
serverAssertWithInfo(c,zobj,ln != NULL);
//获取当前元素值
ele = ln->ele;
//将元素值写入到buffer中批次发送
addReplyBulkCBuffer(c,ele,sdslen(ele));
if (withscores)
//将元素值对应的score发送到客户端
addReplyDouble(c,ln->score);
//按照降序还是升序的形式向前或向后迭代节点
ln = reverse ? ln->backward : ln->level[0].forward;
}
} else {
serverPanic("Unknown sorted set encoding");
}
}
/**
*按找rank值来查找对应的元素节点。
* 通过每个节点对应的span数可以快速获取在skiplist指定开始位置对应的节点
* @param zsl 对应的skiplist
* @param rank rank值代表的是在skiplist中需要被找到的节点距离header之间存在的节点数 传入的rank参数必须大于1
* @return
*/
zskiplistNode* zslGetElementByRank(zskiplist *zsl, unsigned long rank) {
zskiplistNode *x;
//变量用于记录遍历多次后最新节点距离header中节点数
unsigned long traversed = 0;
int i;
//从header开始
x = zsl->header;
//遍历所有level层中对应的链表 从当前skiplist中最高level开始向下寻找
for (i = zsl->level-1; i >= 0; i--) {
//遍历当前层链表
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
//累加span
traversed += x->level[i].span;
//继续下一节点直到满足要求
x = x->level[i].forward;
}
//如果计算出的traversed ==rank 说明已找到节点返回节点
if (traversed == rank) {
return x;
}
}
return NULL;
}1.4.6:streams(关于这块可以先了解消息队列的概念)
1.5:redisObject提供对函数
/*定义在server.h 具体实现在Object.c */
void decrRefCount(robj *o);
void decrRefCountVoid(void *o);
void incrRefCount(robj *o);
robj *makeObjectShared(robj *o);
robj *resetRefCount(robj *obj);
void freeStringObject(robj *o);
void freeListObject(robj *o);
void freeSetObject(robj *o);
void freeZsetObject(robj *o);
void freeHashObject(robj *o);
robj *createObject(int type, void *ptr);
robj *createStringObject(const char *ptr, size_t len);
robj *createRawStringObject(const char *ptr, size_t len);
robj *createEmbeddedStringObject(const char *ptr, size_t len);
robj *dupStringObject(const robj *o);
int isSdsRepresentableAsLongLong(sds s, long long *llval);
int isObjectRepresentableAsLongLong(robj *o, long long *llongval);
robj *tryObjectEncoding(robj *o);
robj *getDecodedObject(robj *o);
size_t stringObjectLen(robj *o);
robj *createStringObjectFromLongLong(long long value);
robj *createStringObjectFromLongLongForValue(long long value);
robj *createStringObjectFromLongDouble(long double value, int humanfriendly);
robj *createQuicklistObject(void);
robj *createZiplistObject(void);
robj *createSetObject(void);
robj *createIntsetObject(void);
robj *createHashObject(void);
robj *createZsetObject(void);
robj *createZsetZiplistObject(void);
robj *createStreamObject(void);
robj *createModuleObject(moduleType *mt, void *value);
int getLongFromObjectOrReply(client *c, robj *o, long *target, const char *msg);
int checkType(client *c, robj *o, int type);
int getLongLongFromObjectOrReply(client *c, robj *o, long long *target, const char *msg);
int getDoubleFromObjectOrReply(client *c, robj *o, double *target, const char *msg);
int getDoubleFromObject(const robj *o, double *target);
int getLongLongFromObject(robj *o, long long *target);
int getLongDoubleFromObject(robj *o, long double *target);
int getLongDoubleFromObjectOrReply(client *c, robj *o, long double *target, const char *msg);
char *strEncoding(int encoding);
int compareStringObjects(robj *a, robj *b);
int collateStringObjects(robj *a, robj *b);
int equalStringObjects(robj *a, robj *b);
unsigned long long estimateObjectIdleTime(robj *o);
void trimStringObjectIfNeeded(robj *o);