Inferring Analogous Attributes CVPR 2014
Chao-Yeh Chen and Kristen Grauman
Abstract:
The appearance of an attribute can vary considerably from class to class (e.g., a “fluffy” dog vs. a “fluffy” towel), making standard class-independent attribute models break down. Yet, training object-specific models for each attribute can be impractical, and defeats the purpose of using attributes to bridge category boundaries. We propose a novel form of transfer learning that addresses this dilemma. We develop a tensor factorization approach which, given a sparse set of class-specific attribute classifiers, can infer new ones for object-attribute pairs unobserved during training. For example, even though the system has no labeled images of striped dogs, it can use its knowledge of other attributes and objects to tailor “stripedness” to the dog category. With two large-scale datasets, we demonstrate both the need for category-sensitive attributes as well as our method’s successful transfer. Our inferred attribute classifiers perform similarly well to those trained with the luxury of labeled class-specific instances, and much better than those restricted to traditional modes of transfer.
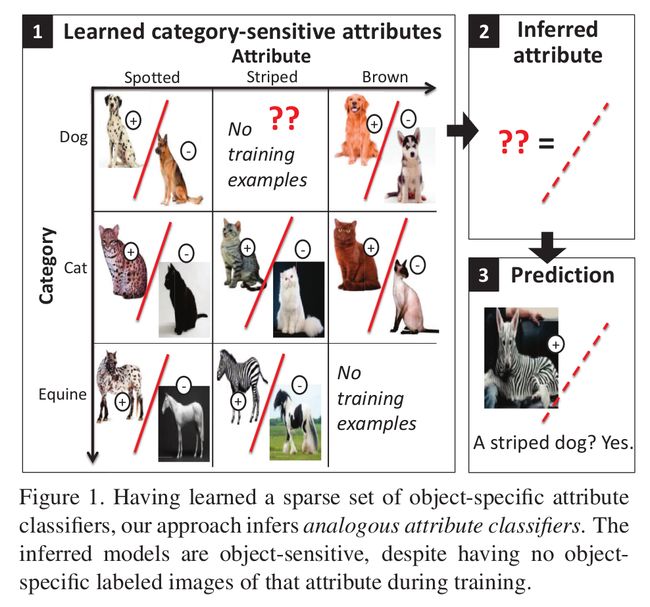
从上图可以看出,通过学习一些特定目标的属性分类器,我们可以类推出相似的属性分类器.该分类器是对目标敏感的,虽然没有特定种类的带标签的训练图像.
1.Introduction:
本文的核心贡献有3点:
1.First, performing transfer jointly in the space of two labeled aspects of the data—namely, categories and attributes—is new. Critically, this means our method is not confined to transfer along same-object or same-attribute boundaries; rather, it discovers analogical relationships based on some mixture of previously seen objects and attributes.
第一点,就是与传统的转移学习不同,本文的转移是联合的转移,即:目标种类和属性的转移.
2.Second, our approach produces a discriminative model for an attribute with zero training examples from that category.
第二点,就是产生一种判别性的模型,尽管该类属性没有训练样本.
3.Third, while prior methods often require information about which classes should transfer to which [2, 29, 26, 1] (e.g., that a motorcycle detector might transfer well to a bicycle), our approach naturally discovers where transfer is possible based on how the observed attribute models relate. It can transfer easily between multiple classes at once, not only pairs, and we avoid the guesswork of manually specifying where transfer is likely.
第三点,就是本文所提出的方法不需要关于什么转移到什么的信息.而可以在多种类别之间很方便的转移.
2. Related Work
In contrast, our approach implicitly discovers analogical relationships among object-sensitive attribute classifiers, and our goal is to generate
novel category-sensitive attribute classifiers.
3. Approach
Given training images labeled by their category and one or more attributes, our method produces as output a series of category-sensitive attribute classifiers. Some of those classifiers are explicitly trained with the labeled data, while the rest are inferred by our method. We show how to create these analogous attribute classifiers via tensor completion.
In the following, we first describe how we train category-sensitive classifiers (Sec. 3.1). Then we define the tensor of attributes (Sec. 3.2) and show how we use it to infer analogous models (Sec. 3.3). Finally, we discuss certain salient aspects of the method design (Sec. 3.4).
3.1. Learning Category-Sensitive Attributes
在现有的系统当中,属性的训练是通过一种种类之间相互独立的方式 ( in a category-independent manner )进行.
在这个工作中,我们挑战传统的训练方式,即:in a completely category-indenpent mannner.
while attributes’ visual cues are often shared among some objects, the sharing is not universal. It can dilute(稀释) the learning process to pool cross-category exemplars indiscriminately. (在某些物体中,属性的视觉线索通常是共享的,但是这种共享不是普遍的.能够非判别性的稀释学习过程来集中跨种类的样本).
一种比较 naive 的做法就是,instead train category-sensitive attributes would be to partition training exemplars by their category labels, and train one attribute per category. 当有足够的 attribute + object combinations 的带标签的样本时,这种策略可能是足够的.但是,初步实验证明该方法是次于训练单个普遍的属性.我们归结了两点原因:
1.even in large-scale collections, the long-tailed distribution of object/scene/attribute occurrences in the real world means that some label pairs will be undersampled, leaving inadequate exemplars to build a statistically sound model,
2.this naive approach completely ignores attributes’ inter-class semantic ties. 属性类别之间的语意连接.
To overcome these shortcomings, we instead use an importance-weighted support vector machine (SVM) to train each category-sensitive attribute. 每一个训练样本(xi, yi)都包括一个图像描述xi,和标签yi 属于{-1, +1}.