2机器学习sklearn-----降维
1.降维介绍
保证数据所具有的代表性特性或分布的情况下,将高维数据转化为低维数据。
聚类和分类都是无监督学习的典型任务,任务之间存在关联,比如某些高维数据的分类可以通过降维处理更好的获得。
降维过程可以被理解为数据集的组成成分进行分解(decomposition)的过程,因此sklearn为降维模块命名为decomposition。在对降维算法调用需要使用sklearn.decomposition模块

2.降维算法
①主成分分析(PCA)
主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够尽可能保留原始数据的信息。
其中需要理解的一些数学知识:
1.方差:是各个样本和样本均值的差的平方和的均值,用来度量一组数据的分散程度。

2.协方差:用于度量两个变量之间的线性相关性程度,若两个变量的协方差为0,则可认为二者线性无关。协方差矩阵则 是由变量的协方差值构成的矩阵(对称阵)

3.特征向量:矩阵的特征向量是描述数据集结构的非零向量,并满足 如下公式:

其中A是方阵,υ是特征向量,λ是特征值
算法原理:矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推。
算法过程:

具体使用:
使用sklearn.decomposition.PCA加载PCA进行降维,主要参数有:
• n_components:指定主成分的个数,即降维后数据的维度
• svd_solver :设置特征值分解的方法,默认为‘auto’,其他可选有 ‘full’, ‘arpack’, ‘randomized’。
实例:
已知鸢尾花数据是4维的, 共三类样本。使用PCA实现对鸢尾花 数据进行降维,实现在二维平面上的可视化。
import matplotlib.pyplot as plt #加载可视化的库 from sklearn.decomposition import PCA #加载PCA算法包 from sklearn.datasets import load_iris #加载鸢尾花数据集导入函数 data = load_iris() #以字典形式加载鸢尾花数据集 y= data.target #使用y表示数据集中的标签 x=data.data #使用x表示数据集中的属性 pca =PCA(n_components=2) #加载PCA算法,设置降维后主成分数目为2 reduced_X =pca.fit_transform(x) #对原始数据进行降维,保存在reduced_X中 #按类别对降维后的数据进行保存 red_x ,red_y =[],[] #第一类数据点 blue_x,blue_y =[],[] #第二类数据点 green_x,green_y=[],[] #第三类数据点 #按照类别对降维后的数据进行保存 for i in range(len(reduced_X)): if y[i]==0: red_x.append(reduced_X[i][0]) red_y.append(reduced_X[i][0]) elif y[i]==1: blue_x.append(reduced_X[i][0]) blue_y.append(reduced_X[i][1]) else: green_x.append(reduced_X[i][0]) green_y.append(reduced_X[i][1]) #降维数据的可视化 plt.scatter(red_x,red_y,c='r',marker='x') plt.scatter(blue_x,blue_y,c='b',marker='D') plt.scatter(green_x,green_y,c='g',marker='.') plt.show()
运行结果:

可以看出,降维后的数 据仍能够清晰地分成三类。 这样不仅能削减数据的维度, 降低分类任务的工作量,还 能保证分类的质量。
②非负矩阵分解(NMF)
非负矩阵分解(Non-negative Matrix Factorization ,NMF) 是在矩阵中所有元素均为非负数约束条件之下的矩阵分解方法。
基本思想:给定一个非负矩阵V,NMF能够找到一个非负矩阵W和一个 非负矩阵H,使得矩阵W和H的乘积近似等于矩阵V中的值。并且有且仅有一个这样的分解,即满足存在性和唯一性。


问题描述
给定矩阵 ,寻找非负矩阵
,寻找非负矩阵 和非负矩阵
和非负矩阵 ,使得
,使得
分解前后可理解为:原始矩阵 的列向量是对左矩阵
的列向量是对左矩阵 中所有列向量的加权和,而权重系数就是右矩阵对应列向量的元素,故称
中所有列向量的加权和,而权重系数就是右矩阵对应列向量的元素,故称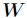 为基矩阵,
为基矩阵,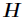 为系数矩阵。一般情况下
为系数矩阵。一般情况下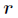 的选择要比
的选择要比 小,即满足
小,即满足 。
。
这时用系数矩阵代替原始矩阵,就可以实现对原始矩阵进行降维,得到数据特征的降维矩阵,从而减少存储空间,减少计算机资源。
NMF实现原理
NMF求解问题实际上是一个最优化问题,利用乘性迭代的方法求解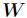 和
和 ,非负矩阵分解是一个NP问题。NMF题的目标函数有很多种,应用最广泛的就是欧几里得距离和KL散度。
,非负矩阵分解是一个NP问题。NMF题的目标函数有很多种,应用最广泛的就是欧几里得距离和KL散度。
在NMF的分解问题中,假设噪声矩阵为 ,那么有
,那么有

现在要找出合适的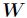 和
和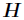 使得
使得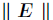 最小。假设噪声服从不同的概率分布,通过最大似然函数会得到不同类型的目标函数。接下来会分别以噪声服从高斯分布和泊松分布来说明。
最小。假设噪声服从不同的概率分布,通过最大似然函数会得到不同类型的目标函数。接下来会分别以噪声服从高斯分布和泊松分布来说明。
(1)噪声服从高斯分布
假设噪声服从高斯分布,那么得到最大似然函数为:

取对数后,得到对数似然函数为:

假设各数据点噪声的方差一样,那么接下来要使得对数似然函数取值最大,只需要下面目标函数值最小。
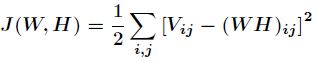
该损失函数为2范数损失函数,它是基于欧几里得距离的度量。又因为
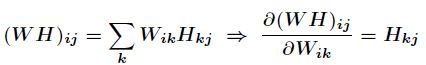
那么得到

同理有

接下来就可以使用梯度下降法进行迭代了。如下
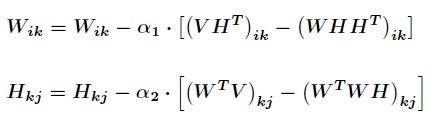
如果选取

那么最终得到迭代式为
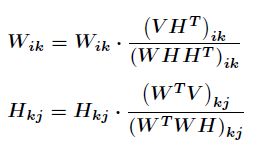
可看出这是乘性迭代规则,每一步都保证了结果为正数,一直迭代下去就会收敛,当然收敛性的证明省略。
(2)噪声服从泊松分布
若噪声为泊松噪声,那么得到损失函数为
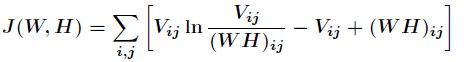
同样经过推到得到

最后总结为:
矩阵分解优化目标:最小化W矩阵H矩阵的乘积和原始矩阵之间的差别,目标函数如下:
 基于KL散度的优化目标,损失函数如下:
基于KL散度的优化目标,损失函数如下:

具体使用:
在sklearn库中,可以使用sklearn.decomposition.NMF加载NMF算 法,主要参数有:
• n_components:用于指定分解后矩阵的单个维度k;
• init:W矩阵和H矩阵的初始化方式,默认为‘nndsvdar’。
实例:NMF人脸数据特征提取
目标:已知Olivetti人脸数据共 400个,每个数据是64*64大小。由于NMF分解得到的W矩阵相当于从原始矩阵中提取的特征,那么就可以使用NMF对400个人脸数据进行特征提取。
通过设置k的大小,设置提取的 特征的数目。在本实验中设置k=6, 随后将提取的特征以图像的形式展示 出来。

import matplotlib.pyplot as plt #加载matplotlib用于数据可视化 from sklearn import decomposition #加载PCA算法包 from sklearn.datasets import fetch_olivetti_faces #加载人脸数据集 from numpy.random import RandomState #加载RandomState用于创建随机种子 #设置基本参数并加载数据: n_row,n_col =2,3 #设置图像展示时的排列情况 n_components =n_row*n_col #设置提取的特征的数目 image_shape =(64,64) #人脸数据图片的像素矩阵大小 dataset =fetch_olivetti_faces(shuffle=True,random_state=RandomState(0)) #加载人脸数据,并打乱顺序 faces =dataset.data #设置图像的展示方式 def plot_gallery(title,images,n_col=n_col,n_row=n_row): #创建图片,并指定图片大小(英寸) plt.figure(figsize=(2.0*n_col,2.26*n_row)) #设置镖旗及字号大小 plt.suptitle(title,size=16) for i,comp in enumerate(images): #选择画制的子图,第三个参数为第几个图,从1开始 plt.subplot(n_row,n_col,i+1) vmax =max(comp.max(),-comp.min()) plt.imshow(comp.reshape(image_shape),cmap=plt.cm.gray, interpolation='nearest',vmin=-vmax,vmax=vmax) plt.xticks(()) plt.yticks(()) plt.subplots_adjust(0.01,0.05,0.99,0.93,0.04,0.0) #创建特征提取的对象NMF,使用PCA作为对比 estimators =[ ('Eigenfaces - PCA using randomized SVD', decomposition.PCA(n_components=6,whiten=True)), ('Non-negative components - NMF', decomposition.NMF(n_components=6,init='nndsvda', tol=5e-3))] #降维后数据点的可视化: for name,estimator in estimators: estimator.fit(faces)#调用PCA或NMF提取特征 components_ =estimator.components_ #获取提取的特征 plot_gallery(name,components_[:n_components]) #按照固定格式进行排列 plt.show()
结果:

