Kaggle Tweet Sentiment Extraction竞赛
Kaggle Tweet Sentiment Extraction竞赛
Kaggle是一个数据分析竞赛的网站,里面有很多有趣的竞赛和练习。最近刚结束的一个twitter sentiment extraction的竞赛挺有意思的,给出Twitter的文本以及情感分类(positive, negative, neutral),需要找出文本中的哪些内容是支持这个情感分类的。例如对于“Sooo SAD I will miss you here in San Diego!!!”这条推特,分类为negative,其中的“Sooo SAD”是判断为negative的依据。这个竞赛可以看作为NLP中的问答,即把tweet文本以及情感分类作为上下文,从中找出一些词语作为答案。
数据探索性分析EDA
现在我们先来看看这个竞赛提供的训练数据,做一些探索性数据分析的工作,详细了解这个训练集的内容。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
from plotly import graph_objs as go
import plotly.express as px
import plotly.figure_factory as ff
import nltk
from nltk.corpus import stopwords
from PIL import Image
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import numpy as np
import tensorflow as tf
import tensorflow.keras.backend as K
from sklearn.model_selection import StratifiedKFold
from transformers import *
import tokenizers
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
train.head()
| textID | text | selected_text | sentiment | |
|---|---|---|---|---|
| 0 | cb774db0d1 | I`d have responded, if I were going | I`d have responded, if I were going | neutral |
| 1 | 549e992a42 | Sooo SAD I will miss you here in San Diego!!! | Sooo SAD | negative |
| 2 | 088c60f138 | my boss is bullying me... | bullying me | negative |
| 3 | 9642c003ef | what interview! leave me alone | leave me alone | negative |
| 4 | 358bd9e861 | Sons of ****, why couldn`t they put them on t... | Sons of ****, | negative |
train.info()
RangeIndex: 27481 entries, 0 to 27480
Data columns (total 4 columns):
textID 27481 non-null object
text 27480 non-null object
selected_text 27480 non-null object
sentiment 27481 non-null object
dtypes: object(4)
memory usage: 858.9+ KB
训练集中有一个记录的text和selected_text是null,删除掉这个数据
train.dropna(inplace=True)
查看训练集数据中的sentiment类别的分布
temp = train.groupby('sentiment').count()['text'].reset_index().sort_values(by='text',ascending=False)
temp.style.background_gradient(cmap='Purples')
| sentiment | text | |
|---|---|---|
| 1 | neutral | 11117 |
| 2 | positive | 8582 |
| 0 | negative | 7781 |
查看Text和selected_text之间的Jaccard相似度
def jaccard(str1, str2):
a = set(str1.lower().split())
b = set(str2.lower().split())
if (len(a)==0) & (len(b)==0): return 0.5
c = a.intersection(b)
return float(len(c)) / (len(a) + len(b) - len(c))
results_jaccard=[]
for ind,row in train.iterrows():
sentence1 = row.text
sentence2 = row.selected_text
jaccard_score = jaccard(sentence1,sentence2)
results_jaccard.append([sentence1,sentence2,jaccard_score])
jaccard = pd.DataFrame(results_jaccard,columns=["text","selected_text","jaccard_score"])
train = train.merge(jaccard,how='outer')
train.head()
| textID | text | selected_text | sentiment | jaccard_score | |
|---|---|---|---|---|---|
| 0 | cb774db0d1 | I`d have responded, if I were going | I`d have responded, if I were going | neutral | 1.000000 |
| 1 | 549e992a42 | Sooo SAD I will miss you here in San Diego!!! | Sooo SAD | negative | 0.200000 |
| 2 | 088c60f138 | my boss is bullying me... | bullying me | negative | 0.166667 |
| 3 | 9642c003ef | what interview! leave me alone | leave me alone | negative | 0.600000 |
| 4 | 358bd9e861 | Sons of ****, why couldn`t they put them on t... | Sons of ****, | negative | 0.214286 |
text和selected_text的单词长度的核分布图形
train['Num_words_ST'] = train['selected_text'].apply(lambda x:len(str(x).split()))
train['Num_word_text'] = train['text'].apply(lambda x:len(str(x).split()))
train['difference_in_words'] = train['Num_word_text'] - train['Num_words_ST']
plt.figure(figsize=(12,6))
p1=sns.kdeplot(train['Num_words_ST'], shade=True, color="r").set_title('Kernel Distribution of Number Of words')
p1=sns.kdeplot(train['Num_word_text'], shade=True, color="b")

查看Sentiment分类为positive或negative的单词长度差值的核分布图形
plt.figure(figsize=(12,6))
p1=sns.kdeplot(train[train['sentiment']=='positive']['difference_in_words'], shade=True, color="b").set_title('Kernel Distribution of Difference in Number Of words')
p2=sns.kdeplot(train[train['sentiment']=='negative']['difference_in_words'], shade=True, color="r")

查看Sentiment分类为positive或negative的Jaccard相似性的核分布图形
plt.figure(figsize=(12,6))
p1=sns.kdeplot(train[train['sentiment']=='positive']['jaccard_score'], shade=True, color="b").set_title('KDE of Jaccard Scores across different Sentiments')
p2=sns.kdeplot(train[train['sentiment']=='negative']['jaccard_score'], shade=True, color="r")
plt.legend(labels=['positive','negative'])
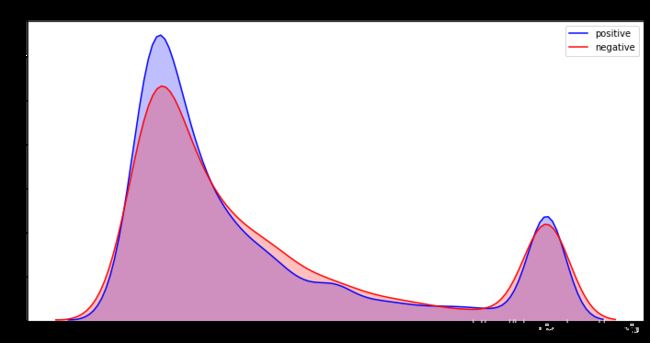
从以上的图形中可以看到,positive或者negative的text与selected_text的jaccard相似性都在1.0或0.1左右有两个尖锐的峰度。单词长度的差值也有两个峰度,其中差值为0的是一个尖锐的峰度。意味着很大一部分比例的positive或者negative的text和selected_text是一样的。
用词云的方式来展示一下不同类别的推特的词语出现的频率
def plot_wordcloud(text, mask=None, max_words=200, max_font_size=100, figure_size=(16.0,6.0), color = 'white',
title = None, title_size=40, image_color=False):
stopwords = set(STOPWORDS)
more_stopwords = {'u', "im"}
stopwords = stopwords.union(more_stopwords)
wordcloud = WordCloud(background_color=color,
stopwords = stopwords,
max_words = max_words,
max_font_size = max_font_size,
random_state = 42,
width=200,
height=100,
mask = mask)
wordcloud.generate(str(text))
plt.figure(figsize=figure_size)
if image_color:
image_colors = ImageColorGenerator(mask);
plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation="bilinear");
plt.title(title, fontdict={'size': title_size,
'verticalalignment': 'bottom'})
else:
plt.imshow(wordcloud);
plt.title(title, fontdict={'size': title_size, 'color': 'black',
'verticalalignment': 'bottom'})
plt.axis('off');
plt.tight_layout()
Netural的词云
pos_mask = np.array(Image.open('twitter.jpg'))
neutral_sent = train[train['sentiment']=='neutral']
plot_wordcloud(neutral_sent.text,mask=pos_mask,color='white',max_font_size=80,title_size=30,title="WordCloud of Neutral Tweets")

Postive的词云
positive_sent = train[train['sentiment']=='positive']
plot_wordcloud(positive_sent.text,mask=pos_mask,color='white',max_font_size=80,title_size=30,title="WordCloud of Neutral Tweets")

Negative的词云
negative_sent = train[train['sentiment']=='negative']
plot_wordcloud(negative_sent.text,mask=pos_mask,color='white',max_font_size=80,title_size=30,title="WordCloud of Neutral Tweets")

模型构建与训练
NLP近年来发展很快,涌现出了很多好的论文和模型,其中以Google提出的BERT模型最为著名,之后还有很多类似BERT的模型,例如Facebook的roBERTa,Google的XLNet等等。这些模型在大规模的语料库中进行训练,其得出的词向量可以用在不同的NLP领域中,不过这些训练都需要耗费大量的GPU,对于一般的个人来说是无法负担这个从头训练的开销的,因此我们可以利用已训练好的模型参数,进行微调后用在我们的NLP任务中。这里我采用的是HuggingFace开源的Transformers库,这个库提供了很多已经预训练好的模型,并提供很完善易用的接口,可以直接调用,并采用Pytorch或者Tensorflow来搭建模型。具体可以上huggingface.co/transformers查阅详细的文档介绍。
我采用的是Facebook的roBERTa模型,首先需要构建tokenizer,把训练文本转化为RoBerta的token,可见以下例子:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Nf8ssmbn-1596323023905)(roberta_token.jpg)]
构建tokenizer,转换训练集和测试集的文本为token
MAX_LEN = 96
PATH = '../../NLP/models/roberta-base/'
tokenizer = tokenizers.ByteLevelBPETokenizer(
vocab_file=PATH+'vocab.json',
merges_file=PATH+'merges.txt',
lowercase=True,
add_prefix_space=True
)
sentiment_id = {'positive': 1313, 'negative': 2430, 'neutral': 7974}
ct = train.shape[0]
input_ids = np.ones((ct,MAX_LEN),dtype='int32')
attention_mask = np.zeros((ct,MAX_LEN),dtype='int32')
token_type_ids = np.zeros((ct,MAX_LEN),dtype='int32')
start_tokens = np.zeros((ct,MAX_LEN),dtype='int32')
end_tokens = np.zeros((ct,MAX_LEN),dtype='int32')
for k in range(train.shape[0]):
text1 = " "+" ".join(train.loc[k,'text'].split())
text2 = " ".join(train.loc[k,'selected_text'].split())
idx = text1.find(text2)
if text1[idx-1] == " ":
idx -= 1
enc1 = tokenizer.encode(text1)
enc2 = tokenizer.encode(text2)
start_token_idx = 1
if idx>0:
start_token_idx = len(tokenizer.encode(text1[0:idx]).ids)+1
end_token_idx = start_token_idx+len(enc2.ids)-1
s_tok = sentiment_id[train.loc[k,'sentiment']]
input_ids[k,:len(enc1.ids)+5] = [0] + enc1.ids + [2,2] + [s_tok] + [2]
attention_mask[k,:len(enc1.ids)+5] = 1
start_tokens[k,start_token_idx] = 1
end_tokens[k,end_token_idx] = 1
ct = test.shape[0]
input_ids_t = np.ones((ct,MAX_LEN),dtype='int32')
attention_mask_t = np.zeros((ct,MAX_LEN),dtype='int32')
token_type_ids_t = np.zeros((ct,MAX_LEN),dtype='int32')
for k in range(test.shape[0]):
text1 = " "+" ".join(test.loc[k,'text'].split())
enc = tokenizer.encode(text1)
s_tok = sentiment_id[test.loc[k,'sentiment']]
input_ids_t[k,:len(enc.ids)+5] = [0] + enc.ids + [2,2] + [s_tok] + [2]
attention_mask_t[k,:len(enc.ids)+5] = 1
构建roBERTa模型,首先加载预训练好的模型,模型的输入是上面转换后的文本token,输出是BatchxMAX_LENx768的向量,添加两个Q&A的Head,其中一个负责预测答案(selected_text)的开始位置,另一负责预测答案的结束位置。通过对输出向量进行一个768x1的全连接层来得到Head,这样输出就变为BatchxMAX_LENx1的向量,再rehaspe为BatchxMAX_LEN的向量,然后进行Softmax
这里做了一点改进,即先加一个Head预测结束位置,再把这个Head的输出和原模型的输出拼接起来,接另外一个Head来预测开始位置。
def build_model():
ids = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
att = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
tok = tf.keras.layers.Input((MAX_LEN,), dtype=tf.int32)
config = RobertaConfig.from_pretrained(PATH+'config.json')
bert_model = TFRobertaModel.from_pretrained(PATH+'tf_model.h5',config=config)
x = bert_model(ids,attention_mask=att,token_type_ids=tok)
# The end position of the answer
x2 = tf.keras.layers.Dropout(0.1)(x[0])
x2b = tf.keras.layers.Dense(1)(x2)
x2 = tf.keras.layers.Flatten()(x2b)
x2 = tf.keras.layers.Activation('softmax')(x2)
# The start position of the answer
x1 = tf.keras.layers.Concatenate()([x2b,x[0]])
x1 = tf.keras.layers.Dense(1)(x1)
x1 = tf.keras.layers.Flatten()(x1)
x1 = tf.keras.layers.Activation('softmax')(x1)
model = tf.keras.models.Model(inputs=[ids, att, tok], outputs=[x1,x2])
optimizer = tf.keras.optimizers.Adam(learning_rate=3e-5)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)
return model
把训练集划分为5份,每次取其中4份训练,1份做验证。
每次训练3个epoch,取验证集Loss最低的那个EPOCH的参数。每次训练完得到一个新的模型,这样最后我们会获得5个模型。
做预测时将把这5个模型的预测结果做平均。
def jaccard(str1, str2):
a = set(str1.lower().split())
b = set(str2.lower().split())
if (len(a)==0) & (len(b)==0): return 0.5
c = a.intersection(b)
return float(len(c)) / (len(a) + len(b) - len(c))
skf = StratifiedKFold(n_splits=5,shuffle=True,random_state=777)
val_start = np.zeros((input_ids.shape[0],MAX_LEN))
val_end = np.zeros((input_ids.shape[0],MAX_LEN))
for fold,(idxT,idxV) in enumerate(skf.split(input_ids,train.sentiment.values)):
print('#'*30)
print('### Start Fold %i training:'%fold)
print('#'*30)
K.clear_session()
model = build_model()
sv = tf.keras.callbacks.ModelCheckpoint(
'roberta-%i.h5'%(fold), monitor='val_loss', verbose=1, save_best_only=True,
save_weights_only=True, mode='auto', save_freq='epoch')
model.fit([input_ids[idxT,], attention_mask[idxT,], token_type_ids[idxT,]], [start_tokens[idxT,], end_tokens[idxT,]],
epochs=3, batch_size=32, verbose=True, callbacks=[sv],
validation_data=([input_ids[idxV,],attention_mask[idxV,],token_type_ids[idxV,]],
[start_tokens[idxV,], end_tokens[idxV,]]))
model.load_weights('roberta-%i.h5'%fold)
val_start[idxV,],val_end[idxV,] = model.predict([input_ids[idxV,],attention_mask[idxV,],token_type_ids[idxV,]])
val_metric = []
for k in idxV:
start = np.argmax(val_start[k])
end = np.argmax(val_end[k])
if end>=start:
selected_text = tokenizer.decode(input_ids[k,start:(end+1)])
else:
selected_text = train.loc[k, 'text']
val_metric.append(jaccard(selected_text, train.loc[k, 'selected_text']))
val_metric_all = np.mean(val_metric)
print('Fold %i metric:%f'%(fold, val_metric_all))
##############################
### Start Fold 0 training:
##############################
Some weights of the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5 were not used when initializing TFRobertaModel: ['lm_head']
- This IS expected if you are initializing TFRobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing TFRobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFRobertaModel were initialized from the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5.
If your task is similar to the task the model of the ckeckpoint was trained on, you can already use TFRobertaModel for predictions without further training.
Train on 21984 samples, validate on 5496 samples
Epoch 1/3
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
21952/21984 [============================>.] - ETA: 0s - loss: 2.2670 - activation_1_loss: 1.0392 - activation_loss: 1.2278
Epoch 00001: val_loss improved from inf to 1.76498, saving model to roberta-0.h5
21984/21984 [==============================] - 207s 9ms/sample - loss: 2.2667 - activation_1_loss: 1.0391 - activation_loss: 1.2277 - val_loss: 1.7650 - val_activation_1_loss: 0.8611 - val_activation_loss: 0.9037
Epoch 2/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.8038 - activation_1_loss: 0.8228 - activation_loss: 0.9810
Epoch 00002: val_loss did not improve from 1.76498
21984/21984 [==============================] - 204s 9ms/sample - loss: 1.8032 - activation_1_loss: 0.8225 - activation_loss: 0.9807 - val_loss: 1.7662 - val_activation_1_loss: 0.8408 - val_activation_loss: 0.9254
Epoch 3/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.6722 - activation_1_loss: 0.7702 - activation_loss: 0.9020
Epoch 00003: val_loss improved from 1.76498 to 1.73339, saving model to roberta-0.h5
21984/21984 [==============================] - 206s 9ms/sample - loss: 1.6726 - activation_1_loss: 0.7709 - activation_loss: 0.9017 - val_loss: 1.7334 - val_activation_1_loss: 0.8281 - val_activation_loss: 0.9048
Fold 0 metric:0.701402
##############################
### Start Fold 1 training:
##############################
Some weights of the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5 were not used when initializing TFRobertaModel: ['lm_head']
- This IS expected if you are initializing TFRobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing TFRobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFRobertaModel were initialized from the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5.
If your task is similar to the task the model of the ckeckpoint was trained on, you can already use TFRobertaModel for predictions without further training.
Train on 21984 samples, validate on 5496 samples
Epoch 1/3
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
21952/21984 [============================>.] - ETA: 0s - loss: 2.2584 - activation_1_loss: 1.0409 - activation_loss: 1.2175
Epoch 00001: val_loss improved from inf to 1.76730, saving model to roberta-1.h5
21984/21984 [==============================] - 215s 10ms/sample - loss: 2.2578 - activation_1_loss: 1.0406 - activation_loss: 1.2173 - val_loss: 1.7673 - val_activation_1_loss: 0.8203 - val_activation_loss: 0.9464
Epoch 2/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.7283 - activation_1_loss: 0.8079 - activation_loss: 0.9204
Epoch 00002: val_loss improved from 1.76730 to 1.66336, saving model to roberta-1.h5
21984/21984 [==============================] - 206s 9ms/sample - loss: 1.7280 - activation_1_loss: 0.8077 - activation_loss: 0.9203 - val_loss: 1.6634 - val_activation_1_loss: 0.7952 - val_activation_loss: 0.8677
Epoch 3/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.5658 - activation_1_loss: 0.7340 - activation_loss: 0.8317
Epoch 00003: val_loss did not improve from 1.66336
21984/21984 [==============================] - 205s 9ms/sample - loss: 1.5659 - activation_1_loss: 0.7342 - activation_loss: 0.8317 - val_loss: 1.7117 - val_activation_1_loss: 0.8102 - val_activation_loss: 0.9011
Fold 1 metric:0.705445
##############################
### Start Fold 2 training:
##############################
Some weights of the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5 were not used when initializing TFRobertaModel: ['lm_head']
- This IS expected if you are initializing TFRobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing TFRobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFRobertaModel were initialized from the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5.
If your task is similar to the task the model of the ckeckpoint was trained on, you can already use TFRobertaModel for predictions without further training.
Train on 21984 samples, validate on 5496 samples
Epoch 1/3
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
21952/21984 [============================>.] - ETA: 0s - loss: 2.2245 - activation_1_loss: 1.0421 - activation_loss: 1.1824
Epoch 00001: val_loss improved from inf to 1.73921, saving model to roberta-2.h5
21984/21984 [==============================] - 216s 10ms/sample - loss: 2.2231 - activation_1_loss: 1.0414 - activation_loss: 1.1816 - val_loss: 1.7392 - val_activation_1_loss: 0.8067 - val_activation_loss: 0.9326
Epoch 2/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.6859 - activation_1_loss: 0.8012 - activation_loss: 0.8847
Epoch 00002: val_loss improved from 1.73921 to 1.71752, saving model to roberta-2.h5
21984/21984 [==============================] - 207s 9ms/sample - loss: 1.6857 - activation_1_loss: 0.8010 - activation_loss: 0.8847 - val_loss: 1.7175 - val_activation_1_loss: 0.8052 - val_activation_loss: 0.9126
Epoch 3/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.5334 - activation_1_loss: 0.7320 - activation_loss: 0.8014
Epoch 00003: val_loss did not improve from 1.71752
21984/21984 [==============================] - 206s 9ms/sample - loss: 1.5331 - activation_1_loss: 0.7317 - activation_loss: 0.8014 - val_loss: 1.7310 - val_activation_1_loss: 0.8152 - val_activation_loss: 0.9161
Fold 2 metric:0.700393
##############################
### Start Fold 3 training:
##############################
Some weights of the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5 were not used when initializing TFRobertaModel: ['lm_head']
- This IS expected if you are initializing TFRobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing TFRobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFRobertaModel were initialized from the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5.
If your task is similar to the task the model of the ckeckpoint was trained on, you can already use TFRobertaModel for predictions without further training.
Train on 21984 samples, validate on 5496 samples
Epoch 1/3
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
21952/21984 [============================>.] - ETA: 0s - loss: 2.2241 - activation_1_loss: 1.0227 - activation_loss: 1.2014
Epoch 00001: val_loss improved from inf to 1.76534, saving model to roberta-3.h5
21984/21984 [==============================] - 215s 10ms/sample - loss: 2.2234 - activation_1_loss: 1.0224 - activation_loss: 1.2010 - val_loss: 1.7653 - val_activation_1_loss: 0.8515 - val_activation_loss: 0.9146
Epoch 2/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.7019 - activation_1_loss: 0.8103 - activation_loss: 0.8917
Epoch 00002: val_loss improved from 1.76534 to 1.68762, saving model to roberta-3.h5
21984/21984 [==============================] - 206s 9ms/sample - loss: 1.7009 - activation_1_loss: 0.8099 - activation_loss: 0.8909 - val_loss: 1.6876 - val_activation_1_loss: 0.8064 - val_activation_loss: 0.8817
Epoch 3/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.5538 - activation_1_loss: 0.7411 - activation_loss: 0.8127
Epoch 00003: val_loss did not improve from 1.68762
21984/21984 [==============================] - 205s 9ms/sample - loss: 1.5536 - activation_1_loss: 0.7407 - activation_loss: 0.8129 - val_loss: 1.7459 - val_activation_1_loss: 0.8075 - val_activation_loss: 0.9390
Fold 3 metric:0.705772
##############################
### Start Fold 4 training:
##############################
Some weights of the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5 were not used when initializing TFRobertaModel: ['lm_head']
- This IS expected if you are initializing TFRobertaModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPretraining model).
- This IS NOT expected if you are initializing TFRobertaModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
All the weights of TFRobertaModel were initialized from the model checkpoint at ../../NLP/models/roberta-base/tf_model.h5.
If your task is similar to the task the model of the ckeckpoint was trained on, you can already use TFRobertaModel for predictions without further training.
Train on 21984 samples, validate on 5496 samples
Epoch 1/3
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
WARNING:tensorflow:Gradients do not exist for variables ['tf_roberta_model/roberta/pooler/dense/kernel:0', 'tf_roberta_model/roberta/pooler/dense/bias:0'] when minimizing the loss.
21952/21984 [============================>.] - ETA: 0s - loss: 2.2621 - activation_1_loss: 1.0300 - activation_loss: 1.2321
Epoch 00001: val_loss improved from inf to 1.79803, saving model to roberta-4.h5
21984/21984 [==============================] - 215s 10ms/sample - loss: 2.2617 - activation_1_loss: 1.0297 - activation_loss: 1.2320 - val_loss: 1.7980 - val_activation_1_loss: 0.8497 - val_activation_loss: 0.9477
Epoch 2/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.7302 - activation_1_loss: 0.8083 - activation_loss: 0.9219
Epoch 00002: val_loss improved from 1.79803 to 1.72778, saving model to roberta-4.h5
21984/21984 [==============================] - 206s 9ms/sample - loss: 1.7299 - activation_1_loss: 0.8081 - activation_loss: 0.9218 - val_loss: 1.7278 - val_activation_1_loss: 0.8590 - val_activation_loss: 0.8681
Epoch 3/3
21952/21984 [============================>.] - ETA: 0s - loss: 1.6010 - activation_1_loss: 0.7494 - activation_loss: 0.8516
Epoch 00003: val_loss did not improve from 1.72778
21984/21984 [==============================] - 205s 9ms/sample - loss: 1.6001 - activation_1_loss: 0.7491 - activation_loss: 0.8511 - val_loss: 1.7729 - val_activation_1_loss: 0.8351 - val_activation_loss: 0.9372
Fold 4 metric:0.705081
对测试集数据进行预测。采用训练好的5个模型的预测值进行平均。
preds_start = np.zeros((input_ids_t.shape[0],MAX_LEN))
preds_end = np.zeros((input_ids_t.shape[0],MAX_LEN))
for i in range(5):
model.load_weights('roberta-%i.h5'%i)
preds = model.predict([input_ids_t,attention_mask_t,token_type_ids_t])
preds_start += preds[0]/5
preds_end += preds[1]/5
preds_text = []
for i in range(test.shape[0]):
start = np.argmax(preds_start[i])
end = np.argmax(preds_end[i])
if end>=start:
selected_text = tokenizer.decode(input_ids_t[i, start:(end+1)]).strip()
else:
selected_text = test.loc[0, 'text']
preds_text.append(selected_text)
test['selected_text'] = preds_text
test[['textID', 'selected_text']].to_csv('submission.csv', index=False)
test.head(20)
| textID | text | sentiment | selected_text | |
|---|---|---|---|---|
| 0 | f87dea47db | Last session of the day http://twitpic.com/67ezh | neutral | last session of the day http://twitpic.com/67ezh |
| 1 | 96d74cb729 | Shanghai is also really exciting (precisely -... | positive | exciting |
| 2 | eee518ae67 | Recession hit Veronique Branquinho, she has to... | negative | such a shame! |
| 3 | 01082688c6 | happy bday! | positive | happy bday! |
| 4 | 33987a8ee5 | http://twitpic.com/4w75p - I like it!! | positive | i like it!! |
| 5 | 726e501993 | that`s great!! weee!! visitors! | positive | that`s great!! |
| 6 | 261932614e | I THINK EVERYONE HATES ME ON HERE lol | negative | hates |
| 7 | afa11da83f | soooooo wish i could, but im in school and my... | negative | blocked |
| 8 | e64208b4ef | and within a short time of the last clue all ... | neutral | and within a short time of the last clue all o... |
| 9 | 37bcad24ca | What did you get? My day is alright.. haven`... | neutral | what did you get? my day is alright.. haven`t ... |
| 10 | 24c92644a4 | My bike was put on hold...should have known th... | negative | argh total bummer |
| 11 | 43b390b336 | I checked. We didn`t win | neutral | i checked. we didn`t win |
| 12 | 69d6b5d93e | .. and you`re on twitter! Did the tavern bore... | neutral | .. and you`re on twitter! did the tavern bore ... |
| 13 | 5c1e0b61a1 | I`m in VA for the weekend, my youngest son tur... | negative | it makes me kinda sad, |
| 14 | 504e45d9d9 | Its coming out the socket I feel like my phon... | negative | i feel like my phones hole is not a virgin. th... |
| 15 | ae93ad52a0 | So hot today =_= don`t like it and i hate my ... | negative | i hate my new timetable, having such a bad week |
| 16 | 9fce30159a | Miss you | negative | miss you |
| 17 | 00d5195223 | Cramps . . . | negative | cramps |
| 18 | 33f19050cf | you guys didn`t say hi or answer my questions... | positive | nice songs. |
| 19 | f7718b3c23 | I`m going into a spiritual stagnentation, its ... | neutral | i`m going into a spiritual stagnentation, its ... |