MATLAB 正则表达式
MATLAB 正则表达式
文章目录
- MATLAB 正则表达式
- 与正则表达式相关的函数
- regexp 用法
- 输出类型
- 如何构建 exp
- 元字符
- 字符转义
- 重复限定符
- 重复限定符的三种模式
- 分组运算符
- 锚点
- 选项(option)
- 例子
与正则表达式相关的函数
matlab 中与正则表达式相关的函数:
| 函数名 | 功能 |
|---|---|
| regexp | 匹配正则表达式,大小写敏感 |
| regexpi | 匹配正则表达式,大小写不敏感 |
| regexprep | 基于正则表达式进行字符替换 |
regexp 用法
以 regexp 为例说明用法
startIndex = regexp(str, exp)
[startIndex, endIndex] = regexp(str, exp)
[out1, out2, ...] = regexp(str, exp, outkey1, outkey2, ...)
out = regexp(str, exp, option, ...)
其中,str 为待匹配的字符串,exp 为正则表达式,outkey 用于指明输出的类型。option 为可选的选项。
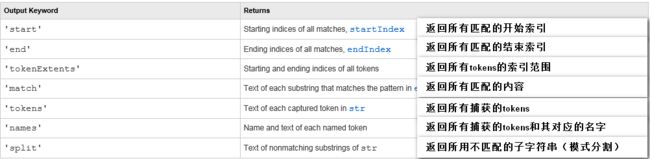
输出类型
outkey 取值:
如何构建 exp
元字符
. : 匹配任意一个字符
[c1c2c3] : 匹配来自方括号内的任意一个字符(+,-,.,*,?,|,$ 按照字面处理, - 表示范围除外)
[^c1c2c3] : 匹配除方括号内字符以外的任意一个字符(+,-,.,*,?,|,$ 按照字面处理, - 表示范围除外)
[c1-c2] : 匹配介于 c1-c2 之间的任意一个字符
\w : 匹配字母、数字、下划线中的任意一个字符 <==> [a-z_A-Z0-9]
\W : 匹配除字母、数字、下划线以外的任意一个字符 <==> [^a-z_A-Z0-9]
\s : 匹配任意一个空白符
\S : 匹配任意一个非空白字符符
\d : 匹配任意一个数字
\D : 匹配任意一个非数字字符
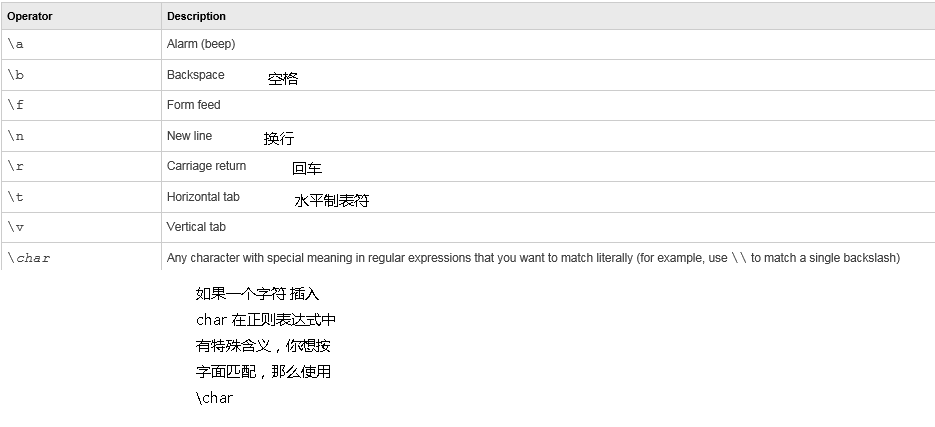
字符转义
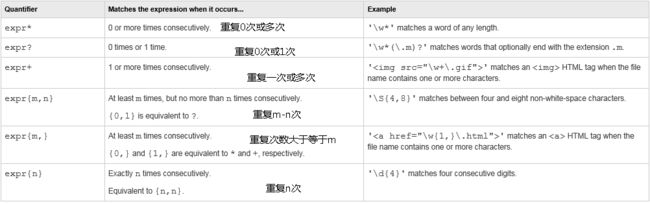
重复限定符
重复限定符的三种模式
重复限定符 *, +, ?, {m,n} 有三种模式:
- 贪婪模式(默认)
- 懒惰模式,在重复限定符后面加 ?
- 占有模式,在重复限定符后面加 +
分组运算符
分组运算符 (), 有两个作用:
- 用于捕获 tokens
- 分组,改变运算优先级
(exp) : 分组,且捕获 tokens
(exp) : 分组不捕获
锚点
^exp : 以表达式开头
exp$ : 以表达式结尾
选项(option)

例子
例如在 C 或 C++ 源文件中查找所有的函数调用,并提取函数名
主程序:
clc
clear all
file_list = getFileList('src', 'l'); % 获取名称列表
k = 1;
% 读取全部文件建立cell数据结构
for i=1:length(file_list)
if strcmp(file_list{i}(end-1:end), '.c')
cont{k,1} = file_list{i};
cont{k,2} = txt2char(file_list{i});
k = k +1;
end
end
data = build_ref_tree('main', cont, 6); % 调用子函数建立具有tree结构的cell
str = print_data(data); % 打印该数据结构
子程序:
function data = build_ref_tree(fun_name, cont, max_deep)
% 完成对递归函数的外部包装,返回具有递归结构的cell
count = 0;
global deep;
deep = max_deep;
data = fun_recursive(fun_name, cont, count);
data = {data};
function out = fun_recursive(fun_name, cont, count)
% 递归调用的函数,构建树形结构形如{fun_name, file_name, {...}}, {...}
% 内具有自相似结构
count = count + 1;
if count == deep;
out = {};
return;
end
[code, file] = find_def(fun_name, cont);
if isempty(code)
out = {};
return;
end
fun_names = list_fun_name(code);
if isempty(fun_names)
out = {};
return;
end
k = 1;
t = {''};
for j=1:length(fun_names)
tmp = fun_recursive(fun_names{j}, cont, count);
if isempty(tmp);
continue;
end
t{k,:} = tmp;
k = k + 1;
end
out = {fun_name,file, t};
end
end
function [code, file] = find_def(fun_name, cont)
% 在所用文件中查找给定函数的定义处,返回所在文件和代码块
t = regexp(cont(:,2), ['\s+',fun_name, '\(.*?\)\s*{'], 'end', 'dotexceptnewline');
flag = 0;
if isempty(t)
code = '';
file = '';
return;
end
for i=1:length(t)
if isempty(t{i})
continue;
else
ind = i;
file = cont{ind,1};
flag = 1;
break;
end
end
if flag == 0
code = '';
file = '';
return;
end
flag = 0;
range_start = t{ind};
range_end = range_start;
ch = cont{ind,2};
for i=range_start:length(ch)
if strcmp(ch(i),'{')
flag = flag + 1;
elseif strcmp(ch(i),'}')
flag = flag - 1;
end
if flag == 0
range_end = i;
break;
end
end
code = ch(range_start:range_end);
end
function out = list_fun_name(code)
% 在一串字符中找出所用被调用的函数名称
exclude = {'if','while','printf','for'};
out = cell(1);
out2 = regexp(code, '([a-z_A-Z]\w*)\(.*?\);', 'tokens', 'dotexceptnewline');
out2 = out2';
k = 1;
for i=1:length(out2)
tmp = out2{i}{1};
if ismember(tmp, exclude)
continue;
end
out{k,:} = tmp;
k = k + 1;
end
end
function str = print_data(data, count)
if isempty(data{1})
str = '';
return;
end
if nargin == 1
count = 0;
else
count = count + 1;
end
str = '';
for i=1:length(data)
if count == 0
ch = [data{i}{1}, '(', data{i}{2}, ')'];
disp(ch);
else
ch = [' ', repmat('| ', 1, count-1), '|----', data{i}{1}, '(', data{i}{2}, ')'];
disp(ch);
end
str = [str, ch, sprintf('\n'), print_data(data{i}{3}, count)];
end
end
打印输出:
main(main.c)
|----parse_network_cfg_custom(src\parser.c)
| |----make_network(src\network.c)
| |----parse_net_options(src\parser.c)
| |----free_section(src\parser.c)
| |----parse_convolutional(src\parser.c)
| |----parse_local(src\parser.c)
| |----parse_activation(src\parser.c)
| |----parse_rnn(src\parser.c)
| |----parse_gru(src\parser.c)
| |----parse_crnn(src\parser.c)
| |----parse_connected(src\parser.c)
| |----parse_crop(src\parser.c)
| |----parse_cost(src\parser.c)
| |----parse_region(src\parser.c)
| |----parse_yolo(src\parser.c)
| |----parse_detection(src\parser.c)
| |----parse_softmax(src\parser.c)
| |----parse_normalization(src\parser.c)
| |----parse_batchnorm(src\parser.c)
| |----parse_maxpool(src\parser.c)
| |----parse_reorg(src\parser.c)
| |----parse_reorg_old(src\parser.c)
| |----parse_avgpool(src\parser.c)
| |----parse_route(src\parser.c)
| |----parse_upsample(src\parser.c)
| |----parse_shortcut(src\parser.c)
| |----parse_dropout(src\parser.c)
| |----option_find_int_quiet(src\option_list.c)
| |----option_find_int_quiet(src\option_list.c)
| |----option_find_int_quiet(src\option_list.c)
| |----option_find_int_quiet(src\option_list.c)
| |----option_unused(src\option_list.c)
| |----free_section(src\parser.c)
| |----free_list(src\list.c)
|----load_weights(src\parser.c)
| |----load_weights_upto(src\parser.c)