【数据压缩】LZW算法原理与源码解析
转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/50331883
<勿在浮沙筑高台>
LZW压缩算法原理非常简单,因而被广泛地采用,已经被引入主流图像文件格式中。该算法由Lempel-Ziv-Welch三人发明,这种技术将定长码字分配给变长信源符号序列,它不需要知道被压缩文件的符号出现概率的先验知识,只需要动态地建立和维护一个字典,和其他压缩算法相比既是缺点也是优点。
1. LZW原理
1.1 概念的理解
LZW通过建立一个字典(code table),把不认识的字符串序列加入字典,当下次再次遇到此种字符串序列时,用字典的索引序号代替此序列,而一个索引序号占用的字节数往往比代替的字符串小的多,以此来达到压缩文件的目的。通常在图像压缩上,由于0-255用于表示灰度级(8位二进制),而我们的索引序号要与灰度级区别开来,因而,字典索引的建立要从256开始,见下面的例子,此例子不表示LZW算法的原型,暂时不要关心字典是如何建立的。
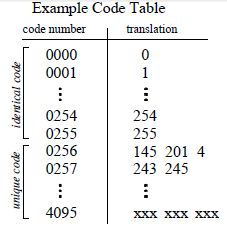

注意到,在上图中,压缩文件中保存了123 256 119 ... ,由于文件数据都是采用二进制形式保存的,解压时为了正确的按位读取,通常压缩文件中,写入的每一个数据都是以12位形式写入文件。这时用字典索引号256代替连续的字符序列145 201 4,就是用了12位的数据代替了3个8位的数据。虽然其他的字符以原型写入,例如第一个8位数据123被扩展成12位的123,但是总体上看,仍然达到了压缩的作用。
1.2 压缩过程&流程图
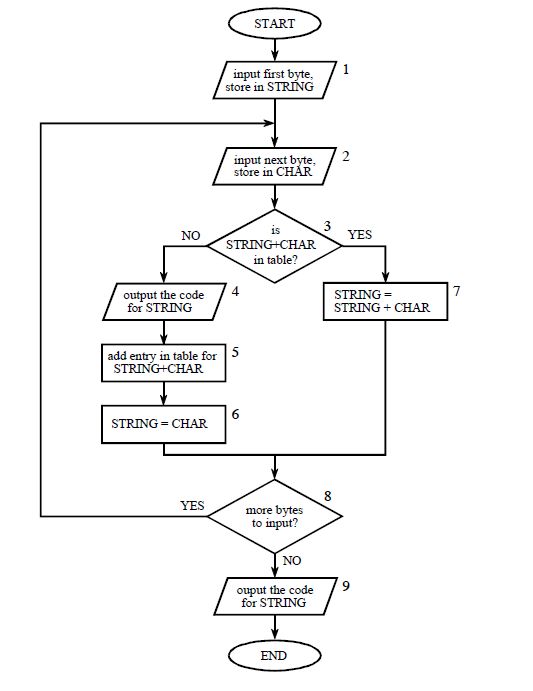
LZW算法采用动态的建立字典的方法,依次读入原文件的字符序列,每次碰到新的连续的字符串,就在字典中加入标示,当下次再次遇到这种字符串时,就可以用字典索引序号直接代替字符串,写入压缩文件中。在这里引入两个名词: "string","char";string表示前缀,char 表示新读入的字符,每个字典索引对应一对(string,char);
--------------------------------------------------------------------------------------------------------------------------------------
举个例子:“ABCABC”开始时,初始化字典,索引0~255被初始化为(NULL, i), i =0,1,...,255;让字典从索引号256开始记录,正如上面所说,为了解压时方便识别数据,每次向压缩文件中写数据时,都是12位格式,这时字典索引范围为0~4095;
1. 开始时,读入第一个字符string = A,读下一个字符char = B ;
3. 查字典(A,B),字典中没有找到,在字典索引256中记录(A,B),然后输出前缀A,更新string=char=B,再次读入字符,char=C;
4. 查字典(B,C),字典中没有找到,在字典索引257中记录(B,C),然后输出前缀B,更新string=char=C,再次读入字符,char=A;
5. 查字典(C,A),字典中没有找到,在字典索引258中记录(C,A),然后输出前缀C,更新string=char=A,再次读入字符,char=B;
6. 查字典(A,B),字典可以找到,对应索引号256,然后更新string=256,再次读入字符,char=C;
7. 查字典(256,C),字典中没有找到,在字典索引259中记录(256,C),然后输出前缀256,更新string=char=C,再次读入字符,char=NULL;
8. char = NULL ,文件结束,输出前缀C.
压缩完成后:A B C 256 C ; 字典不需要写入文件中;
上述过程概括:"前缀string+字符char"在字典中不存在,加入字典,输出前缀,更新前缀=char,读入新字符char;
"前缀string+字符char"在字典中存在,更新前缀=索引号,读入新字符char;
--------------------------------------------------------------------------------------------------------------------------------------
1.3 解压过程&流程图
上述压缩文件为 A B C 256 C ,同样采用上述的步骤,初始化字典,建立字典、查字典的方法可以实现文件的解压缩,但是解压缩过程并不简单等同于压缩过程。解压缩完成后压缩文件时建立的字典和解压缩建立的字典完全一样!PS:解压缩过程,网上部分博客说法不准确,结果导致我折腾了两天程序 。
------------------------------------------------------------------------------------------------------------------------------------------------
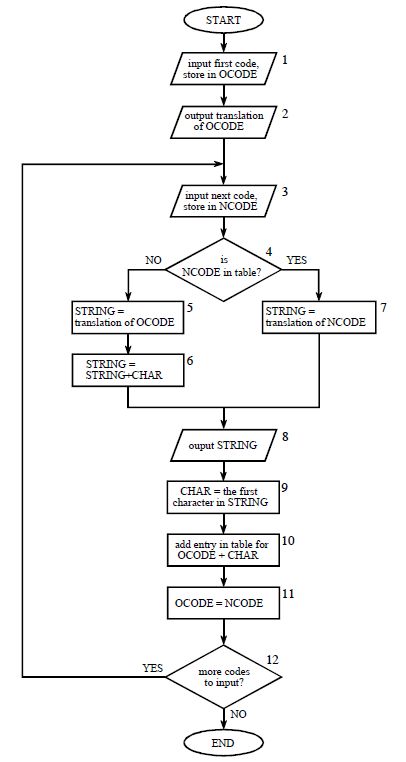
OCODE:表示已经读入的12位数据 ; NCODE:表示新读入的12位数据;
STRING:表示12位数据代表的字符串;CHAR表示被写入文件的字符串的第一个字符;
1. 开始时,初始化字典(0~255),读入第一个数据OCODE = A,输出字典索引OCODE对应的字符串A,读下一个数据NCODE = B ;
2. NCODE在字典中存在,输出table[NCODE]=B,CHAR=B;在字典索引256加入(OCODE,CHAR)=(A,B),更新OCODE=NCODE,读取数据NCODE=C;
3. NCODE在字典中存在,输出table[NCODE]=C,CHAR=C;在字典索引257加入(OCODE,CHAR)=(B,C),更新OCODE=NCODE,读取数据NCODE=256;
4. NCODE在字典中已建立,table[256]=AB,并记录CHAR=A;在字典索引258加入(OCODE,CHAR)=(C,A),更新OCODE=NCODE,读取数据NCODE=C;
5. NCODE在字典中已建立,table[NCODE]=C,CHAR=C,在字典索引259加入(OCODE,CHAR)=(256,C),更新OCODE=NCODE读取数据NCODE=空;
6. 文件结束!跳出循环!
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
你肯定已经注意到,上面举得例子解压缩时读取的NCODE都可以在字典中找到,什么情况下在字典中找不到呢?
压缩这个字符串"ABBBBBBBB",解压缩时就可以碰到字典中找不到的情况;一定要动手试试,方便你理解整个流程图!
2.关于LZW的使用和改进
上面的例子都是采用12位格式写入文件,但是12位在字典中表示的范围为0~4095,真实去压缩一个文件时,这个大小肯定是不够的,如果扩展字典的范围,占用内存很大。但是这时可以在文件中加入一个标示,然后重新初始化字典,表示从此开始,采用新字典继续压缩文件,可以理解成把文件分割成多个小文件,每个小文件单独采用一张表。通常令256表示新表的开始,257表示文件压缩结束。
从上面的过程可以看到,每一个数据都采用12位格式写入文件,无疑造成了内存的浪费,例如256实际上可以用9位二进制表示,所以有很多人对此进行了改进,采用变长的字典算法,例如当9位的字典写满时,继续采用10位的字典压缩。同时也有多算法对查找字典的方法进行了改进,时间上也有很大的提高!
3.LZW算法的实现
完整工程下载:http://download.csdn.net/detail/luoshixian099/9369093
/**********************************
CSDN 勿在浮沙筑高台
http://blog.csdn.net/luoshixian099
【数据压缩】LZW压缩算法 2015年12月17日
***********************************/
#include
#include
#include "Compress.h"
using namespace std;
#define IN "D:\\my.bmp"
#define OUT "D:\\test.rar"
int main()
{
compress COM(IN,OUT);
if (!COM.CheckFile())
return 0;
COM.Intial(); //压缩初始化
COM.WriteChar(START); //写入开始标志
UINT pre_code = COM.ReadChar();//读取前缀
UINT Count = 0;
while (!COM.CheckEOF())
{
UINT code = COM.ReadChar(); //读入新字符
UINT temp = COM.CheckTable(pre_code, code);//查字典
if (temp == EMPTY)
{
COM.WriteChar(pre_code); //写入前缀
pre_code = code; //更新前缀
}
else if (temp == NEW_TABLE) //字典已满,重新初始化字典
{
COM.WriteChar(pre_code);
COM.WriteChar(NEW_TABLE);
COM.Intial();
pre_code = code;
}
else
{
pre_code = temp;
}
}
COM.WriteChar(pre_code); //文件结束,输出前缀
COM.WriteEnd();
return 0;
} /**********************************
CSDN 勿在浮沙筑高台
http://blog.csdn.net/luoshixian099
【数据压缩】LZW解压缩算法 2015年12月17日
***********************************/
#include
#include
#include "decompress.h"
using namespace std;
#define IN "D:\\test.rar"
#define OUT "D:\\mytest.bmp"
int main()
{
DeCompress DCOM(IN,OUT);
if (!DCOM.CheckFile())
return 0;
DCOM.Intial(); //初始化字典
UINT OCODE, NCODE;
UCHAR FirstChar;
OCODE = DCOM.ReadData(); //读取第一个数据
DCOM.WriteChar(OCODE); //输出
while (!DCOM.CheckEOF())
{
NCODE = DCOM.ReadData(); //读入新数据
if (NCODE == END) //文件结束标志
break;
else if (NCODE == NEW_TABLE) //读入新字典标志
{
OCODE = DCOM.ReadData();
DCOM.WriteChar(OCODE);
DCOM.Intial();
continue;
}
if (DCOM.CheckTable(NCODE)) //在字典中存在
{
DCOM.WriteChar(NCODE); //输出NCODE
FirstChar = DCOM.GetFirstChar(NCODE);//更新NCODE的第一个字符
}
else //字典中不存在
{
DCOM.WriteChar(OCODE);
DCOM.WriteChar(FirstChar);
FirstChar = DCOM.GetFirstChar(OCODE);
}
DCOM.AddtoTable(OCODE, FirstChar); //OCODE+CHAR字典
OCODE = NCODE;
}
DCOM.WriteEnd();
return 0;
} 参考文章:
http://blog.chinaunix.net/uid-23741326-id-3124208.html
http://blog.csdn.net/abcjennifer/article/details/7995426