Hbase学习汇总(尚硅谷)-超级详细
一 、Hbase介绍
二、 Hbase安装
1、首先保证hadoop和zookeeper正常部署
2、解压 tar -zxvf hbase-1.3.1-bin.tar.gz -C /opt/module
3、修改hbase-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HBASE_MANAGES_ZK=false
JDK1.8需要注释
#export HBASE_MASTER_OPTS。。。。
#export HBASE_REGIONSERVER_OPTS。。。
4、修改hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98后的新变动,之前版本没有.port,默认端口为60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node01:2181,node02:2181,node03:2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/zkData</value>
</property>
</configuration>
说明:
hdfs://mycluster:8020 表示HDFS的地址
/opt/module/zookeeper-3.4.10/zkData 表示是zookeeper的地址,并且zkData目录是之前安装zookeeper指定的目录
5、修改regionservers
node01
node02
node03
node04
node05
6、创建软连接
ln -s /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml /opt/module/hbase/conf/core-site.xml
ln -s /opt/module/hadoop-2.7.2/etc/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml
7、分发集群到node01至05
xsync hbase/
8、启动
bin/start-hbase.sh
当然,我更喜欢写hbase脚本进行启动
hbase.sh start
hbase.sh的脚本如下所示:
#! /bin/bash
case $1 in
"start"){
echo " -------- 启动Hbase集群 -------"
/opt/module/hbase/bin/start-hbase.sh
jps.sh
};;
"stop"){
echo " -------- 停止Hbase集群 -------"
/opt/module/hbase/bin/stop-hbase.sh
};;
esac
9、WebUI
http://192.168.0.121:16010/master-status
三、Hbase Shell操作
启动shell
bin/hbase shell
查看有哪些表
list
1、创建表
必须指定列族
create 'student','info'
2、插入数据
put 'student','1001','info:sex','male'
put 'student','1001','info:age','18'
put 'student','1002','info:name','Janna'
put 'student','1002','info:sex','female'
put 'student','1002','info:age','20'
3、扫描查看数据
注意:STARTROW 和STOPROW 的范围是含头不含尾
scan 'student'
scan 'student',{STARTROW => '1001', STOPROW => '1002'}
scan 'student',{STARTROW => '1001'}
注意:如果插入一条rowKey为100122的数据,还是会被1001到1002的范围扫描出来
例如:
put 'student','100121','info:age','18'
scan 'student',{STARTROW => '1001', STOPROW => '1002'}
结果:

因为是字典顺序,100122 在比较了1001字符比1002字符小之后,剩下的22字符就不比较了
4、查看表结构
describe 'student'
5、更新指定字段的数据
put 'student','1001','info:name','Nick'
put 'student','1001','info:age','100'
6、查看“指定行”或“指定列族:列”的数据
get 'student','1001'
get 'student','1001','info:name'
7、统计表数据行数
count 'student'
8、删除数据
删除某rowkey的全部数据:
deleteall 'student','1001'
删除某rowkey的某一列数据:
delete 'student','1002','info:sex'
9、清空表数据
truncate 'student'
提示:清空表的操作顺序为先disable,然后再truncate。
10、删除表
首先需要先让该表为disable状态:
disable 'student'
然后才能drop这个表:
drop 'student'
11、变更表信息
将info列族中的数据存放3个版本:
alter 'student',{NAME=>'info',VERSIONS=>3}
get 'student','1002',{COLUMN=>'info:name',VERSIONS=>3}
例如:
put 'student','1002','info:name','er'
put 'student','1002','info:name','san'
put 'student','1002','info:name','si'
执行:
get 'student','1002',{COLUMN=>'info:name',VERSIONS=>3}
执行的结果中发现只有三个版本的数据,最开始的那个版本的数据没有了:

执行一把删除操作:
delete 'student','1002','info:name'
scan 'student',{RAW => TRUE, VERSIONS =>10}
结果:

图中表明:删除也是增加,但是被标记为删除了,而且之前限制保存3个版本,但是此时最早的版本也显示出来了,一旦某个版本被标记为删除,那么,比它低的版本将在查询时不会显示,当然,这种查询方式除外。
那么,它真的不会被删除吗?它会在合适的时机进行删除操作的。
12、查看命名空间
list_namespace
默认有default和hbase命名空间,hbase命名空间中有mata表和namespace表
创建命名空间:
create_namespace 'testnamespace'
指定命名空间创建表:
create testnamespace.emp,'info'
四、Hbase读写流程
读流程:
Hbase如何知道根据条件去某个regionserver上去找数据呢?通过mata表,mata表中记录了这些元数据信息(一定要去看看这个表的结构)
Hbase如何知道mata表在哪个机器上面呢?ZOOKEEPER中记录了mata表所在机器
写流程:
先访问mata,mata告诉你去写到哪台机器,到底是机器的哪个region,rowkey决定了是哪个region,相当于分区,怎么找到某个region的store呢,列族。
读:

1)Client先访问zookeeper,从meta表读取region的位置,然后读取meta表中的数据。meta中又存储了用户表的region信息;
2)根据namespace、表名和rowkey在meta表中找到对应的region信息;
3)找到这个region对应的regionserver;
4)查找对应的region;
5)先从MemStore找数据,如果没有,再到BlockCache里面读;
6)BlockCache还没有,再到StoreFile上读(为了读取的效率);
7)如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。
写:

1)Client向HregionServer发送写请求;
2)HregionServer将数据写到HLog(write ahead log)。为了数据的持久化和恢复;
3)HregionServer将数据写到内存(MemStore);
4)反馈Client写成功。
五、Hbase JAVA API
1、添加依赖:
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
package com.learning.hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* ClassName:HbaseUtil
* Package:com.learning.hbase
* Desciption:HbaseUtil
*
* @date:2019/12/29 13:00
*/
public class HbaseUtil {
//现在之间数据封闭,保证多线程情况下的数据安全
private static ThreadLocal<Connection> connHolder = new ThreadLocal<>();
private static ThreadLocal<HBaseAdmin> adminHolder = new ThreadLocal<>();
private static Configuration conf =null;
/*
* 初始化adminHolder和connHolder
*/
static {
conf = HBaseConfiguration.create();
try {
adminHolder.set(new HBaseAdmin(conf));
Connection conn = ConnectionFactory.createConnection(conf);
connHolder.set(conn);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 查看namespace是否存在
* @param namespace namespace
* @return boolean
*/
public static boolean namespaceExists(String namespace) throws IOException {
Admin admin = adminHolder.get();
NamespaceDescriptor[] names = admin.listNamespaceDescriptors(); // 获取所有的命名空间
for(NamespaceDescriptor desc : names) {
if(namespace.equals(desc.getName()))
return true;
}
return false;
}
/**
* 創建命名空間
* @param namespace namespace
* @throws IOException IOException
*/
public static void createNamespace(String namespace) throws IOException {
Admin admin = adminHolder.get();
admin.createNamespace(NamespaceDescriptor.create(namespace).build());
}
/**
* 查看表是否存在
* @param tableName tableName
* @return boolean
* @throws IOException IOException
*/
public static boolean isTableExist(String tableName) throws IOException {
Admin admin = adminHolder.get();
return admin.tableExists(TableName.valueOf(tableName));
}
/**
* 创建表
* @param tableName tableName
* @param columnFamily columnFamily
* @throws IOException IOException
*/
public static void createTable(String tableName, String... columnFamily) throws IOException {
Admin admin = adminHolder.get();
//判断表是否存在
if(isTableExist(tableName)){
System.out.println("表" + tableName + "已存在");
}else{
//创建表属性对象,表名需要转字节
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf(tableName));
//创建多个列族
for(String cf : columnFamily){
descriptor.addFamily(new HColumnDescriptor(cf));
}
//根据对表的配置,创建表
admin.createTable(descriptor);
System.out.println("表" + tableName + "创建成功!");
}
}
/**
* 删除表
* @param tableName tableName
* @throws IOException IOException
*/
public static void dropTable(String tableName) throws IOException {
HBaseAdmin admin = adminHolder.get();
if(isTableExist(tableName)){
admin.disableTable(tableName);
admin.deleteTable(tableName);
System.out.println("表" + tableName + "删除成功!");
}else{
System.out.println("表" + tableName + "不存在!");
}
}
/**
* 删除表的多行数据
* @param tableName tableName
* @param rows rows
* @throws IOException IOException
*/
public static void deleteMultiRow(String tableName, String... rows) throws IOException{
HTable hTable = new HTable(conf, tableName);
List<Delete> deleteList = new ArrayList<Delete>();
for(String row : rows){
Delete delete = new Delete(Bytes.toBytes(row));
deleteList.add(delete);
}
hTable.delete(deleteList);
hTable.close();
}
/**
* 查询某张表下的所有数据
* @param tableName tableName
* @throws IOException IOException
*/
public static void getAllRows(String tableName) throws IOException{
HTable hTable = new HTable(conf, tableName);
//得到用于扫描region的对象
Scan scan = new Scan();
//使用HTable得到resultcanner实现类的对象
ResultScanner resultScanner = hTable.getScanner(scan);
for(Result result : resultScanner){
Cell[] cells = result.rawCells();
for(Cell cell : cells){
//得到rowkey
System.out.println("行键:" + Bytes.toString(CellUtil.cloneRow(cell)));
//得到列族
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
}
/**
* 获取某一行数据
* @param tableName tableName
* @param rowKey rowKey
* @throws IOException IOException
*/
public static void getRow(String tableName, String rowKey) throws IOException{
HTable table = new HTable(conf, tableName);
Get get = new Get(Bytes.toBytes(rowKey));
//get.setMaxVersions();显示所有版本
//get.setTimeStamp();显示指定时间戳的版本
Result result = table.get(get);
for(Cell cell : result.rawCells()){
System.out.println("行键:" + Bytes.toString(result.getRow()));
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
System.out.println("时间戳:" + cell.getTimestamp());
}
}
/**
* 获取"列族:列"的数据
* @param tableName tableName
* @param rowKey rowKey
* @param family family
* @param qualifier qualifier
* @throws IOException IOException
*/
public static void getRowQualifier(String tableName, String rowKey, String family, String
qualifier) throws IOException{
HTable table = new HTable(conf, tableName);
Get get = new Get(Bytes.toBytes(rowKey));
get.addColumn(Bytes.toBytes(family), Bytes.toBytes(qualifier));
Result result = table.get(get);
for(Cell cell : result.rawCells()){
System.out.println("行键:" + Bytes.toString(result.getRow()));
System.out.println("列族" + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("列:" + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("值:" + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
/**
* 关闭Connection连接
* @throws IOException IOException
*/
public void close() throws IOException {
Connection conn = connHolder.get();
conn.close();
}
/**
* 插入一条数据
* @param tableName tableName
* @param rowKey rowKey
* @param family family
* @param column column
* @param value value
* @throws IOException IOException
*/
public static void insertData(String tableName,String rowKey,String family,String column,String value) throws IOException {
Connection conn = connHolder.get();
Table table = conn.getTable(TableName.valueOf(tableName));
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes(family),Bytes.toBytes(column),Bytes.toBytes(value));
table.put(put);
table.close();
}
}
六、MapReduce操作Hbase
6.1 将Hbase中的一张表的数据复制到另一张表
需求:实现Hbase一张表的数据复制到另一张表(在默认的namespace,如果在别的namespace复制,会有问题,暂时没有研究,主要是找不到namespace下某张表的问题)
通用代码:
1、先在hbase中创建student和student_copy表,并且在student表中插入一些数据
package com.learning.hbase.mr;
import org.apache.hadoop.util.ToolRunner;
public class Table2TableApplication {
public static void main(String[] args) throws Exception {
ToolRunner.run(new HbaseMapReduceTool(),args);
}
}
package com.learning.hbase.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobStatus;
import org.apache.hadoop.util.Tool;
public class HbaseMapReduceTool implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance();
job.setJarByClass(HbaseMapReduceTool.class);
//mapper
TableMapReduceUtil.initTableMapperJob(
"student",
new Scan(),
ScanDataMapper.class,
ImmutableBytesWritable.class,
Put.class,
job
);
//reduce
TableMapReduceUtil.initTableReducerJob(
"student_copy",
InsertDataReducer.class,
job
);
//执行作业
boolean flag = job.waitForCompletion(true);
return flag ? JobStatus.State.SUCCEEDED.getValue() : JobStatus.State.FAILED.getValue();
}
@Override
public void setConf(Configuration configuration) {
}
@Override
public Configuration getConf() {
return null;
}
}
package com.learning.hbase.mr;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import java.io.IOException;
public class ScanDataMapper extends TableMapper<ImmutableBytesWritable, Put> {
@Override
protected void map(ImmutableBytesWritable key, Result result, Context context) throws IOException, InterruptedException {
Put put = new Put(key.get());
for (Cell cell : result.rawCells()){
put.addColumn(
CellUtil.cloneFamily(cell),
CellUtil.cloneQualifier(cell),
CellUtil.cloneValue(cell)
);
}
context.write(key,put);
}
}
package com.learning.hbase.mr;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
public class InsertDataReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
for (Put put : values) {
context.write(NullWritable.get(),put);
}
}
}
将代码打成可运行jar包并上传:https://blog.csdn.net/qq_37023928/article/details/103756355
在/etc/profile添加:
export HBASE_HOME=/opt/module/hbase
export HADOOP_HOME=/opt/module/hadoop-2.7.2
并在hadoop-env.sh中配置:(注意:在for循环之后配)
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/module/hbase/lib/*
执行jar包:
yarn jar /opt/my_jar/HBASE_LEARNING_jar/HBASE_LEARNING.jar
**结果验证:**在student_copy表中查看数据。
6.2 读取HDFS数据到Hbase
数据:
222221,25,sex1
333331,26,sex2
444441,22,sex3
555551,23,sex4
666661,25,sex5
package com.learning.hbase.mr2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobStatus;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.util.Tool;
/**
* ClassName:HdfsFile2HtableTool
* Package:com.learning.hbase.mr2
* Desciption:
*
* @date:2019/12/29 20:54
*/
public class HdfsFile2HtableTool implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance();
job.setJarByClass(HdfsFile2HtableTool.class);
Path path = new Path("hdfs://node01:8020/data/student.csv");
FileInputFormat.addInputPath(job,path);
job.setMapperClass(Hdfs2HtableMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
TableMapReduceUtil.initTableReducerJob("student",Hdfs2HtableReducer.class,job);
boolean flag = job.waitForCompletion(true);
return flag ? JobStatus.State.SUCCEEDED.getValue() : JobStatus.State.FAILED.getValue();
}
@Override
public void setConf(Configuration configuration) {
}
@Override
public Configuration getConf() {
return null;
}
}
package com.learning.hbase.mr2;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* ClassName:Hdfs2HtableMapper
* Package:com.learning.hbase.mr2
* Desciption:
*
* @date:2019/12/29 20:57
*/
public class Hdfs2HtableMapper extends Mapper<LongWritable, Text, ImmutableBytesWritable, Put> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split(",");
String rowKey=arr[0];
Put put = new Put(Bytes.toBytes(rowKey));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("age"),Bytes.toBytes(arr[1]));
put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("sex"),Bytes.toBytes(arr[2]));
ImmutableBytesWritable rowKeyWritable = new ImmutableBytesWritable(Bytes.toBytes(rowKey));
context.write(rowKeyWritable,put);
}
}
package com.learning.hbase.mr2;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.io.NullWritable;
import java.io.IOException;
/**
* ClassName:Hdfs2HtableReducer
* Package:com.learning.hbase.mr2
* Desciption:
*
* @date:2019/12/29 20:57
*/
public class Hdfs2HtableReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {
for (Put put : values) {
context.write(NullWritable.get(),put);
}
}
}
package com.learning.hbase.mr2;
import org.apache.hadoop.util.ToolRunner;
/**
* ClassName:HdfsFile2HtableApplication
* Package:com.learning.hbase.mr2
* Desciption:
*
* @date:2019/12/29 20:52
*/
public class HdfsFile2HtableApplication {
public static void main(String[] args) throws Exception {
ToolRunner.run(new HdfsFile2HtableTool(),args);
}
}
将代码打成可执行jar包,放到集群上面运行。
6.3 将Hbase中查询的结果统计分析后写入Mysql
七、协处理器
增量与全量:表的备份,很多情况下没有必要进行全量导入,有的表是增量导入的,有的表示全量导入的。
需求:A表插入数据的时候,同时在B表插入一条数据,default:student -> learning:student
1、协处理器代码:
package com.learning.hbase;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import java.io.IOException;
/**
* ClassName:InsertCorprocesser
* Package:com.learning.hbase
* Desciption:协处理器
*
* @date:2020/1/1 23:04
* @author:[email protected]
*/
public class InsertCorprocesser extends BaseRegionObserver {
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException {
//获取表
Table table = e.getEnvironment().getTable(TableName.valueOf("learning:student"));
//增加数据
table.put(put);
table.close();
}
}
将上面的项目打成依赖jar包,上传到hbase的lib目录下面,并且分发jar包到集群。
2、在创建表的时候指定协处理器:
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf("tableName"));descriptor.addCoprocessor("com.learning.hbase.InsertCorprocesser");
descriptor.addFamily(new HColumnDescriptor("cf1"));
admin.createTable(descriptor);
3、在default:student表中插入一条数据,在learning:student表中查询数据是否也更新过来了。
八、与HIVE集成
8.1 hive与hbase对比
1.Hive
(1) 数据仓库
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询。
(2) 用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高。
(3) 基于HDFS、MapReduce
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行。
2.HBase
(1) 数据库
是一种面向列存储的非关系型数据库。
(2) 用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
(3) 基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理。
(4) 延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度。
8.2 hive与hbase集成
目标:建立Hive表,关联HBase表,插入数据到Hive表的同时能够影响HBase表。
1、执行下面的软链接
export HBASE_HOME=/opt/module/hbase
export HIVE_HOME=/opt/module/hive
ln -s $HBASE_HOME/lib/hbase-common-1.3.1.jar $HIVE_HOME/lib/hbase-common-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-server-1.3.1.jar $HIVE_HOME/lib/hbase-server-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-client-1.3.1.jar $HIVE_HOME/lib/hbase-client-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-protocol-1.3.1.jar $HIVE_HOME/lib/hbase-protocol-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-it-1.3.1.jar $HIVE_HOME/lib/hbase-it-1.3.1.jar
ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar $HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar
ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar
ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop-compat-1.3.1.jar
2、需要将hive-hbase-handler-1.2.2.jar 重新编译,这里有编译好的包,直接替换即可。
3、再hive中创建表:
第一张是中间表
CREATE TABLE hive_hbase_emp_table(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno")
TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
4、加载数据
hive> load data local inpath '/home/admin/softwares/data/emp.txt' into table emp;
hive> insert into table hive_hbase_emp_table select * from emp;
5、查询hive和hbase中的结果
hive:
hive> select * from hive_hbase_emp_table;
hbase:
hbase> scan ‘hbase_emp_table’
九、预分区
region切分:
当region到达阈值256M的时候,会进行切分,先找到中间的rowkey,一分为二。
数据倾斜的场景:
如果rowkey是按照时间顺序进行存储的,第一次切分:region1[存储2018年的rowkey]、region2[存储大于2019年的rowkey],当region2的数据急剧增加时,region2又要进行切分,但是此时的region1是不会再进行切分的了,因为rowkey是按照顺序存储的,后面的数据不可能再存储到region1,所以region1的数据一直不变,导致了数据倾斜。
根据数据进行预估:
100G数据,10台,每个region 10G,所以需要10个region就够了,但是还要考虑数据的增量,如果每年增加50G,预估十年,就是600G数据,那么需要60个region。
每一个region维护着startRow与endRowKey,如果加入的数据符合某个region维护的rowKey范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高HBase性能。
1.手动设定预分区
create 'staff1','info','partition1',SPLITS => ['1000','2000','3000','4000']
2.生成16进制序列预分区
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}
3.按照文件中设置的规则预分区
创建splits.txt文件内容如下:
aaa
bbb
ccc
然后执行:
create 'staff3','partition3',SPLITS_FILE => 'splits.txt'
4.使用JavaAPI创建预分区
分区编号:
先来看一下hashMap的原理:
hashMap默认有16个小格子,如果某个小格子已经有数据了,那么,这个小格子会形成一个链表,当这个链表长度到达8的时候,放第九个数据,它会认为:你为什么把这个数据放到这么长的链表里面呢?而不是放在小格子里面呢?哦!可能是容量不够(小格子数量),所以扩容为16X2=32,当这个链表的长度到10时,还是扩容,32X2=64,如果还放第11个数据到链表,它认为:64个小格子已经不少了,是不是数据结构有问题?,此时,它会把链表变成红黑二叉树。
为什么扩容?因为放在一个链表里面不均衡。
为什么扩容是二倍?(按位&运算)
例如:00001111 16 个格子,意味着区间在[0,15],现在有散列:00010101,它会与00001111进行&运算(位运算),此时运算的结果是00000101,结果为5,在区间当中。如果只有6个格子,即00000110,意味着区间在[0,5],但是1这个值永远都得不到,因为00000110的最后一位是0,0&任何数的结果都是0,所以不可能得到1,导致数据不均衡,不断进行扩容,效率低。当格子数为2的n次方时,那么区间范围是[0,2的n次方-1],…111111,是类似这种尾数全是1的二进制。这就有一个规律,2的n次方的格子进行扩容时,可以采用位运算。
如果分区的数量不是2的n次方,那么进行取余运算即可,如果是2的n次方,则进行按位&运算,这种效率更高。
那么如何判断区间是2的N次方呢?
00000100 & 00000011 =00000000 ,n(按位&运算)n-1 =0 即n与n-1的按位与运算的结果为0
分区键:
“|”是Ascall码中的第二大的值,例如0_lil的rowkey会被存储到第一个分区,1_ada会被存储到第二个分区,因为“_”比“|”小。分区如下图所示:
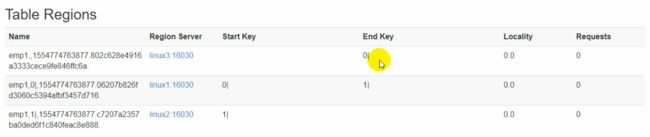
代码实现:
/**
*生成分区号
* @param rowKey rowKey
* @param totalRegion totalRegion
* @return String
*/
public static String getRegionNum(String rowKey,int totalRegion){
int regionNum;
int hash = rowKey.hashCode();
if(totalRegion >1 && (totalRegion & (totalRegion -1)) ==0){
//region数量是2的N次方,按位&运算
regionNum=hash & (totalRegion-1);
}else{
regionNum=totalRegion %totalRegion;
}
return regionNum+"_";
}
存数据的时候需要调用上述方法,取数据的时候也要调用这个方法。
/**
* 预分区的分区键,也就是临界值
* @param totalRegion totalRegion
* @return byte[][]
*/
public static byte[][] getRegionKey(int totalRegion){
byte[][] bytes = new byte[totalRegion - 1][];
for (int i =0; i<totalRegion-1;i++){
bytes[i]= Bytes.toBytes(i+"|");
}
return bytes;
}
public static void main(String[] args) {
byte[][] regionKey = getRegionKey(5);
for(byte[] b:regionKey){
System.out.println(Bytes.toString(b));
}
}
输出的分区键结果:
0|
1|
2|
3|
创建表的时候指定预分区:
//创建表的时候同时指定预分区
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf("tableName"));
descriptor.addFamily(new HColumnDescriptor("cf1"));
admin.createTable(descriptor,getRegionKey(6));
添加数据时指定分区编号:
String rowKey=getRegionNum("zhangsan",6) //1_zhangsan
Put put = new Put(Bytes.toBytes(rowKey));
十、rowkey设计原则
1、唯一性原则
2、长度原则,一般是60-80个字节,不要超过100,最大值是64K。
3、散列原则,让rowkey没有规律,均匀分配
有些时候的数据不能散列,例如我要把2020年1月份的数据放在一块。这样统计分析比较方便,如果这时候散列,数据散的太广了,不利于统计分析,所以是否散列,需要根据具体的业务进行选择。
十一、Hbase优化
①预分区
②rowkey设计
③内存优化:
HBase操作过程中需要大量的内存开销,毕竟Table是可以缓存在内存中的,一般会分配整个可用内存的70%给HBase的Java堆。但是不建议分配非常大的堆内存,因为GC过程持续太久会导致RegionServer处于长期不可用状态,一般16~48G内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。
④基础优化:
1.允许在HDFS的文件中追加内容
hdfs-site.xml、hbase-site.xml
属性:dfs.support.append
解释:开启HDFS追加同步,可以优秀的配合HBase的数据同步和持久化。默认值为true。
2.优化DataNode允许的最大文件打开数
hdfs-site.xml
属性:dfs.datanode.max.transfer.threads
解释:HBase一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作,设置为4096或者更高。默认值:4096
3.优化延迟高的数据操作的等待时间
hdfs-site.xml
属性:dfs.image.transfer.timeout
解释:如果对于某一次数据操作来讲,延迟非常高,socket需要等待更长的时间,建议把该值设置为更大的值(默认60000毫秒),以确保socket不会被timeout掉。
4.优化数据的写入效率
mapred-site.xml
属性:
mapreduce.map.output.compress
mapreduce.map.output.compress.codec
解释:开启这两个数据可以大大提高文件的写入效率,减少写入时间。第一个属性值修改为true,第二个属性值修改为:org.apache.hadoop.io.compress.GzipCodec或者其他压缩方式。
5.设置RPC监听数量
hbase-site.xml
属性:hbase.regionserver.handler.count
解释:默认值为30,用于指定RPC监听的数量,可以根据客户端的请求数进行调整,读写请求较多时,增加此值。
6.优化HStore文件大小
hbase-site.xml
属性:hbase.hregion.max.filesize
解释:默认值10737418240(10GB),如果需要运行HBase的MR任务,可以减小此值,因为一个region对应一个map任务,如果单个region过大,会导致map任务执行时间过长。该值的意思就是,如果HFile的大小达到这个数值,则这个region会被切分为两个Hfile。
7.优化hbase客户端缓存
hbase-site.xml
属性:hbase.client.write.buffer
解释:用于指定HBase客户端缓存,增大该值可以减少RPC调用次数,但是会消耗更多内存,反之则反之。一般我们需要设定一定的缓存大小,以达到减少RPC次数的目的。
8.指定scan.next扫描HBase所获取的行数
hbase-site.xml
属性:hbase.client.scanner.caching
解释:用于指定scan.next方法获取的默认行数,值越大,消耗内存越大。
9.flush、compact、split机制
当MemStore达到阈值,将Memstore中的数据Flush进Storefile;compact机制则是把flush出来的小文件合并成大的Storefile文件。split则是当Region达到阈值,会把过大的Region一分为二。
涉及属性:
即:128M就是Memstore的默认阈值
hbase.hregion.memstore.flush.size:134217728
即:这个参数的作用是当单个HRegion内所有的Memstore大小总和超过指定值时,flush该HRegion的所有memstore。RegionServer的flush是通过将请求添加一个队列,模拟生产消费模型来异步处理的。那这里就有一个问题,当队列来不及消费,产生大量积压请求时,可能会导致内存陡增,最坏的情况是触发OOM。
hbase.regionserver.global.memstore.upperLimit:0.4
hbase.regionserver.global.memstore.lowerLimit:0.38
即:当MemStore使用内存总量达到hbase.regionserver.global.memstore.upperLimit指定值时,将会有多个MemStores flush到文件中,MemStore flush 顺序是按照大小降序执行的,直到刷新到MemStore使用内存略小于lowerLimit
0.4与0.38说明:当内存到达40%时,就会就行flush,在0.4到0.38(0.4X0.95)之间,数据是不能往这边写入的,当低于0.38时,数据就可以一边刷到磁盘,一边写入。
十二、Hbase面试题
11.1 Hbase热点(数据倾斜)问题
读写请求会集中到某一个RegionServer上 如何处理
产生热点问题的原因:
- hbase的中的数据是按照字典序排序的,当大量连续的rowkey集中写在个别的region,各个region之间数据分布不均衡;
- 创建表时没有提前预分区,创建的表默认只有一个region,大量的数据写入当前region
- 创建表已经提前预分区,但是设计的rowkey没有规律可循
热点问题的解决方案: - 随机数+业务主键,如果想让最近的数据快速get到,可以将时间戳加上。
- Rowkey设计越短越好,不要超过10~100个字节
- 映射regionNo,这样既可以让数据均匀分布到各个region中,同时可以根据startkey和endkey可以get到同一批数据
11.2 rowkey设计原理
Rowkey设计时需要遵循三大原则:
唯一性原则
rowkey在设计上保证其唯一性。rowkey是按照字典顺序排序存储的,因此,设计rowkey的时候,要充分利用这个排序的特点,将经常读取的数据存储到一块,将最近可能会被访问的数据放到一块。
长度原则
rowkey是一个二进制码流,可以是任意字符串,最大长度 64kb ,实际应用中一般为10-100bytes,以byte[] 形式保存,一般设计成定长。建议越短越好,不要超过16个字节,原因如下:数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率。目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率
加盐:如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位作为散列字段,由程序随机生成,低位放时间字段,这样将提高数据均衡分布在每个RegionServer,以实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息,所有的数据都会集中在一个RegionServer上,这样在数据检索的时候负载会集中在个别的RegionServer上,造成热点问题,会降低查询效率加盐:这里所说的加盐不是密码学中的加盐,而是在rowkey的前面增加随机数,具体就是给rowkey分配一个随机前缀以使得它和之前的rowkey的开头不同。分配的前缀种类数量应该和你想使用数据分散到不同的region的数量一致。加盐之后的rowkey就会根据随机生成的前缀分散到各个region上,以避免热点
哈希:哈希会使同一行永远用一个前缀加盐。哈希也可以使负载分散到整个集群,但是读却是可以预测的。使用确定的哈希可以让客户端重构完整的rowkey,可以使用get操作准确获取某一个行数据
反转:第三种防止热点的方法时反转固定长度或者数字格式的rowkey。这样可以使得rowkey中经常改变的部分(最没有意义的部分)放在前面。这样可以有效的随机rowkey,但是牺牲了rowkey的有序性。反转rowkey的例子以手机号为rowkey,可以将手机号反转后的字符串作为rowkey,这样的就避免了以手机号那样比较固定开头导致热点问题
时间戳反转:一个常见的数据处理问题是快速获取数据的最近版本,使用反转的时间戳作为rowkey的一部分对这个问题十分有用,可以用Long.Max_Value - timestamp 追加到key的末尾,例如[key][reverse_timestamp] ,[key] 的最新值可以通过scan [key]获得[key]的第一条记录,因为HBase中rowkey是有序的,第一条记录是最后录入的数据。比如需要保存一个用户的操作记录,按照操作时间倒序排序,在设计rowkey的时候,可以这样设计[userId反转][Long.Max_Value - timestamp],在查询用户的所有操作记录数据的时候,直接指定反转后的userId,startRow是[userId反转][000000000000],stopRow是[userId反转][Long.Max_Value - timestamp]如果需要查询某段时间的操作记录,startRow是[user反转][Long.Max_Value - 起始时间],stopRow是[userId反转][Long.Max_Value - 结束时间]
12.3 hbase中compact
用途是什么,什么时候触发,分为哪两种,有什么区别?
在HBase中,每当memstore的数据flush到磁盘后,就形成一个storefile,当storefile的数量越来越大时,会严重影响HBase的读性能 ,HBase内部的compact处理流程是为了解决MemStore Flush之后,文件数目太多,导致读数据性能大大下降的一种自我调节手段,它会将文件按照某种策略进行合并,大大提升HBase的数据读性能。
主要起到如下几个作用:
合并文件
清除删除、过期、多余版本的数据
提高读写数据的效率
HBase中实现了两种compaction的方式:minor and major. Minor compactions will usually pick up a couple of the smaller adjacent StoreFiles and rewrite them as one. Minors do not drop deletes or expired cells, only major compactions do this. Sometimes a minor compaction will pick up all the StoreFiles in the Store and in this case it actually promotes itself to being a major compaction.
这两种compaction方式的区别是:
Minor操作只用来做部分文件的合并操作以及包括minVersion=0并且设置ttl的过期版本清理,不做任何删除数据、多版本数据的清理工作。
Major操作是对Region下的HStore下的所有StoreFile执行合并操作,最终的结果是整理合并出一个文件。
compaction触发时机:
Memstore刷写后,判断是否compaction
CompactionChecker线程,周期轮询
12.4 Hbase的原理 regionserver挂了 如何恢复数据 ?新的数据从Hlog里读出来是如何恢复的
引起RegionServer宕机的原因各种各样,有因为Full GC导致、网络异常导致、官方Bug导致(close wait端口未关闭)以及DataNode异常导致等等
HBase检测宕机是通过Zookeeper实现的, 正常情况下RegionServer会周期性向Zookeeper发送心跳,一旦发生宕机,心跳就会停止,超过一定时间(SessionTimeout)Zookeeper就会认为RegionServer宕机离线,并将该消息通知给Master
一旦RegionServer发生宕机,HBase都会马上检测到这种宕机,并且在检测到宕机之后会将宕机RegionServer上的所有Region重新分配到集群中其他正常RegionServer上去,再根据HLog进行丢失数据恢复,恢复完成之后就可以对外提供服务,整个过程都是自动完成的,并不需要人工介入.
![]()
12.5 二级索引
默认情况下,Hbase只支持rowkey的查询,对于多条件的组合查询的应用场景,不够给力。
如果将多条件组合查询的字段都拼接在RowKey中显然又不太可能
全表扫描再结合过滤器筛选出目标数据(太低效),所以通过设计HBase的二级索引来解决这个问题。
这里所谓的二级索引其实就是创建新的表,并建立各列值(family:column)与行键(rowkey)之间的映射关系。这种方式需要额外的存储空间,属于一种以空间换时间的方式
12.6 设计hbase表设计有哪些注意点
题目主要考核hbase表的设计要素:rowkey, family, column, cell, value, timestamp
设计hbase表时需要了解:
行键的结构是什么的并且要包含什么内容
表有多少个列族?
列族中都要放什么数据?
每个列族中有多少个列?
列名是什么?尽管列名在创建表时不需要指定,你读写数据是需要用到它们。
单元数据需要包含哪些信息?
每个单元数据需要存储的版本数量是多少?
12.7habse与mysql的区别
数据存储的方式:
Mysql面向行存储数据,整个行的数据是一个整体,存储在一起。
HBase面向列存储数据,整个列的数据是一个整体,存储在一起,有利于压缩和统计
数据之间的关系:
Mysql存储关系型数据,结构化数据
Hbase存储的非关系型数据,存储结构化和非结构化数据
事务处理:
Mysql数据库存在事务,因为着重于计算(算法)
Hbase数据库侧重于海量数据的存储,所以没有事务的概念
储存容量:
Hbase依托于Hadoop,容量非常大,一般都以PB级为单位存储
Mysql存储数据依赖于所在的硬件设备
12.8 habse读写原理
12.9 Hbase优化
十三、源码分析
十四、常用配置参数
14.1hbase.master.port
<property>
<name>hbase.master.portname>
<value>16000value>
<description>The port the HBase Master should bind to.description>
property>
14.2hbase.hstore.compaction.max
<property>
<name>hbase.hstore.compaction.maxname>
<value>10value>
<description>Max number of HStoreFiles to compact per 'minor'
compaction.description>
property>
<property>
<name>hbase.coprocessor.abortonerrorname>
<value>truevalue>
<description>Set to true to cause the hosting server (master or
regionserver)
to abort if a coprocessor fails to load, fails to initialize, or throws
an
unexpected Throwable object. Setting this to false will allow the server to
continue execution but the system wide state of the coprocessor in
question
will become inconsistent as it will be properly executing in only a
subset
of servers, so this is most useful for debugging only.
description>
property>
true:表示如果协处理器出问题了,RegionServer是不能用的,如果是false,regionServer是能使用的。
14.3hbase.hregion.max.filesize
hbase.hregion.max.filesize
10737418240
Maximum HStoreFile size. If any one of a column families' HStoreFiles has
grown to exceed this value, the hosting HRegion is split in two.
14.4hbase.regionserver.global.memstore.size
<property>
<name>hbase.regionserver.global.memstore.sizename>
<value>value>
<description>Maximum size of all memstores in a region server before
new
updates are blocked and flushes are forced. Defaults to 40% of max heap (0.4).
Updates are blocked and flushes are forced until size of all
memstores
in a region server hits
hbase.regionserver.global.memstore.size.lower.limit.
The default value in this configuration has been intentionally left
emtpy in order to
honor the old hbase.regionserver.global.memstore.upperLimit property if
present.
description>
property>
源码表现:
MemStoreFlusher类:

HeapMemorySizeUtil.safeGetHeapMemoryUsage();
这是工具类,可以直接在main方法中执行,自己测试打印usage.getInit()和usage.getMax(),第一个值其实就是-Xms,是可用内存的1/64,第二个值是-Xmx,是内存的1/4.
getGlobalMemStorePercent方法:

先获取hbase.regionserver.global.memstore.size的值,如果没有,取老版本的配置hbase.regionserver.global.memstore.upperLimit,如果这个也没有,就去默认值0.4,最后防止随意配置,对配置值给出了限制,在0.0~0.8之间。(兼容老版本,并且防止非法值)
14.5hbase.regionserver.global.memstore.size.lower.limit
<property>
<name>hbase.regionserver.global.memstore.size.lower.limitname>
<value>value>
<description>Maximum size of all memstores in a region server before
flushes are forced.
Defaults to 95% of hbase.regionserver.global.memstore.size (0.95).
A 100% value for this value causes the minimum possible flushing to
occur when updates are
blocked due to memstore limiting.
The default value in this configuration has been intentionally left
emtpy in order to
honor the old hbase.regionserver.global.memstore.lowerLimit property if
present.
description>
property>
源码表现:
在MemStoreFlusher中,点击getGlobalMemStoreLowerMark方法的调用:
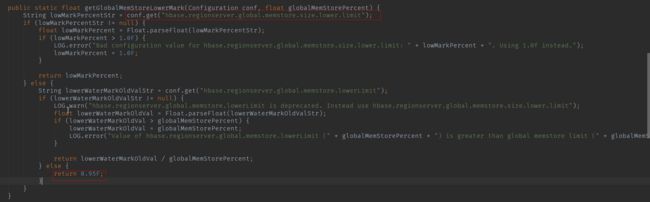
先取配置文件的值,取不到就返回0.95,而且这里对老版本的参数也进行了兼容。
再来看看0.4*0.95的表现:

再在这个类中搜globalMemStoreLimitLowMark,看看这个值在哪里被用到了:

它是线程的方式进行启动,如果服务没有停。如果超过了MemStoreFlusher.this.isAboveLowWaterMark(),也就是0.4*0.95,就调用flushOneForGlobalPressure方法:

在运行过程中,如果把一个非常大的region进行刷写合适吗?当然不合适,因为在这个过程中会阻塞用户的写操作。它会寻找一些小的进行flush,但是又不能把很小的文件进行flush,它会在这两者之间进行寻找。但是,当一个region超过了限定值的两倍,它还是会进行flush,因为它能释放两倍的内存,这样还是很好的。
14.6hbase.regionserver.region.split.policy
<property>
<name>hbase.regionserver.region.split.policyname>
<value>org.apache.hadoop.hbase.regionserver.IncreasingToUpperBoundRegionSplitPolicy
value>
<description>
A split policy determines when a region should be split. The various
other split policies that
are available currently are ConstantSizeRegionSplitPolicy,
DisabledRegionSplitPolicy,
DelimitedKeyPrefixRegionSplitPolicy, KeyPrefixRegionSplitPolicy etc.
description>
property>
14.7hbase.regionserver.regionSplitLimit
<property>
<name>hbase.regionserver.regionSplitLimitname>
<value>1000value>
<description>
Limit for the number of regions after which no more region splitting
should take place.
This is not hard limit for the number of regions but acts as a guideline
for the regionserver
to stop splitting after a certain limit. Default is set to 1000.
description>
property>
14.8hbase.hregion.memstore.flush.size
<property>
<name>hbase.hregion.memstore.flush.sizename>
<value>134217728value>
<description>
Memstore will be flushed to disk if size of the memstore
exceeds this number of bytes. Value is checked by a thread that runs
every hbase.server.thread.wakefrequency.
description>
property>
14.9hbase.hregion.memstore.block.multiplier
<property>
<name>hbase.hregion.memstore.block.multipliername>
<value>4value>
<description>
Block updates if memstore has hbase.hregion.memstore.block.multiplier
times hbase.hregion.memstore.flush.size bytes. Useful preventing
runaway memstore during spikes in update traffic. Without an
upper-bound, memstore fills such that when it flushes the
resultant flush files take a long time to compact or split, or
worse, we OOME.
description>
property>
14.10hbase.hregion.majorcompaction
hbase.hregion.majorcompaction
604800000
The time (in miliseconds) between 'major' compactions of
all
HStoreFiles in a region. Default: Set to 7 days. Major compactions tend to
happen exactly when you need them least so enable them such that they
run at
off-peak for your deploy; or, since this setting is on a periodicity that is
unlikely to match your loading, run the compactions via an external
invocation out of a cron job or some such.
十五、补充
Hbase没有事务的概念,它不能让多个操作当做一个整体来执行,它做不到,但是它有原子性,也就是当增加某一列的过程中,别人是不能打断的。
Hbase disable:删除表之前先禁用,表示当前有人在用,不删除,但是还有其他人想开始用这张表时,不会让他用。当没有人用了时,才会删除表,这样是为了防止脏数据
byte的范围是-127到128,一个字节占8bit
为什么以字节码的形式存储数据?首先,为了数据压缩,节省空间,第二,可以保存任何类型的数据:视频、图片等。
region类似于 partition
hbase中是没有数据的,hbase只是数据管理软件,真正的数据在HDFS上面,Hfile是对HDFS上文件的一个引用的概念
hbase中查询表名为test,rowkey为userl开头的:
HBase Shell :scan 'test', FILTER => "PrefixFilter ('userl')"
HBase JavaAPI : Scan scan = new Scan(); Filter filter = new PrefixFilter(Bytes.toBytes("userl")); scan.setFilter(filter);
文档收集于尚硅谷